LLM from scratch
1.DataComp-LM (DCLM)
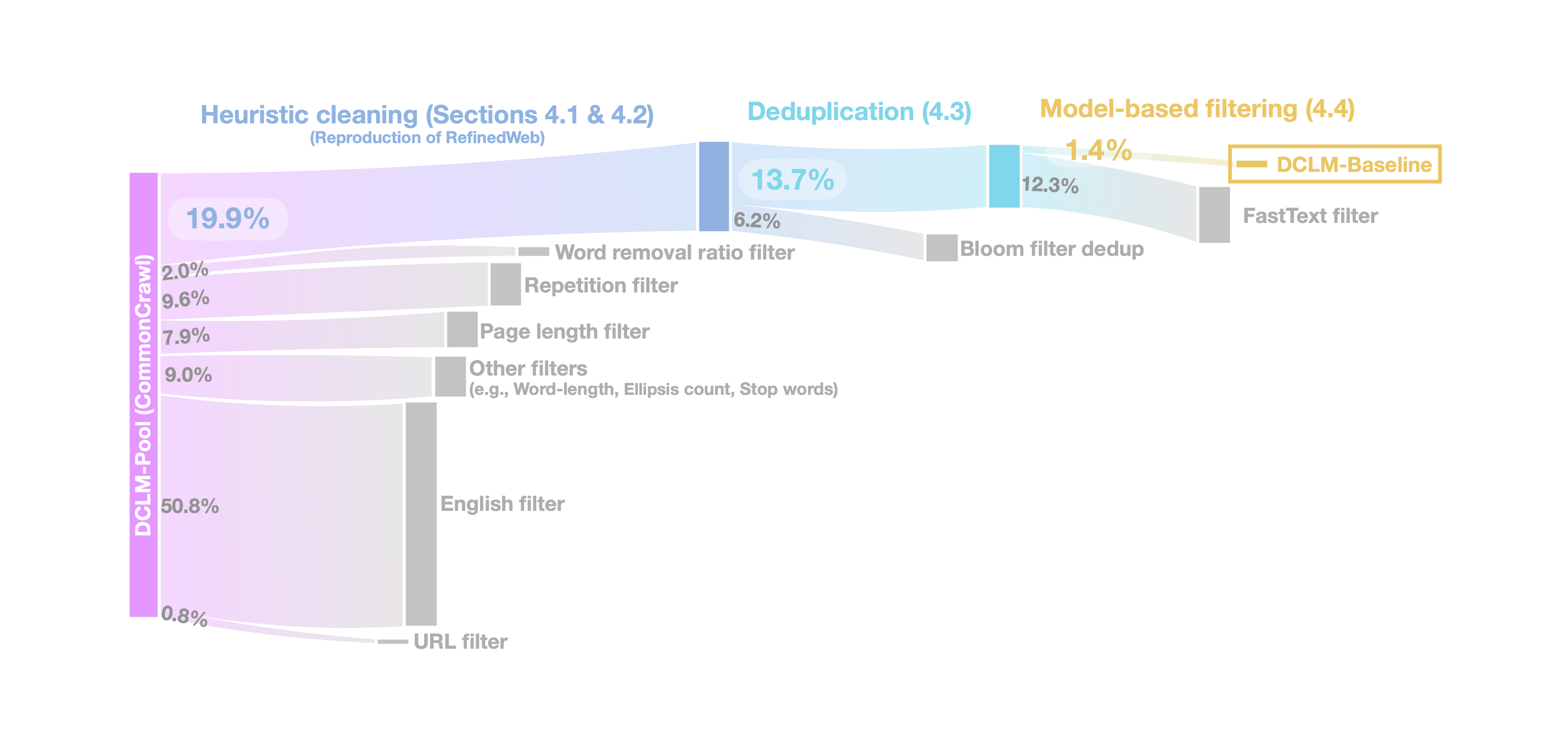
1. 서론 1.1 문제 정의 > Lack of controlled comparisons in the curation of pretraining datasets for language models. 최근 LLM 사전학습 데이터에 관한 연구에서는 데이터 필터링, 중복
2025년 4월 19일
1. 서론 1.1 문제 정의 > Lack of controlled comparisons in the curation of pretraining datasets for language models. 최근 LLM 사전학습 데이터에 관한 연구에서는 데이터 필터링, 중복