📌다음 영화 평점 사이트 분석
원래 강의에서는 네이버 영화 평점 사이트로 분석을 하는데 230331일 부로 네이버 영화 평점 사이트 운영 종료....ㅠㅠ
네이버를 할 수 없으니 강의를 보면서 다음 영화 평점 사이트로 대체 해보기로 했다.
좀 다른데 잘 될지는 모르겠지만 스스로 해보면 더 늘겠지;)
📌영화 평점 사이트 분석, 데이터 추출
1. 다음 영화 평점 사이트 분석
-
영화 랭킹 탭 이동
-
영화 랭킹에서 평점순(현재 상영 영화) 선택
-
https://movie.daum.net/ranking/boxoffice/weekly?date=20230321
-
웹 페이지 주소에는 많은 정보가 담겨있다.
-
원하는 정보를 얻기 위해서 변화시켜줘야하는 주소의 규칙을 찾을 수 있다.
-
여기에서는 날짜 정보를 변경해주면 해당 페이지에 접근이 가능하다.
2. 페이지 가져오기
# requirements
import pandas as pd
from urllib.request import urlopen
from bs4 import BeautifulSoupurl = "https://movie.daum.net/ranking/boxoffice/weekly?date=20230404"
response = urlopen(url)
# 이 웹 페이지는 유저 헤더 정보를 주지 않아도 바로 응답해줌
# response.status
soup = BeautifulSoup(response, "html.parser")
print(soup.prettify())
🤔문제점
찾아야 하는 것 -> 영화 제목, 평점
네이버 평점 사이트는 랭킹 메인 화면에 제목, 평점이 나와있는데 다음은 영화 제목, 개봉일이 나와있다. 영화 상세 페이지에 접근해야만 평점이 나온다.
앞서 시카고 매거진 처럼 해봐야지...ㅠ
3. 필요 데이터 추출 - 랭킹페이지
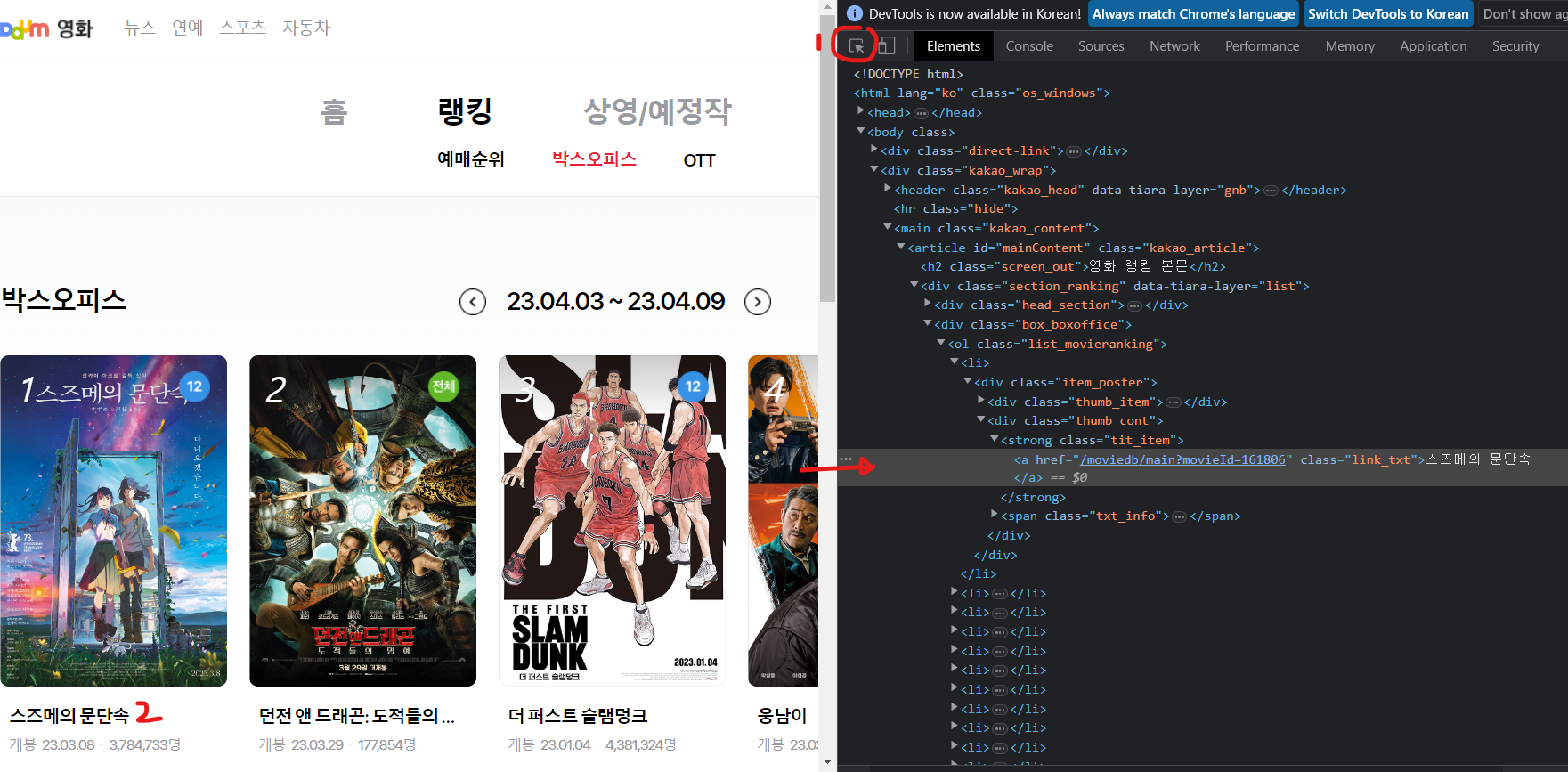
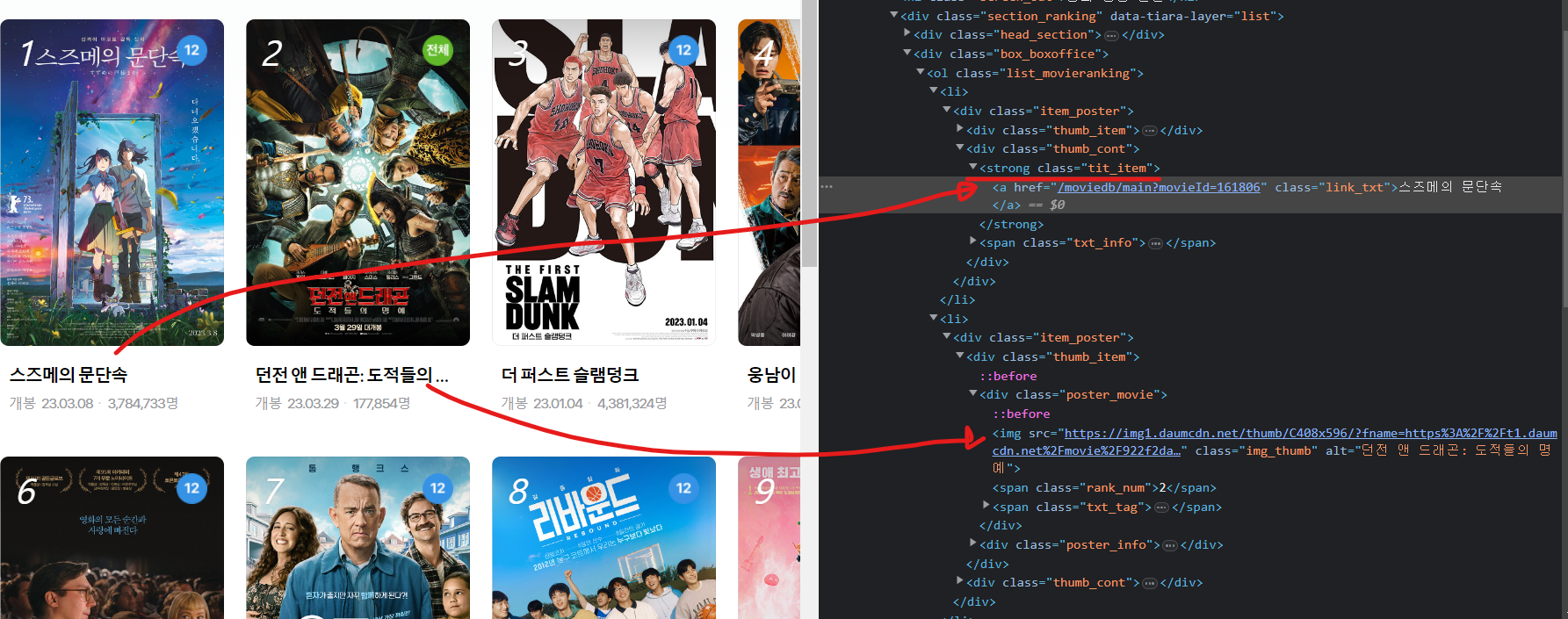
- 영화 제목 추출 테스트
다양한 방법들이 있다.

- 영화 상세페이지 URL 추출 테스트
soup.select("strong.tit_item")[0].a["href"]
- 원하는 데이터 추출
end = len(soup.select("strong.tit_item"))
base_url = "https://movie.daum.net"
movie_name = []
movie_url = []
for n in range(0, end):
movie_name.append(soup.select("strong.tit_item")[n].a.string)
movie_url.append(base_url + soup.select("strong.tit_item")[n].a["href"]) 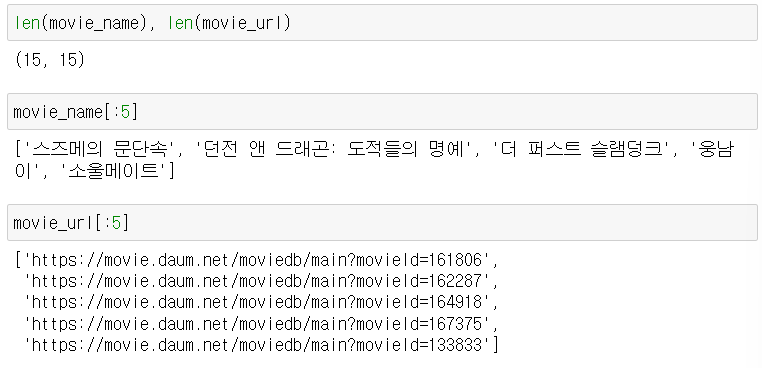
4. DataFrame 생성 및 저장
영화제목, URL을 DataFrame에 담자
import pandas as pd
data = {
"Movie": movie_name,
"URL": movie_url,
}
df = pd.DataFrame(data)
df
5. 영화 상세 페이지 가져오기
네이버 영화에서는 평점이 랭킹에 있었지만 다음은 없기 때문에 상세 페이지에 접근해서 가져오도록 하자.
req = urlopen(df["URL"][0])
# 이 웹 페이지는 유저 헤더 정보를 주지 않아도 바로 응답해줌
req.status
soup = BeautifulSoup(req, "html.parser")
print(soup.prettify())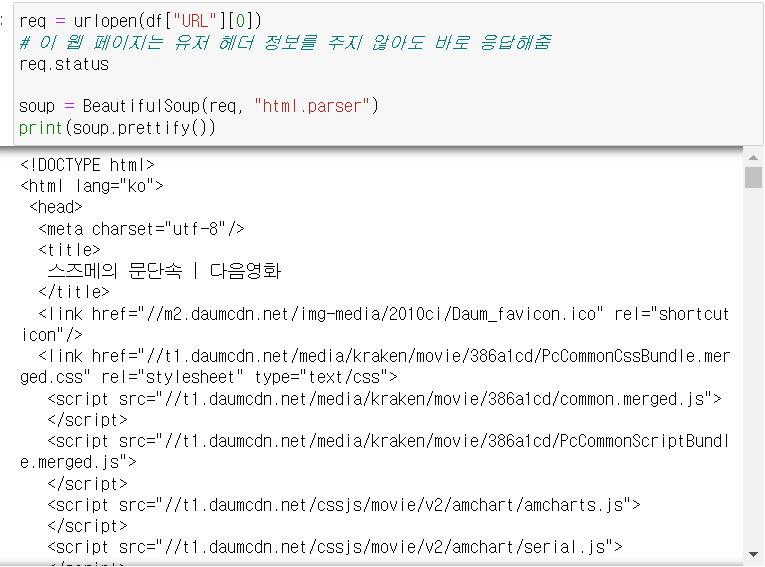
6. 상세 페이지 데이터 추출 - 평점
- 평점 추출 테스트
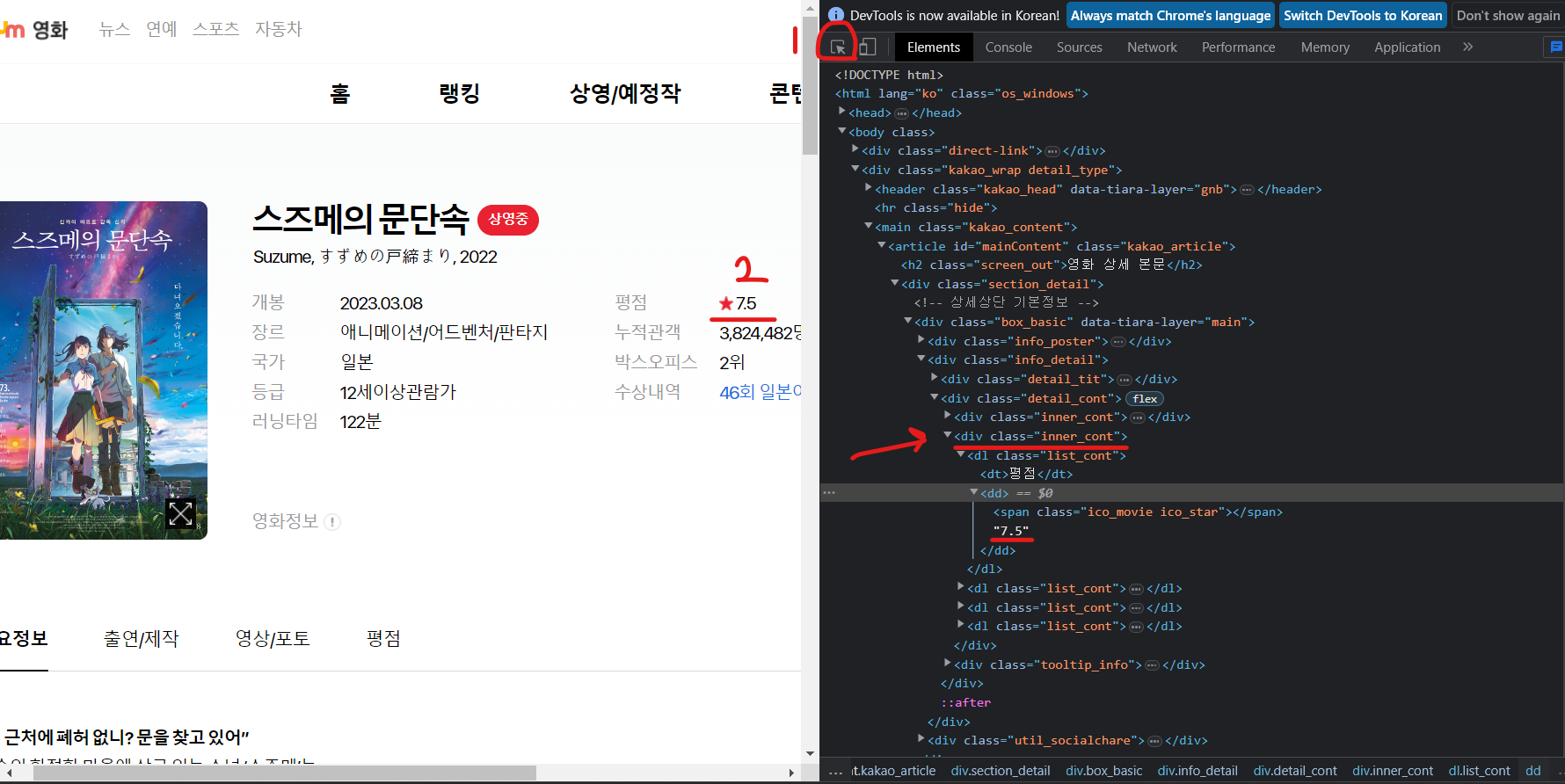
movie_star = soup.select(".inner_cont")[1].select_one("dd").text
movie_star- 랭킹 평점 추출
end = len(soup.select("strong.tit_item"))
movie_star =[]
for n in range(0, end):
req = urlopen(df["URL"][n])
soup_req = BeautifulSoup(req, "html.parser")
movie_star.append(soup_req.select(".inner_cont")[1].select_one("dd").text)
movie_star
7. 자동화를 위한 코드
https://movie.daum.net/ranking/boxoffice/weekly?date=20230404
날짜만 변경하면 우리가 원하는 기간 만큼 데이터를 얻을 수 있다.
- 날짜 데이터 생성
date = pd.date_range("2022.12.22", periods=100, freq="D") # 하루기준
date
- 날짜 원하는 형태로 변경
date[0].strftime("%Y-%m-%d")
date[0].strftime("%Y.%m.%d")
date[0].strftime("%Y%m%d")
- 문자열 format
# 문자열 format
test_string = "Hi, I'm {name}"
test_string.format(name="Young")
- 날짜에 따른 영화 랭킹 데이터 가져오기
import time
from tqdm import tqdm
movie_date = []
movie_name = []
movie_url = []
movie_point = []
base_url = "https://movie.daum.net"
for today in tqdm(date):
url = "https://movie.daum.net/ranking/boxoffice/weekly?date={date}"
response = urlopen(url.format(date=today.strftime("%Y%m%d")))
soup = BeautifulSoup(response, "html.parser")
end = len(soup.select("strong.tit_item"))
movie_date.extend([today for _ in range(0, end)])
for n in range(0, end):
movie_name.append(soup.select("strong.tit_item")[n].a.string)
now_url = base_url + soup.select("strong.tit_item")[n].a["href"]
movie_url.append(now_url)
# 영화 상세 페이지 - 평점 추출
req = urlopen(now_url)
soup_req = BeautifulSoup(req, "html.parser")
movie_point.append(soup_req.select(".inner_cont")[1].select_one("dd").text)
# 사이트에 사람이 아닌 속도로 접근하면 해킹이라고 인식할 수 있다.
time.sleep(0.5) 어려웠던 점
평점이 없는 페이지가 있어서 중간 중간 에러가 발생했다.
같은 태그인 평점 대신 관람객 수가 들어왔던 것!!
if문이나 예외처리로 하면 되겠지만 지금은 그것이 목적이 아니라서 최대한 평점이 있는 영화들 날짜로 피해서 연습을 했다.
- 데이터 확인

8. DataFrame 생성 및 저장
# 데이터 프레임 생성
movie = pd.DataFrame({
"date": movie_date,
"title": movie_name,
"point": movie_point,
})
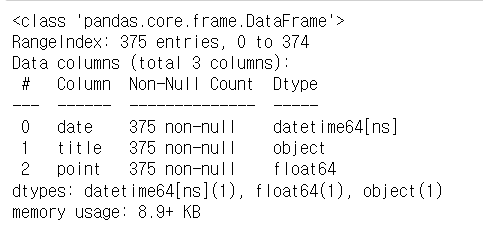
movie.tail()- 데이터 info 확인
movie.info() 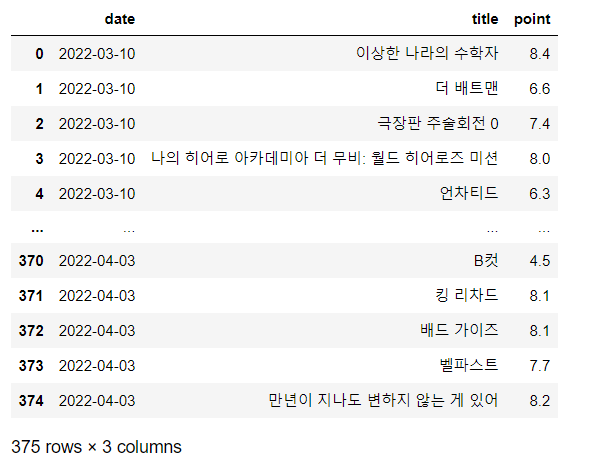
- object => float 타입 변경
movie["point"] = movie["point"].astype(float) # object -> float으로 변경
movie.info()
9. 데이터 저장 및 확인
- 데이터 저장
movie.to_csv(
"../data/03. daum_movie_data.csv", sep=",", encoding="utf-8"
)- 데이터 확인
df = pd.read_csv("../data/03. daum_movie_data.csv", index_col=0)
df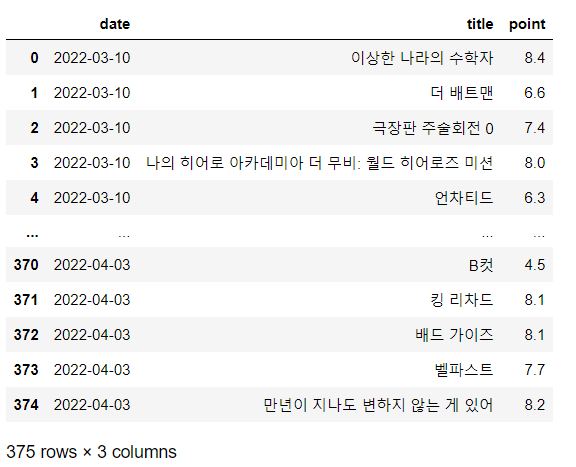
📌영화 평점 데이터 정리
- 영화 이름으로 인덱스를 잡는다.
- 점수의 합산을 구한다.
- 다음은 날짜 별 평점이 없을 것이기 때문에 같은 평점이 계속 더해질 것
- 100일 간 네이버 영화 평점 합산 기준 베스트 & 워스트 10 선정
import numpy as np
import pandas as pdmovie = pd.read_csv("../data/03. daum_movie_data.csv", index_col=0)
movie.tail()- pivot table 생성
movie_unique = pd.pivot_table(data=movie, index="title", aggfunc=np.sum)
movie_unique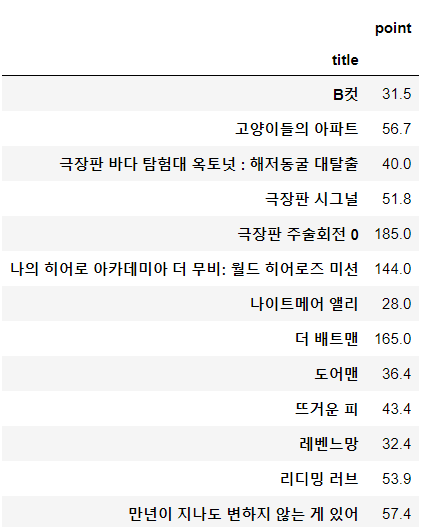
- pivot 정렬 - Best Movie
movie_best = movie_unique.sort_values(by="point", ascending=False) # 내림차순
movie_best.head()- 한 영화 날짜 별 평점
주의⚠️
네이버가 아닌 다음 영화 상세 페이지에서 가져온 평점(최종 현재 평점)이기 때문에 평점이 모두 일치하다.
tmp = movie.query("title == ['더 배트맨']")
tmp
📌영화 평점 데이터 시각화
- 시각화 1
# 시각화
import matplotlib.pyplot as plt
from matplotlib import rc
rc("font", family="Malgun Gothic")
%matplotlib inlineplt.figure(figsize=(15, 8)) # x 15, y 8
plt.plot(tmp["date"], tmp["point"]) # 선 그래프 x축 - 날짜, y축 - 평점 => 날짜에 따른 평점 변화ㅏ를 선그래프로 표현(시계열)
plt.title("날짜별 평점")
plt.xlabel("날짜")
plt.ylabel("평점")
plt.legend(labels=["평점 추이"], loc="best")
plt.grid(True)
- xticks
plt.figure(figsize=(15, 8)) # x 15, y 8
plt.plot(tmp["date"], tmp["point"]) # 선 그래프 x축 - 날짜, y축 - 평점 => 날짜에 따른 평점 변화ㅏ를 선그래프로 표현(시계열)
plt.title("날짜별 평점")
plt.xticks(rotation="vertical") # 날짜를 세로
plt.xlabel("날짜")
plt.ylabel("평점")
plt.legend(labels=["평점 추이"], loc="best")
plt.grid(True)
- 상위, 하위 10개 영화
평점이 날짜 별 다른 데이터가 아닌 점, 날짜별로 상영 시작, 상영 종료 영화가 있기 때문에 상위, 하위라고 하기엔 문제가 있지만 실습하는 것에 의미를 둬야한다.
# 상위 10개 영화
movie_best.head(10)# 하위 10개 영화
movie_best.tail(10)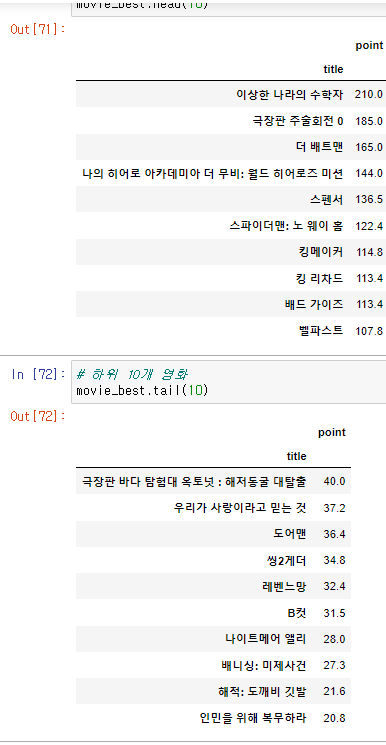
- pivot table
movie_pivot = pd.pivot_table(data=movie, index="date", columns="title", values="point")
movie_pivot.head()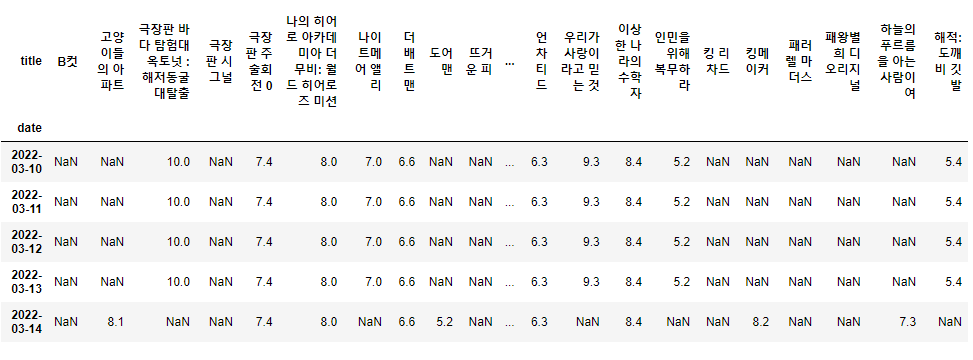
- Excel 저장
movie_pivot.to_excel("../data/03. movie_pivot.xlsx")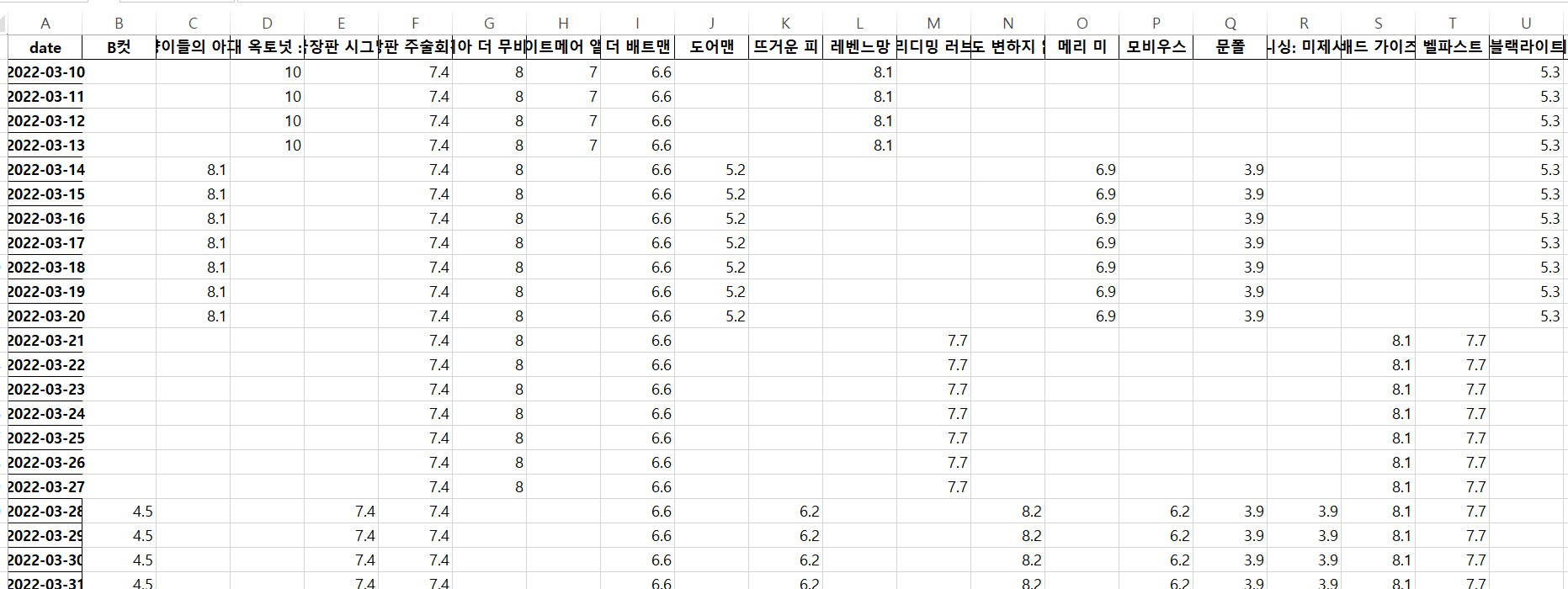
- 시각화 2
import platform
import seaborn as sns
from matplotlib import font_manager, rc
path = "C:/Windows/Fonts/malgun.ttf"
if platform.system() == "Darwin":
rc("font", family="Arial Unicode Ms")
elif platform.system() == "Windows":
font_name = font_manager.FontProperties(fname=path).get_name()
rc("font", family=font_name)
else:
print("Unknown system. sorry")target_col = ["해적: 도깨비 깃발", "스파이더맨: 노 웨이 홈", "이상한 나라의 수학자", "배드 가이즈", "신비한 동물사전"]
plt.figure(figsize=(20, 8))
plt.title("날짜별 평점")
plt.xlabel("날짜")
plt.ylabel('평점')
plt.xticks(rotation="vertical")
plt.plot(movie_pivot[target_col])
plt.legend(target_col, loc="best")
plt.grid(True)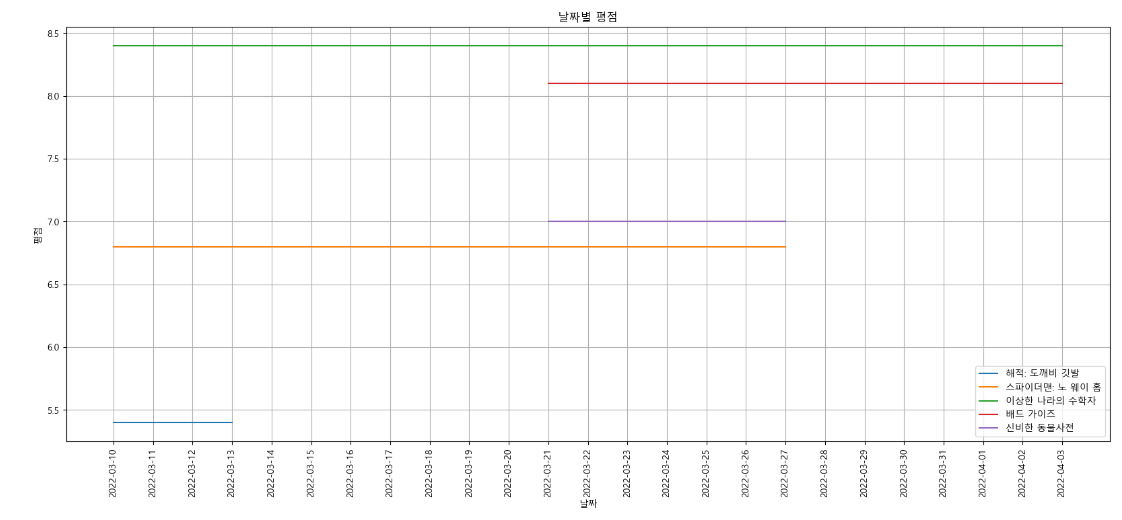
- tick_param()
날짜를 선으로 구분
target_col = ["해적: 도깨비 깃발", "스파이더맨: 노 웨이 홈", "이상한 나라의 수학자", "배드 가이즈", "신비한 동물사전"]
plt.figure(figsize=(20, 8))
plt.title("날짜별 평점")
plt.xlabel("날짜")
plt.ylabel('평점')
plt.xticks(rotation="vertical")
plt.tick_params(bottom="off", labelbottom="off")
plt.plot(movie_pivot[target_col])
plt.legend(target_col, loc="best")
plt.grid(True)
😊 느낀점
네이버 영화 페이지가 운영 종료되는 바람에 다음 영화 페이지로 바꿔서 실습을 해본다고 훨씬 더 많은 시간이 소비되었다.
페이지 구성이 달라서 상세에 한 번 더 접근해야했던 점, 영화가 아닌 다른 관람영상이 포함되어 평점이 없었던 점 등등 시간이 걸리는 요소가 너무 많았다.
하지만 강의 내용과 다르게 스스로 배웠던 걸 적용해봄으로써 복습이 된 점은 좋았다.
그리고 컴퓨터가 왜 이렇게 느리지ㅠㅠ 정말 바꿀 때가 된것인가!!!
"이 글은 제로베이스 데이터 취업 스쿨 강의를 듣고 작성한 내용으로 제로베이스 데이터 취업 스쿨 강의 자료 일부를 발췌한 내용이 포함되어 있습니다."
