📌시카고 맛집 데이터 분석 - 개요
- chicago-magazine-sandwinches URL
- chicago magazine the 50 best sandwiches
최종 목표
총 51개의 페이지에서 각 가게의 정보를 가져온다.
- 가게 이름
- 대표 메뉴
- 대표 메뉴의 가격
- 가게 주소
📌시카고 맛집 데이터 분석 - 메인페이지
📍 403 ERROR
서버는 정상적인데 서버가 문제 있다고 판단하고 차단한 것
from urllib.request import Request, urlopen
from bs4 import BeautifulSoup
url_base = "https://www.chicagomag.com/"
url_sub = "chicago-magazine/november-2012/best-sandwiches-chicago/"
url = url_base + url_sub
response = urlopen(url)
response
- 해결 방법
hearders 값을 추가해 본다.
from urllib.request import Request, urlopen
from bs4 import BeautifulSoup
url_base = "https://www.chicagomag.com/"
url_sub = "chicago-magazine/november-2012/best-sandwiches-chicago/"
url = url_base + url_sub
req = Request(url, headers={"User-Agent": "Chrome"}) # 어떤 웹 브라우저로 접근 할 것인가?
response = urlopen(req)
response.status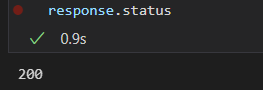
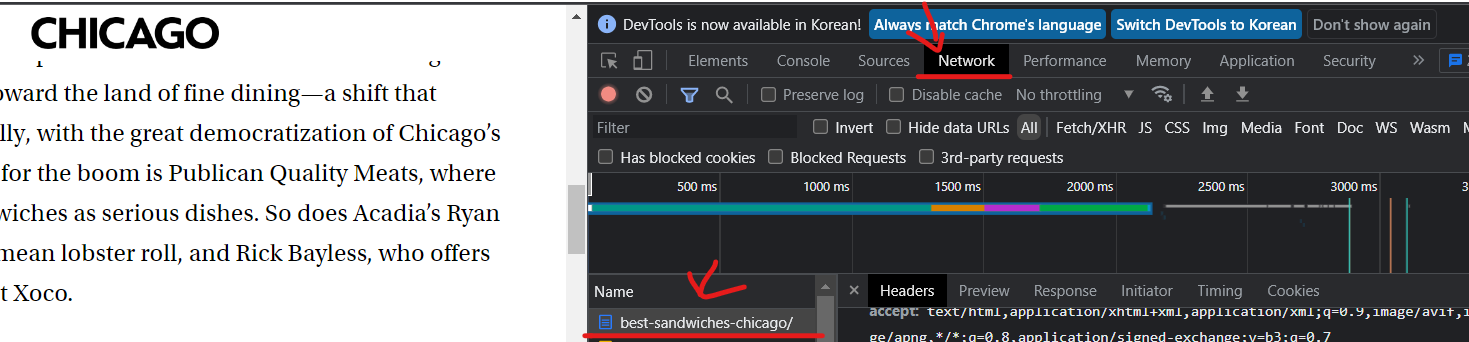
- Network -> best-sandwiches-chicago 제일 아래 user-agent가 있다.
해당 값으로 작성하면 잘 실행되는 것은 볼 수 있다. (현재 접근하는 브라우저)


처음에는 그냥 접근해보고 문제가 생기면 headers 값을 주고 추가해보면 된다.
💡UserAgent
User-Agent 안에 있는 값을 랜덤하게 만들어주는 기능
여러 번 실행할 때마다 다른 환경으로 자동으로 만들어준다.
설치 - pip install fake-useragent
# !pip install fake-useragent
from urllib.request import Request, urlopen
from fake_useragent import UserAgent
from bs4 import BeautifulSoup
url_base = "https://www.chicagomag.com/"
url_sub = "chicago-magazine/november-2012/best-sandwiches-chicago/"
url = url_base + url_sub
ua = UserAgent()
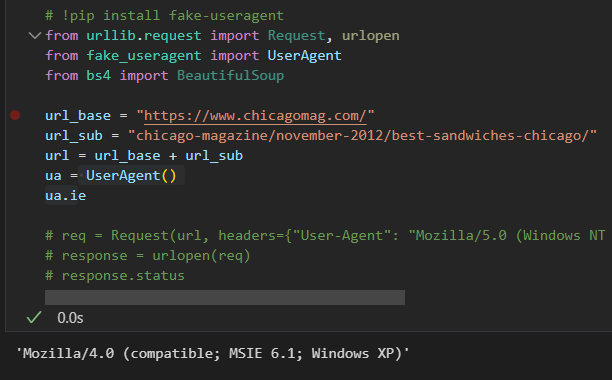
ua.ie- 실행마다 값이 다르게 나온다.
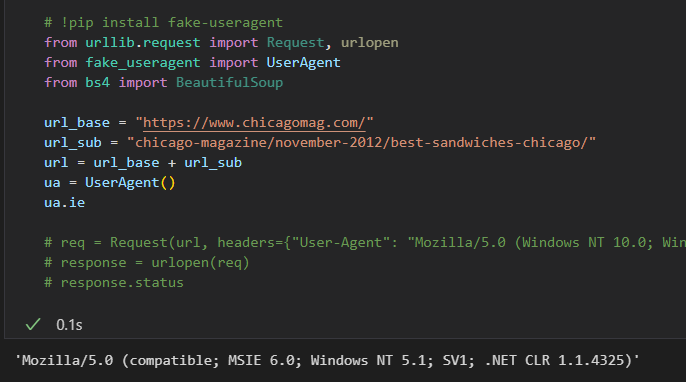
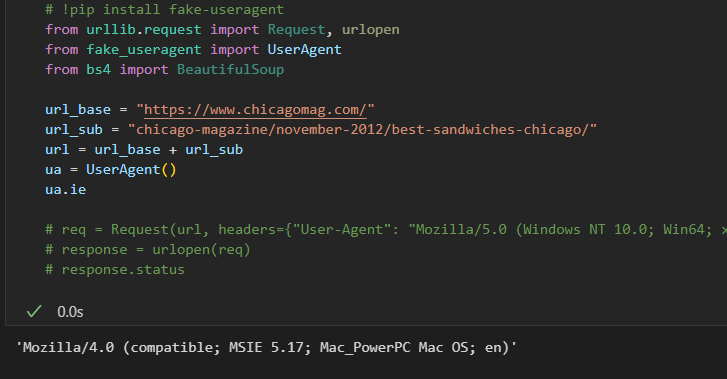
# !pip install fake-useragent
from urllib.request import Request, urlopen
from fake_useragent import UserAgent
from bs4 import BeautifulSoup
url_base = "https://www.chicagomag.com/"
url_sub = "chicago-magazine/november-2012/best-sandwiches-chicago/"
url = url_base + url_sub
ua = UserAgent()
req = Request(url, headers={"User-Agent": ua.ie}) # 어떤 웹 브라우저로 접근 할 것인가?
response = urlopen(req)
response.status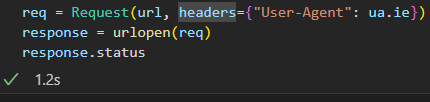
잘 실행되는 모습을 볼 수 있다.
📍페이지 가져오기
# !pip install fake-useragent
from urllib.request import Request, urlopen
from fake_useragent import UserAgent
from bs4 import BeautifulSoup
url_base = "https://www.chicagomag.com/"
url_sub = "chicago-magazine/november-2012/best-sandwiches-chicago/"
url = url_base + url_sub
ua = UserAgent()
req = Request(url, headers={"User-Agent": ua.ie}) # 어떤 웹 브라우저로 접근 할 것인가?
html = urlopen(req)
soup = BeautifulSoup(html, "html.parser")
print(soup.prettify())- 출력결과
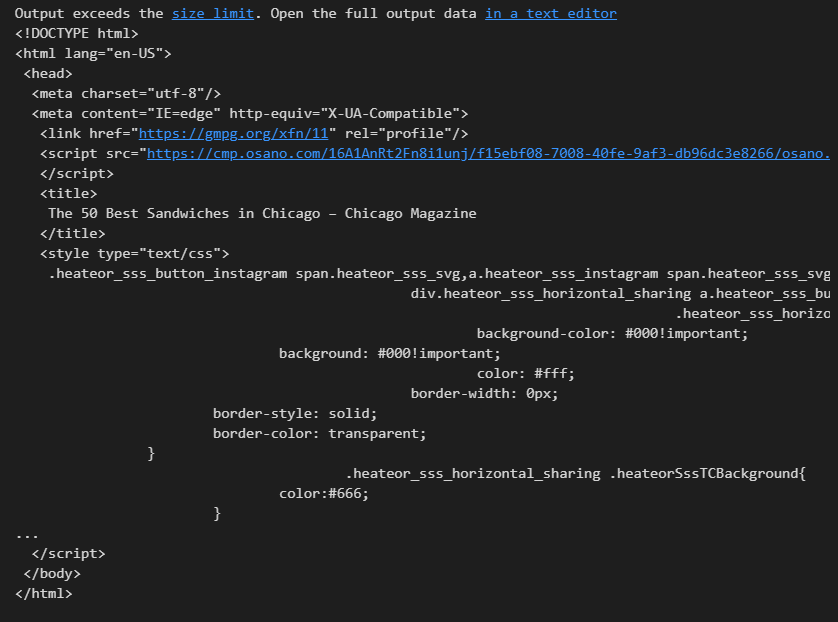
📍필요한 데이터 가져오기
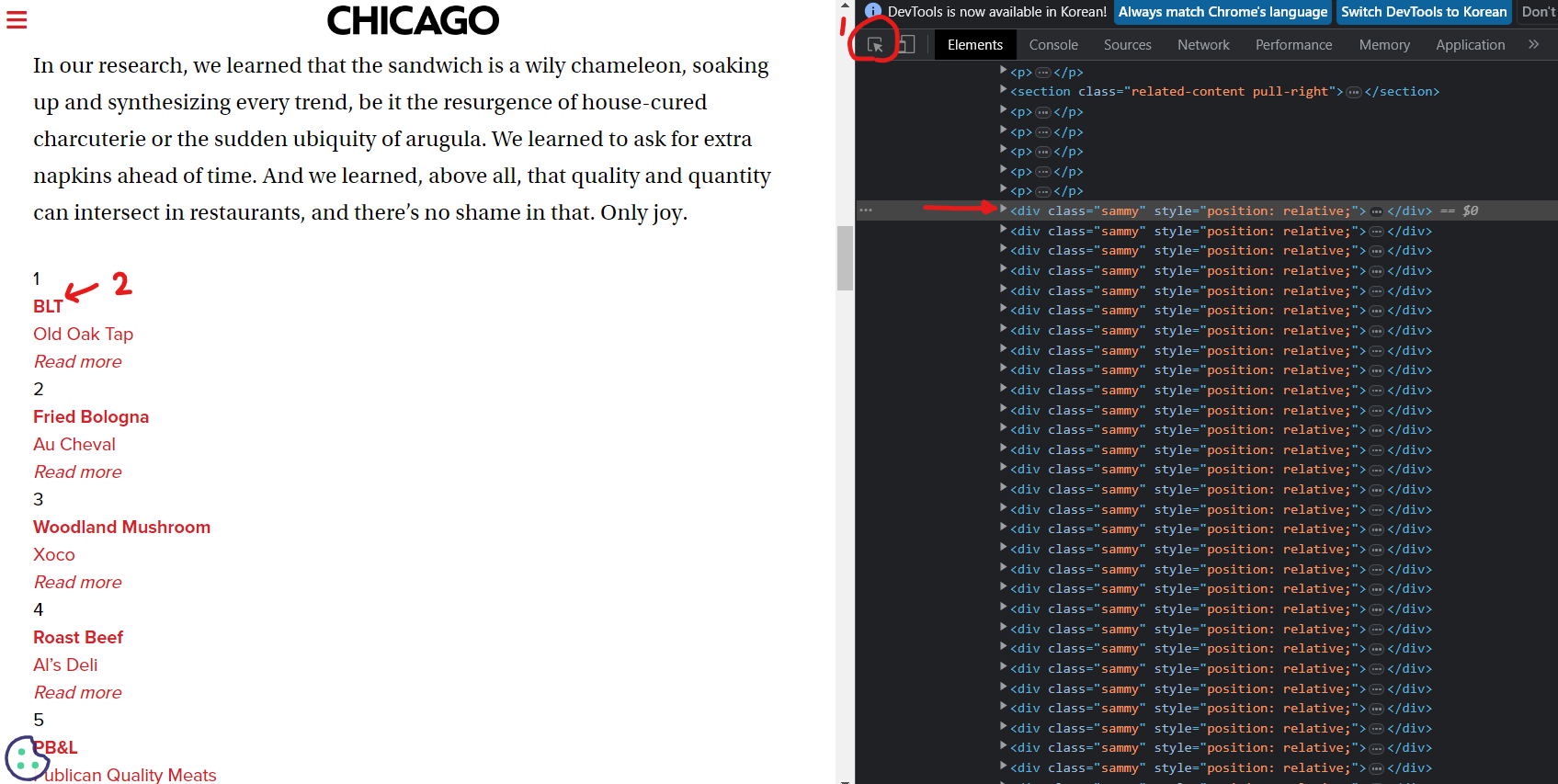
필요한 정보를 선택해보면 div태그에 "sammy" class를 가져오면 원하는 데이터를 가지고 올 수 있음을 알 수 있다.
- 원하는 데이터 가져오기 및 개수 확인(find_all, select)
# find_all
soup.find_all("div", "sammy"), len(soup.find_all("div", "sammy"))# select
soup.select(".sammy"), len(soup.select(".sammy"))
- 샘플 데이터 확인
전체 데이터를 가져오기 전 데이터 하나를 가져와서 확인한다.
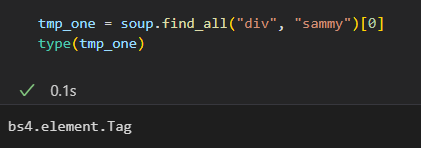
tmp_one = soup.find_all("div", "sammy")[0]
tmp_one
type을 이용하여 BeautifulSoup 객체로 생성됐음을 확인 할 수 있다.
즉, BeautifulSoup에서 사용하는 find_all, select 등 메서드를 사용할 수 있음을 확인한다.
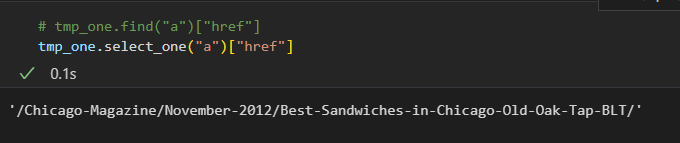
- 필요 데이터 추출
from urllib.parse import urljoin
import re
url_base = "https://www.chicagomag.com/"
# 필요한 내용을 담을 빈 리스트
# 리스트로 하나씩 컬럼을 만들고, DataFrame으로 합칠 예정
rank = []
main_menu = []
cafe_name = []
url_add = []
list_soup = soup.find_all("div", "sammy") # soup.select(".sammy")
for item in list_soup:
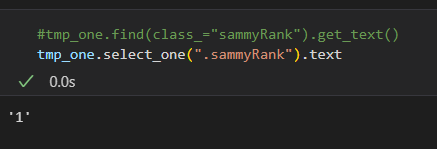
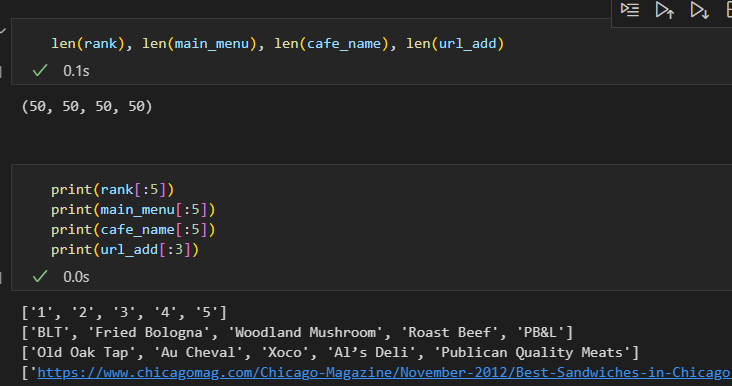
rank.append(item.find(class_="sammyRank").get_text())
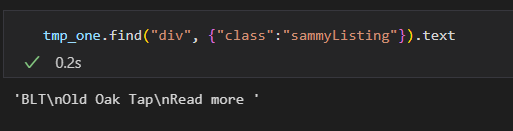
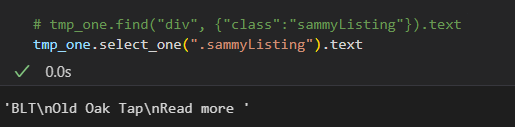
tmp_string = tmp_one.find(class_="sammyListing").get_text()
main_menu.append(re.split(("\n|\r\n"), tmp_string)[0])
cafe_name.append(re.split(("\n|\r\n"), tmp_string)[1])
url_add.append(urljoin(url_base, item.find("a")["href"])) # urljoin : 있으면 join 안하고, 없으면 알아서 붙여줌- 데이터 check
📍DataFrame 생성
웹 페이지에서 가져온 데이터로 DataFrame 생성
import pandas as pd
data = {
"Rank": rank,
"Menu": main_menu,
"Cafe": cafe_name,
"URL": url_add,
}
df = pd.DataFrame(data)
df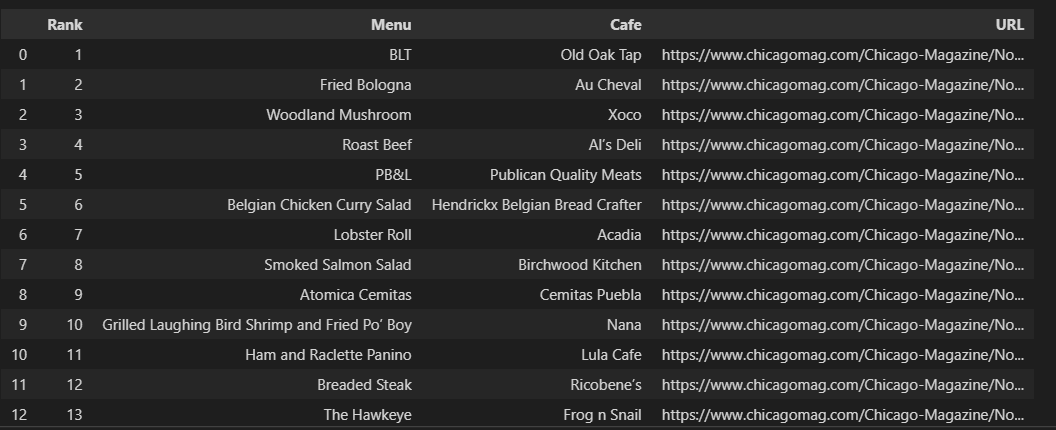
- 컬럼 순서 변경
# 컬럼 순서 변경
df = pd.DataFrame(data, columns=["Rank", "Cafe", "Menu", "URL"])
df.tail(2)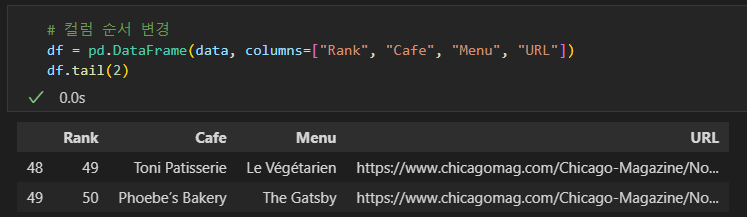
📍데이터 csv 저장
# 데이터 저장
df.to_csv(
"../data/03. best_sandwiches_list_chicago.csv", sep=",", encoding="utf-8"
)📌시카고 맛집 데이터 분석 - 하위페이지
예제 3에서 가져온 데이터에서 URL을 찾아 들어가 해당 페이지 가게의 메뉴 가격, 가게 주소를 가져오자.
📍csv 파일 읽기
# requirements
import pandas as pd
from urllib.request import urlopen
from fake_useragent import UserAgent
from bs4 import BeautifulSoupdf = pd.read_csv("../data/03. best_sandwiches_list_chicago.csv", index_col=0)
df.tail(2)
- Rank 1위의 가게 URL
df["URL"][0]
📍페이지, 데이터 가져오기
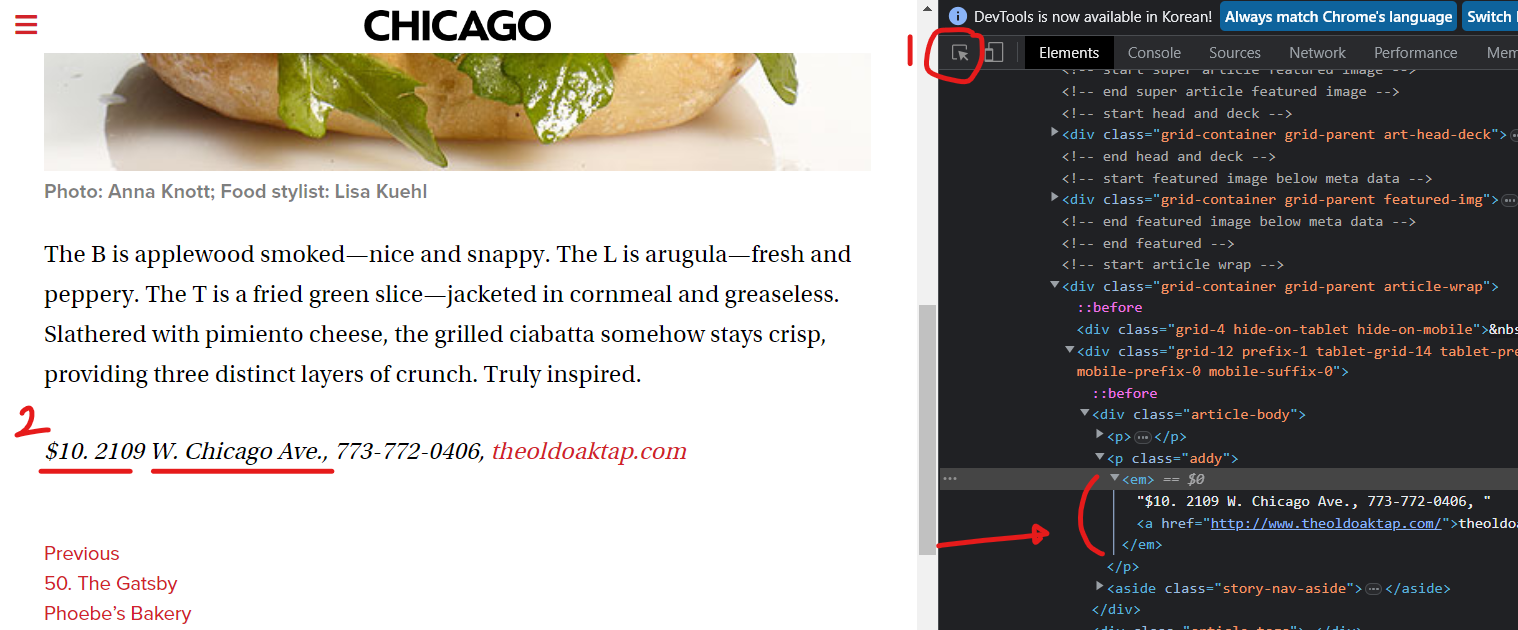
ua = UserAgent()
req = Request(df["URL"][0], headers={"user-agent":ua.ie})
html = urlopen(req).read()
soup_tmp = BeautifulSoup(html, "html.parser")
soup_tmp.find("p", "addy") # soup_tmp.select_one(".addy")
📍데이터 추출
- 데이터 테스트
전체 데이터를 가져오기 전 하나의 데이터로 테스트한다.
# regular expression
price_tmp = soup_tmp.find("p", "addy").text
price_tmp
import re
re.split(".,", price_tmp)
price_tmp = re.split(".,", price_tmp)[0]
price_tmp
- 가격
tmp = re.search("\$\d+\.(\d+)?", price_tmp).group()
tmp
- 주소
tmp = re.search("\$\d+\.(\d+)?", price_tmp).group()
price_tmp[len(tmp) + 2:] # 가격 길이 끝난 부분부터 맨 끝까지
- 필요 데이터 추출
tqdm 설치 conda install -c conda-forge tqdm
from tqdm import tqdm
import re
price = []
address = []
for idx, row in tqdm(df.iterrows()):
req = Request(row["URL"], headers={"user-agent":ua.ie})
html = urlopen(req).read()
soup_tmp = BeautifulSoup(html, "html.parser")
gettings = soup_tmp.find("p", "addy").get_text()
price_tmp = re.split(".,", gettings)[0]
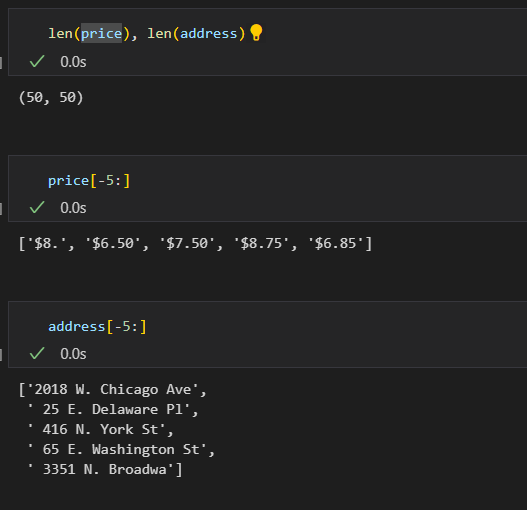
tmp = re.search("\$\d+\.(\d+)?", price_tmp).group()
price.append(tmp)
address.append(price_tmp[len(tmp)+2:])
print(idx)
강의에서는 위와 같이 코드했을 때 잘 작동했는데 내가 했을 땐 실행할 때마다 계속 403 상태 에러가 나타나서 그냥 UserAgent 사용하지 않고 "Crome"이라 작성하고 사용했다.
(idx가 출력되면서 2, 30, 5, 44 등등 랜덤 타이밍에 해당 줄에서 에러가 나길래 ua.ie가 문제라고 생각함)
req = Request(row["URL"], headers={"user-agent":"Crome"}) # ua.ie- 데이터 확인
📍DataFrame 데이터 추가 및 정리
df["Price"] = price
df["Address"] = address
df = df.loc[:, ["Rank", "Cafe", "Menu", "Price", "Address"]] # 행은 전체 선택, URL 컬럼 제외(최종적으로 필요없음)
df.set_index("Rank", inplace=True)
df.head()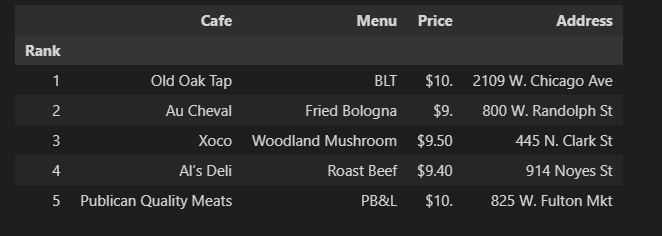
📍데이터 저장
df.to_csv(
"../data/03. best_sandwiches_list_chicago2.csv", sep=",", encoding="utf-8"
)📍저장 데이터 확인
pd.read_csv("../data/03. best_sandwiches_list_chicago2.csv", index_col=0)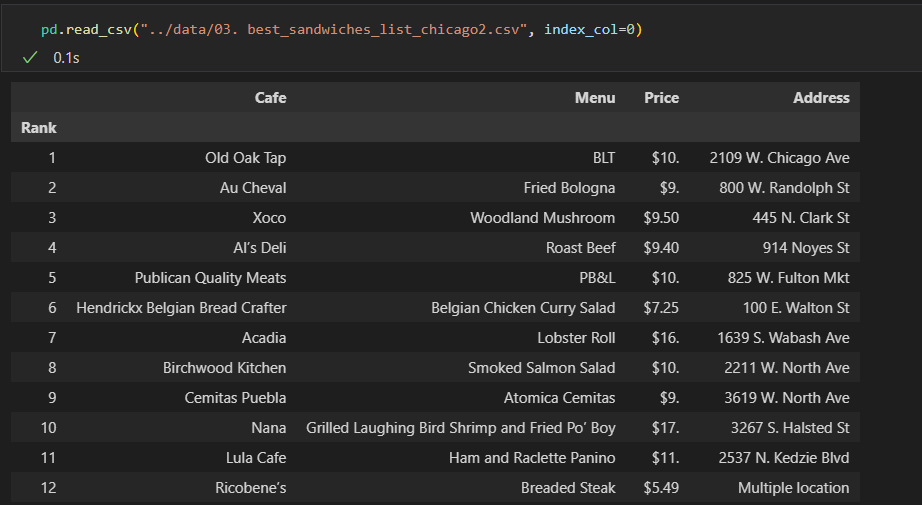
📌시카고 맛집 데이터 지도 시각화
# requirements
import folium
import pandas as pd
import numpy as np
import googlemaps
from tqdm import tqdm📍데이터 읽기
df = pd.read_csv("../data/03. best_sandwiches_list_chicago2.csv", index_col=0)
df.tail(10)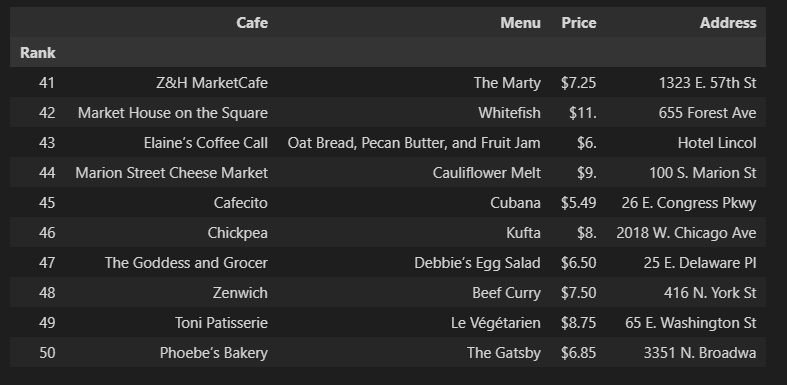
📍google maps에서 위도, 경도 가져오기
gmaps_key = "API키 입력"
gmaps = googlemaps.Client(key=gmaps_key)lat = []
lng = []
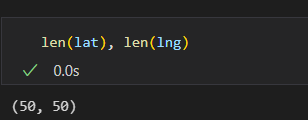
for idx, row in tqdm(df.iterrows()):
if not row["Address"] == "Multiple location":
target_name = row["Address"] + ", " + "Chicago"
# print(target_name)
gmaps_output = gmaps.geocode(target_name)
location_output = gmaps_output[0].get("geometry")
lat.append(location_output["location"]["lat"])
lng.append(location_output["location"]["lng"])
else:
lat.append(np.nan)
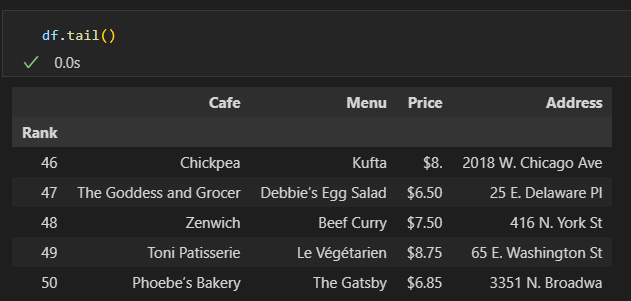
lng.append(np.nan) - 위도, 경도 확인
📍DataFrame에 위도, 경도 저장
df["lat"] = lat
df["lng"] = lng
df.tail()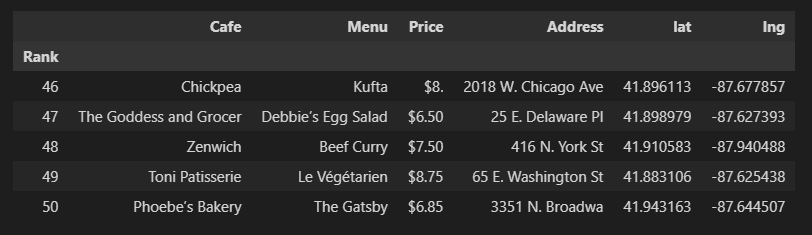
📍지도에 좌표 찍기
mapping = folium.Map(location=[41.8781136, -87.6297982], zoom_start=11)
for idx, row in df.iterrows():
if not row["Address"] == "Multiple location":
folium.Marker(
location=[row["lat"], row["lng"]],
popup=row["Cafe"],
).add_to(mapping)
mapping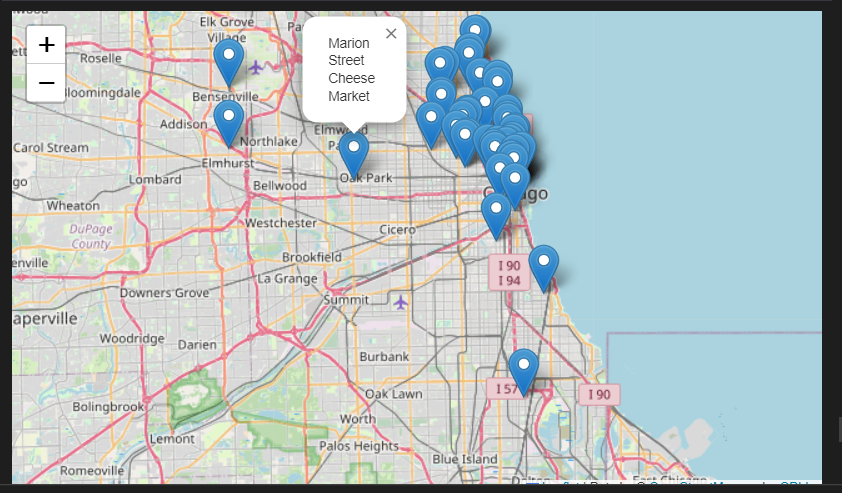
- 커스텀
mapping = folium.Map(location=[41.8781136, -87.6297982], zoom_start=11)
for idx, row in df.iterrows():
if not row["Address"] == "Multiple location":
folium.Marker(
location=[row["lat"], row["lng"]],
popup=row["Cafe"],
tooltip=row["Menu"],
icon=folium.Icon(
icon="coffee",
prefix="fa"
)
).add_to(mapping)
mapping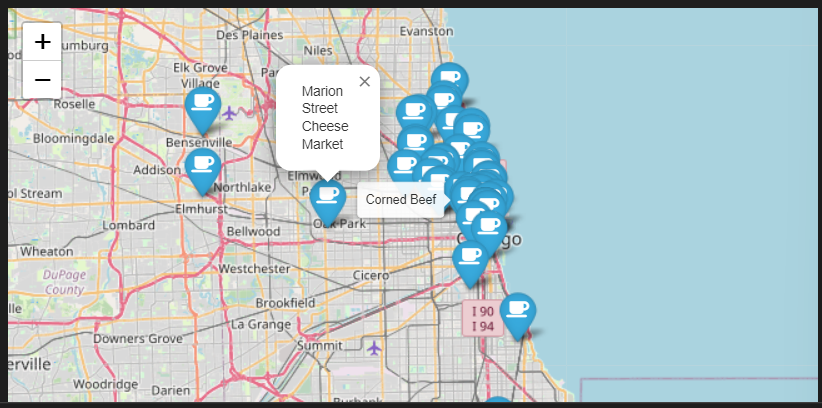
느낀점🤔
웹 데이터 분석 예제를 몇 가지 해보고 나니 재밌다는 생각이 들었다.
웹에서 원하는 데이터를 가져오는 것도, 데이터 프레임에 저장하는 것도, 지도에 시각화하는 것도 다 재밌다.
처음 하는 작업이라 어렵기도 하고 아직 이해가 안 되는 부분도 있고 혼자서 하려면 물론 아직 제대로 못하겠지만 흥미롭고 뿌듯하다.👍웹 프로그래밍 프로젝트 때 같은 팀원이 지도에서 맛집 데이터를 가져왔었는데 이렇게 한 게 아닐까 싶으면서 이해가 되고 있다!! 재밌다.😊
"이 글은 제로베이스 데이터 취업 스쿨 강의 자료 일부를 발췌한 내용이 포함되어 있습니다."
