📌GBM
-
Gradient Boosting Machine
(Gradient 단어가 붙어있으면 계산이 많아 오래걸린다.) -
부스팅 알고리즘은 여러 개의 약한 학습기(week learner)를 순차적으로 학습-예측하면서 잘못 예측한 데이터에 가중치를 부여해서 오류를 개선해가는 방식
-
GBM은 가중치를 업데이트할 때 경사 하강법(Gradient Descent)을 이용하는 것이 큰 차이
- GBM 예제
- 데이터 읽기
import pandas as pd
url = 'https://raw.githubusercontent.com/PinkWink/ML_tutorial/master/dataset/HAR_dataset/features.txt'
feature_name_df = pd.read_csv(url, sep='\s+', header=None, names=['column_index', 'column_name'])
feature_name = feature_name_df.iloc[:, 1].values.tolist()
X_train_url = 'https://raw.githubusercontent.com/PinkWink/ML_tutorial/master/dataset/HAR_dataset/train/X_train.txt'
X_test_url = 'https://raw.githubusercontent.com/PinkWink/ML_tutorial/master/dataset/HAR_dataset/test/X_test.txt'
X_train = pd.read_csv(X_train_url, sep='\s+', header=None)
X_test = pd.read_csv(X_test_url, sep='\s+', header=None)
X_train.columns = feature_name
X_test.columns = feature_namey_train_url = 'https://raw.githubusercontent.com/PinkWink/ML_tutorial/master/dataset/HAR_dataset/train/y_train.txt'
y_test_url = 'https://raw.githubusercontent.com/PinkWink/ML_tutorial/master/dataset/HAR_dataset/test/y_test.txt'
y_train = pd.read_csv(y_train_url, sep='\s+', header=None, names=['action'])
y_test = pd.read_csv(y_test_url, sep='\s+', header=None, names=['action'])- 필요 모듈 import
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.metrics import accuracy_score
import time
import warnings
warnings.filterwarnings('ignore')- 실행 시작
start_time = time.time()
gb_clf = GradientBoostingClassifier(random_state=13)
gb_clf.fit(X_train, y_train)
gb_pred = gb_clf.predict(X_test)
print('ACC : ', accuracy_score(y_test, gb_pred))
print('Fit time : ', time.time() - start_time)
- 일반적으로 GBM이 성능자체는 랜덤 포레스트보다는 좋다고 알려져 있음
- sckit-learn의 GBM은 속도가 아주 느린 것으로 알려져 있음
🤔사담
강의에서는 500초 정도 나왔다고 했는데 1600초 정도 나옴,,,
3배정도 더 많이 걸려 실행하는데 26분 걸렸다.
macbook으로 바꾸고 싶은데 정말 바꿔야하는 것인가!!!
- GridSearchCV(너무 오래걸려서 생략)
from sklearn.model_selection import GridSearchCV
params = {
'n_estimators' : [100, 500],
'learning_rate' : [0.05, 0.1]
}
start_time = time.time()
grid = GridSearchCV(gb_clf, param_grid=params, cv=2, verbose=1, n_jobs=-1)
grid.fit(X_train, y_train)
print('Fit time : ', time.time() - start_time)- best 파라미터
- Test 데이터 성능
📌 XGBoost
- XGBoost는 트리 기반의 앙상블 학습에서 가장 각광받는 알고리즘 중 하나
- GBM 기반의 알고리즘인데, GBM의 느린 속도를 다양한 규제를 통해 해결
- 특히 병렬 학습이 가능하도록 설계됨
- XGBoost는 반복 수행 시마다 내부적으로 학습데이터와 검증데이터를 교차검증을 수행
- 교차검증을 통해 최적화되면 반복을 중단하는 조기 중단 기능을 가지고 있음
- install
- pip install xgboost
- 에러가 날 경우, conda install py-xgboost - xgboost는 설치해야 함
- 주요 파라미터
- nthread : CPU의 실행 스레드 개수를 조정. 디폴트는 CPU의 전체 스레드를 사용하는 것
- eta : GBM 학습률
- num_boost_rounds : n_estimators와 같은 파라미터
- max_depth
- 성능 확인
from xgboost import XGBClassifier
start_time = time.time()
xgb = XGBClassifier(n_estimators=400, learning_rate=0.1, max_depth=3)
xgb.fit(X_train.values, y_train)
print('Fit time : ', time.time() - start_time)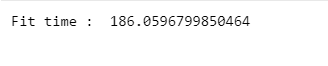
훨씬 속도가 빨라졌다.
⚠️Error
Invalid classes inferred from unique values ofy. Expected: [0 1 2 3 4 5], got [1 2 3 4 5 6]버전이 달라지면서 필요한듯하다.
- 해결방법
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
y_train = le.fit_transform(y_train)
accuracy_score(y_test, xgb.predict(X_test.values))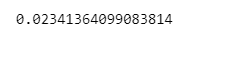
- 조기 종료 조건과 검증데이터 지정 후 성능 확인
from xgboost import XGBClassifier
evals = [(X_test.values, y_test)]
start_time = time.time()
xgb = XGBClassifier(n_estimators=400, learning_rate=0.1, max_depth=3)
xgb.fit(X_train.values, y_train, early_stopping_roungs=10, eval_set=evals)
print('Fit time : ', time.time() - start_time)early_stopping_roungs=10 : 비슷한 성능으로 10번 이상 반복되는 경우 종료해라
accuracy_score(y_test, xgb.predict(X_test.values))📌LightGBM
- LightGBM은 XGBoost와 함께 부스팅 계열에서 가장 각광받는 알고리즘
- LGBM의 큰 장점은 속도
- 단, 적은 수의 데이터에는 어울리지 않음 (일반적으로 10000건 이상의 데이터가 필요하다고 함)
- GPU 버전도 존재함
- install
- conda install lightgbm
error시 pip install lightgbm

from lightgbm import LGBMClassifier
start_time = time.time()
lgbm = LGBMClassifier(n_estimators=400)
lgbm.fit(X_train.values, y_train, early_stopping_roungs=100, eval_set=evals)
print('Fit time : ', time.time() - start_time)accuracy_score(y_test, lgbm.predict(X_test.values))시간이 훨씬 빨라졌다.
버전 문제인것인가? 강의 내용이랑 방법이 좀 달라져서 error가 많이 나와 결과를 출력 못한 부분이 있다.
"이 글은 제로베이스 데이터 취업 스쿨 강의를 듣고 작성한 내용으로 제로베이스 데이터 취업 스쿨 강의 자료 일부를 발췌한 내용이 포함되어 있습니다."
