📋 Optimization
📌 Gradient Descent
Wt−1 <- Wt - η gt
- η : Learning rate
- gt : Gradient
- gradient 계산을 통해서 하강하는 방향으로 weight update
📌 Momentum
at+1 <- β at + gt
Wt+1 <- Wt - η at+1
- at+1 : accumulation
- β : momentum
- 현재 스탭의 accumulation이용한 momentum 과 현재 gradient 를 함께 사용하여 다음 스탭의 accumulation
- momentum이 포함된 gradient를 이용한 weight update
- 미니 배치를 사용하다 보니 그때 그때 세부적인 내용에 집중하게 되는데 이전에 사용한 미니배치의 gradient 정보를 이용하여 문제 보완
- Local minima에서 벗어날 수 있게해준다.
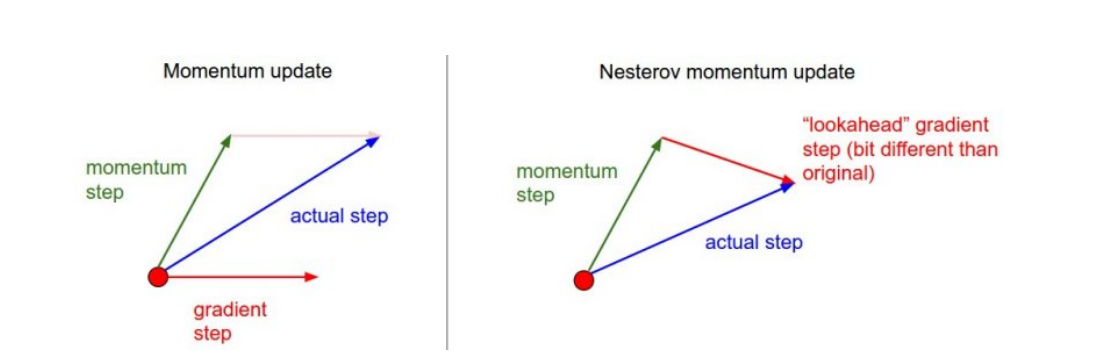
📌 Nesterov Accelerated Gradient
at+1 <- ∇L(Wt−ηβat)
Wt+1 <- Wt - η at+1
- ∇L(Wt−ηβat) : Lookahead gradient
- 현재 가지고 있는 momentum 만큼 업데이트 했을 때를 미리 가보고 gradient를 구해서 모멘텀과 함께 weight update에 사용한다.
📌 Adagrad
Wt+1 = Wt - Gt+ϵηgt
- Gt : Sum of gradient squares
- ϵ : for numeric stability
- Sum of gradient squares 를 통해서 지금까지 많이 변한 파라미터에 대해 적게 update, 적게 변한 파라미터에 대해 많이 업데이트
- 학습이 가면 갈 수 록 적게 학습되는 문제가 있을 수 있다.
📌 Adam
mt = β1mt=1 + (1−β1)gt
vt = β2vt−1 + (1−β2)gt2
Wt+1 = Wt - vt+ϵη1−β1t1−β2tmt
- mt : momentum
- vt : EMA of gradient squares
- vt를 통해서 gradient 크기 변화에 따라 adaptive 하게 learning rate 바꿔주는 역할 + mt 를 통해서 이전의 gradient 정보를 모멘텀으로 사용
