
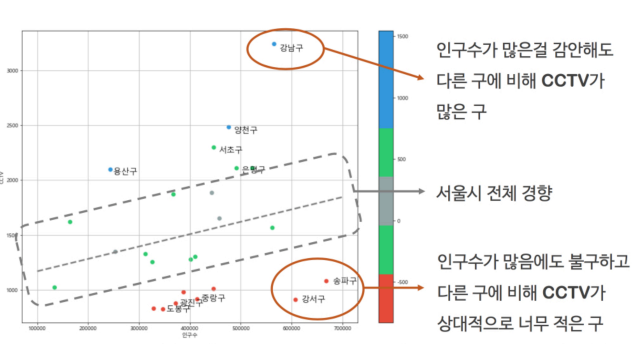
서울시 CCTV 분석
📌 목표
📌데이터 얻기
- 서울시 구별 CCTV 현황 데이터: data.seoul.go.kr
- 당연히 인구 현황 데이터: 서울 열린 데이터 광장 - 데이터 이용하기 - 오픈 API 서비스
📌데이터 읽기
💡2-1. csv 읽어오기
📍read_csv()
경로에 있는 csv 파일을 가져와 읽는다.
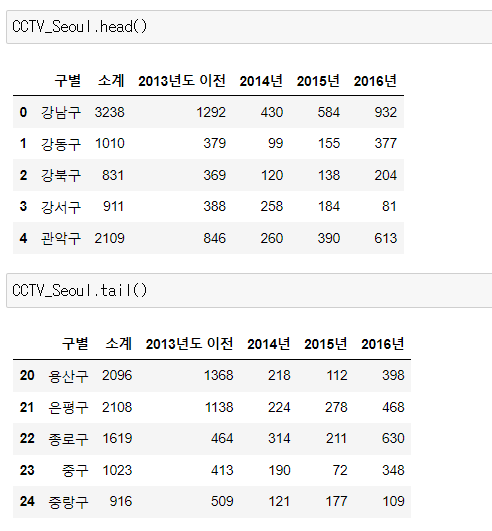
CCTV_Seoul = pd.read_csv("../data/01. Seoul_CCTV.csv", encoding="utf-8")📍head()
- 변수명.head(n): 상단에 있는 n개의 데이터를 보여준다. (default=5)
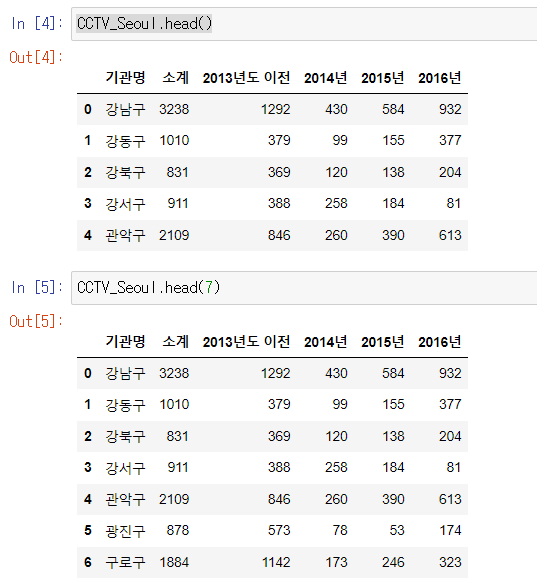
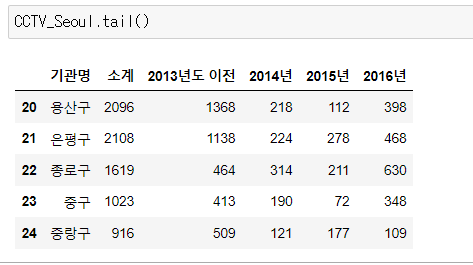
📍tail()
- 변수명.tail(n): 끝에 있는 n개의 데이터를 보여준다. (default=5)
내가 가진 데이터를 전체 개수를 파악할 수 있다.
📍columns
데이터의 컬럼명을 리스트 형태로 반환
즉, 인덱스로 하나하나 데이터를 가져올 수 있다.

📍rename()
컬럼명 변경
- 원본 변경 X
CCTV_Seoul.rename(columns={CCTV_Seoul.columns[0]: "구별"})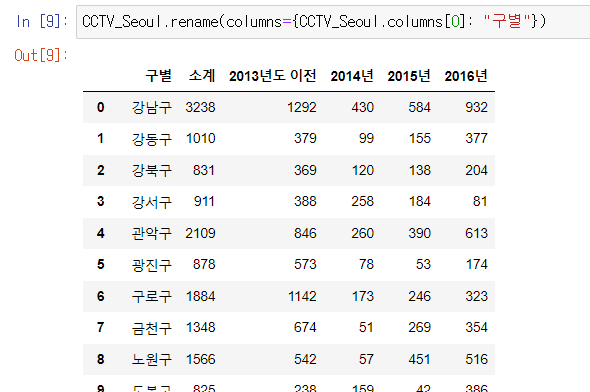
- 원본 변경 O
inplace="True"를 해야지 원본이 변경된다.
CCTV_Seoul.rename(columns={CCTV_Seoul.columns[0]: "구별"}, inplace="True")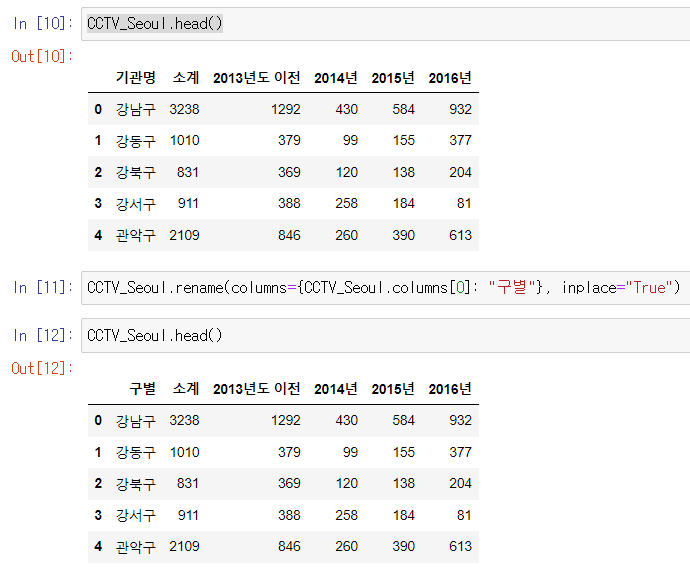
💡2-2. excel 읽어오기
📍read_excel()
경로에 있는 excel 파일을 가져와 읽는다.
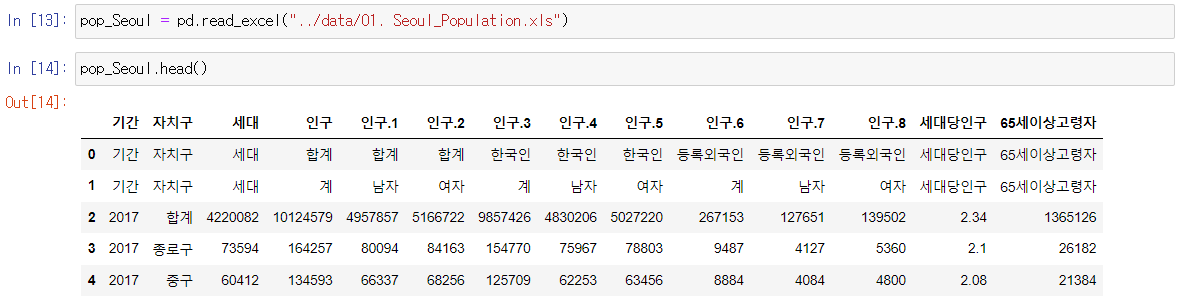
pop_Seoul = pd.read_excel("../data/01. Seoul_Population.xls")- 상단에 있는 0, 1 인덱스는 필요없는 데이터
pop_Seoul = pd.read_excel(
"../data/01. Seoul_Population.xls", header=2, usecols="B, D, G, J, N"
)
pop_Seoul.head()- 원하는 형태의 데이터 가져오기
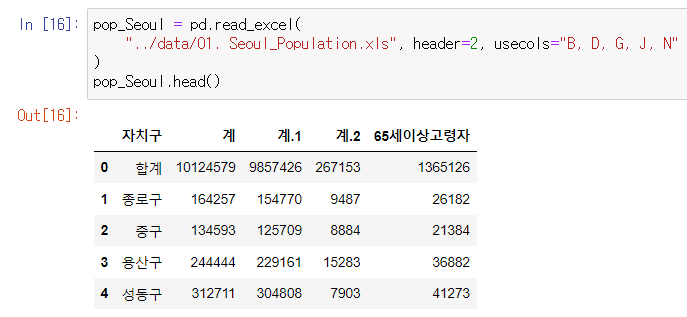
- header: 자료를 읽기 시작할 행
header = 2: 2줄(0,1)빼고 2번째 줄부터 가져와라. - usecols: 읽어올 엑셀의 컬럼을 지정
usecols='B, D, G, J, N': B, D, G, J, N 컬럼 데이터만 가져와라
📍rename()
컬럼명 변경
pop_Seoul.rename(
columns={
pop_Seoul.columns[0]: "구별",
pop_Seoul.columns[1]: "인구수",
pop_Seoul.columns[2]: "한국인",
pop_Seoul.columns[3]: "외국인",
pop_Seoul.columns[4]: "고령자",
},
inplace=True
)
pop_Seoul.head()
📌CCTV 적은 구, 많은 구
📍sort_values()
- CCTV 적은 구 5개
소계 컬럼 기준, 오름차순 정렬(디폴트), 상위 5개 선택
CCTV_Seoul.sort_values(by="소계", ascending=True).head(5)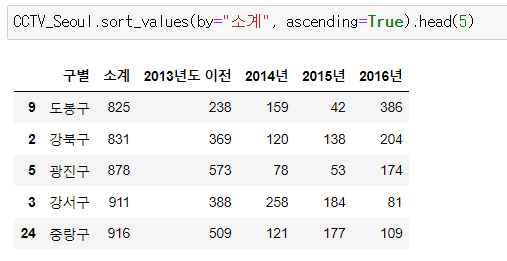
- CCTV 많은 구 5개
소계 컬럼 기준, 내림차순 정렬, 상위 5개 선택
CCTV_Seoul.sort_values(by="소계", ascending=False).head(5)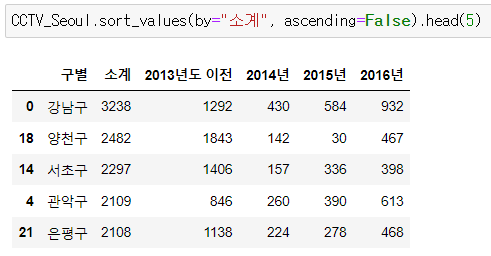
📌최근증가율
📍컬럼 추가
- 기존 컬럼이 없으면 추가
- 기존 컬럼이 있으면 수정
- 최근 3년간 이전 CCTV 보유 대비 증가율 정보
# 기존 컬럼이 없으면 추가, 있으면 수정
CCTV_Seoul["최근증가율"] = (
(CCTV_Seoul["2016년"] + CCTV_Seoul["2015년"] + CCTV_Seoul["2014년"]) / CCTV_Seoul["2013년도 이전"] * 100
)
CCTV_Seoul.sort_values(by="최근증가율", ascending=False).head(5)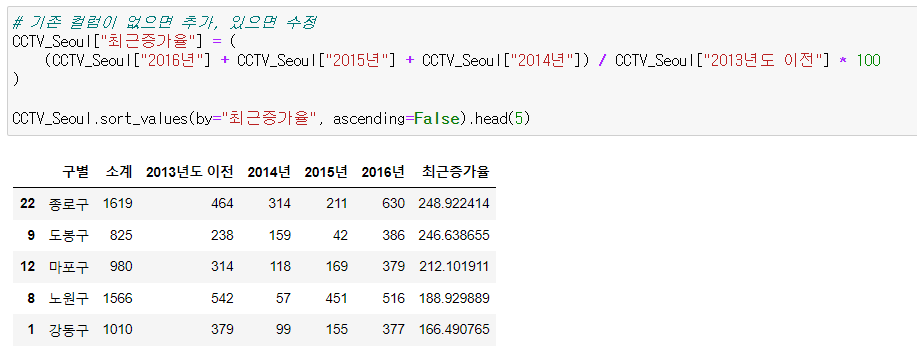
📌인구현황 데이터
📍drop()
- 0번 인덱스 데이터는 필요 없으므로 제거
pop_Seoul.drop([0], axis=0, inplace=True)
pop_Seoul.head()
📍unique()
중복 없이 고유한 데이터가 어떤 것인지 나타남
pop_Seoul["구별"].unique()
len(pop_Seoul["구별"].unique())
📌외국인 비율, 고령자 비율
# 외국인 비율, 고령자 비율
pop_Seoul["외국인비율"] = pop_Seoul["외국인"] / pop_Seoul["인구수"] * 100
pop_Seoul["고령자비율"] = pop_Seoul["고령자"] / pop_Seoul["인구수"] * 100
pop_Seoul.head()
📌 정렬
📍인구수 정렬
인구수가 많은 구 내림차순 정렬
pop_Seoul.sort_values(["인구수"], ascending=False).head()
📍외국인 정렬
외국인이 많은 구 내림차순 정렬
pop_Seoul.sort_values(["인구수"], ascending=False).head()
📍외국인비율 정렬
외국인비율이 많은 구 내림차순 정렬
pop_Seoul.sort_values(["외국인비율"], ascending=False).head()
📍고령자 정렬
고령자가 많은 구 내림차순 정렬
pop_Seoul.sort_values(["고령자"], ascending=False).head()
📍고령자비율 정렬
고령자비율이 많은 구 내림차순 정렬
pop_Seoul.sort_values(["고령자비율"], ascending=False).head()
📌Pandas 데이터 합치기
📍CCTV_Seoul, pop_Seoul 병합
data_result = pd.merge(CCTV_Seoul, pop_Seoul, on="구별")
data_result.head()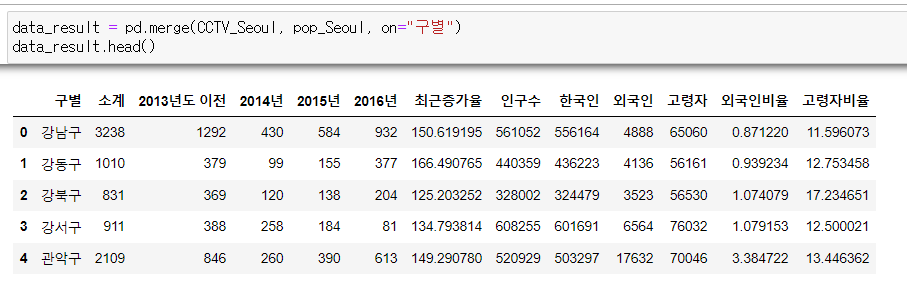
📌년도별 데이터 컬럼 삭제
- del
- drop
📍del
- 사용 방법
del 데이터["지우고 싶은 데이터 컬럼명"]
del data_result["2013년도 이전"]
data_result.head()
del data_result["2014년"]
data_result.head(3)
📍drop
- 사용 방법
컬럼(열) 삭제:데이터.drop(["지우고 싶은 데이터 컬럼명"], axis=1)
행 삭제:데이터.drop(["지우고 싶은 인덱스"], axis=0)
💡즉시 지우려면 inplace=True 추가
data_result.drop(["2015년", "2016년"], axis=1, inplace=True)
data_result.head()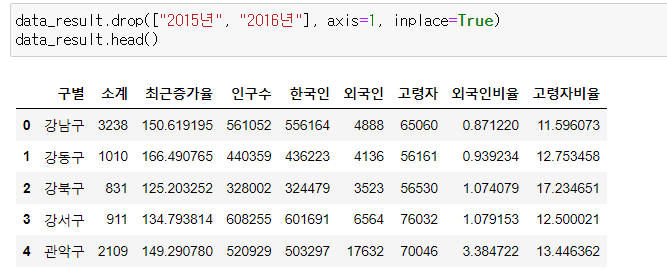
📌인덱스 변경
- set_index()
- 선택한 컬럼을 데이터 프레임의 인덱스로 지정
data_result.set_index("구별", inplace=True)
data_result.head()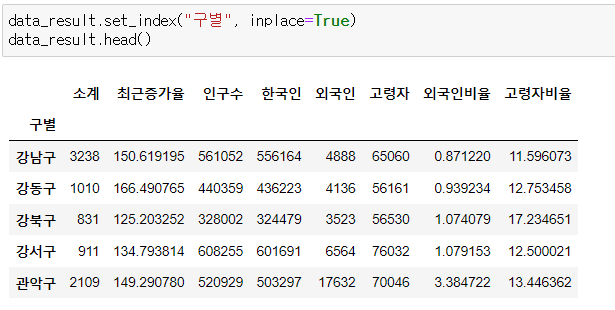
📌상관계수
- corr()
- correlation의 약자
- 상관계수가 0.2 이상인 데이터를 비교
- 연산을 할 수 있는 integer or float 타입 형태만 가능(object(문자) 데이터가 있으면 해당 데이터는 연산 되지 않음)
data_result.corr()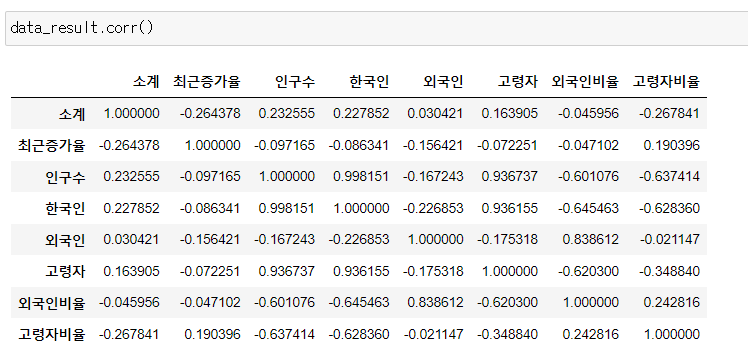
📌CCTV비율
📍CCTV비율 컬럼 추가
data_result["CCTV비율"] = data_result["소계"] / data_result["인구수"]
data_result["CCTV비율"] = data_result["CCTV비율"] * 100
data_result.head()
📍CCTV비율 정렬
- CCTV비율이 높은 구 순서로 정렬
data_result.sort_values(by="CCTV비율", ascending=False).head()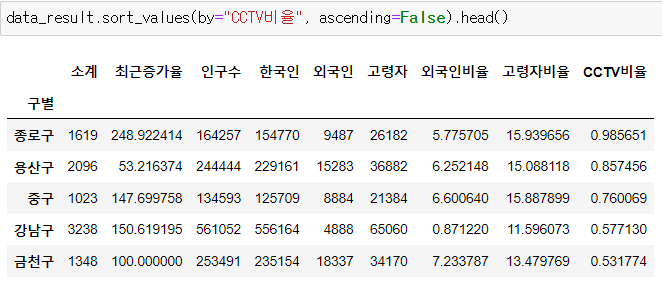
- CCTV비율이 낮은 구 순서로 정렬
data_result.sort_values(by="CCTV비율", ascending=True).head()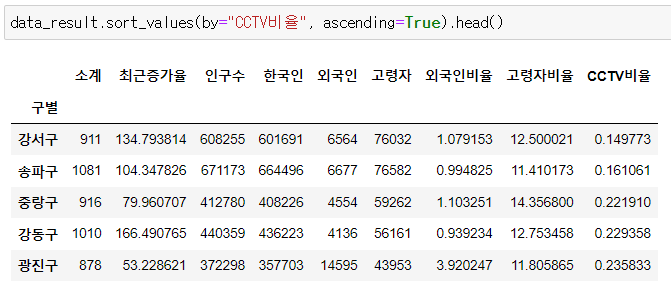
"이 글은 제로베이스 데이터 취업 스쿨 강의 자료 일부를 발췌한 내용이 포함되어 있습니다."
