Kyla Unit-00
1.AI VTuber를 만들고 싶다.
(생략) 만들고 싶어졌다.긴 작업이 될 것 같으니 이제부터라도 블로그를 작성하려고 한다.
2.1일차. 기획.

이 기획은 언제든지 수정될 수 있으며 최신 기획안이 아니다. 최신화된 기획은 아이디어 대화, stream 방식 활용 방법 고안 웹 검색, 문서 검색기능 자신의 감정 분석이 가능하도록 구현 대화 내용 및 지식을 읽을 수 있는 파일로 저장 파일로 저장할 때는 파일
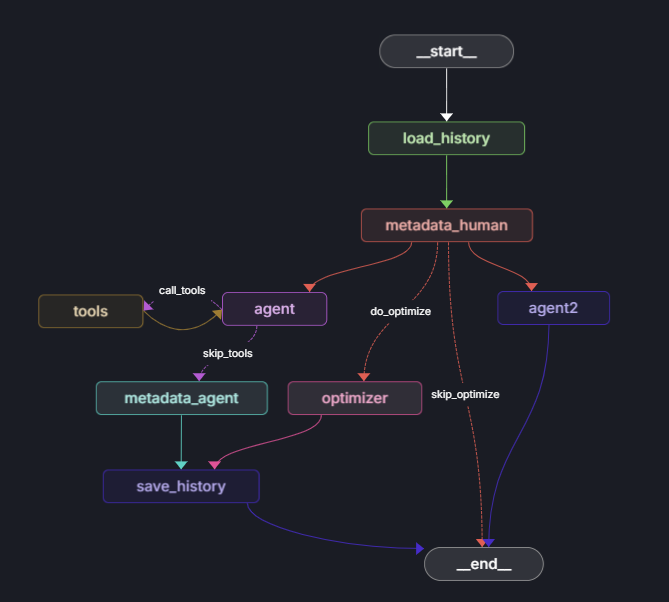
3.2일차. 랭그래프 입문.
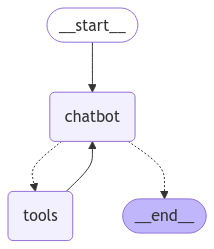
LangGraph 기반 챗봇을 개발하기 위한 지식을 습득하고 있다. 튜토리얼을 따라하며 위 그림과 같은 단순한 구조의 챗봇 그래프를 구성할 수 있었다. 현 시점에서 LLM으로는 Google Generative AI - Gemini 모델군을 무료 티어로 사용하고 있다
4.3일차. 프로젝트 구성.
확장성을 고려하여 프로젝트 구조를 수정했다.시스템 프롬프트를 작성했다.
5.4일차. 공부...
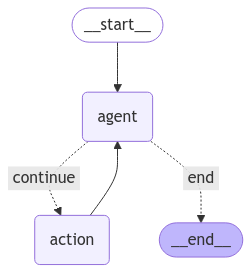
오늘은 기능 개발은 하지 않고 코드를 이리저리 수정하며 더 좋은 프로젝트 구조를 찾는 데에 시간을 썼다.LangChain, LangGraph 생태계에 조금 더 적응할 수 있었던 것 같다.
6.5일차. 공부......
오늘은 공식문서를 읽는 데에 8할, 인터넷 커뮤니티에서 AI 프롬프트 엔지니어링 자료를 찾는데에 2할의 시간을 썼다.공식 문서에서 제공하는 프로젝트 구조를 찾았으므로 다음에 프로젝트 리팩토링을 할 때 적용해 볼 계획이다.효과가 좋다고 알려진 시스템 프롬프트 작성법을 몇
7.6일차. Neo4j 도입 개시.
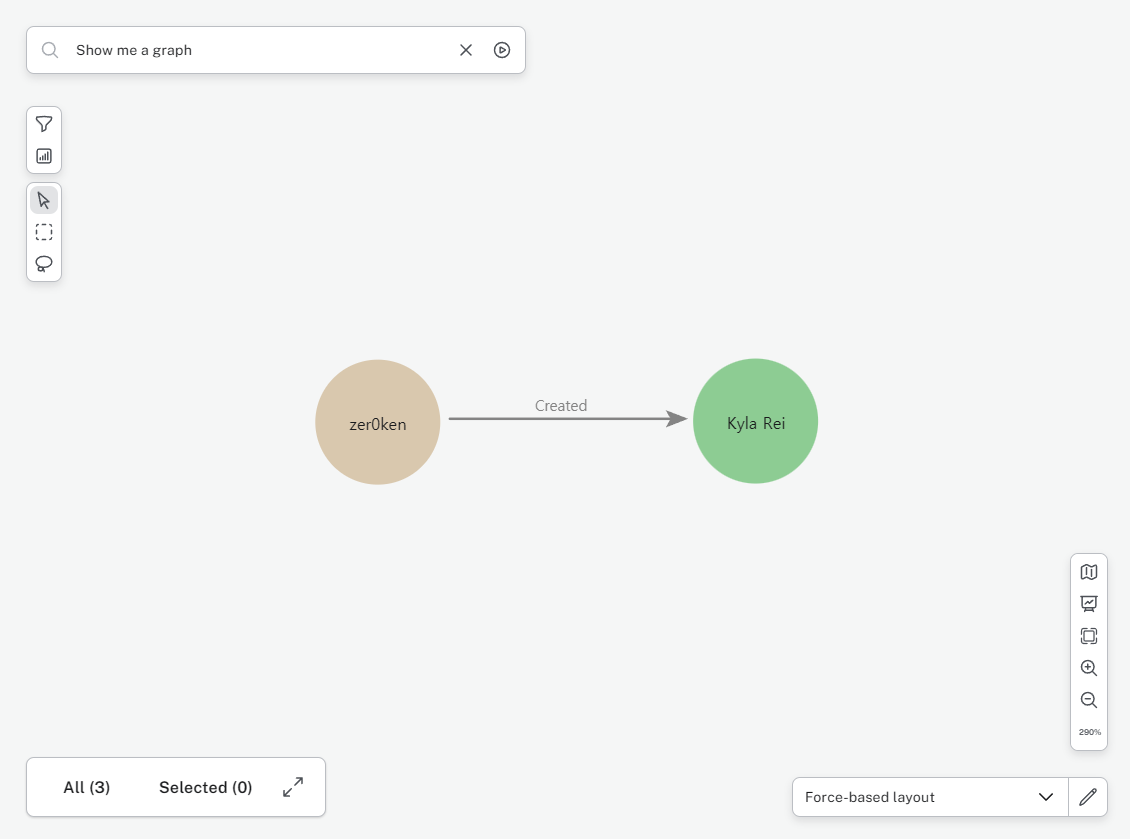
그래프 DB를 추가하기 위한 공부와 작업을 시작했다.Tool 바인딩에서 문제가 생겼다. dict 타입의 인자를 사용하면 오류가 발생한다. 이에 관한 자료를 찾았지만 오류를 수정하지 못해 StackOverflow에 질문 글을 작성해둔 상태이다.
8.7일차. langgraph-cli 적용
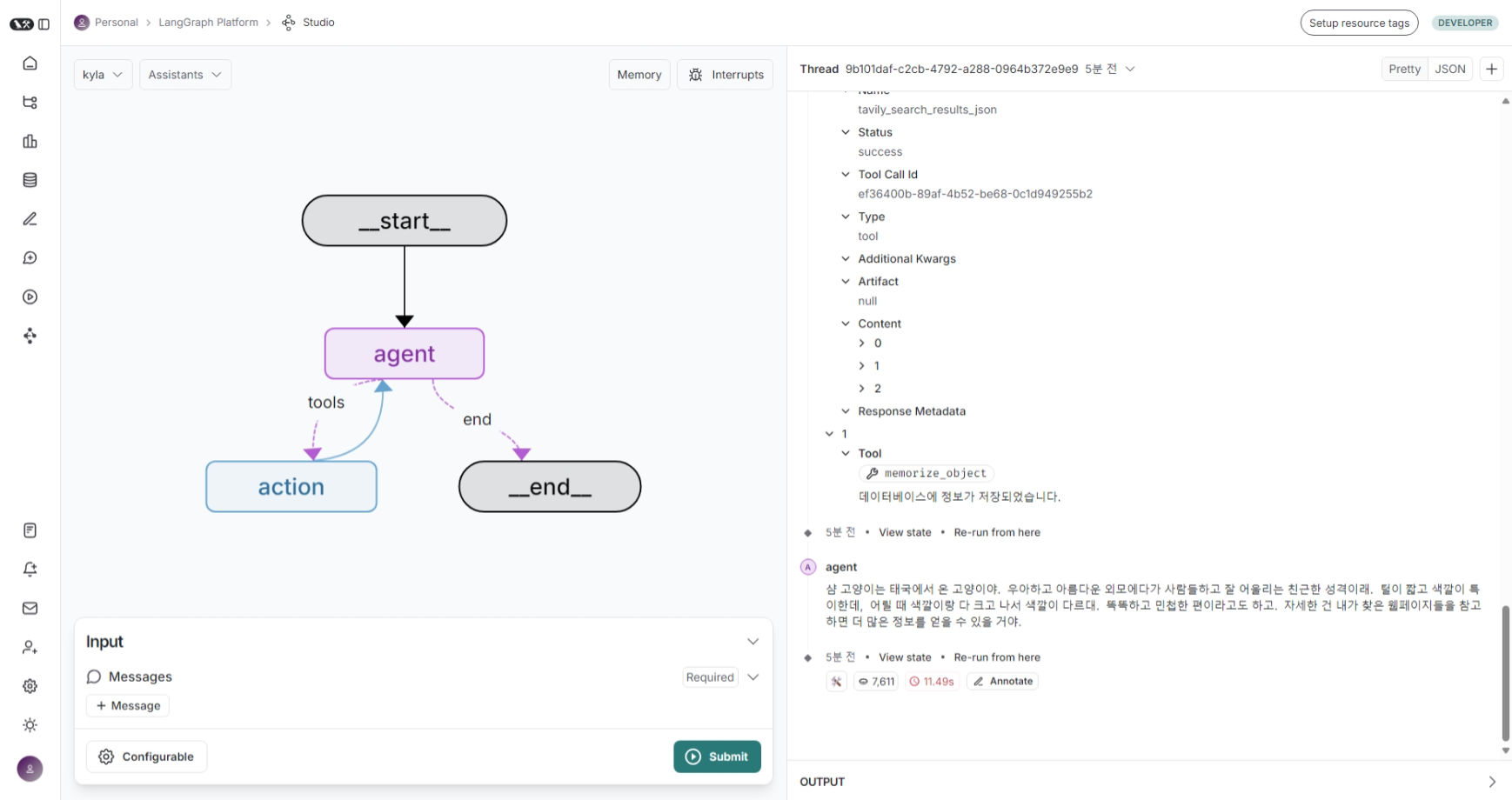
langgrpah-cli를 활용하면 LangGraph Studio를 웹 앱으로 사용하여 실시간 개발이 가능하다.
9.8일차. 공부...
랭그래프의 워크플로우 그래프 구조를 수정하면서 노드를 추가하거나 제거하기를 반복했다. 효율적인 상태 정의를 고려하면서 동적으로 프롬프트를 생성하는 방법을 고려하고 있다.
10.9일차. 그래프 구조 수정
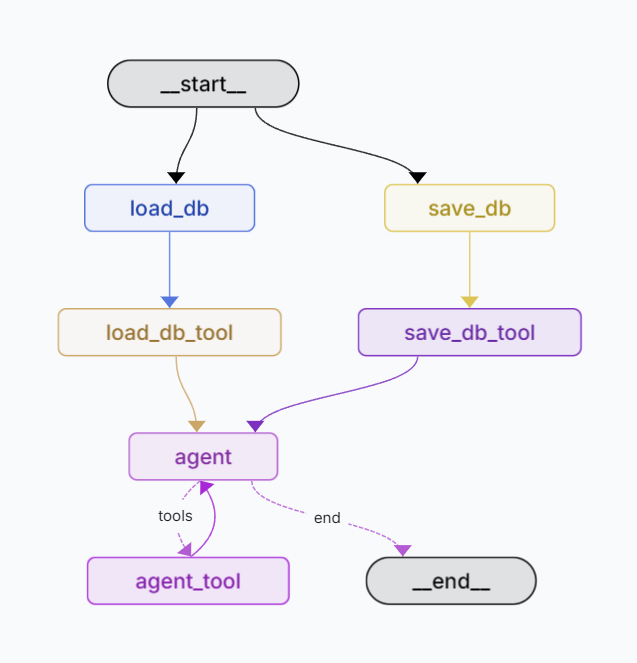
프롬프트 엔지니어링이 굉장히 어려운 과정이라고 느껴지고 있다. 시행착오에 드는 시간이 너무 길다.Neo4j를 주된 데이터베이스로 활용하도록 설계를 바꾸고 있다.새로운 그래프 구조: \- 입력과 동시에 load_db 노드에서 llm을 활용해 입력을 분석하고 Neo4j
11.10일차. 워크플로우, DB 설계.
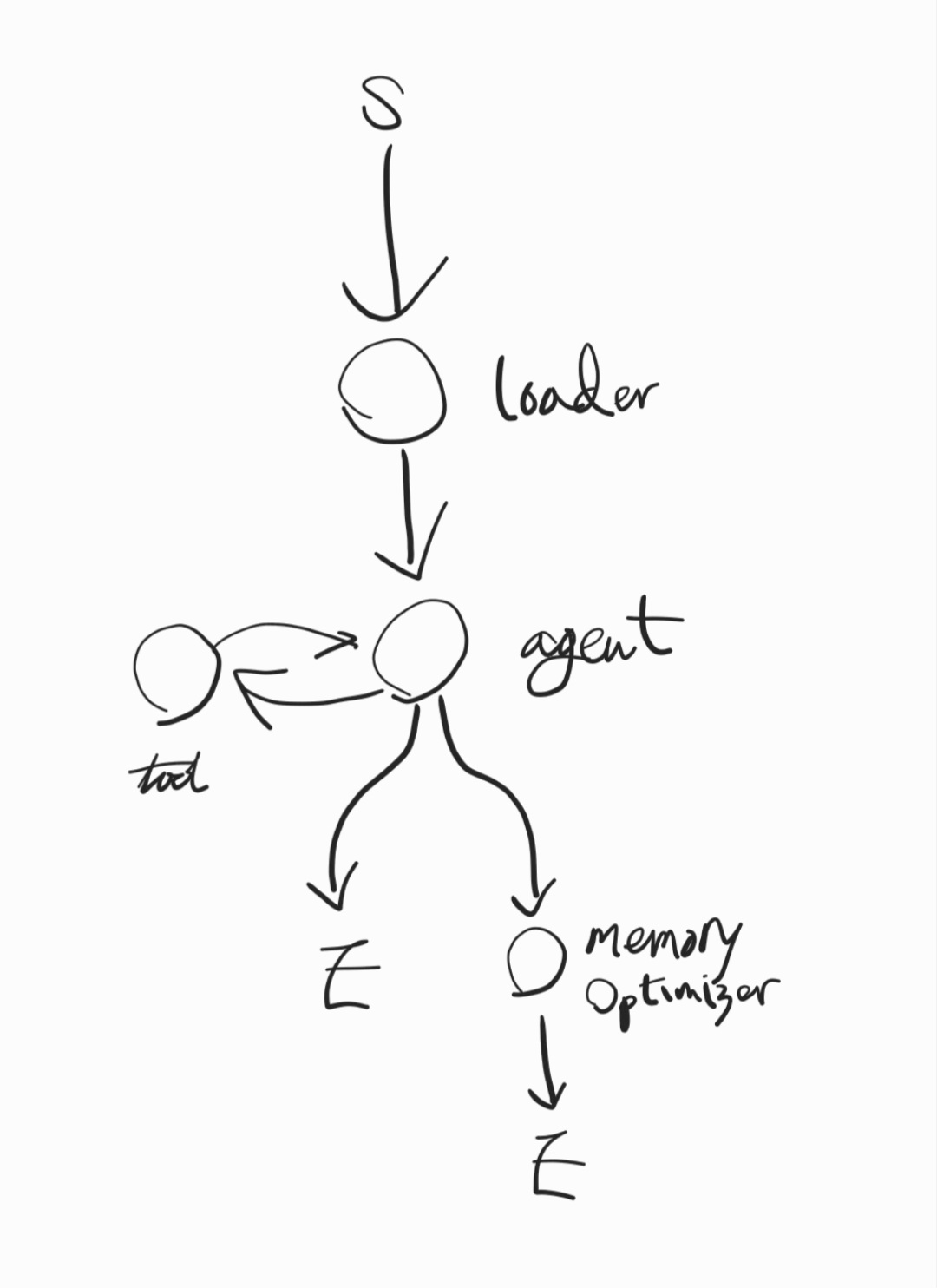
정보를 관리하기 위해 데이터베이스 구조를 생각해보았다. \- Graph DB: 지식 그래프를 생성하고, 그래프의 각 노드가 어느 파일에서 언급되는지 참조하는 관계를 그래프에 추가한다. \- 파일 시스템: 지식과 메타데이터 원본은 로컬 파일로 저장한다. \- Vec
12.11일차. 프로젝트 구조 정리...
프로젝트 구조를 정리하고 있다. 익숙한 환경이 아니라 시간이 더 걸릴 것 같다.
13.12일차. 음성에 관하여...
음성을 실시간으로 입력받아 랭그래프 어시스턴트에게 입력하는 방법을 생각하는 데에 하루를 썼다. 다자간 대화가 조금 골치아픈 과제인 것 같다. 다자간 대화에서 화자 구분과 STT를 동시에 제공해주는 API는 돈이 든다. 게다가 음성을 식별해서 사람의 이름을 맞추주기까지
14.13일차. 프로젝트 구조 정리...
프레임워크 이해도를 확인하기 위해서 프로젝트를 아얘 새로 만드는 걸 좋아하는 편이라, 이번에도 그렇게 잔행했다.Neo4j를 로컬로 옮겼는데, 설정 중에 문제가 생겨서 애를 먹느라 시간을 많이 썼다.
15.14일차. 메모리 최적화 추가.
기존 구현에서는 state.messages 리스트의 크기가 계속 증가한다.Configuration에서 state.messages 리스트의 최대 크기를 제시하고, 워크플로우 실행 중에 현재 크기를 확인하여 메모리 최적화 수행 여부를 결정하도록 분기를 추가했다.
16.15일차. LLM based Knowledge Graph Generation
Multi-turn conversation에서 20개의 데이터와 그 이전의 대화 내용 요약을 가지고 있는 상황.LLM을 활용하여 대화 내용을 기반으로 지식 그래프를 작성하고 이를 Neo4j DB에 저장하려고 한다.몇 가지 방법을 시도했지만 결론부터 말하면 실패. 퀄리티
17.16일차. RTX 3060 VRAM 12GB 탑제된 로컬 AI 머신 구축

처음 데스크탑을 조립했다. 당근에서 중고로 구매한 컴퓨터의 케이스와 쿨러만 교체했다.
18.19일차. 그래프는 나중에 다시... 벡터 DB와 파일 시스템을 임시로 채택
우선 Chroma DB를 사용하도록 구현하고 나중에 여유가 있을 때 그래프 DB를 도입하기로 했다.
19.20일차. ChromaObsidianDB 추가
Chroma DB와 파일 시스템을 결합하여 정보를 저장하는 모듈을 추가했다. 응답을 생성하는 LLM에 직접 도구를 추가하여 테스트 했으나 LLM이 도구를 잘 호출하지 못했다.
20.21일차. 좌우뇌 전략 + 기억 담당 LLM.
기존 좌우뇌 전략에 세 번째 LLM 분기를 추가하여 정보를 기록하고 불러오는 역할을 수행하게 했다. 기능적으로는 인간의 해마와 유사할 것이다.
21.22일차. 파일 시스템 데이터 저장 → Obsidian으로 확인 가능
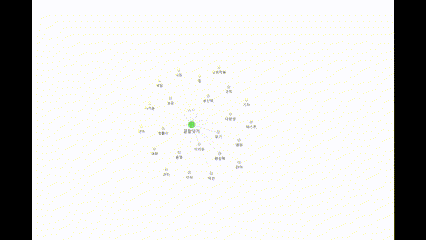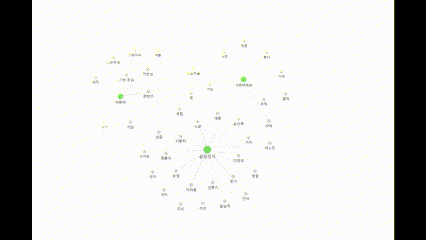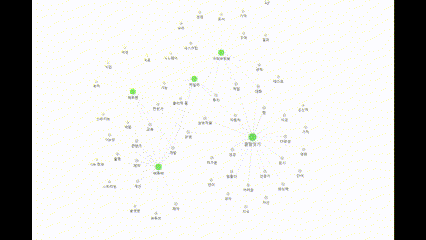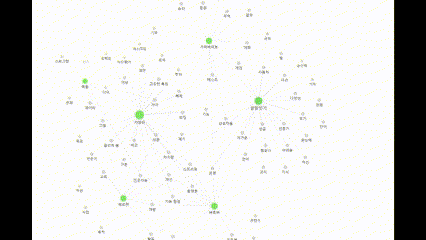
실시간으로 정보를 저장하는 데에 성공 했다.그래프 데이터베이스를 사용하는 대신, 파일 시스템에 Obsidian 저장소를 추가하고 여기에 마크다운 파일을 작성하도록 했다.문제는 파일의 내용을 항상 컴팩트하게 유지하기 위한 방법을 생각하는 것이다.
22.24일차. 원격 작업 환경 구성. Chroma DB 제거.
지난번에 구축한 시스템에 원격으로 접속할 수 있도록 준비했다. 윈도우 기본 제공 앱인 원격 데스크톱 연결을 사용했다.ChromaObsidianDB를 사용하면서, 임베딩 비용에 대해 고민이 컸다. 테스트를 위해서 임베딩을 통한 검색을 제외하고 키워드 검색 방식으로 전환해
23.25일차. 삽질... 보이지 않는 적과 싸우기.
LLM이 도구 호출을 하지 않게되었다.모델 버전을 바꿔보고, 프롬프트를 바꿔보았다.gemini-flash-1.5-001 버전과 002 버전을 번갈아가면서 테스트를 반복했다.일단 동작은 하게 되었다...
24.26일차. 다시 돌아온 갈아엎기 시간.
화이팅...
25.27일차. 갈아엎기...
살려줘...
26.28일차. 다시 처음부터!
에이전트 워크플로우를 고민하는데 사흘을 썼다.실시간 대화를 위한 워크플로우는 지연 시간이 적을 수록 좋으므로, Retriever를 높은 품질, 빠른 속도로 불러오고, llm은 하나만 사용하는 쪽으로 수정할 것 같다.실시간 대화가 아닌 방송 등의 상황에서 쓰이는 워크플로
27.29일차. 이제 LangChain을 놓아줄 때가 왔다. + 쏟아지는 새로운 패러다임...
랭체인은 High-level에서 llm을 다루는 것을 도와준다. 하지만 실제로 도와주는 것은 거의 없는 것 같다. 그냥 llm 제공자의 api를 직접 사용하는 것이 더 나은 상황이 종종 보인다.나는 이제부터 랭체인 없이 개발을 진행해보려고 한다. 코드를 더 간결하
28.30일차. 새로운 프로젝트 구조 적립.
랭체인을 제외한 프로젝트가 정상적으로 작동하는 수준이 되었다.대화 세션을 종료할 때 파일로 요약을 작성하는 기능도 추가했다.
29.31일차. 구조화된 출력과 함수 호출을 동시에 사용하는 방법을 모르겠다.
오늘은 문서를 읽는데 시간을 썼다. 내일도... 아마 그럴 것 같다.현재 카일라의 데스크탑 환경에 문제가 생겼다. 점검을 해야겠다.
30.32일차. 데스크탑 문제... 해결.
갑자기 프리징이 발생하기 시작했다. 데스크탑을 옮기면서 전원을 연결할 때 소리가 났는데, 아마 쇼트가 발생한 것 같다. 데스크탑을 분해해서 부품들을 살펴봤는데, 육안으로 보기에는 이상이 없어 보였다. 결국 운영체제가 설치된 SSD의 고장을 의심하면서 윈도우를 재설치했는
31.33일차. 음성 합성에 관해 조사...
이제 슬슬 STT, TTS에 대해 알아봐야 할 것 같아서 오픈 소스나 API에 대해 찾아보고 있다.
32.34일차. MeloTTS, OpenVoice를 활용하여 Voice Cloning 코드 작성
MeloTTS는 텍스트로부터 정해진 목소리로 음성을 생성한다.OpenVoice는 생성된 TTS 파일의 음성 스타일을 다른 목소리와 유사하게 변환(clone)한다.오늘은 위의 과정이 잘 동작하는 샘플 코드를 작성했다.
33.35일차. TTS 수정, Discord 인터페이스 개발 시작.
TTS의 베이스 모델을 Edge TTS로 변경했다.Voice cloning을 위한 target voice sample을 조정했다.discord.py를 활용한 discord interface 개발을 시작했다.
34.36일차. 저장소 구조 변경, 프롬프팅...
현 시점에서 프로젝트의 저장소는 다음의 구조로 구성되고 있다.오늘은 다른 작업을 하느라 카일라의 작업을 많이 하지 못했다.프롬프트만 조금 수정해서 대화를 매끄럽게 만들고자 했지만, 아직 부족하다.
35.37일차. 치지직 API에 대한 조사.
치지직 API를 다루는 라이브러리가 존재하지만 사용해보니 오류가 나는 것 같았다. 업데이트가 2년 전인 것을 보면 최신화되지 않은 모양이다.다음의 블로그를 참고해서 직접 API 요청을 작성하는 쪽으로 개발할 계획이다: https://blog.ssogari.de
36.38일차. 치지직 api를 chzzkpy 변경
gunyu1019/chzzkpy를 사용하기로 했다.테스트 중에 연령 제한 방송에 대한 오류를 발견해 Issue를 작성했다.
37.39일차. discord, chzzk 서브모듈 테스트
디스코드와 치지직의 서브모듈을 구현하고 테스트했다.모듈 간의 통신을 Flask로 구현했다.
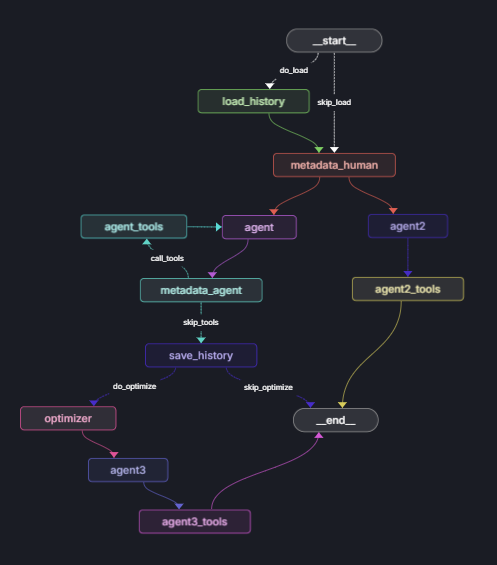
38.40일차. 프로젝트 병합
서브모듈을 분리된 저장소에서 하나의 저장소로 병합했다.현재 core 모듈은 수정되지 않았고, dicord, chzzk 모듈만 수정되어있다.각 모듈을 테스트하기 위해 core를 대신할 stub 코드를 작성했다.
39.41일차. 리팩토링
코어를 수정하기에 앞서 통신에 사용되는 중복된 코드를 제거했다.
40.42일차. 리팩토링된 구조에 맞춰서 모듈 간 인터페이스 수정, 정상 작동 확인
시간이 너무 없다...
41.43일차. 여러 LLM 인스턴스를 동시에 제어하는 방법 공부.
실시간으로 보이지만, 사실은 그렇지 않다는 점을 깨달았다.채팅의 경우는 지연이 다소 생겨도 용인 가능하다.음성 대화의 경우에는 우선 음성을 생성하고 재생하는 동안 다른 작업을 동시에 수행해도 티나지 않는다.이점을 참고해서, 응답과 응답 사이에 백그라운드에서 정보를 더
42.44일차. 구현 계획.
언어 입출력은 단일 모델로 처리해야 지연이 적을 것이다.입력-출력 텍스트 쌍에 대해 백그라운드에서 추가적인 동작을 수행하는 모델이 하나 더 있어야 한다. 이 모델은 대화 내용 분석과 함수 호출을 대신 해주는 역할을 할 것이다. 그리고 이 정보가 다음 입력 단계에 외부
43.45일차. LLM 추가 및 인터페이스와 연결 작업...
디스코드와 치지직에서 수신하는 메시지를 모델에 전달해서 모델이 응답을 생성하는 것 까지는 구현했다.
44.2025년 1월 26일 중간 요약

(썸네일 이미지는 Stable Diffusion에 의해 생성되었다.) Kyla Unit-00는 Neuro Sama같은 버츄얼 AI 스트리머를 만들고 싶어서 시작한 프로젝트였다. MSAI 6기와 병행하느라 진행이 더뎠기 때문에 아직도 버츄얼 캐릭터 모델과 연결하는 단계