Week3 Day3
📋
📌
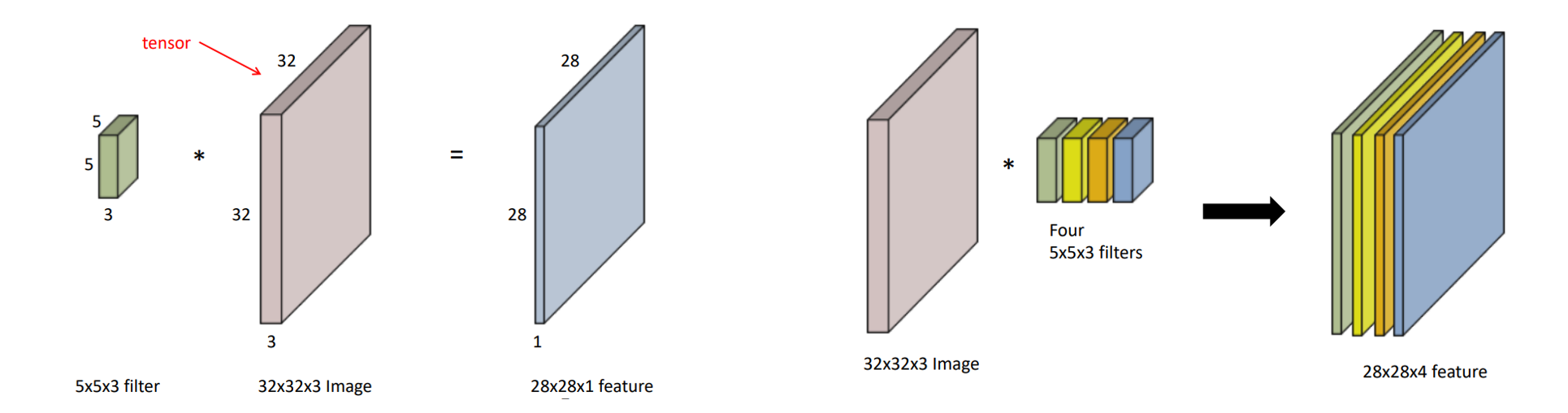
- 연산은 커널()을 입력벡터 상에서 움직여가면서 선형모델과 합성함수가 적용되는 구조
- 입력 크기를 (,), 커널 크기를(,), 출력 크기를(,) 라고하면 출력 크기는 다음과 같이 계산한다.
📌
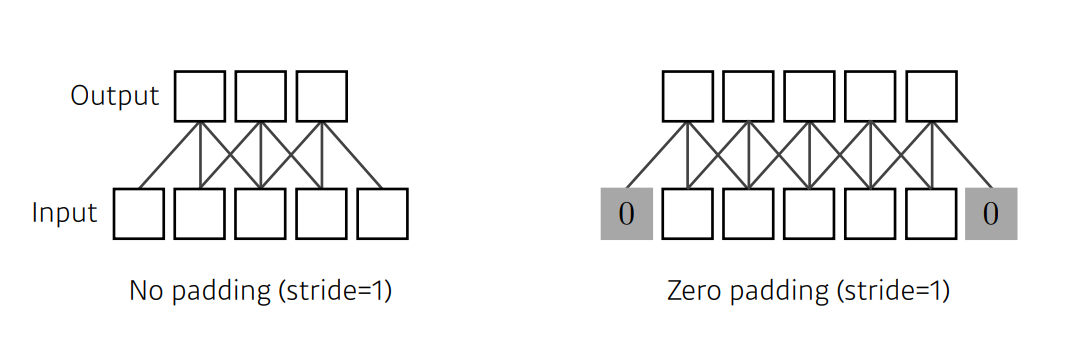
- 패딩()는 합성곱 연산을 수행하기 전, 입력데이터 주변을 특정 값으로 채워 늘리는 것을 말한다. 출력 데이터의 공간적 크기를 조절하기 위해 사용된다.
- 가장자리 정보들이 사라지는 문제가 발생하기 때문에 패딩을 사용
📌
- 스트라이드()는 입력데이터에 필터를 적용할 때 이동할 간격을 조절하는 것, 필터가 이동할 간격을 말한다. 출력 데이터의 크기를 조절하기 위해서 사용
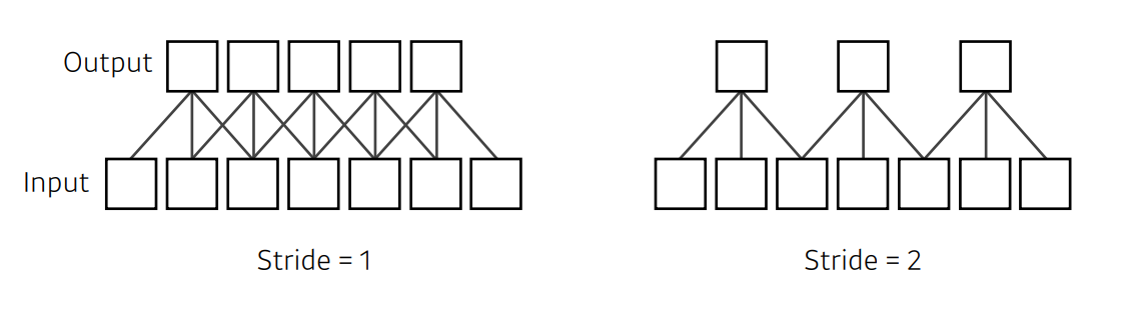
📌
- 입력 데이터, 출력 데이터(, 커널 사이즈
파라미터 수 연산을 위해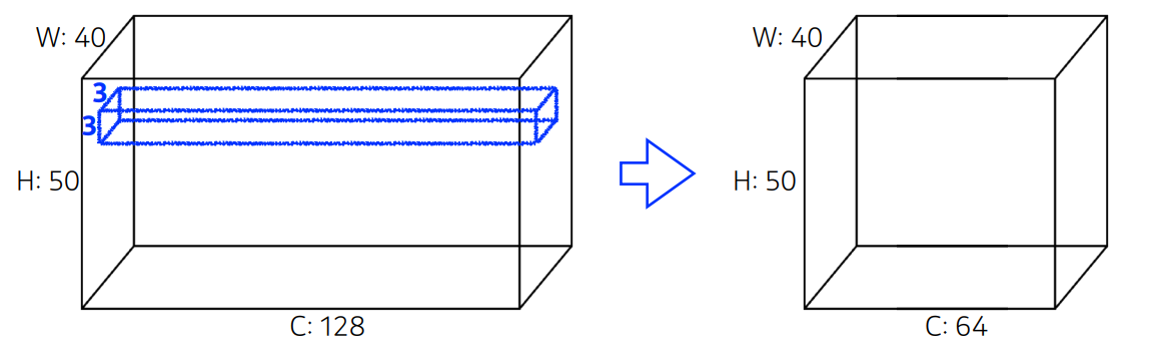
📋
📌
- 처음으로 대회 우승한 모델
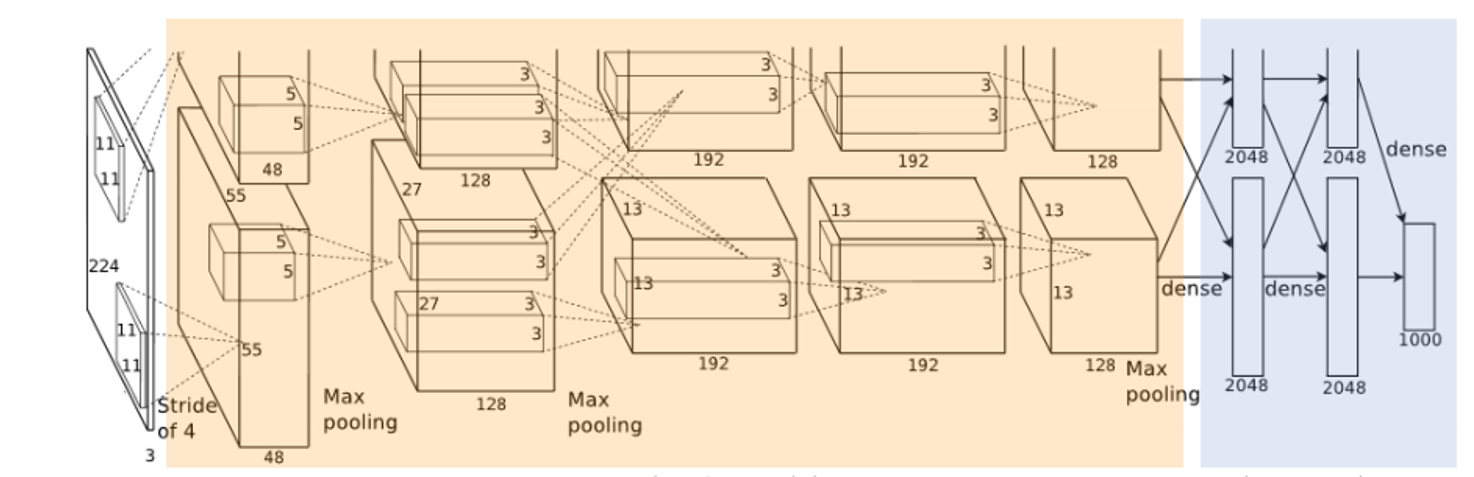
-
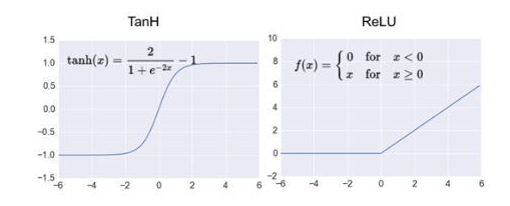
이전 모델에서 사용되었던 함수 대신에 함수를 사용하였다. 특히 활성화 함수의 기울기가 0이되어 학습이 잘 되지않는 문제 개선
- ()
- ()
class AlexNet(nn.Module):
def __init__(self, num_classes=1000):
super().__init__()
self.net = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=96, kernel_size=11, stride=4), # (b x 96 x 55 x 55)
nn.ReLU(),
nn.LocalResponseNorm(size=5, alpha=0.0001, beta=0.75, k=2), # section 3.3
nn.MaxPool2d(kernel_size=3, stride=2), # (b x 96 x 27 x 27)
...
)
self.classifier = nn.Sequential(
nn.Dropout(p=0.5, inplace=True),
nn.Linear(in_features=4096, out_features=4096),
nn.ReLU(),
...
nn.Linear(in_features=4096, out_features=num_classes),
)
def forward(self, x):
x = self.net(x)
x = x.view(-1, 256 * 6 * 6) # reduce the dimensions for linear layer input
return self.classifier(x)📌
- 네트워크의 깊이를 깊게 만드는 것이 성능에 어떤 영향을 미치는지 확인하고자 한 것이 논문의 개요
- 깊이의 영향만을 최대한 확인하고자 필터의 사이즈 으로 고정
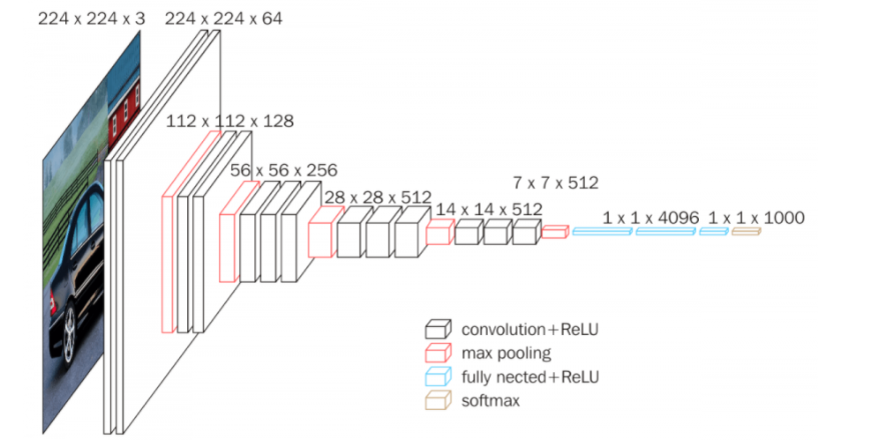
- 필터로 두 차례 컨볼루션 하는 것과 필터로 한 차례 컨볼루션하는 것이 결과적으로 동일한 사이즈의 특성맵 산출
- 필터로 세 차례 컨볼루션 하는 것과 필터로 한 차례 컨볼루션하는 것이 결과적으로 동일한 사이즈의 특성맵 산출
- 차이는 필터를 이용하였을 때 훈련에 필요한 가중치가 줄어들어 학습 속도가 빨라지고 동시에 층의 갯수가 늘어나면서 비선형성을 더 증가시킬 수 있다는 이점
class VGG(nn.Module):
def __init__(self, features):
super(VGG, self).__init__()
self.net = nn.Sequential(
nn.Conv2d(in_channels = 3, 64, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(in_channels = 64, 128, kernel_size=3, padding=1),
nn.ReLU(inplace=True)
nn.MaxPool2d(kernel_size=2, stride=2)
...
)
self.classifier = nn.Sequential(
nn.Dropout(),
nn.Linear(512, 512),
nn.ReLU(True),
nn.Dropout(),
nn.Linear(512, 512),
nn.ReLU(True),
nn.Linear(512, 10),
)
def forward(self, x):
x = self.net(x)
x = x.view(x.size(0), -1)
x = self.classifier(x)
return x📌
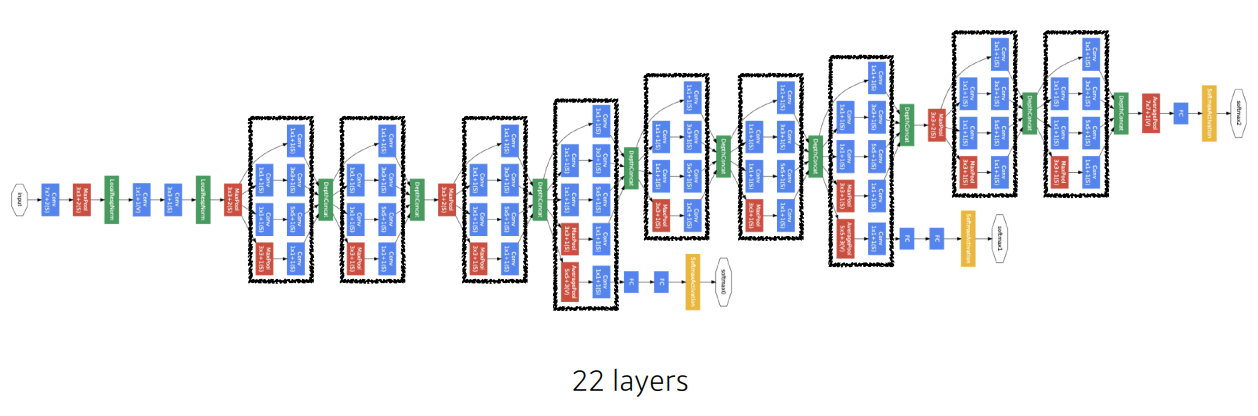
- 또한 좀 더 깊은 네트워크를 만드는 것을 의도하였다. 22층으로 구성
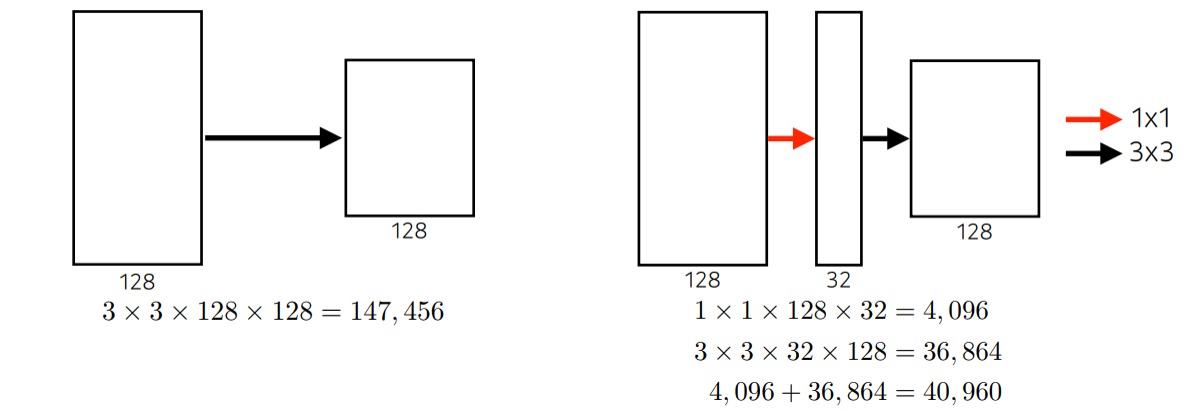
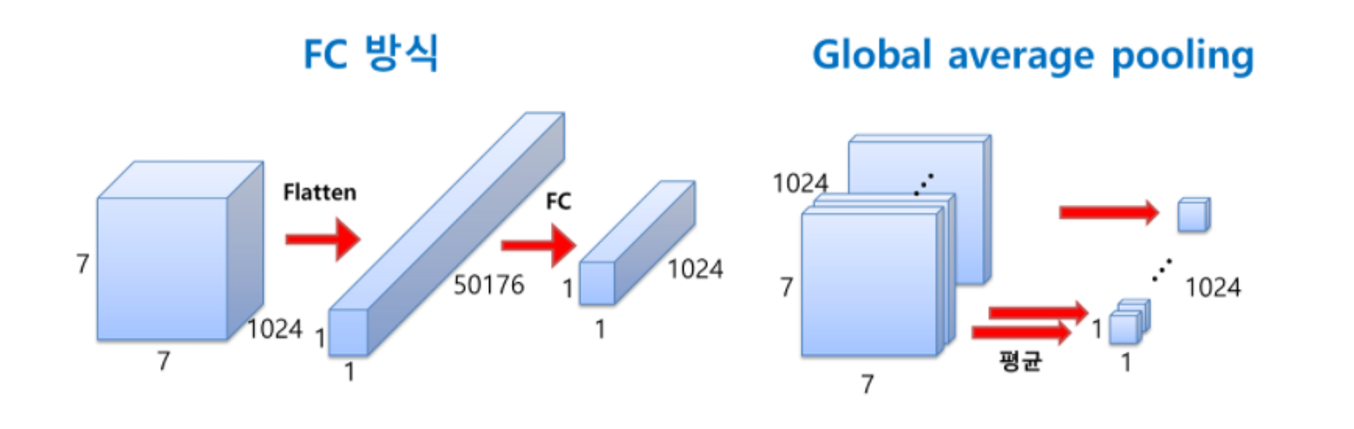
-
컨볼루션은 특성맵의 갯수를 줄여서 연산량을 줄이는 목적으로 사용되었다.
-
기존의 모델들이 한 층에서 동일한 사이즈의 필터 커널을 이용해서 컨볼루션을 해준 것 과 다르게 좀 더 다양한 종류의 특성을 얻기위해 사용되었다.
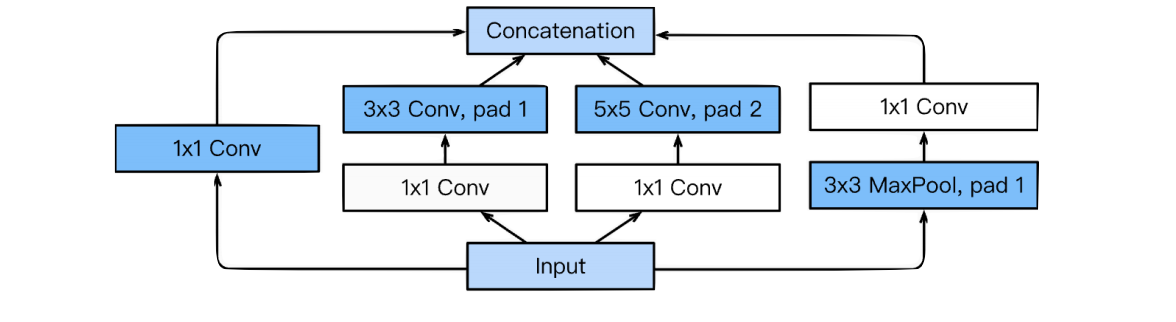
-
, 등에서는 층들이 망의 후반부에 연결되어 있다. 그러나 은 방식 대신에 이란 방식을 사용한다. 을 사용하면 가중치가 단 한개도 필요하지 않다.
class Inception(nn.Module):
def __init__(self, input_channels, n1x1, n3x3_reduce, n3x3, n5x5_reduce, n5x5, pool_proj):
super().__init__()
#1x1conv branch
self.b1 = nn.Conv2d(input_channels, n1x1, kernel_size=1),
#1x1conv -> 3x3conv branch
self.b2 = nn.Sequential(
nn.Conv2d(input_channels, n3x3_reduce, kernel_size=1),
nn.Conv2d(n3x3_reduce, n3x3, kernel_size=3, padding=1),
)
#1x1conv -> 5x5conv branc
self.b3 = nn.Sequential(
nn.Conv2d(input_channels, n5x5_reduce, kernel_size=1),
nn.Conv2d(n5x5_reduce, n5x5, kernel_size=5, padding=2),
)
#3x3pooling -> 1x1conv
#same conv
self.b4 = nn.Sequential(
nn.MaxPool2d(3, stride=1, padding=1),
nn.Conv2d(input_channels, pool_proj, kernel_size=1),
)
def forward(self, x):
return torch.cat([self.b1(x), self.b2(x), self.b3(x), self.b4(x)], dim=1)
📌
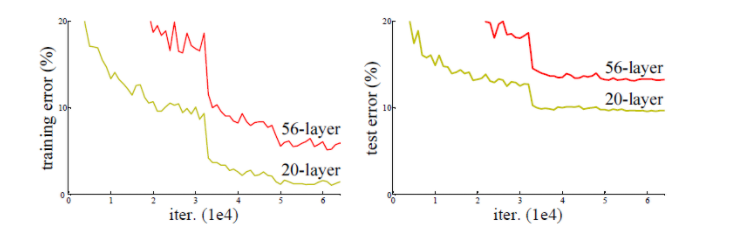
- 급속하게 층이 깊어진 네트워크 152개의 층을 쌓은 모델
- "층을 깊게 하면 무조건 성능이 좋아지는가? 기존의 방식으로는 층을 무조건 깊게 쌓는 것은 능사가 아니다 ( )
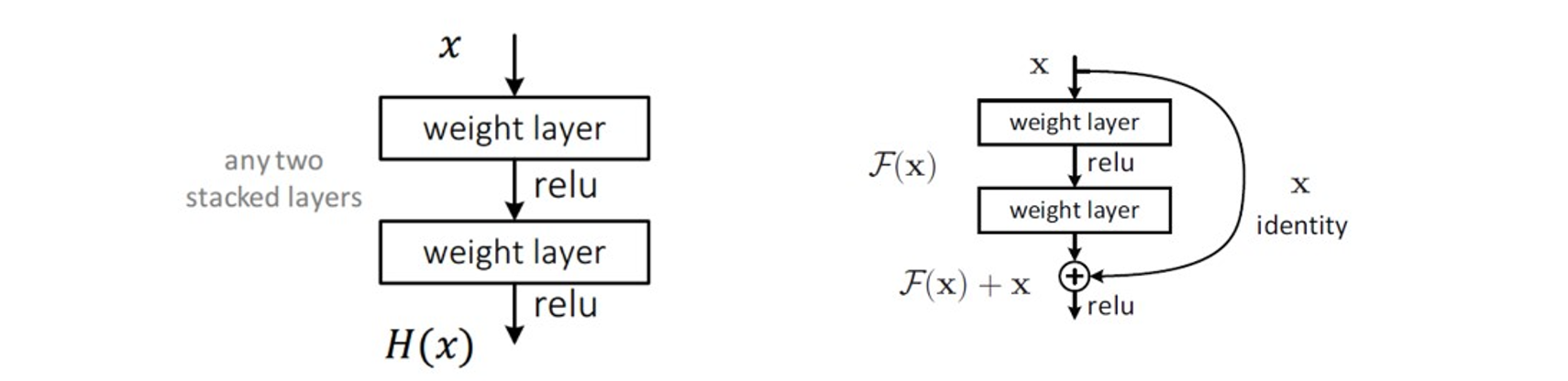
-
을 이용해 네트워크의 난이도를 낮춘다.
가 실제로 내재한 인 을 곧바로 학습하는 것은 어려우므로 대신 잔차()인 = - 를 학습한다.
-> 문제를 줄일 수 있음
class BasicBlock(nn.Module):
def __init__(self, in_channels, out_channels, stride=1):
super().__init__()
#residual function
self.residual_function = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=stride, padding=1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True),
nn.Conv2d(out_channels, out_channels * BasicBlock.expansion, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(out_channels * BasicBlock.expansion)
)
#shortcut
self.shortcut = nn.Sequential()
#the shortcut output dimension is not the same with residual function
#use 1*1 convolution to match the dimension
if stride != 1 or in_channels != BasicBlock.expansion * out_channels:
self.shortcut = nn.Sequential(
nn.Conv2d(in_channels, out_channels * BasicBlock.expansion, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(out_channels * BasicBlock.expansion)
)
def forward(self, x):
return nn.ReLU(inplace=True)(self.residual_function(x) + self.shortcut(x))📌
-
과 같이 방법을 바탕으로 연속적으로 나오는 각각의 를 모두 를 통해 연결하는 방식
의 경우 끼리 더하기를 해주는 방식이였다면 끼리
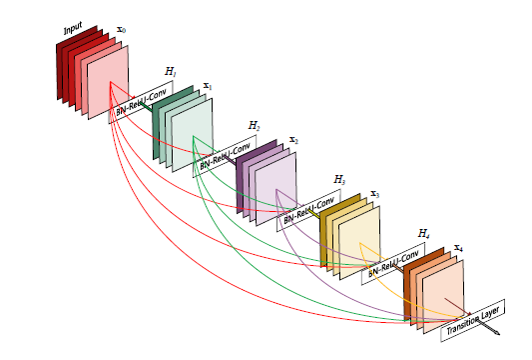
각 각의 들에 불필요한 학습을 줄인다, 에 학습되는 정보를 명확하게 구분
에 하게 접근할 수 있어서, 더 쉽게 학습이 가능하다
-
와 을 통해서 차원을 축소한다.
class SingleLayer(nn.Module):
def __init__(self, nChannels, growthRate):
super(SingleLayer, self).__init__()
self.bn1 = nn.BatchNorm2d(nChannels)
self.conv1 = nn.Conv2d(nChannels, growthRate, kernel_size=3,
padding=1, bias=False)
def forward(self, x):
out = self.conv1(F.relu(self.bn1(x)))
out = torch.cat((x, out), 1)
return out
class Transition(nn.Module):
def __init__(self, nChannels, nOutChannels):
super(Transition, self).__init__()
self.bn1 = nn.BatchNorm2d(nChannels)
self.conv1 = nn.Conv2d(nChannels, nOutChannels, kernel_size=1,
bias=False)
def forward(self, x):
out = self.conv1(F.relu(self.bn1(x)))
out = F.avg_pool2d(out, 2)
return out
class DenseNet(nn.Module):
def __init__(self, growthRate, depth, reduction, nClasses, bottleneck):
super(DenseNet, self).__init__()
nDenseBlocks = (depth-4) // 3
nChannels = 2*growthRate
self.conv1 = nn.Conv2d(3, nChannels, kernel_size=3, padding=1,
bias=False)
self.dense1 = self._make_dense(nChannels, growthRate, nDenseBlocks, bottleneck)
nChannels += nDenseBlocks*growthRate
nOutChannels = int(math.floor(nChannels*reduction))
self.trans1 = Transition(nChannels, nOutChannels)
def _make_dense(self, nChannels, growthRate, nDenseBlocks, bottleneck):
layers = []
for i in range(int(nDenseBlocks))
layers.append(SingleLayer(nChannels, growthRate))
nChannels += growthRate
return nn.Sequential(*layers)📋
- 이미지 한장에 대한 분류를 하는 과 다르게 이미지 내의 하나 하나에 대한 을 분류하는
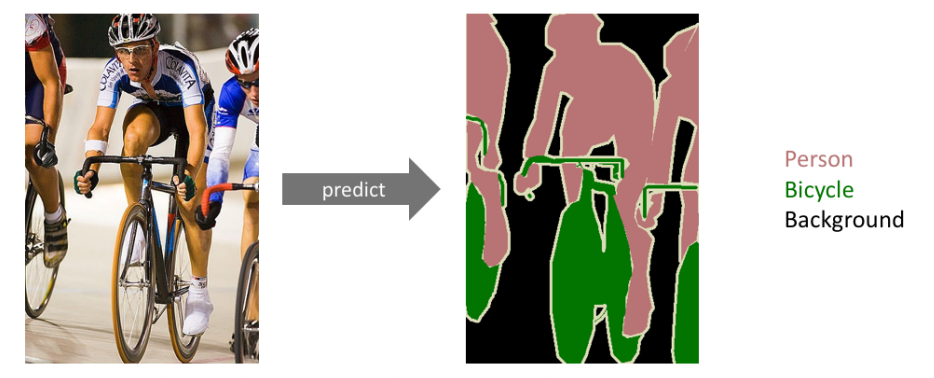
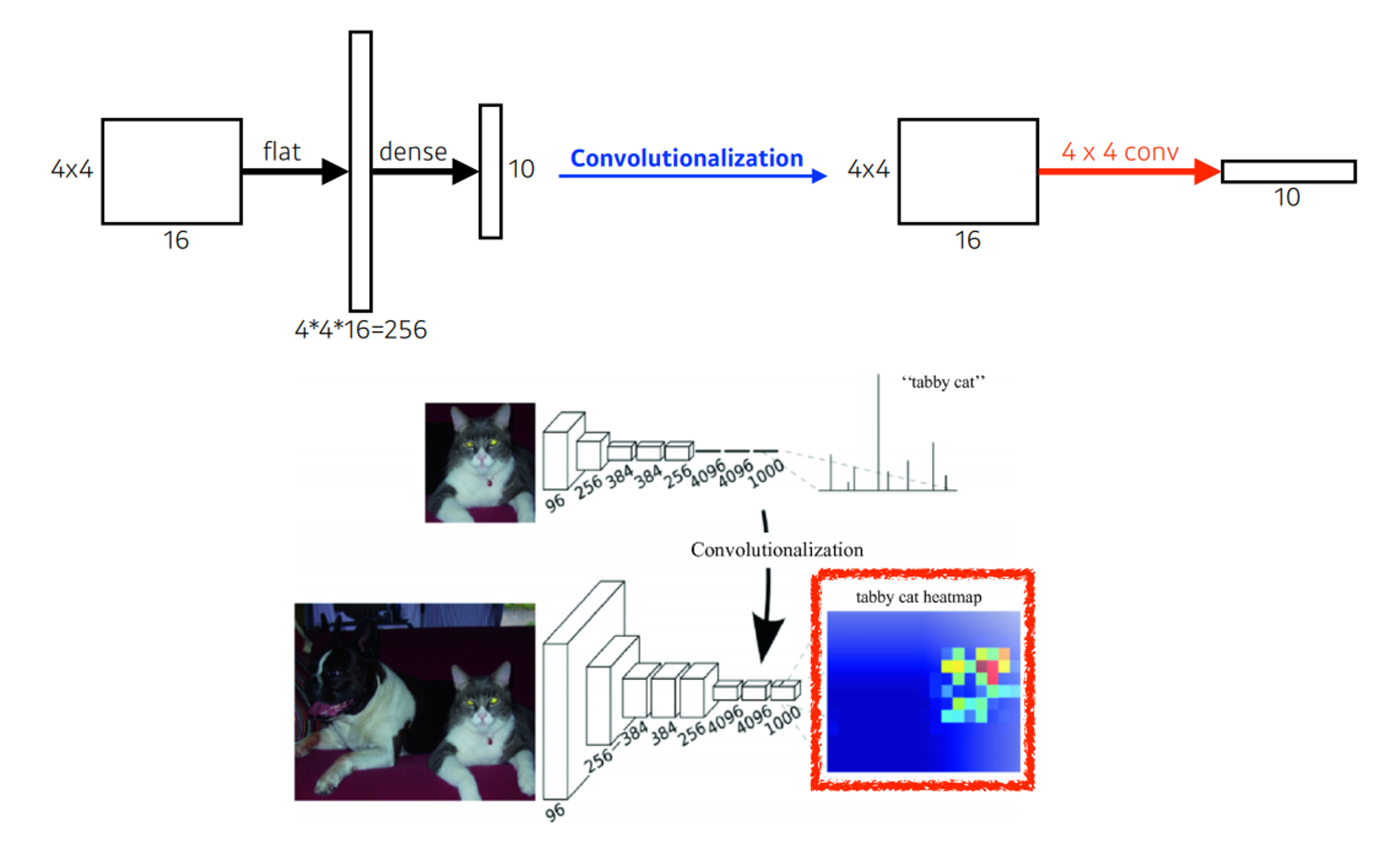
-
을 해서 통해 분류하는 방식과 다르게
통해서 과 같은 한 유지한 얻을 수 있도록 하였다.
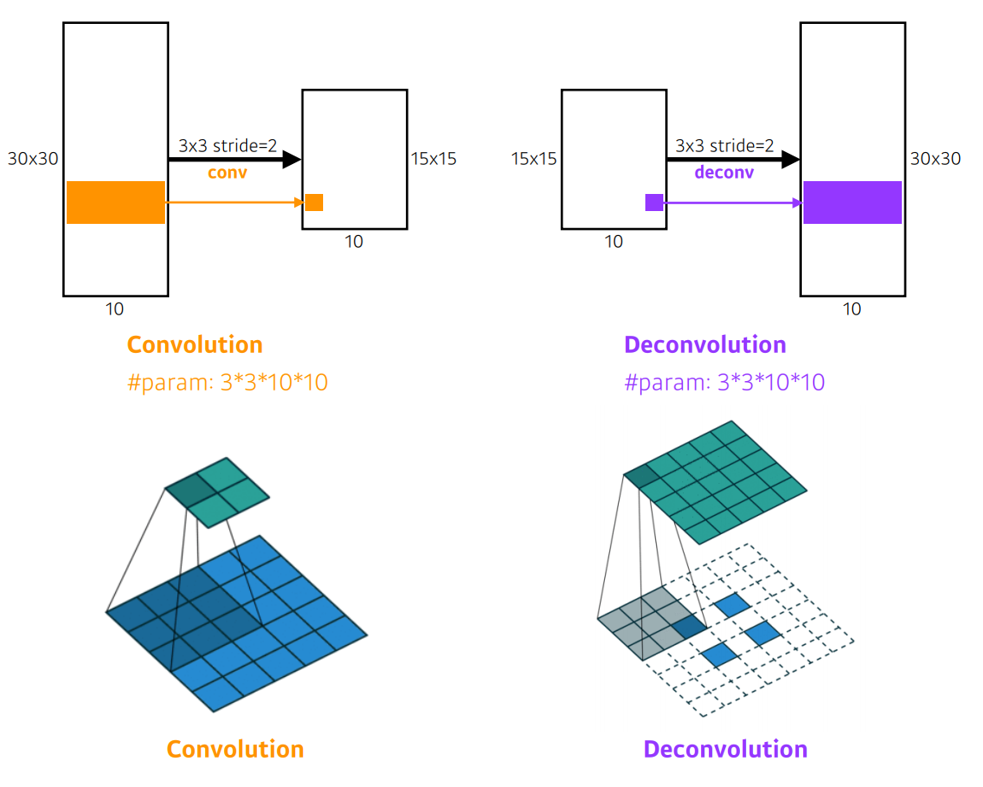
작아진 을 입력 이미지와 같은 사이즈로 만들어 주기 위해서
을 로
📋
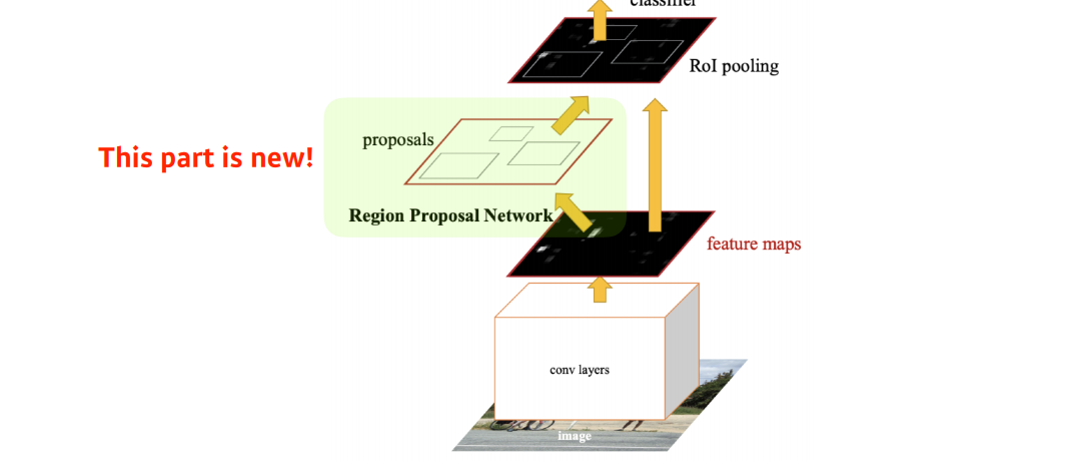
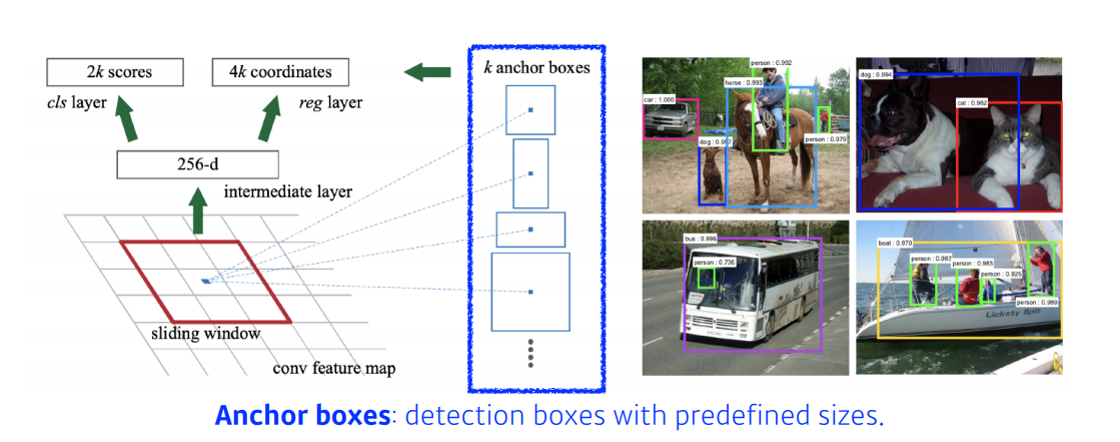
- 이미지 내에 존재하는 물체 위치 를 찾고, 물체에 대한 분류를 동시에 하는
- -