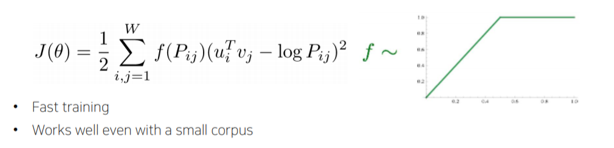Week4 Day1
📋
- 를 적절하게 이해하고 만들어내는 것을 목표로한다.
- , , ,
📌 --
- 를 포함하는 구성
- 를 - 로

- 모든 단어들의 가 같다.
- 모든 단어들의 사이 유사도가 같다.
📌
- 가 주어졌을 때 문서가 어떤에 속하는지 분류하는 태스크
- 베이즈룰을 사용해서 분류하는 방식

📌
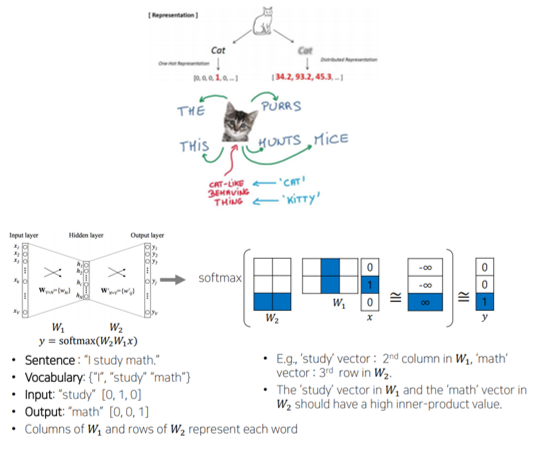
- 하나의 차원에 단어의 모든 의미를 표현하는 - 과 달리 단어의 을 학습하고자 한다.
- 같은 문장에 속한 단어들을 학습하여 비슷한 의미의 단어가 좌표상의 비슷한 위치로 될 수 있도록
📌
- 특정한 입출력 셋이 안에 빈번하게 발생하여 여러번 학습될 때 내적값이 커질 수 있는데 애초에 입출력 셋 쌍에 대한 발생횟수를 미리 계산하여 에 추가해주는 방식
- 중복 계산을 줄여주고, 에 비해 상대적으로 학습 빠르고, 적은 데이터에 잘 동작