-
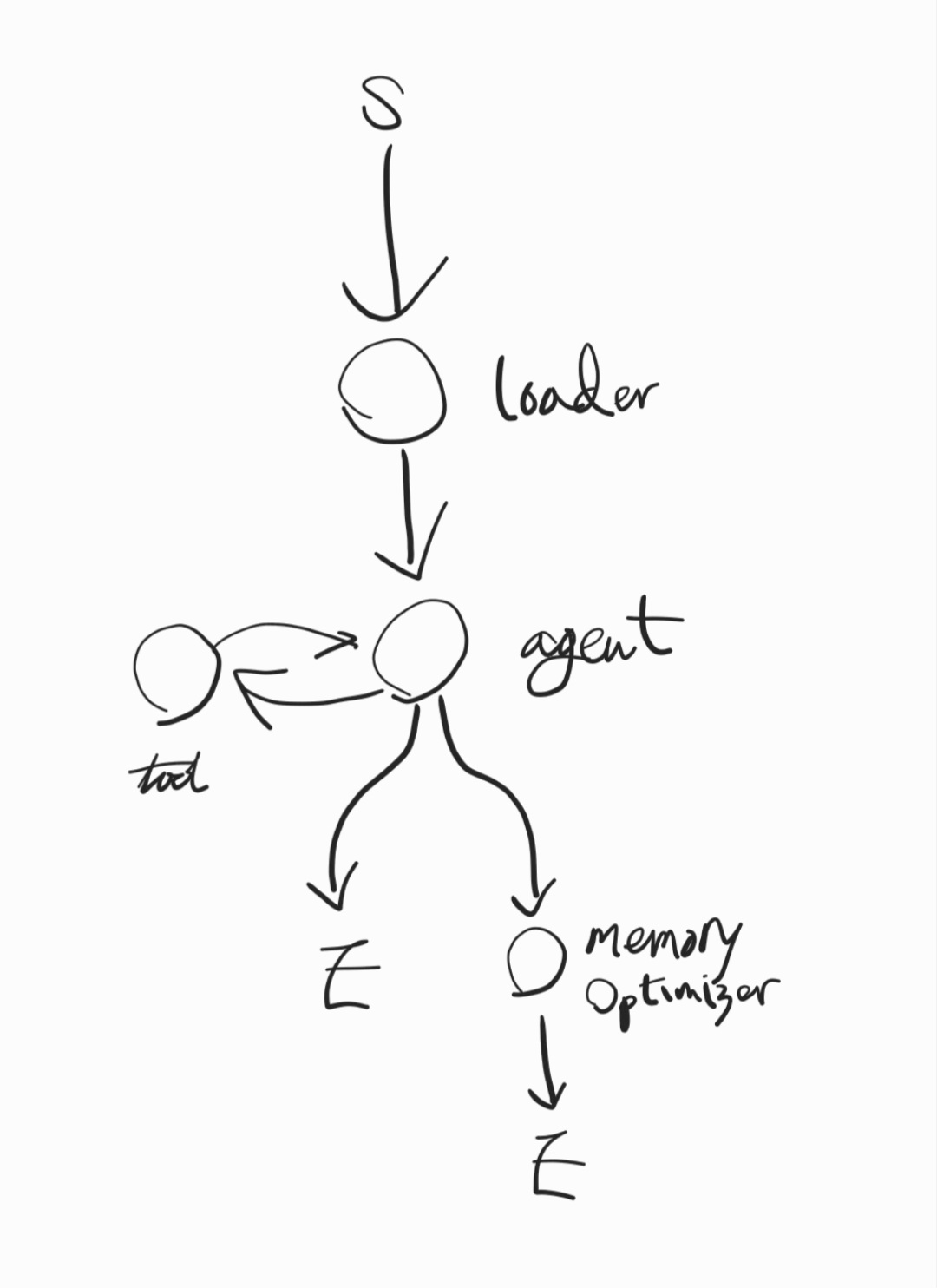
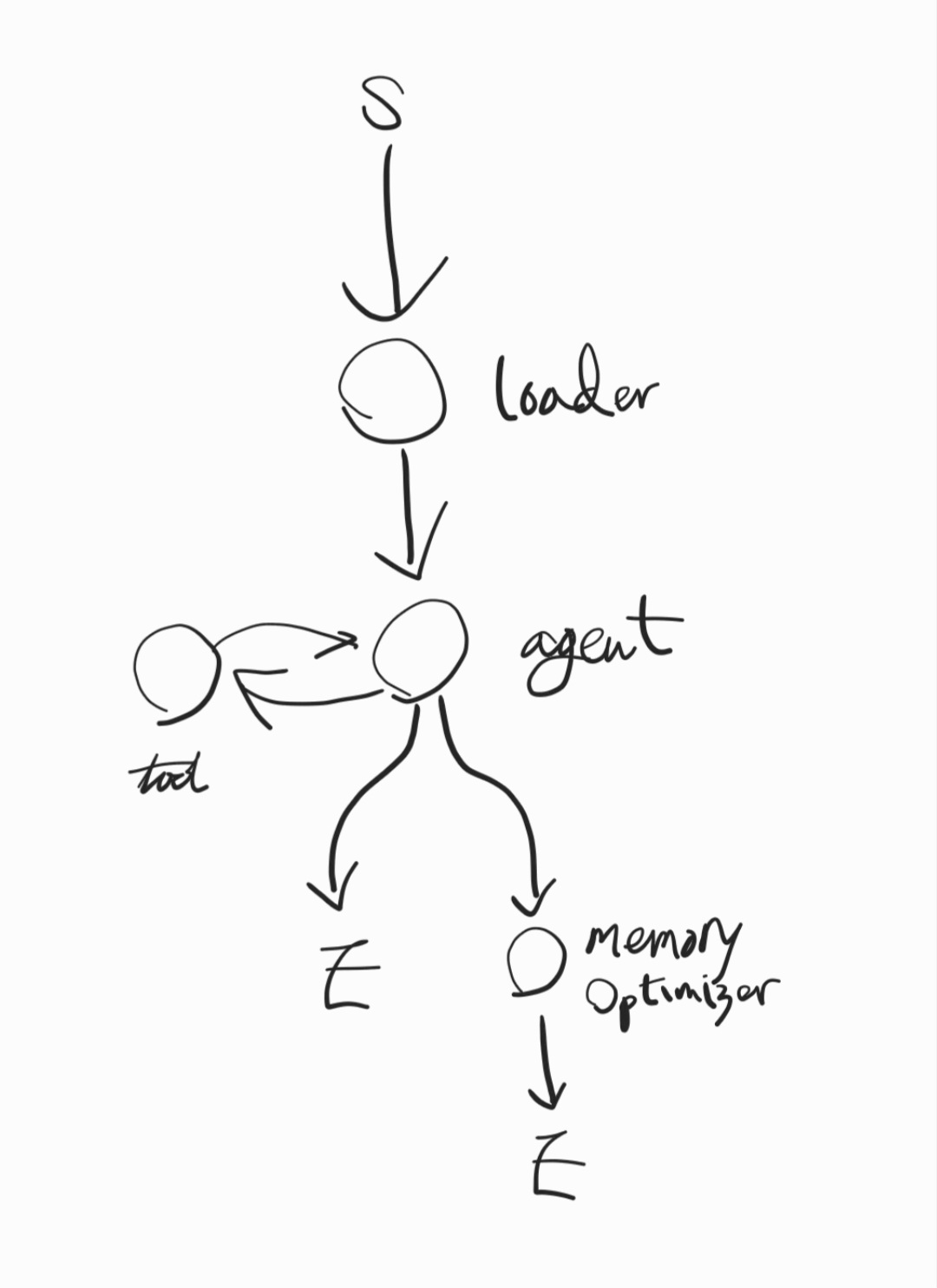
다음에 테스트할 랭그래프 워크플로우 구조이다.
-
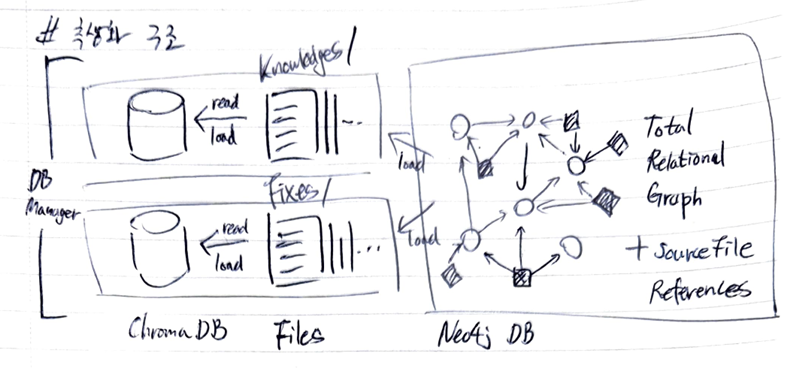
정보를 관리하기 위해 데이터베이스 구조를 생각해보았다.
- Graph DB: 지식 그래프를 생성하고, 그래프의 각 노드가 어느 파일에서 언급되는지 참조하는 관계를 그래프에 추가한다.
- 파일 시스템: 지식과 메타데이터 원본은 로컬 파일로 저장한다.
- Vector DB: RAG에 사용될 문서를 파일 시스템으로부터 불러온다. -
중요한 점은 저장된 정보가 언제든지 새로운 정보로 갱신될 수 있어야 한다는 점이다.
- 이를 위해 Vector DB와 파일 시스템을 각각Knowledges도메인과Fixes도메인으로 구분해서 관리한다.
- RAG 시스템에서 Knowledge DB에서 찾은 정보와 Fixes DB에서 찾은 정보를 모두 참고하도록 한다. -
Save:
- 저장할 내용과 메타데이터를 그대로Knowledges도메인의 Vector DB에 저장한다.
- 저장할 내용과 메타데이터를 그대로 파일 시스템의Knowledges/디랙토리에 저장한다.
- llm을 이용해서 주요 객체와 관계를 추출하고 Graph DB에 저장한다. 각 객체를 언급하는knowledge문서 노드를 추가한다.
- llm을 이용해서 기존 데이터에 대한 Fix를 추가해야 할지 결정한다. -
Save & Fix:
- Save 과정과 함께 수행한다.
- 저장할 내용과 메타데이터를 그대로Fixes도메인의 Vector DB에 저장한다.
- 저장할 내용과 메타데이터를 그대로 파일 시스템의Fixes/디랙토리에 저장한다.
- 주요 객체를 언급하는fix문서 노드를 추가한다. -
Load:
1. LLM(LangGraph workflow): 사용자 입력으로부터 주요 객체 정보를 추출한다.
2. Graph DB(Neo4j): 주요 객체를 언급하는 파일을 모두 찾는다. 필요하다면 주요 객체와 관련이 있는 다른 객체에 대한 파일을 찾을 수 있다.
3. Vector DB(Chroma): 파일을 임베드하여 retriever로 사용한다.