1. Introduction
1.1 Problem statement
Lack of controlled comparisons in the curation of pretraining datasets for language models.
최근 LLM 사전학습 데이터에 관한 연구에서는 데이터 필터링, 중복 제거, 새로운 데이터 소스, 데이터 weighting, synthetic data등의 방법으로 효율적인 학습을 위한 데이터 curation의 연구가 진행되고 있다.
하지만, 각자의 연구에서 제안한 data curation 방법을 서로 다른 모델 구조, 연산량 그리고 하이퍼파라미터로 학습된 모델을 대상으로 평가 하는 것은 공정한 비교가 어렵다. 예를 들어, 데이터셋 A로 학습한 모델이 데이터셋 B로 학습한 모델보다 성능이 좋다고 했을 때, 정말 데이터셋 자체가 더 좋은 것인지 아니면 A를 학습한 모델 구조가 B를 학습한 모델 구조보다 좋은 것인지 명확한 비교가 어렵기 때문이다.
또한 Llama, Mistral, Gemma와 같은 모델들은 학습 데이터셋에 대한 간략한 설명만 제공할 뿐 전체 학습 데이터를 공개하지 않는다. 이러한 문제로 인해 어떤 데이터 조합이 언어모델 사전학습에서 SoTA 성능을 달성하게 하는지 분석에 어려움을 준다.
1.2 Proposed DCLM - summary
데이터셋 curation 방법이 언어모델 사전학습에 미치는 영향을 공정하게 비교하기 위해 본 연구에서는 DCLM을 제안한다. DCLM을 활용하면 연구자들은 학습 데이터 및 curation 알고리즘을 제안하고, 고정된 학습 방법에서 학습된 언어모델을 공정하게 평가할 수 있다.
이를 위해 우선 common-crawl 기반의 240T token으로 구성된 코퍼스 DCLM-Pool을 소개한다. DCLM-Pool은 공개 코퍼스 중 가장 큰 규모로 DCLM filtering track의 기반이 된다.
(DCLM filtering track: DCLM-Pool에서 최적의 데이터 조합을 curation 하는 작업)
또한, 언어 모델 학습에는 매우 큰 비용이 들기 때문에 서로 다른 연산량과 데이터 규모에서의 학습 전략에 따른 성능을 이해하는 것이 필수적이다. 본 연구에서는 어느 데이터셋이 LLM 학습에 효율적인지 판단하기 위해 실험적인 학습을 진행할 때, 400M 파라미터의 모델로 충분히 더 큰 모델에서의 경향성을 예측할 수 있다는 것을 실험적으로 확인하였다.
DCLM의 초기 작업으로 학습 데이터셋 구성과 학습 규모에 따른 416개의 baseline 실험을 진행한다. 본 실험의 결과로 model-based filtering이 가장 효율적인 데이터 curation 방법임이 입증되었다. 또한, filtering 모델에 따라 MMLU 점수가 35%에서 44%로 차이가 나는 것을 보였으며, 이는 필터링 모델에 따라 언어모델 성능이 크게 차이가 난다는 것을 의미한다. 흥미로운 점은 positive-negative로 직접 annotation한 데이터로 학습한 이진 분류기가 다른 filtering 모델에 비해 가장 좋은 성능을 보인다는 점이며, 사람의 품질 판별은 고품질 데이터 식별에 한계가 있음을 보인다는 점이다.
2. DCLM Leaderboard
저자들은 데이터셋 선택 방법에 따른 공정한 LLM 성능 측정을 위해 DCLM Leaderboard를 제공한다. 이번 섹션에서는 다음의 순서로 DCLM Leaderboard에 대해 상세히 다룬다:
- DCLM-Pool
- Selecting the scale of parameters
- Filtering and Mixing
- Training model with fixed hyperparameters
- Evaluation
2.1 DCLM-Pool
DCLM-Pool은 2023년 이전 common-crawl 데이터로 200B 개의 문서(300TB), 240T 토큰으로 구성된다. DCLM 리더보드 제출 시 공정한 평가를 위해 decontamination을 진행해야 하며 decontamination tool은 저자들이 제공한다.
2.2 Selecting the scale of parameters
연산 자원이 서로 다른 연구자들도 DCLM을 활용할 수 있도록 하며, 스케일링 연구를 위해 DCLM에서는 세 컴퓨팅 규모의 경쟁 규모를 구축하였다.

여기에서, Scale은 (모델 파라미터 수)-(Chinchilla multiplier)를 의미한다. 모델 파라미터 수를 , Chinchilla multiplier를 라고 할 때, Scaling-law에 따라 모델 파라미터 수에 따른 학습 토큰 수 는 다음과 같이 정의한다.
하지만, 작은 규모의 모델(400M, 1B)에서 이점을 보이던 데이터셋 구성이 큰 규모의 모델(7B)에서도 동일한 이점을 보인다고 보장할 수 없다는 문제가 있다. 이 우려를 검증하기 위해 400M, 1B, 7B 모델에 대해 10가지 curation 방법에 따른 성능을 실험해 보았다.
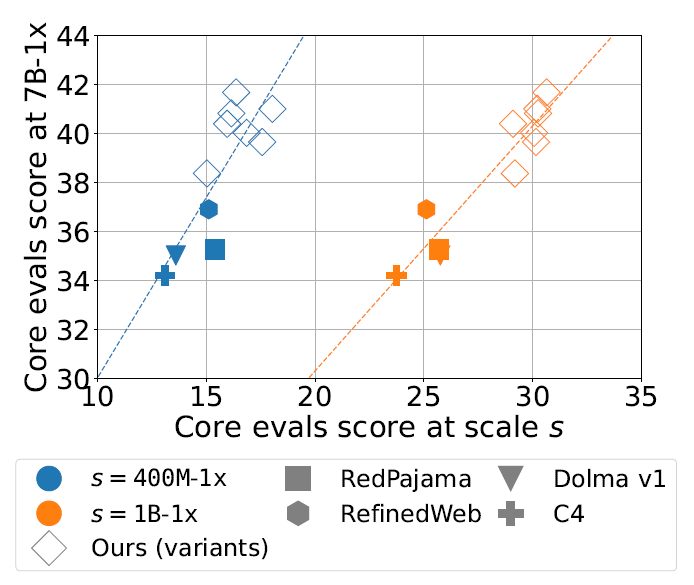
여기에서, x축은 400M, 1B 파라미터의 모델 성능이고 y축은 7B 모델의 성능을 나타낸다. 두 경우 모두 correlation 0.885와 0.919로 큰 상관 관계를 보인다. 이는 소규모 모델로 찾은 curation 전략은 대규모 모델로도 잘 이전된다는 점을 시사한다.
또한 추가적인 실험에서 데이터셋으로 인한 개선 효과는 학습 파라미터와 독립적이라는 결론을 내렸다.
Dataset improvements are largely orthogonal to training hyperparameters
2.3 Filtering and Mixing
모델의 크기 및 학습 토큰 수를 선택한 이후, 다음의 두 가지 트랙을 선택할 수 있다.
1. Filtering track
2. Mixing track
먼저, filtering track은 데이터 선택 알고리즘을 통해 DCLM-Pool에서 데이터를 선택하는 것이다. Mixing track은 DCLM-Pool 뿐만 아니라 외부 데이터 및 synthetic 데이터도 활용할 수 있다.
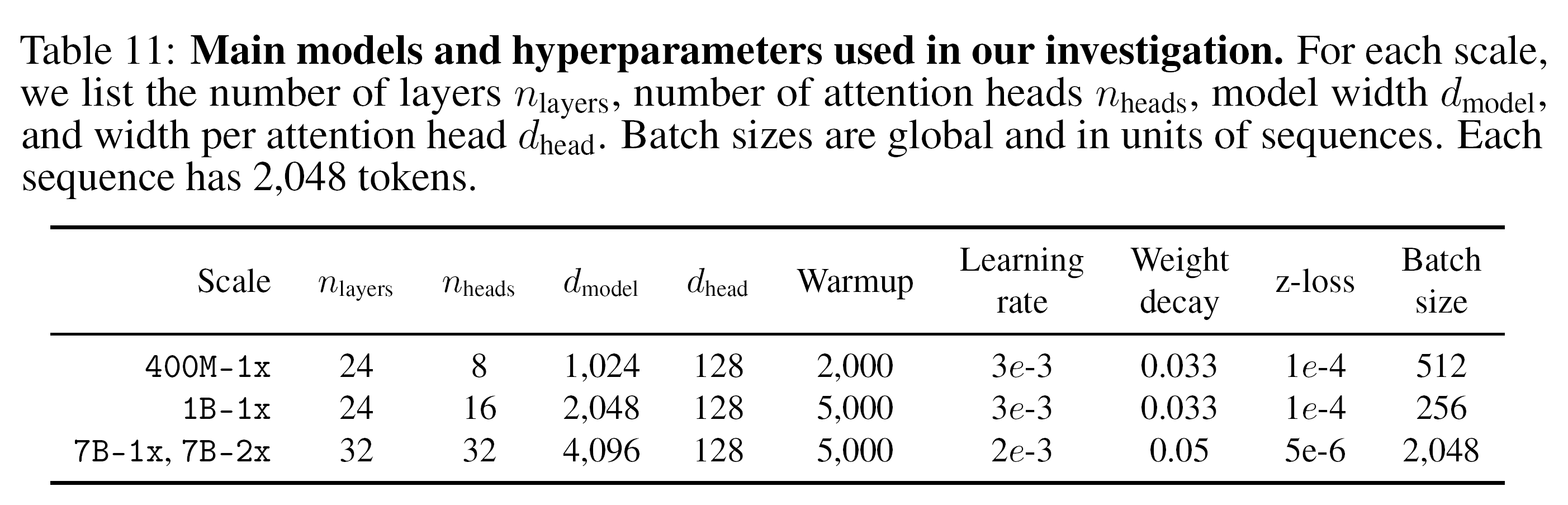
2.4 Training
Decoder-only 모델을 대상으로 하며, 학습 세부 사항은 다음과 같다:
- 기본적으로 normalization은 bias 없는 LayerNorm 사용
- query와 key의 안정성을 위해 qk-LayerNorm 사용
- SwiGLU가 적용된 MLP layer
- Depth-scaled initialization 적용
- Sequence length 2048
- EOS 토큰으로 구분된 sequence packing
- 한 샘플의 서로 다른 문서도 attention 허용 (문서 간 attention masking을 실험해본 결과, downstream task에서 효과가 미미함)
- 기본적인 causal language modeling 사용
- 안정적인 logit 범위를 위해 z-loss 활용
Hyperparameter는 다음을 따른다:
2.5 Evaluation
평가 데이터셋은 LLM-Foundry 기반으로 구축된 53개의 downstream task로 구성되어 fine-tuning 없이 base model의 성능을 검증하도록 설계됨.
다음의 주요 성능 지표 3가지를 측정:
1. MMLU-5shot
2. CORE: 53개 task 중 모델 규모에 따른 성능 편차가 적은 22task. 여기에서 task에 따른 accuracy를 정규화해서 0점은 random guessing을, 1점은 100% 정확도를 의미함.
3. EXTENDED: 전체 53개 task의 평균 점수
3. Building high-quality datasets with DCLM
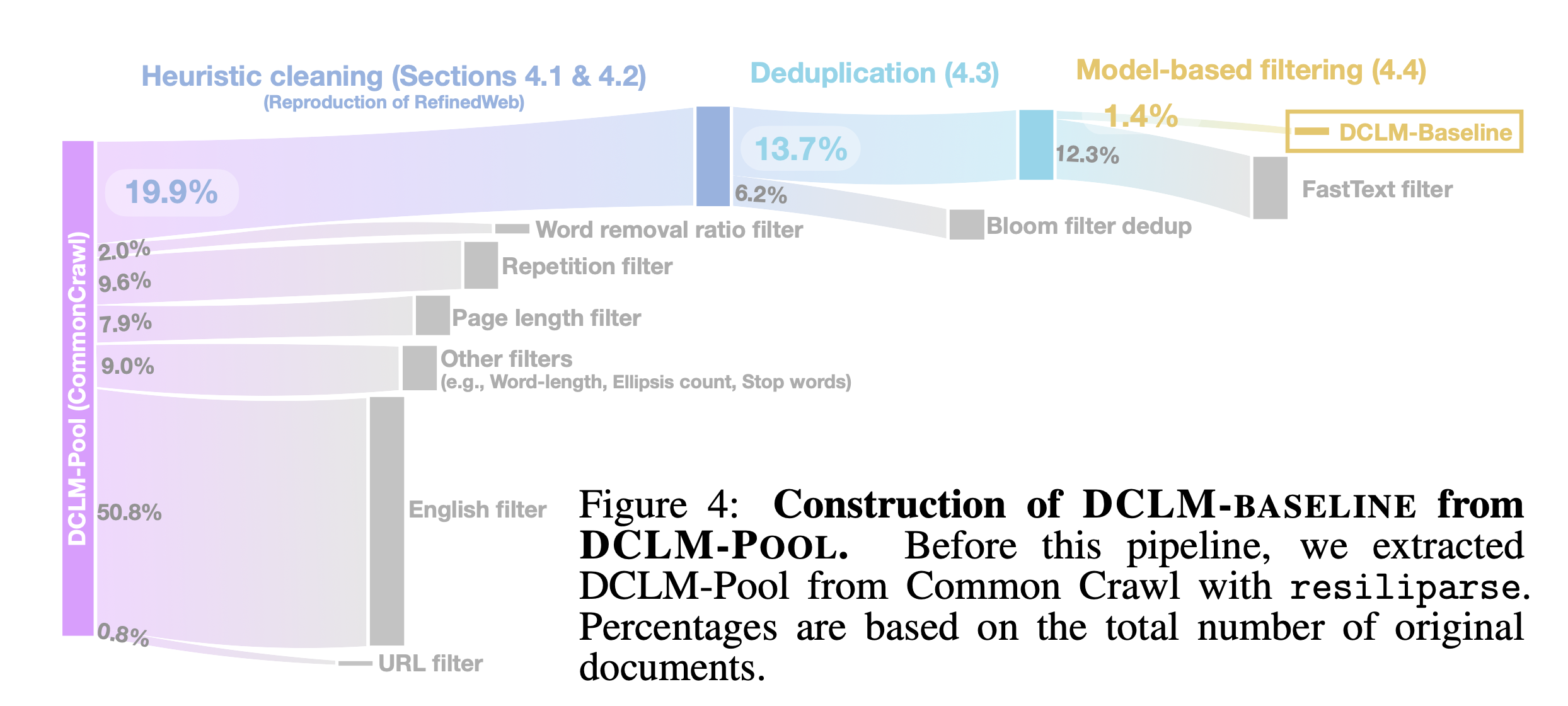
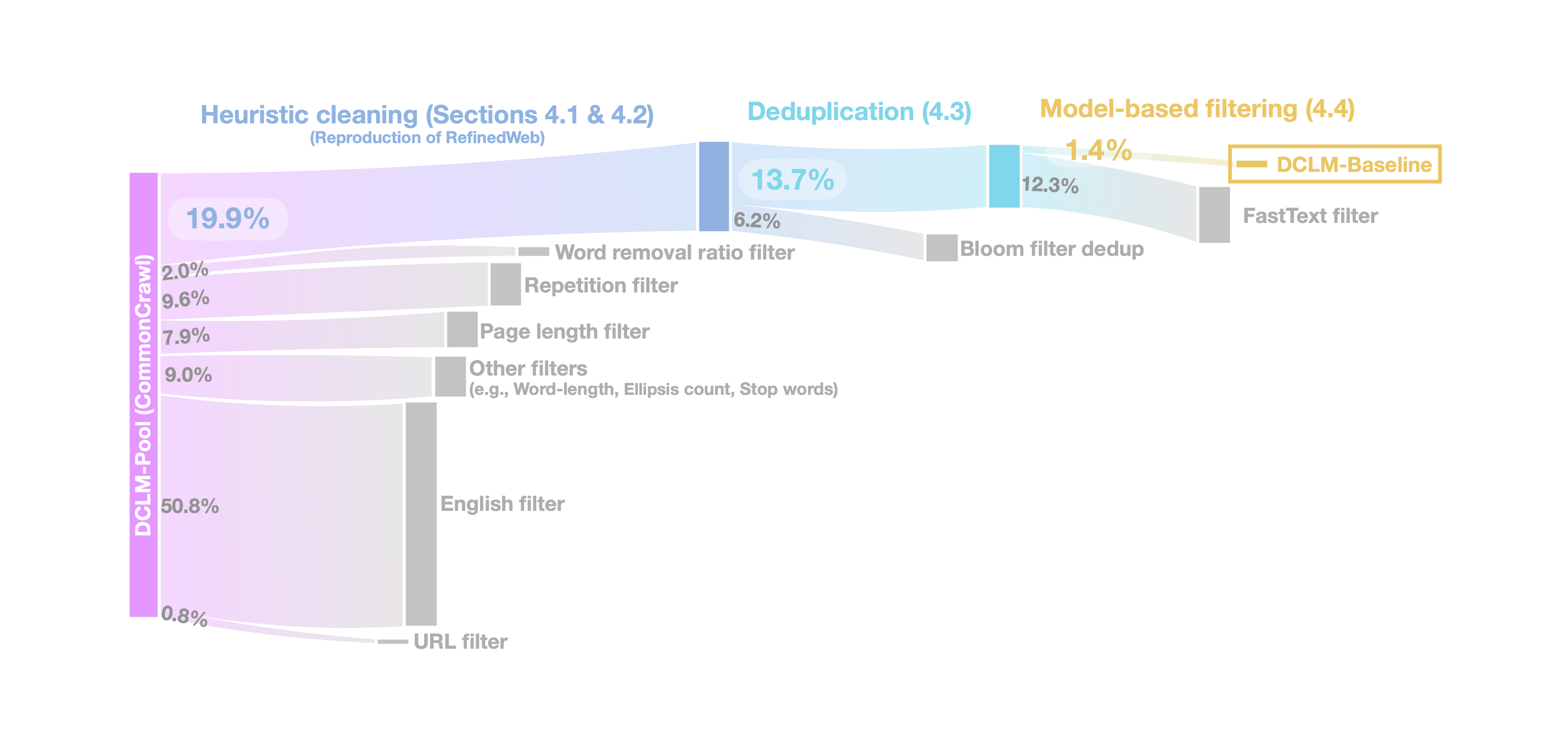
DCLM에서 제안하는 DCLM-Baseline은 DCLM-Pool에서 고퀄리티 데이터를 curation한 데이터셋이다. 이번 섹션에서는 DCLM-Baseline을 어떤 방법으로 구축하는지 다룬다. 구체적으로, 다음의 순서를 따른다:
- open-source 데이터셋(C4, RefinedWeb, RedPajama, Dolma-V1) 평가
- Text extraction method (from HTML)
- Deduplication method
- Model-based filtering
- Mixing in high-quality sources
- Data contamination analysis
3.1 Evaluating open-source dataset
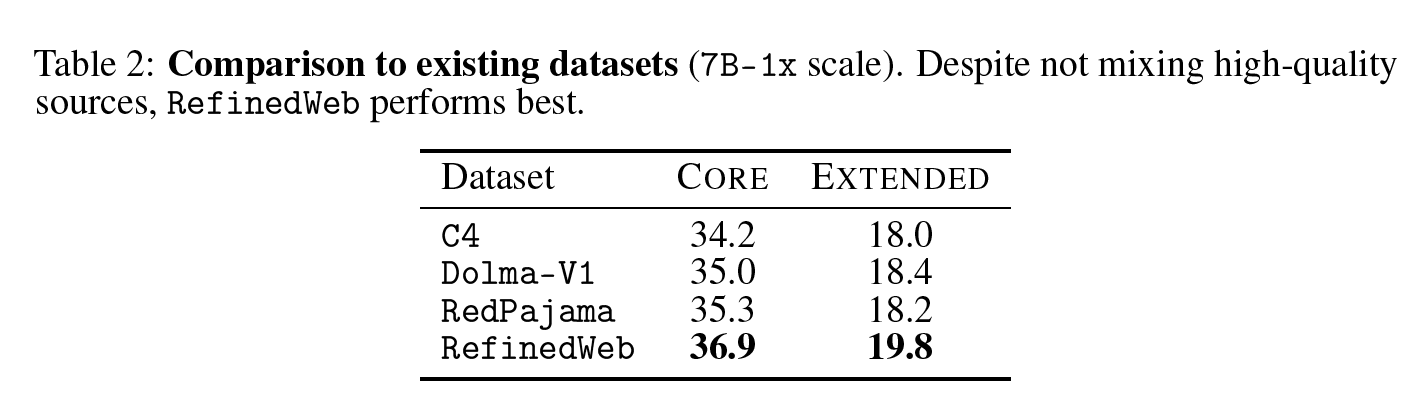
Table 2는 C4, Dolma-V1, RedPajama, RefinedWeb 데이터셋에 따른 CORE와 EXTENDED 점수를 나타낸다. 네 가지 데이터셋 모두 다양한 heuristic filters와 데이터 정제 작업을 거쳤지만, RefinedWeb이 가장 성능이 좋은 것을 보인다. 흥미롭게도, Dolma와 RedPajama는 Wikipedia와 같은 high-quality 데이터가 섞인 반면, RefinedWeb은 common-crawl에서 필터링 및 deduplication만 적용한 데이터셋이다. 이는 RefinedWeb이 상대적으로 강한 필터링 방법을 적용했음을 시사하고, DCLM-Baseline에서는 RefinedWeb의 필터링 방법을 차용한다.
3.2 Text extraction method
Text extraction은 raw HTML에서 텍스트를 추출해오는 단계이다. 이 단계의 효과를 이해하기 위해 1)resiliparse, 2) trafilatura, 3) WET 방법을 비교한다.
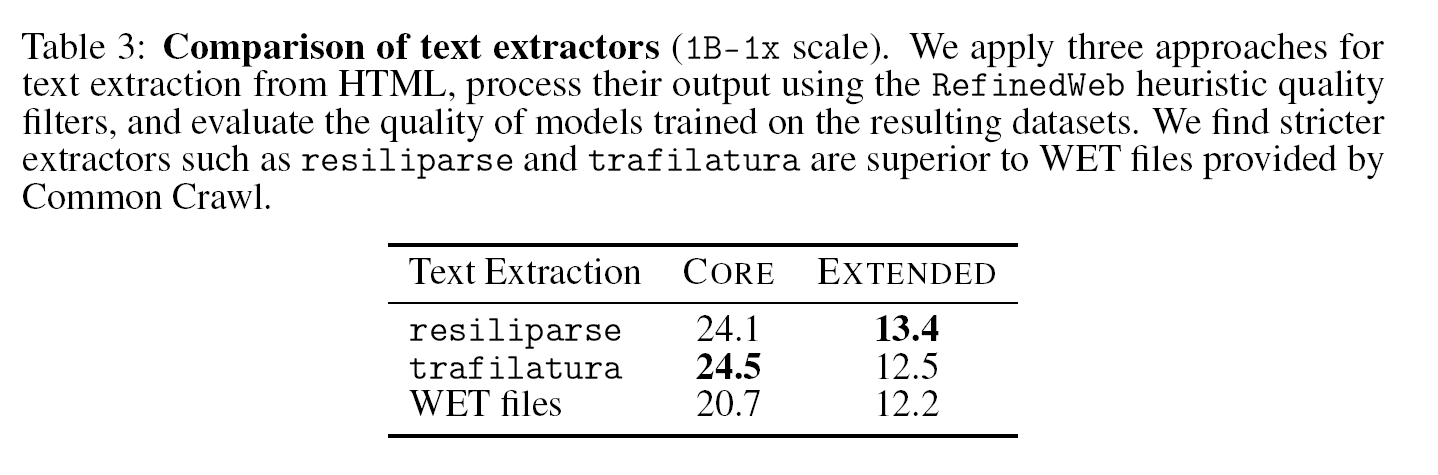
위의 표는 각각의 방법으로 HTML문서에서 텍스트를 추출한 뒤, RefinedWeb의 heuristic quality filter를 적용한 데이터셋으로 1B scale의 모델에 학습한 결과이다. C4, RedPajama, Dolma-V1과 같은 대부분의 open-source 데이터셋이 WET extraction을 사용한다는 점에서 이 부분은 중요하다. resiliparse와 trafilatura가 비슷한 downstream 성능을 보이지만, resiliparse가 8배 빠르기 때문에 더욱 실용적인 방안이다.
3.3 Deduplication
웹 데이터 특성 상 중복되는 데이터나 거의 유사한 데이터 샘플이 많다. 이렇게 중복되는 데이터를 제거하여 1) 데이터의 다양성을 늘리고, 2) computing budget을 절약한다.
본 연구에서는 MinHash 알고리즘과 Bloom filter를 사용한다. 두 방법이 비슷한 성능을 보이지만, Bloom filter가 10TB가 넘는 데이터셋에서 더 빠른 속도를 보인다. 따라서 DCLM-Baseline 구축에는 Bloom filter를 활용한다.
3.4 Model-based quality filtering
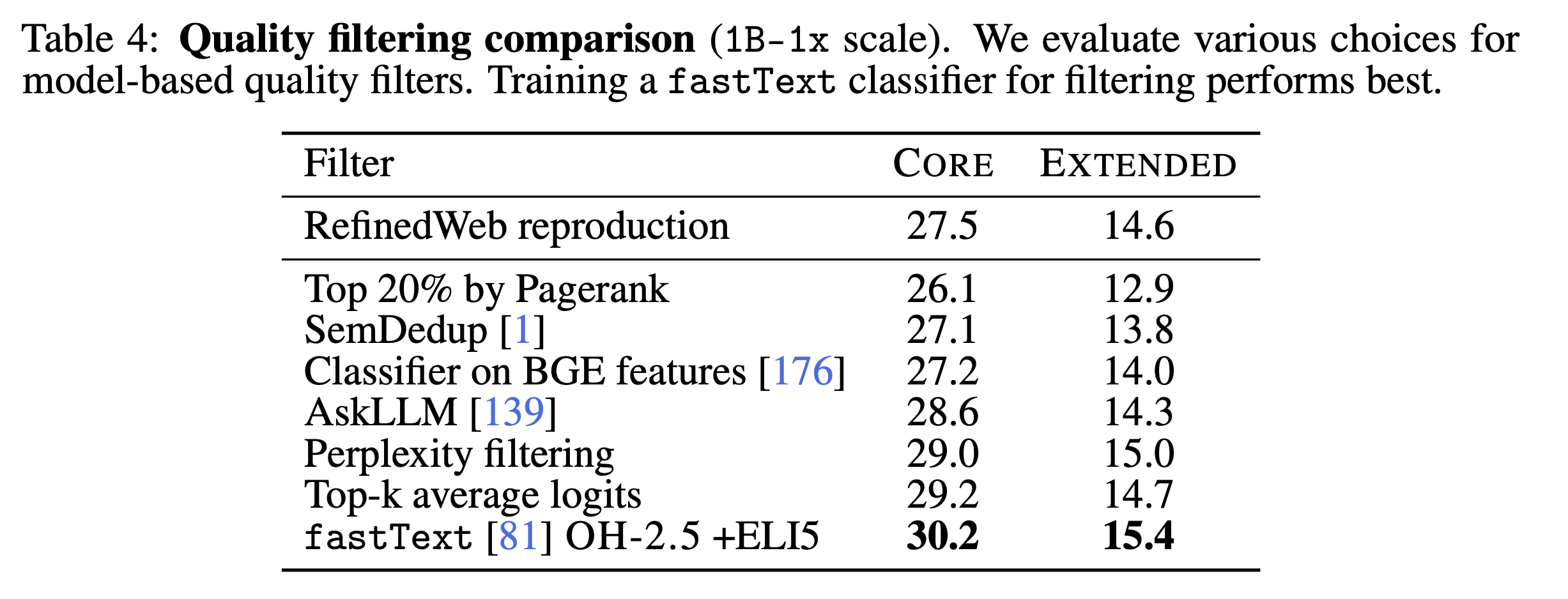
DCLM-Baseline 구축의 마지막 단계로 model-based filtering을 진행한다. CoLoR filter, fineweb-classifier 등의 연구에서 모델 기반으로 필터링 하는 것이 downstream 성능 향상을 보였다.
DCLM에서는 다음의 방법을 실험하여 어떤 방법이 가장 효과적인지 보인다:
- 1) PageRank score filtering: page rank 알고리즘을 통해 연결이 많이 되어 있는 문서를 남김 (연결이 많이 되어 있으면 중요한 문서로 판단)
- 2) Semantic Deduplication (SemDedup)
- 3) Linear classifiers fit on pretrained BGE
- 4) AskLLM method: LLM에게 해당 데이터 샘플이 유용한지 물어보는 방법
- 5) Perplexity filtering: reference 모델에 데이터 를 입력했을 때 perplexity 점수가 낮으면 고품질 데이터라고 판단.
- 6) Top-k average logits filtering: 한 개의 데이터 포인트 에 대하여, reference 모델에 를 입력했을 때, top-k 예측 안에 가 있는 경우가 많으면 고퀄리티 데이터로 판단.
- 7) fastText binary classification: 고품질 데이터 와 랜덤 웹 샘플링 데이터(저품질으로 가정) 를 입력하여 binary classification 진행.
여기에서, Perplexity filtering과 Top-k logit filtering의 경우 154M 파라미터의 casual language model을 구축하여 Wikipedia, RedPajama, peS2o를 통해 학습한 모델을 사용한다.
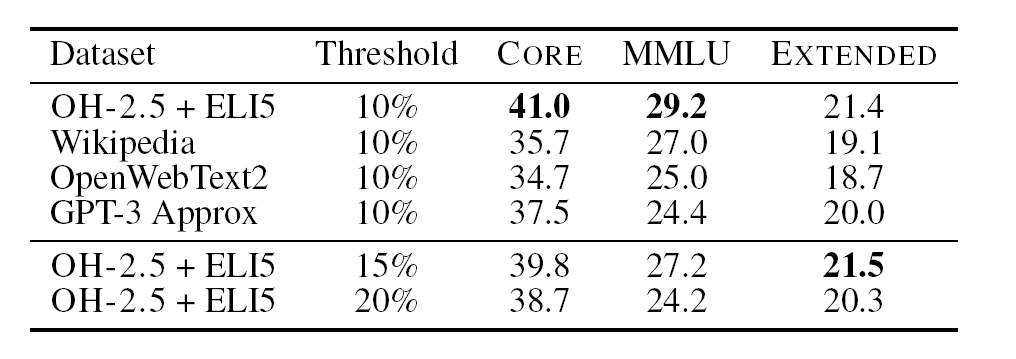
또한, fastText의 경우 Wikipedia, OpenWebText2, RedPajama-books 및 OpenHermes2.5(OH-2.5), ELI5(high-quality reddit QA data)를 조합하여 실험적으로 성능을 측정한다. 흥미로운 점은, OH-2.5와 ELI5를 조합하여 fastText 모델을 학습하여 필터링한 데이터가 LLM 학습에서 가장 좋은 성능을 보인다는 점이다. OH-2.5와 ELI5는 instruction-following 포맷으로 구성되어 있다는 점을 주목해야 한다.
3.5 Dataset mixing
일반적으로 LLM 사전학습 코퍼스는 web 코퍼스와 high-quality 코퍼스를 혼합하여 사용한다. Llama와 RedPajama의 경우, 66% common-crawl(web)과 33%의 high-quality data(Wikipedia, Books, Stack exchange, arXiv, Github)을 혼합하여 학습했다. 이러한 Mixing 전략의 이점을 알아보기 위해 web data로 common-crawl의 subset인 DCLM-Baseline, RedPajama, RefinedWeb, C4를 사용하고, 혼합 유무에 따른 성능을 비교한다.
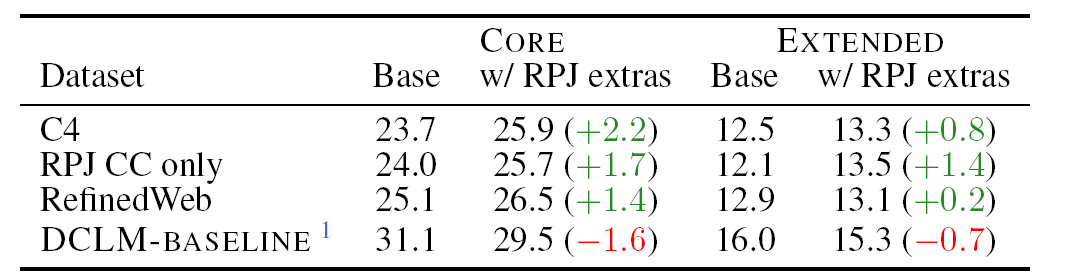
C4, RedPajama, RefinedWeb의 경우 high-quality 데이터를 함께 학습했을 때 성능이 개선되는 반면, DCLM-Baseline에서는 성능이 하락한다. 이는 잘 필터링 된 데이터의 경우 high-quality 데이터를 섞으면 성능이 떨어짐을 시사한다.
3.6 Decontamination
MMLU 기반으로 decontamination을 진행한다. MMLU의 마지막 문장(질문)과 선택지 중 하나를 포함하는 문서가 있다면, 질문 및 선택지와 일치하는 부분을 삭제한다. (재현율을 높이기 위해 마지막 문장만 선택)
Decontamination 결과는 신기하게도 성능이 상승한다.

