A/B testing steps
- Pre-requisites
- Experiment Design
- Running Experiment
- Result to Decision
- Post-launch Monitoring
1.Pre-requisites
- Objective & Key Metrics
- Key Metric
- Revenue
- Fair when N(control) = N(treatment)
- Normalize revenue by # of users
- Revenue per user
- Key Metric
- Vatiants
- Control group : checkout
- Treatment group 1: display similar products in checkout
- Treatment group 2: popup similar products window in checkout
- Randomization units
- Users
- Assume enough users
2.Experiment Design
- User to target
- All users?
- Specific segment of users?
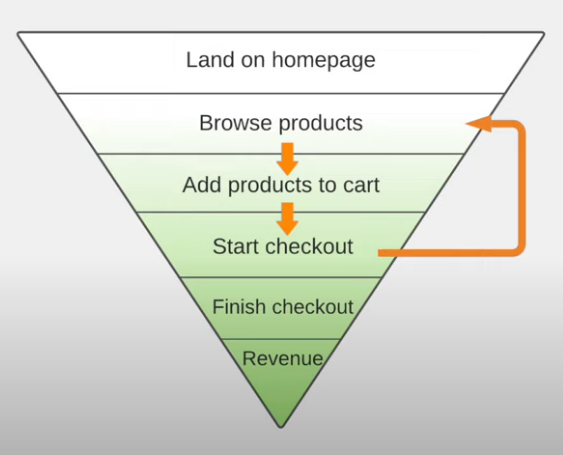
If choose users from "Land on homepage", most of them won't see the feature
therefore, target users should be from "Start checkout"
- Practical significane boundary
- Assume pratical significane:
- Revenue incrase : $2 per user
- Power of the test : 80% (indsutrial standard)
- Significan level : 5% (indsutrial standard)
- Sample size
(sigma = Standard deviation of population / delta = difference between treatment & control
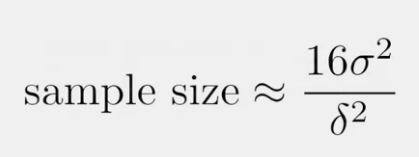
- Assume pratical significane:
Assume sigma is 20 for this example :
16*20^2 / 2^2 = 1600 (we need 1600 unique users in each variant)
therefore 4800 unique users for 3 variants
Other case - Need more samples when
Smaller change, sigma = $1 per suser
Smaller significane level, alpha = 2.5%Decide how long to run (consider 4 factors)
- Rump-up plan: Start with dozens of users
- No bugs
- Traffic can be handled
- Expose to a small population
- Gradually increase percentage
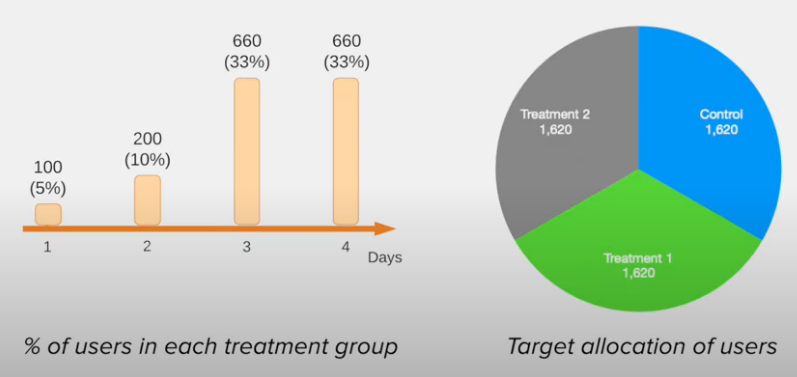
Assume 2000 users per day entering checkout
- Day of week effect
- People behave differently (People make more purchases on wage day)
Recommended - Run experiment for more then 1 whole week
- Seasonality
- Holiday season (Surge in sales during Black Friday)
so the data during the holidays can not be used for analysis and run experiment longer
- Primacy and novelty effects
- users respond to changes differently
3.Running Experiment
running the experiment based on experiment design and collecting log data
Running experiment for too long will not imporve precision any further
4.Result to Decision
Before into analysis
- Sanity checks
- Unreliable if assumptions are violated
Things need to check
1. number of users assigned to groups
2. Latency when loading the webpage (user experience is consistant among each group)
- Hypotheses test to make recommendation
Recommend launching a change when
1. Statistically significant
2. Practically significant
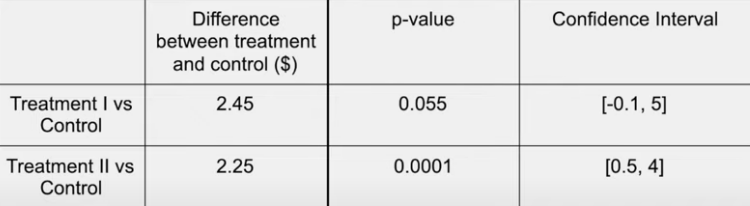
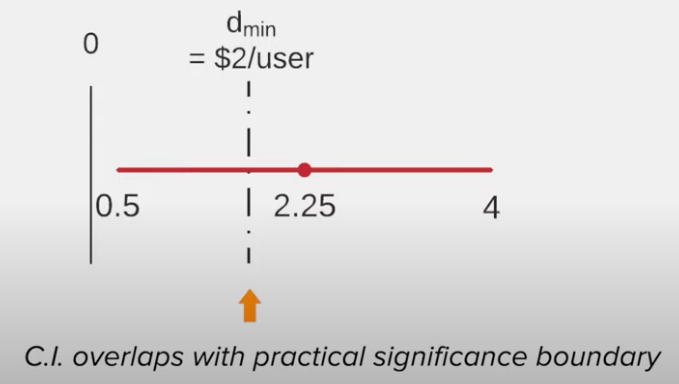
Treatment 1 vs control
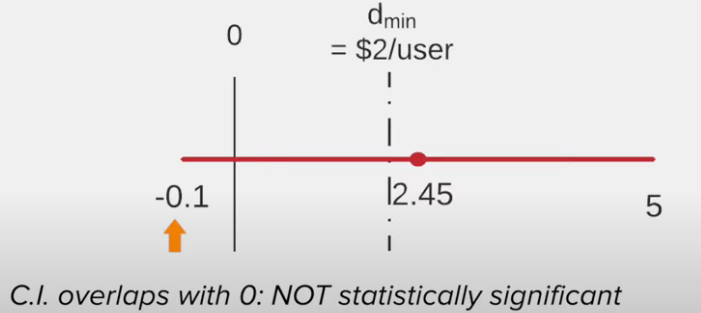
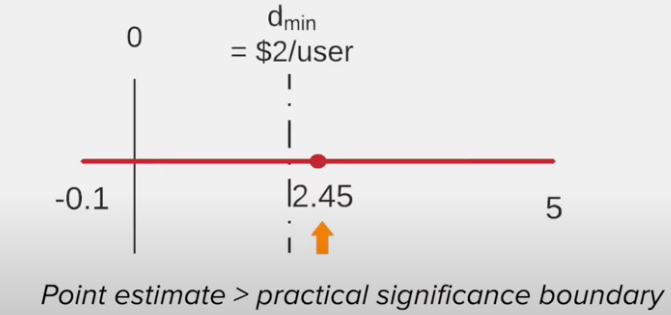
Result of treatment 1 (arguable)
- No impact at all
or - Impact is significant enough
Recommendation of treatment 1
Due to some uncertainty
- Do not launch the change
- Run a follow-up test with more power
Treatment 2 vs control
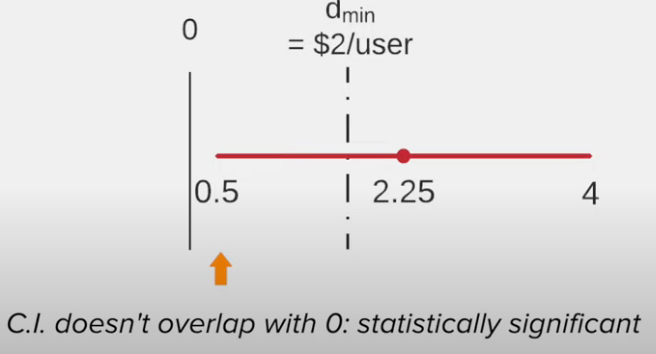
Recommendation of treatment 2
- Run a follow-up test with more power
