📌selenium 설치
-
Window, mac(intel)
- conda install selenium
-
mac(M1)
- pip install selenium
- chromedriver 설치
- chrome web > 오른쪽 상단 점 3개 > 도움말 > chrome 정보
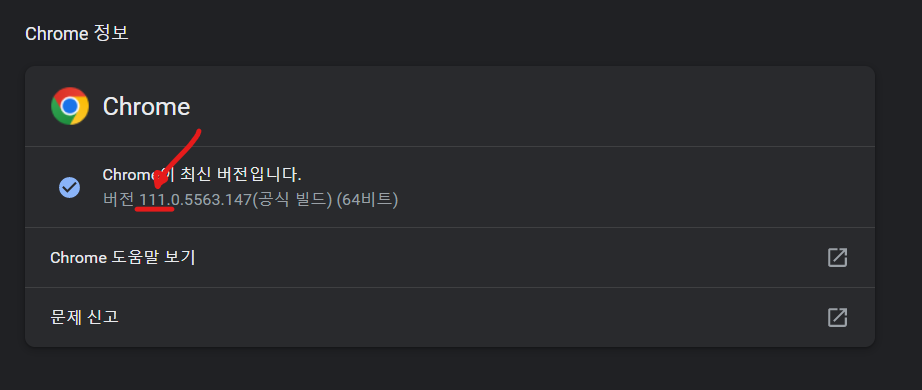
버전 앞 큰 수만 기억하기
- Google -> chrome driver download 검색
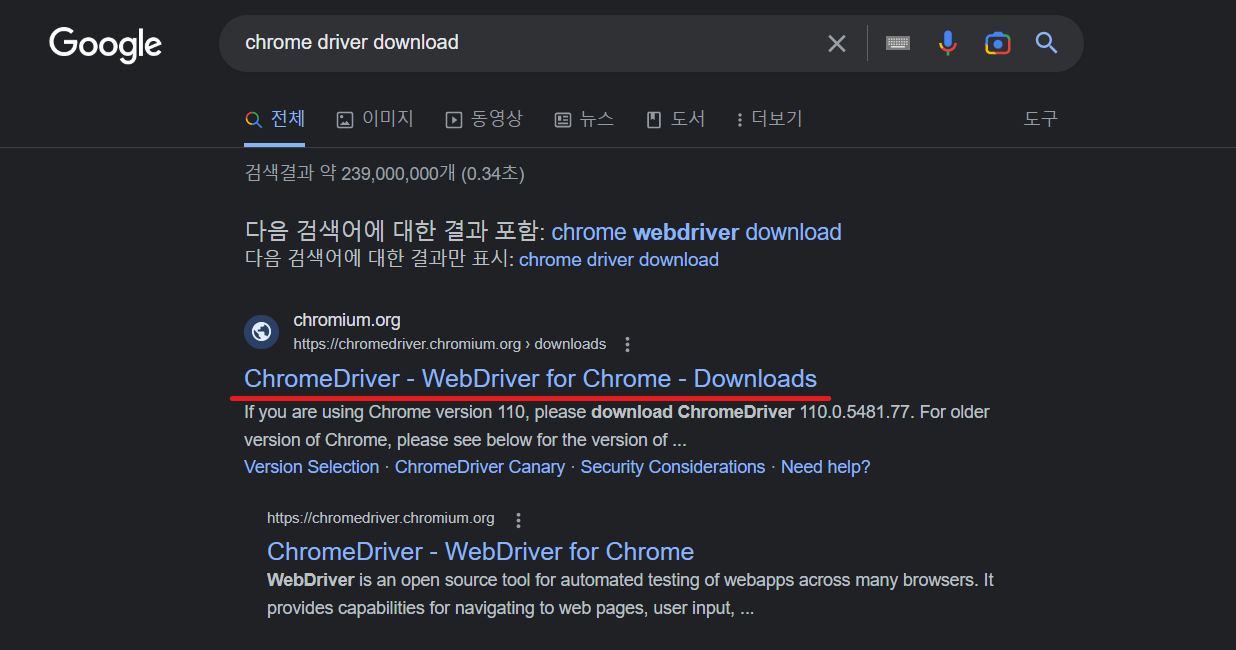
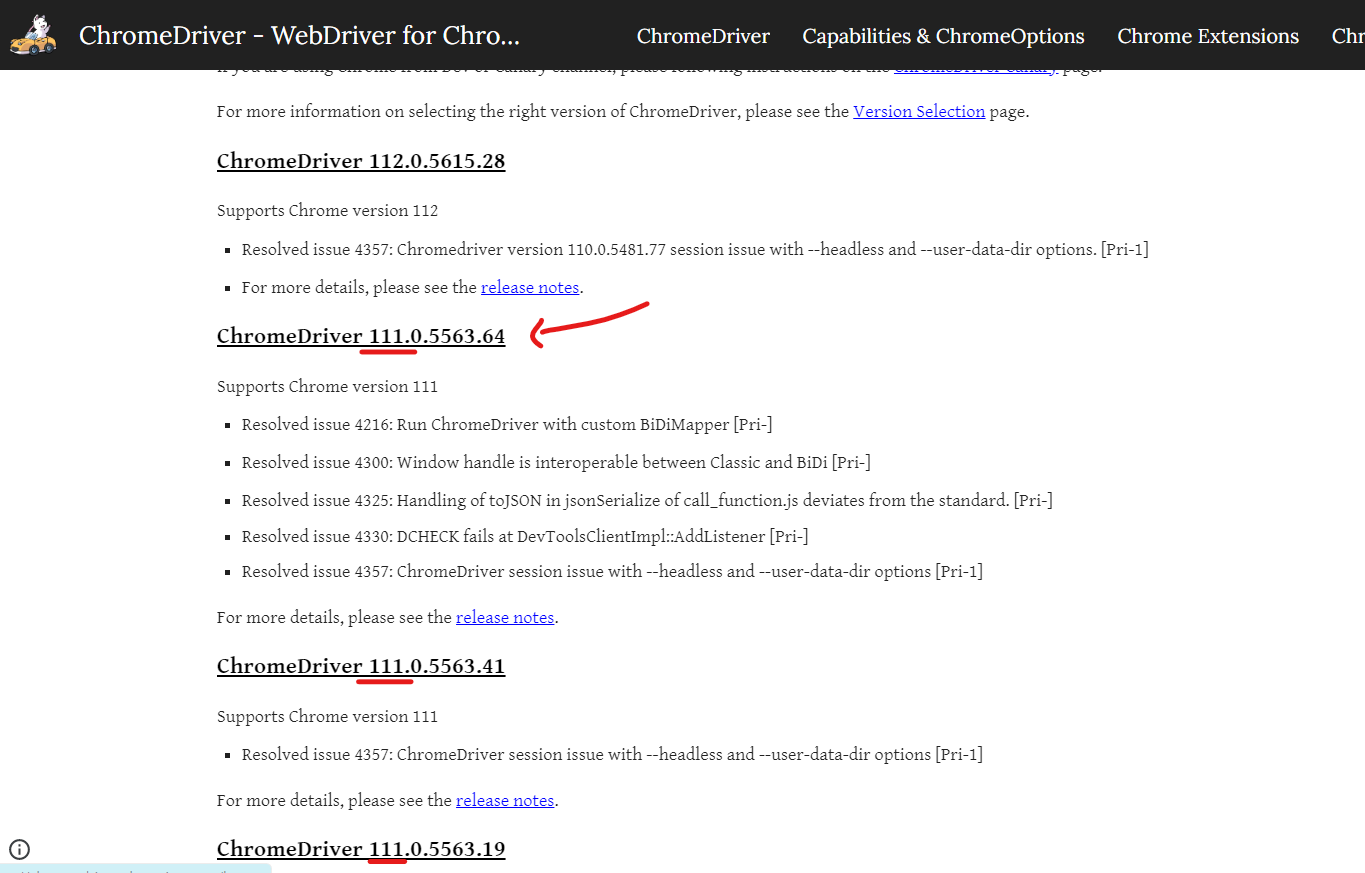
- 앞 번호가 같은 버전 다운로드(뒷 번호는 상관 없다.)
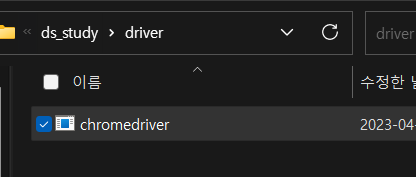
- ds_study 파일에 driver 폴더 생성 후 저장
📌selenium
- 웹브라우저를 원격 조작하는 도구
- 자동으로 URL을 열고 클릭 등이 가능
- 스크롤, 문자의 입력, 화면 캡처 등등
BeautifulSoup만으로 해결할 수 없는 것
- 접근할 웹 주소를 알 수 없을 때
- 자바스크립트를 사용하는 웹페이지의 경우
- 웹 브라우저로 접근하지 않으면 안될 때
- 동적 페이지(서버 내부에 변화가 일어남)
스크롤을 내리니 코드가 더 늘어나는 것을 볼 수 있다.
📍selenum webdriver 사용
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome("../driver/chromedriver.exe")
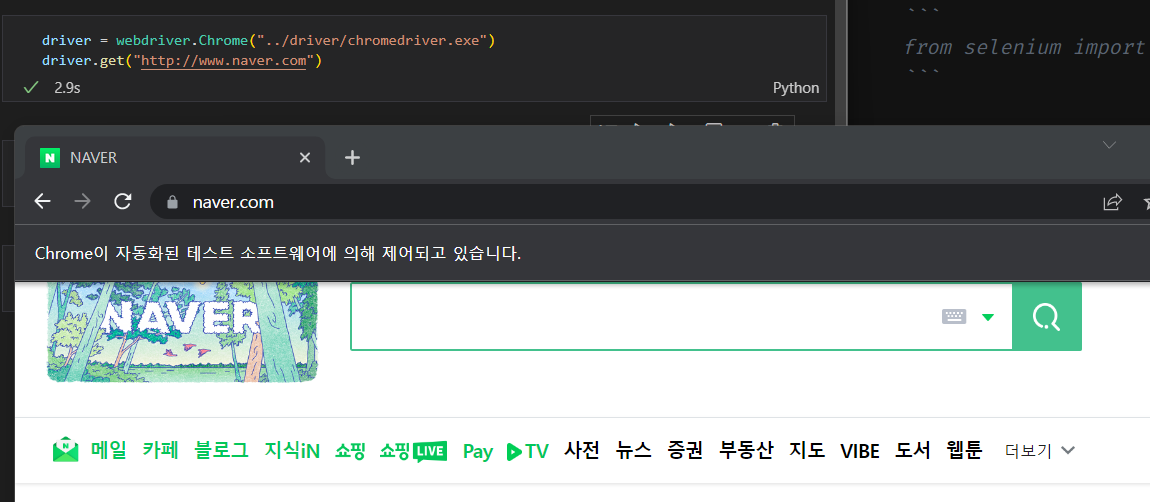
driver.get("https://www.naver.com")새로운 웹 브라우저가 생성되면 설치 완료 된 것
맥은 권한 설정 필요
꼭 quit을 이용하여 종료해줘야 한다. 아니면 여러 창이 아래 생성 되어 있을 수 있음
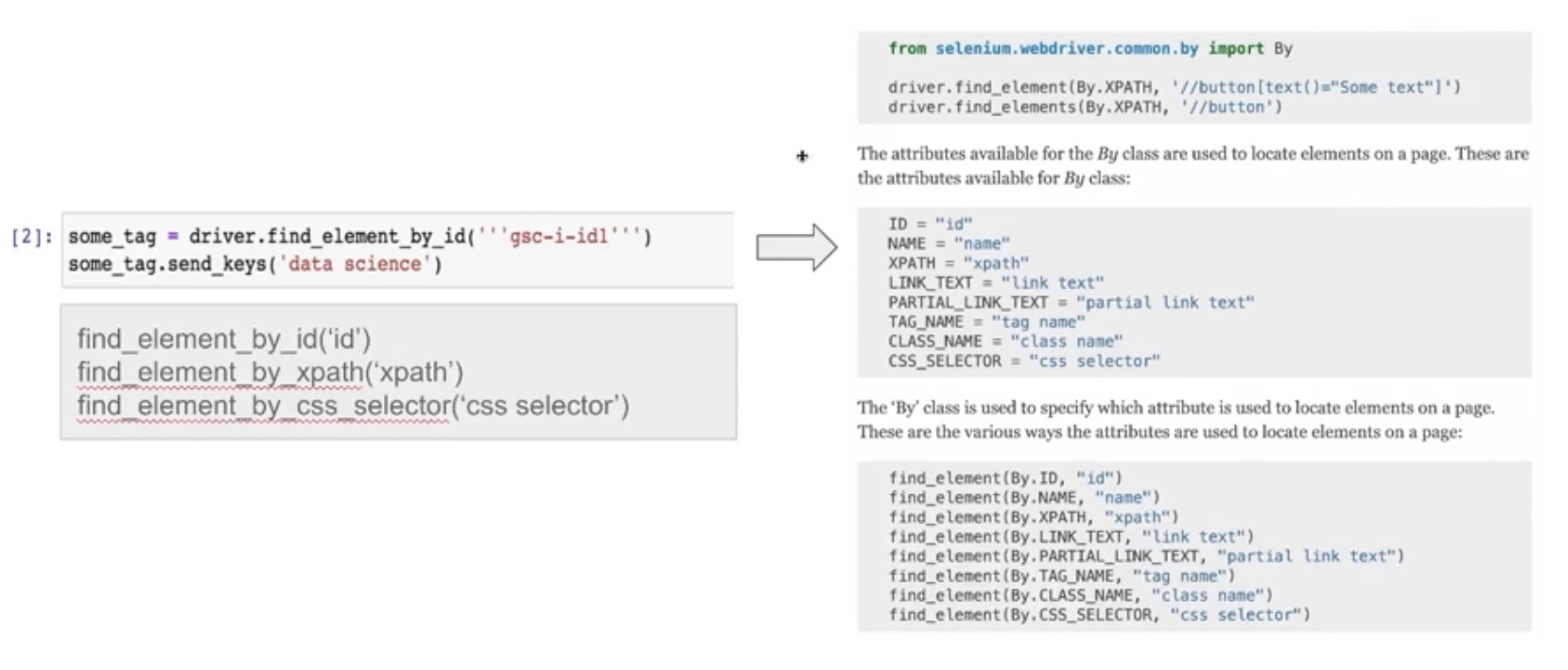
driver.quit()📍문법 변경 사항
왼쪽 문법에서 오른쪽 문법으로 변경되었으니 잘 숙지해야한다.
📍기본 동작
- 화면 최대 크기 설정
페이지의 태그에서 데이터를 가져 올 때 화면의 크기가 작거나 스크롤로 인해 데이터가 화면에 나타나지 않는 경우 해당 태그가 존재하고 있지 않을 수가 있다.
따라서 화면 크기를 크게 설정하면 도움이 될 수 있다.
driver.maximize_window()-
크기 조절 전
-
크기 조절 후
- 화면 최소 크기 설정
driver.minimize_window()- 화면 크기 설정
driver.set_window_size(600, 600)
- 새로 고침
driver.refresh()- 뒤로 가기
driver.back()- 앞으로 가기
driver.forward()- 클릭
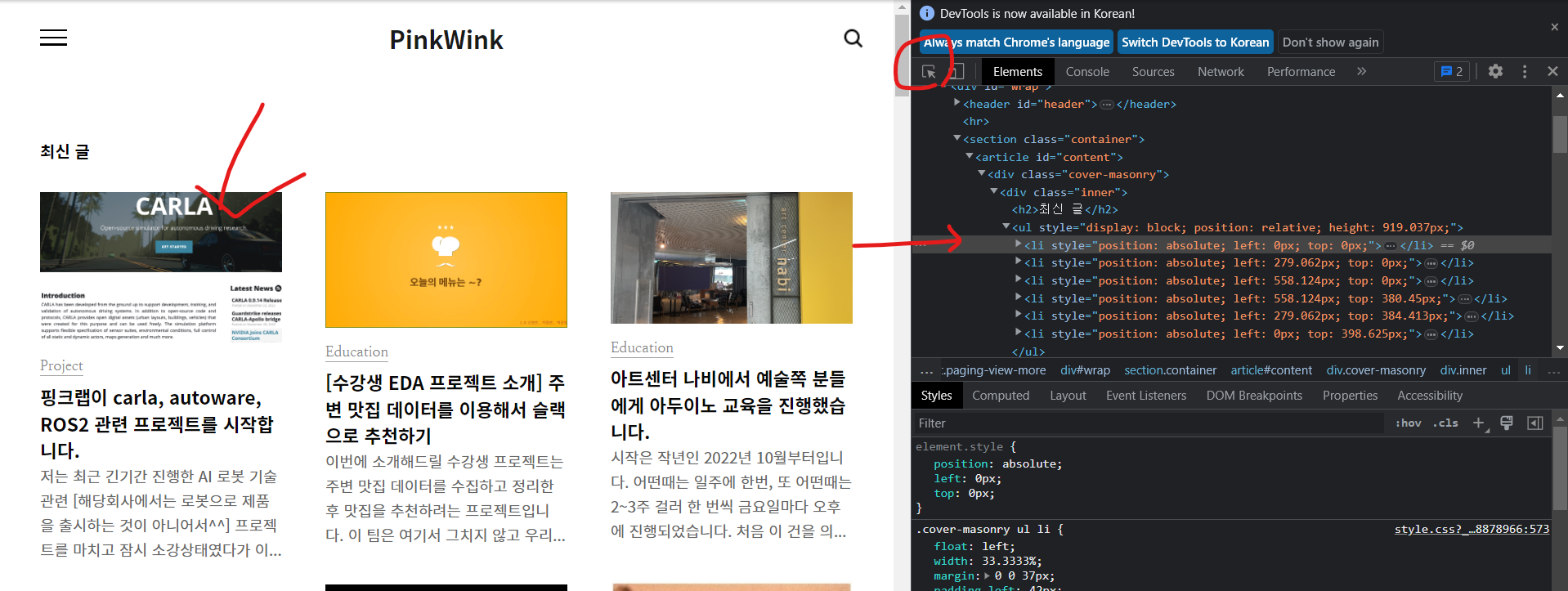
해당 태그에서 오른쪽 클릭 > copy > copy selector
from selenium.webdriver.common.by import By
first_content = driver.find_element(By.CSS_SELECTOR, "#content > div.cover-masonry > div > ul > li:nth-child(1)")
first_content.click()-
클릭 전
-
클릭 후
- 새로운 탭 생성
driver.execute_script('window.open("https://www.naver.com/")') # 자바 스크립트 코드 사용
- 탭
- 탭 개수 확인
len(driver.window_handles)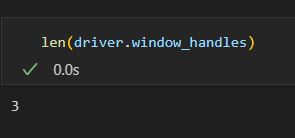
- 탭 이동
driver.switch_to.window(driver.window_handles[1])- 탭 닫기
driver.close()
- 웹 닫기
최종적으로 quit을 잘 해줘야한다. 안그러면 컴퓨터 자원을 계속 사용하고 있어 컴퓨터가 다운될 수 있다.
driver.quit()📍화면 스크롤
- driver.execute_script()
()안에 자바스크립트 언어를 이용하겠다.
- 스크롤 가능한 높이(길이)
- 스크롤 가능한 높이(길이)
- 자바 스크립트 코드 실행
- 화면 크기에 따라 달라짐
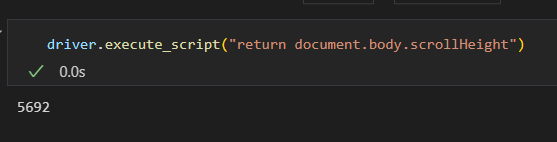
driver.execute_script("return document.body.scrollHeight")document(=html)에서 body 태그에서 전체 스크롤 할 수 있는 크기를 반환해라
- 화면 스크롤 하단 이동
driver.execute_script('window.scrollTo(0, document.body.scrollHeight)')- 화면 스크롤 상단 이동
driver.execute_script('window.scrollTo(0, 0)')- 현재 보이는 화면 스크린샷 저장
driver.execute_script('window.scrollTo(0, document.body.scrollHeight)')

현재 화면이 저장되었다.
- 특정 태그 지점까지 스크롤 이동
from selenium.webdriver import ActionChains
some_tag = driver.find_element(By.CSS_SELECTOR, '#content > div.cover-list > div > ul > li:nth-child(1)')
action = ActionChains(driver)
action.move_to_element(some_tag).perform()📍검색어 입력
📍CSS_SELECTOR
from selenium import webdriver # selenium을 이용하여 크롬 제어하기 위함
from selenium.webdriver.common.by import By # 태그 선택 위함driver = webdriver.Chrome("../driver/chromedriver.exe")
driver.get("https://www.naver.com/")- 검색어 입력
keyword = driver.find_element(By.CSS_SELECTOR, "#query")
keyword.clear() # 원래 있던 검색어 지움
keyword.send_keys('딥러닝')
- 검색 버튼 클릭
search_btn = driver.find_element(By.CSS_SELECTOR, "#search_btn")
search_btn.click()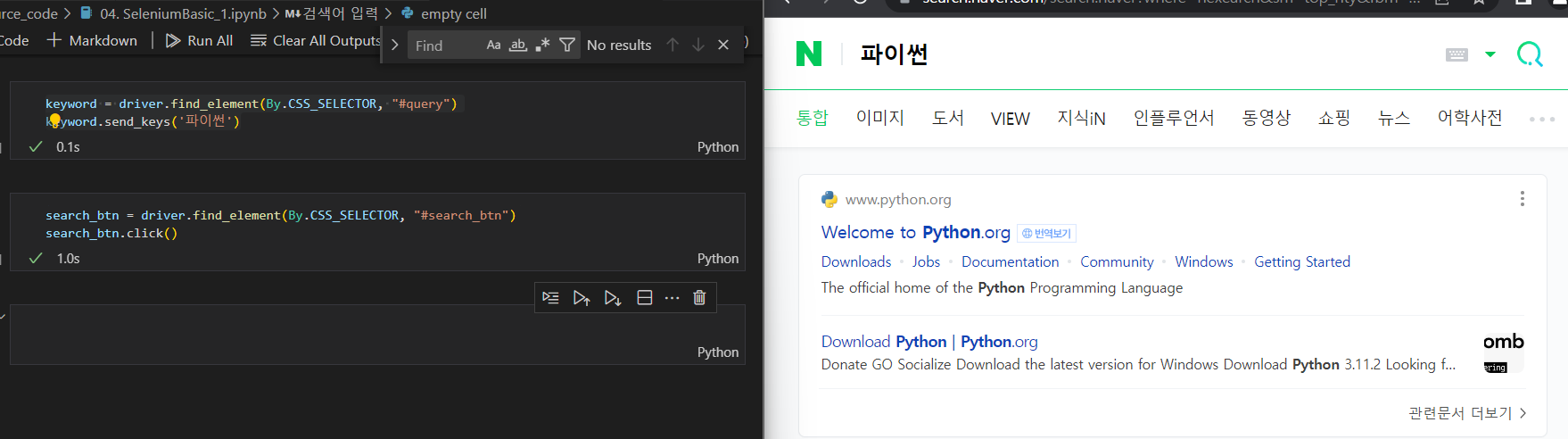
📍XPATH
CSS_SELECTOR와 동일하지만 TAG 찾는 방법만 조금 달라짐
BeautifulSoup에서는 사용 불가능, selenium에서만 사용 가능
'//': 최상위
'*': 자손 태그 -> ex. 태그 두개 아래 있는 태그
'/': 자식 태그 -> 태그 바로 밑
'div[1]': div 중에서 1번째 태그
해당 태그에서 오른쪽 클릭 > copy > copy XPath
- 검색어 입력
driver.find_element(By.XPATH, '//*[@id="query"]').send_keys('xpath')- 클릭
driver.find_element(By.XPATH, '//*[@id="search_btn"]').click()📍검색어 입력 연습
from selenium import webdriver # selenium을 이용하여 크롬 제어하기 위함
from selenium.webdriver.common.by import By # 태그 선택 위함driver = webdriver.Chrome("../driver/chromedriver.exe")
driver.get("https://pinkwink.kr/")1. 돋보기 버튼 클릭
처음 웹 화면에 검색어 입력창이 나타나지 않고 돋보기를 클릭했을 때 검색창이 나타난다. 하지만 돋보기 버튼 클릭을 했을 때 에러가 발생
driver.find_element(By.CSS_SELECTOR, "#header > div.search").click()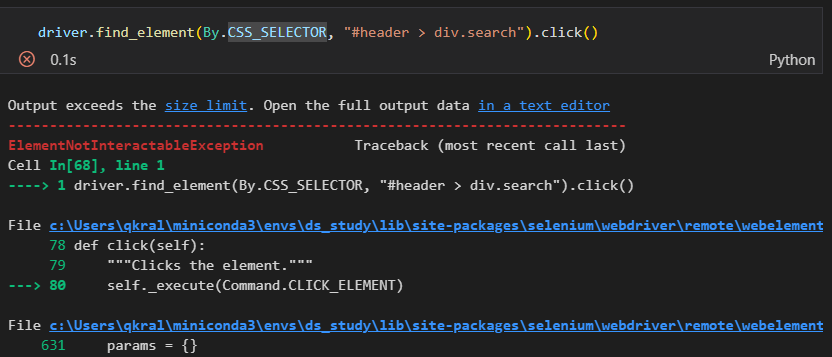
그렇다면 input 태그에 바로 검색어를 입력하는 것은 가능한지 실험을 해보자.
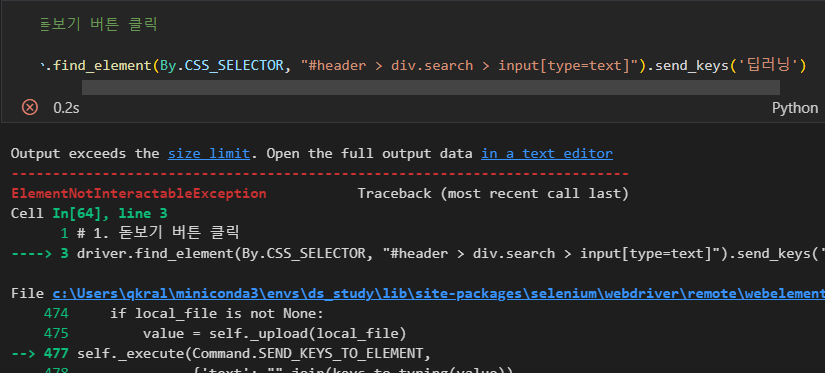
안된다. 그렇다면 직접 돋보기를 클릭한 후 검색을 해보면 작동 된다.
-
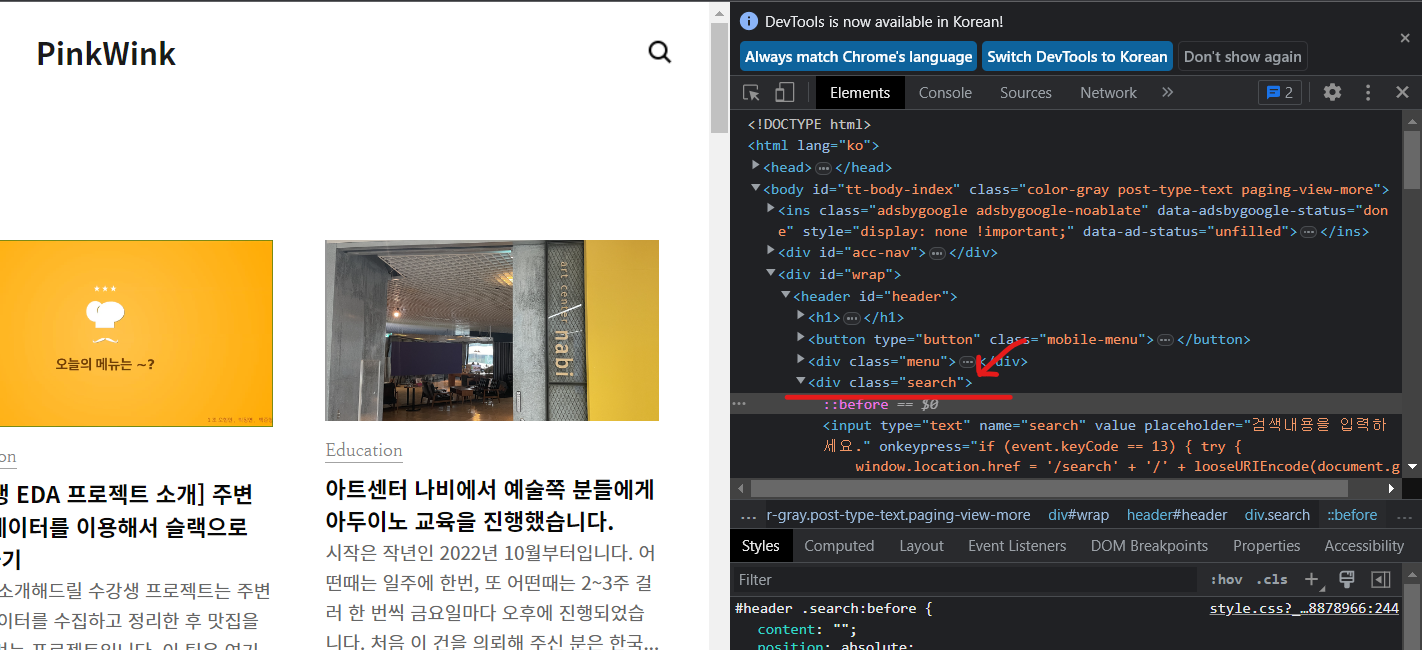
돋보기 클릭 전(search)
-
돋보기 클릭 후(search on )
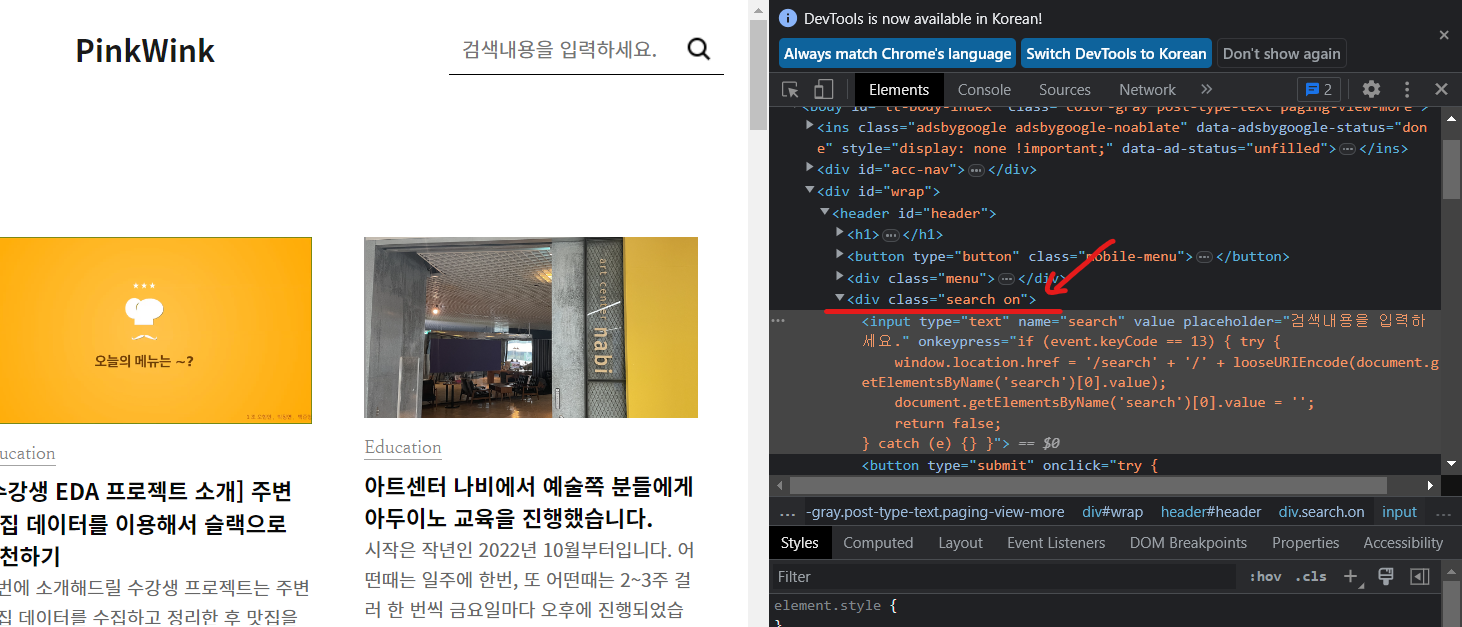
돋보기 클릭 전과 클릭 후 class 이름이 변화하는 것을 볼 수 있다.
이것은 동적 페이지 기능 중 하나이다. -> 일반적인 방식으로 동작하지 않는다.

- 동적 페이지에서 돋보기 클릭
from selenium.webdriver import ActionChains
search_tag = driver.find_element(By.CSS_SELECTOR, '.search')
action = ActionChains(driver)
action.click(search_tag)
action.perform()위와 같이 작성하면 잘 동작한다.
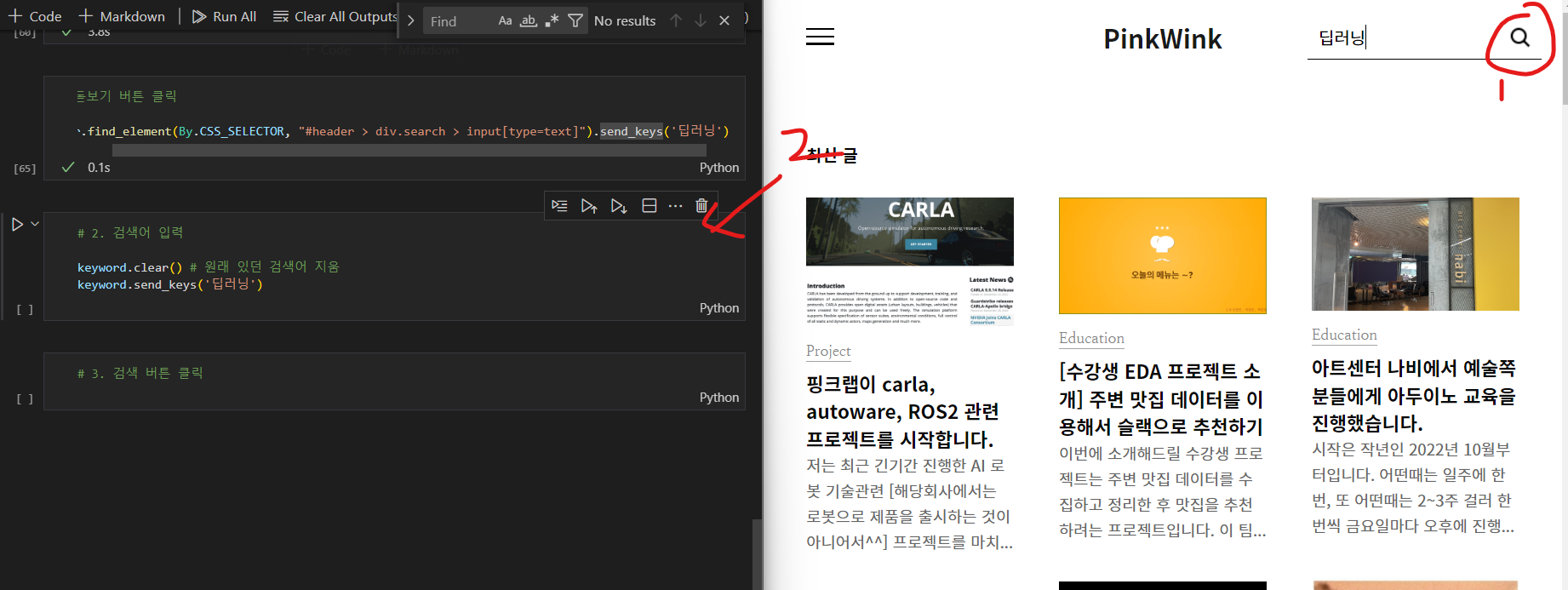
2. 검색어 입력
driver.find_element(By.CSS_SELECTOR, "#header > div.search > input[type=text]").send_keys('딥러닝')
3. 검색 버튼 클릭
driver.find_element(By.CSS_SELECTOR, "#header > div.search.on > button").click()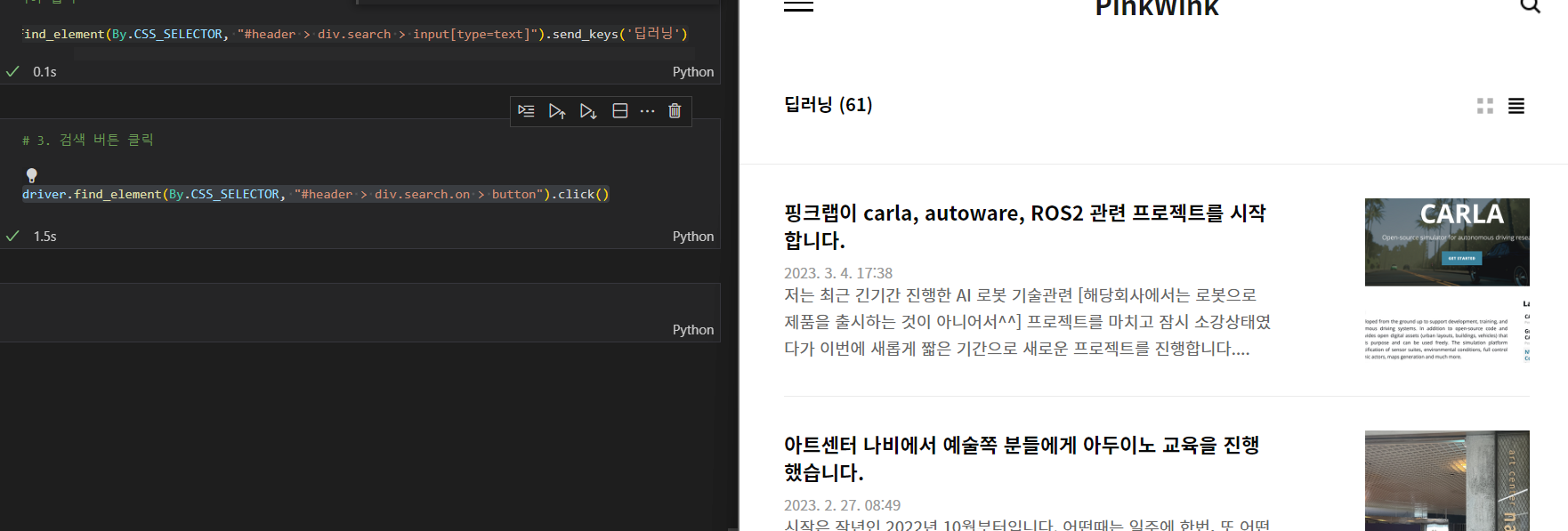
📌selenium + BeautifulSoup
최종적으로 사용하고자하는 데이터가 selenium을 이용해서 동작해야지만 나오는 부분까지 이동한 다음 그 상태에서 BeautifulSoup을 이용해 가져오는 작업
- page_source
현재 화면의 html 코드 가져오기
driver.page_source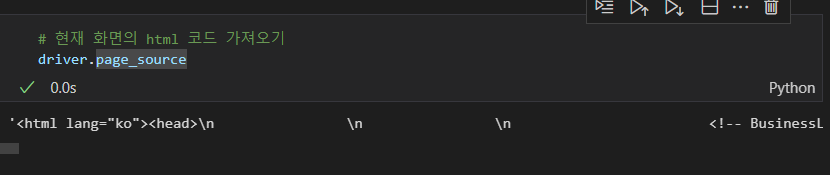
from bs4 import BeautifulSoup
req = driver.page_source
soup = BeautifulSoup(req, "html.parser")- 확인하기
soup.select('.post-item')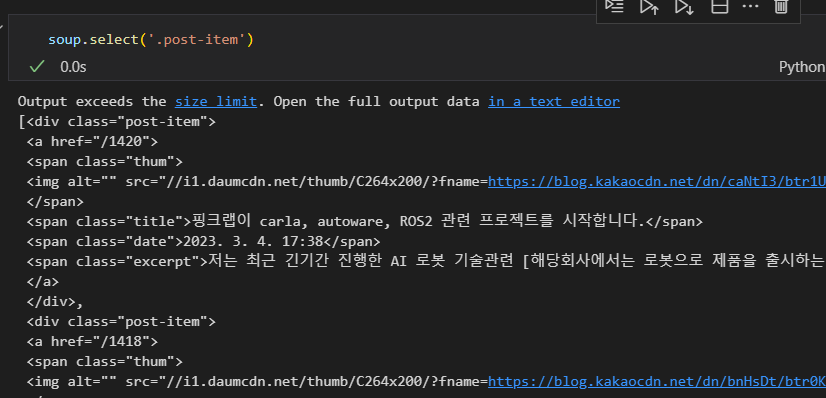
contents = soup.select('.post-item')
len(contents)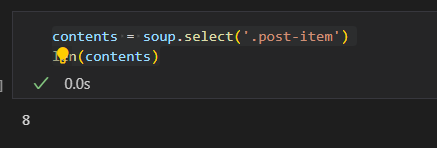
contents[2] # 두 번째 컨텐츠 가져오기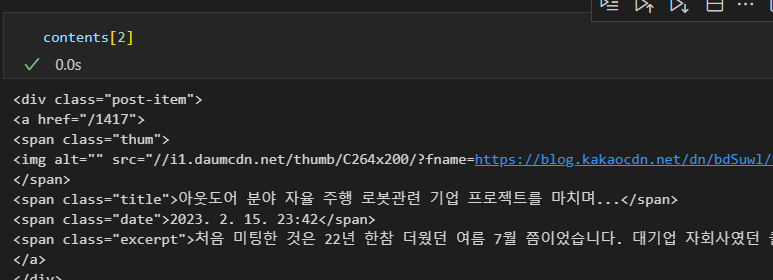
"이 글은 제로베이스 데이터 취업 스쿨 강의를 듣고 작성한 내용으로 제로베이스 데이터 취업 스쿨 강의 자료 일부를 발췌한 내용이 포함되어 있습니다."
