
📌교차 검증
- 과적합 : 모델이 학습 데이터에만 과도하게 최적화된 현상.
그로 인해 일반화된 데이터에서는 예측 성능이 과하게 떨어지는 현상 - 지난번 와인 맛 평가에서 훈련용 데이터의 Acc는 72.94, 테스트용 데이터는 Acc가 71.61%였는데, 누가 이 결과가 정말 괜찮은 것인지 묻는다면?
- 나에게 주어진 데이터에 적용한 모델의 성능을 정확히 표현하기 위해서도 유용하다.
- holdout
train 데이터와 test 데이터의 분리
train 데이터의 accuracy, test 데이터의 accuracy를 보고 비교하는 것

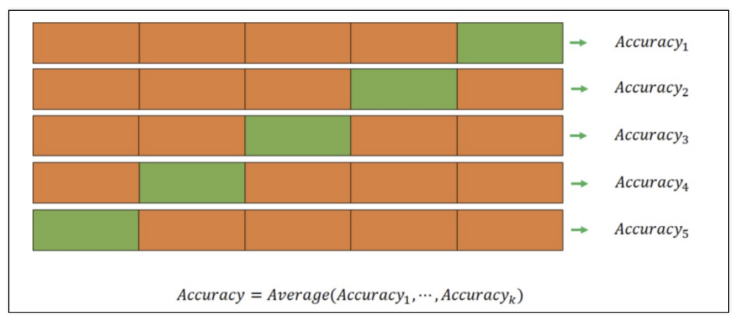
- k-fold cross validation
이미지에 있는 데이터는 모두 train 데이터다 test 데이터는 따로 존재
(k-fold에서 k는 숫자) 5-fold 이면 train 데이터를 5등분으로 나눈다.
4개를 가지고 train하고 나머지 한 개로 validation -> 5번 반복(검증 구간을 달리하여) 그리고 마지막에 average를 구한다.
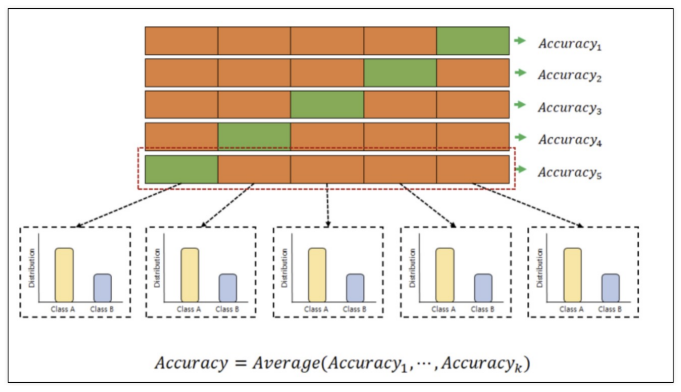
- stratified k-fold cross validation
위와 같이 5등분으로 나눌건데 나눌 때 해당 데이터의 클래스 분포가 다르다면 이 분포 상태를 유지해야한다는 것
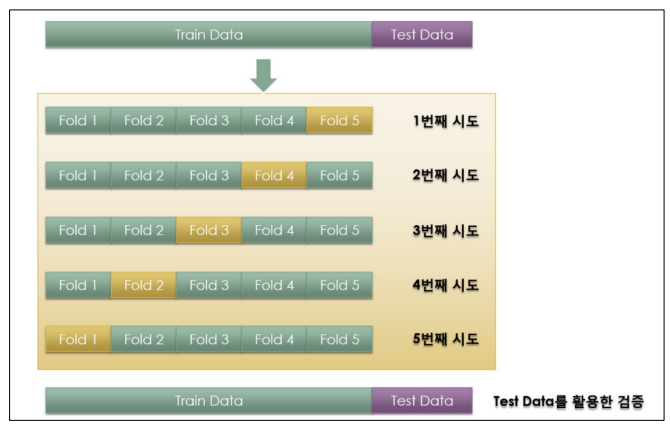
검증 validation이 끝난 후 test용 데이터로 최종 평가
📌교차 검증 구현
📍sample example
import numpy as np
from sklearn.model_selection import KFold
X = np.array([[1, 2], [3, 4], [1, 2], [3, 4]])
y = np.array([1, 2, 3, 4])
kf = KFold(n_splits=2) # 몇 등분 할 것인가?
print(kf.get_n_splits(X))
print(kf)
for train_idx, test_idx in kf.split(X):
print('--- idx')
print(train_idx, test_idx)
print('--- train data')
print(X[train_idx])
print('--- test data')
print(X[test_idx])
📍Wine data
import pandas as pd
red_url = 'https://raw.githubusercontent.com/PinkWink/ML_tutorial/master/dataset/winequality-red.csv'
white_url = 'https://raw.githubusercontent.com/PinkWink/ML_tutorial/master/dataset/winequality-white.csv'
red_wine = pd.read_csv(red_url, sep=';')
white_wine = pd.read_csv(white_url, sep=';')
red_wine['color'] = 1.
white_wine['color'] = 0.
wine = pd.concat([red_wine, white_wine])wine['taste'] = [1. if grade>5 else 0. for grade in wine['quality']]
X = wine.drop(['taste', 'quality'], axis=1)
y = wine['taste']- DecisionTree
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=13)
wine_tree = DecisionTreeClassifier(max_depth=2, random_state=13)
wine_tree.fit(X_train, y_train)
y_pred_tr = wine_tree.predict(X_train) # train accuracy
y_pred_test = wine_tree.predict(X_test) # test accuracy
print('Train Acc :', accuracy_score(y_train, y_pred_tr))
print('Test Acc :', accuracy_score(y_test, y_pred_test))
여기서 잠깐, 그러니까 누가, “데이터를 저렇게 분리하는 것이 최선인건가?”
, “저 acc를 어떻게 신뢰할 수 있는가?” 라고 묻는다면 어떻게 할 것인가?
- KFold
from sklearn.model_selection import KFold
kfold = KFold(n_splits=5)
wine_tree_cv = DecisionTreeClassifier(max_depth=2, random_state=13)for train_idx, test_idx in kfold.split(X):
print(len(train_idx), len(test_idx))
훈련하고 검증하고를 위와 같은 길이로 5번 반복한다.
- 각 각의 fold에 대한 학습 후 acc
cv_accuracy = []
for train_idx, test_idx in kfold.split(X):
X_train, X_test = X.iloc[train_idx], X.iloc[test_idx]
y_train, y_test = y.iloc[train_idx], y.iloc[test_idx]
wine_tree_cv.fit(X_train, y_train)
pred = wine_tree_cv.predict(X_test)
cv_accuracy.append(accuracy_score(y_test, pred))
cv_accuracy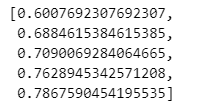
나의 모델이 60% accuracy가 나올 때가 있고 78% accuracy가 나올 때도 있구나 하나의 accuracy가 아님을 알아야하며 성능이 60-78%까지 나올 수 있구나 생각해야한다.
np.mean(cv_accuracy)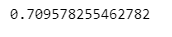
각 acc의 분산이 크지 않다면 평균을 대표 값으로 한다
- StratifiedKFold
from sklearn.model_selection import StratifiedKFold
skfold = StratifiedKFold(n_splits=5)
wine_tree_cv = DecisionTreeClassifier(max_depth=2, random_state=13)
cv_accuracy = []
for train_idx, test_idx in skfold.split(X, y): # y값 기준으로 stratified를 유지
X_train, X_test = X.iloc[train_idx], X.iloc[test_idx]
y_train, y_test = y.iloc[train_idx], y.iloc[test_idx]
wine_tree_cv.fit(X_train, y_train)
pred = wine_tree_cv.predict(X_test)
cv_accuracy.append(accuracy_score(y_test, pred))
cv_accuracynp.mean(cv_accuracy)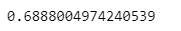
성능이 더 떨어진 모습을 볼 수 있다.
나의 모델 성능이 나의 예상보다 좋지 않을 수 있다는 생각을 해야함
- cross_val_score
간편한 cross validation 구현
from sklearn.model_selection import cross_val_score
skfold = StratifiedKFold(n_splits=5)
wine_tree_cv = DecisionTreeClassifier(max_depth=2, random_state=13)
cross_val_score(wine_tree_cv, X, y, scoring=None, cv=skfold)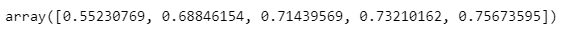
- 함수로 구현
def skfold_dt(depth):
from sklearn.model_selection import cross_val_score
skfold = StratifiedKFold(n_splits=5)
wine_tree_cv = DecisionTreeClassifier(max_depth=depth, random_state=13)
print(cross_val_score(wine_tree_cv, X, y, scoring=None, cv=skfold))- depth 별 차이
skfold_dt(2)
skfold_dt(5)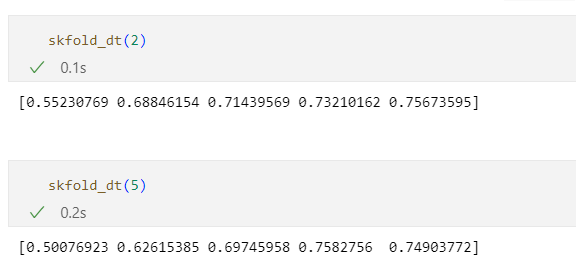
depth가 높다고 무조건 acc가 좋아지는 것도 아니다.
- train score 추가
from sklearn.model_selection import cross_validate
cross_validate(wine_tree_cv, X, y, scoring=None, cv=skfold, return_train_score=True)
과적합 현상도 보인다.
📌하이퍼파라미터 튜닝
모델의 성능을 확보하기 위해 조절하는 설정 값
직접 손으로 직접 다 수정해야하는 것들,,,
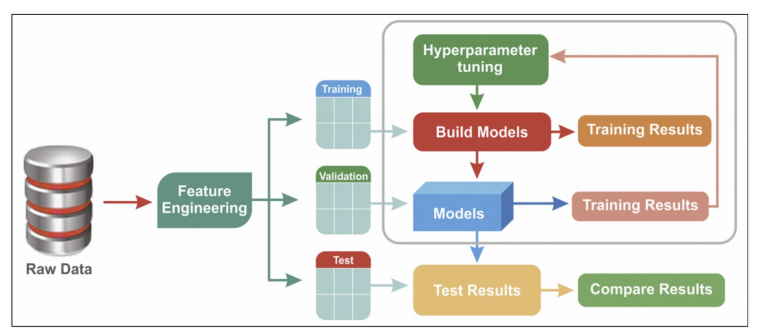
feature engineering - 특성을 관찰하고 특성에서 머신러닝 모델이 보다 잘 학습 결과를 더 이끌어 나갈 수 있도록 특성을 바꾸거나 새로운 특성을 찾아내는 것
<튜닝 대상>
• 결정나무에서 아직 우리가 튜닝해 볼만한 것은 max_depth이다.
• 간단하게 반복문으로 max_depth를 바꿔가며 테스트해볼 수 있을 것이다.
• 그런데 앞으로를 생각해서 보다 간편하고 유용한 방법을 생각해보자.
import pandas as pd
red_url = 'https://raw.githubusercontent.com/PinkWink/ML_tutorial/master/dataset/winequality-red.csv'
white_url = 'https://raw.githubusercontent.com/PinkWink/ML_tutorial/master/dataset/winequality-white.csv'
red_wine = pd.read_csv(red_url, sep=';')
white_wine = pd.read_csv(white_url, sep=';')
red_wine['color'] = 1.
white_wine['color'] = 0.
wine = pd.concat([red_wine, white_wine])
wine['taste'] = [1. if grade>5 else 0. for grade in wine['quality']]
X = wine.drop(['taste', 'quality'], axis=1)
y = wine['taste']- GridSearchCV
결과를 확인하고 싶은 파라미터를 정의만 하면 된다.
cv: cross validation
from sklearn.model_selection import GridSearchCV
from sklearn.tree import DecisionTreeClassifier
params = {'max_depth': [2, 4, 7, 10]}
wine_tree = DecisionTreeClassifier(max_depth=2, random_state=13)
gridsearch = GridSearchCV(estimator=wine_tree, param_grid=params, cv=5)
gridsearch.fit(X, y)GridSearchCV(estimator=wine_tree, param_grid=params, cv=5)
gridsearch.fit(X, y)
-> 지정된 분류기에 params을 [2, 4, 7, 10]로 정해줄테니 5겹 kfold로 알아서 fit해!
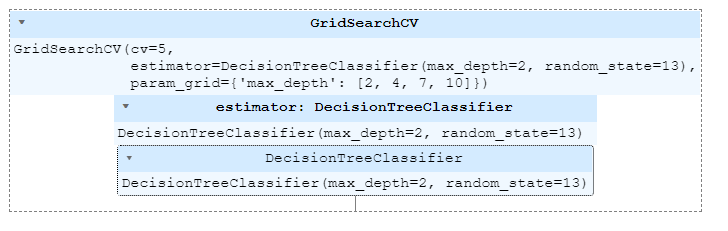
- GridSearchCV 결과
import pprint
pp = pprint.PrettyPrinter(indent=4)
pp.pprint(gridsearch.cv_results_)
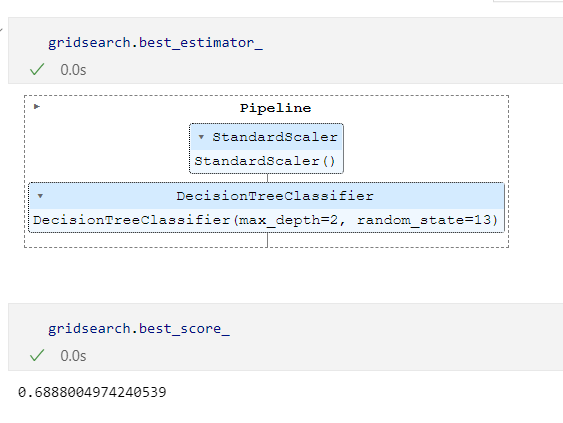
⭐최적의 성능을 가진 모델은?
gridsearch.best_estimator_
max_depth=2가 가장 좋았다.
gridsearch.best_score_gridsearch.best_params_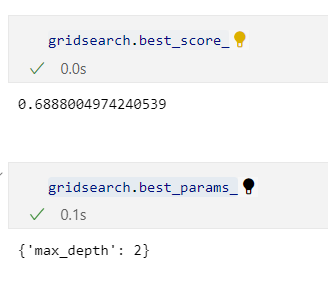
내가 지정한 경우의 수를 다 따져 알려준다.
- pipeline + GridSearch
pipeline을 적용한 모델에 GridSearch를 적용하고 싶다면
from sklearn.pipeline import Pipeline
from sklearn.tree import DecisionTreeClassifier
from sklearn.preprocessing import StandardScaler
estimators = [('scaler', StandardScaler()),
('clf', DecisionTreeClassifier(random_state=13))]
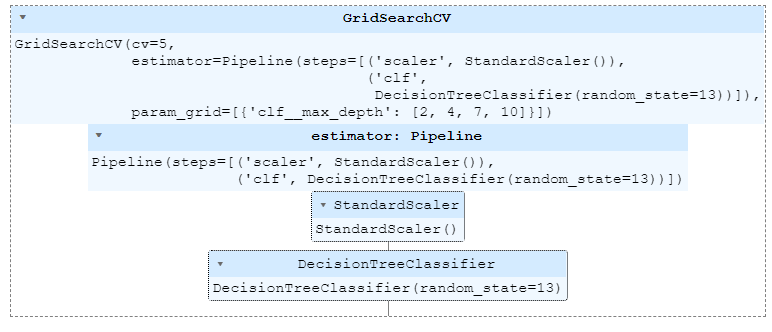
pipe = Pipeline(estimators)param_grid = [{'clf__max_depth': [2, 4, 7, 10]}]
gridsearch = GridSearchCV(estimator=pipe, param_grid=param_grid, cv=5)
gridsearch.fit(X, y)
✔️성능 결과 정리(표)
accuracy의 평균과 표준편차 표로 확인
import pandas as pd
score_df = pd.DataFrame(gridsearch.cv_results_)
score_df[['params', 'rank_test_score', 'mean_test_score', 'std_test_score']]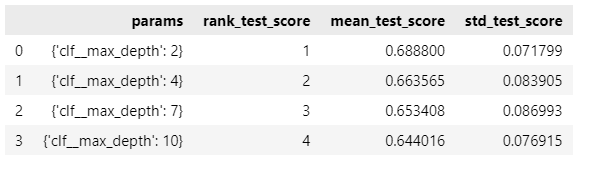

"이 글은 제로베이스 데이터 취업 스쿨 강의를 듣고 작성한 내용으로 제로베이스 데이터 취업 스쿨 강의 자료 일부를 발췌한 내용이 포함되어 있습니다."
