📋 Basic of Recurrent Neural Networks
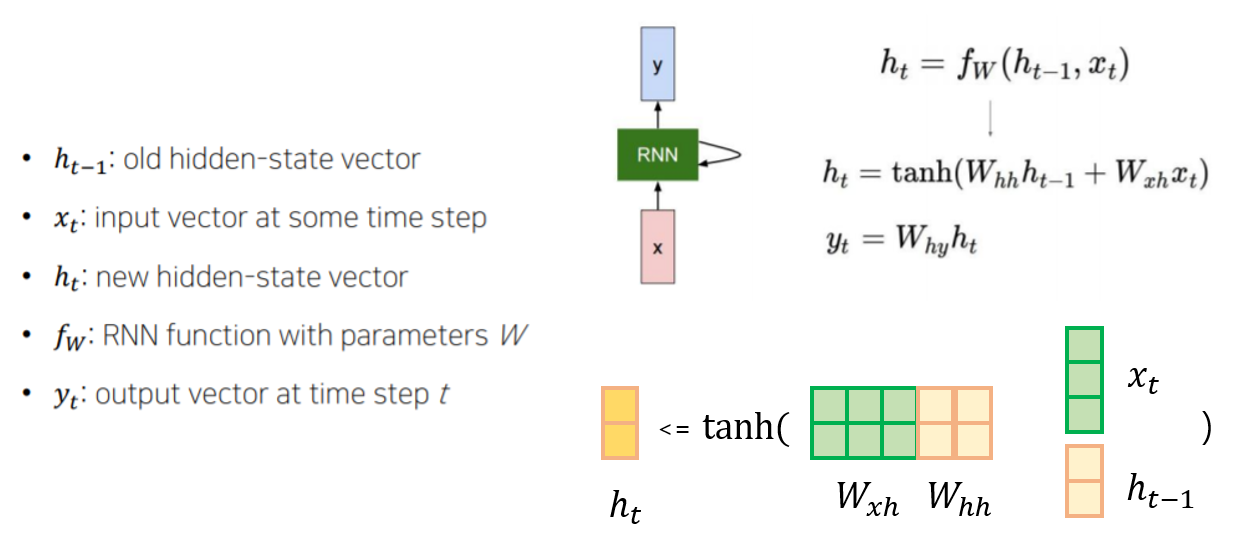
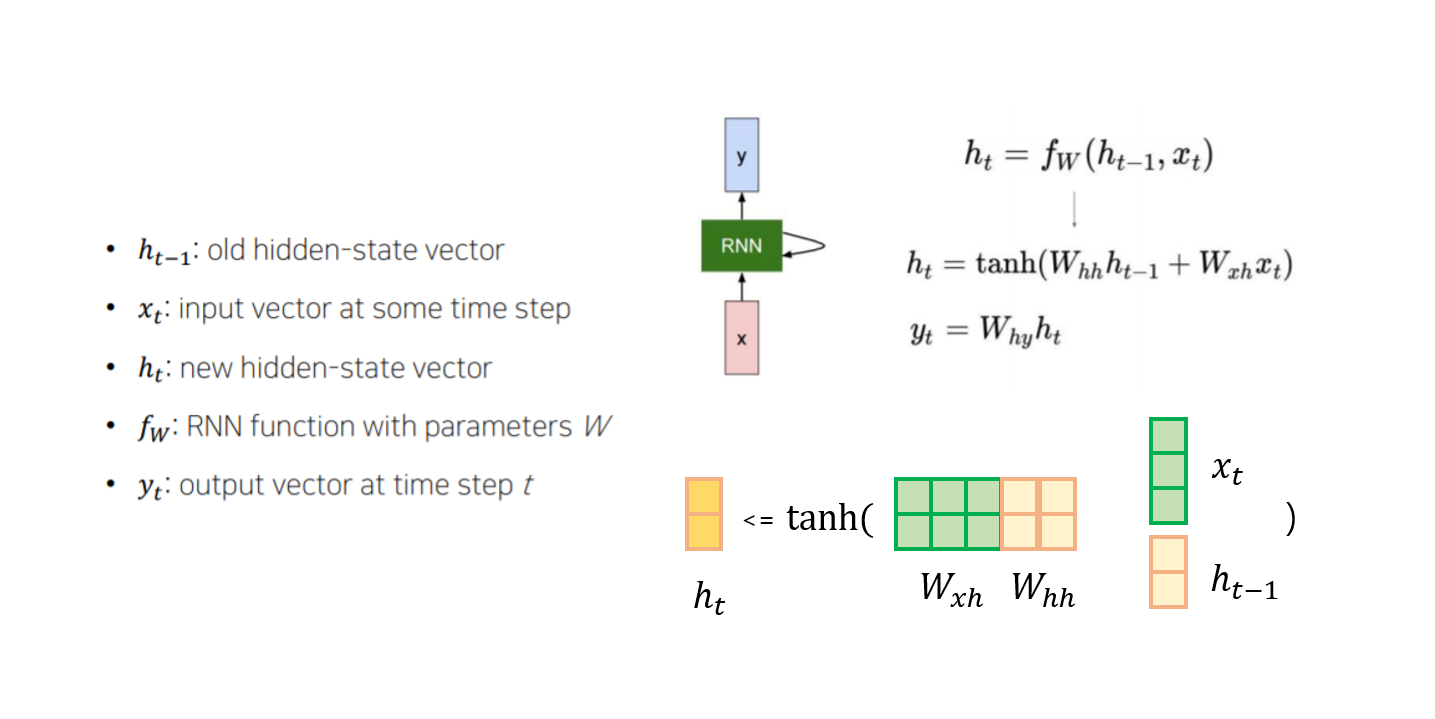
📌 Recurrent Neural Network
- sequential 한 데이터에 대해서 입력 데이터와 이전 스텝의 state를 이용하여 recursive하게 아웃풋을 출력하는 모델
vocab_size = 100
batch = torch.LongTensor(data)
embedding_size = 256
embedding = nn.Embedding(vocab_size, embedding_size)
batch_emb = embedding(batch)
hidden_size = 512
num_layers = 1
num_dirs = 1
rnn = nn.RNN(
input_size=embedding_size,
hidden_size=hidden_size,
num_layers=num_layers,
bidirectional=True if num_dirs > 1 else False
)
h_0 = torch.zeros((num_layers * num_dirs, batch.shape[0], hidden_size))
hidden_states, h_n = rnn(batch_emb.transpose(0, 1), h_0)
num_classes = 2
classification_layer = nn.Linear(hidden_size, num_classes)
output = classification_layer(h_n.squeeze(0))
📌 Backpropagation through time
- loss를 계산하기 위해서 전체 sequence에 걸쳐서 forward를 하고, 그러고나서 gradient를 계산하기 위해 전체 sequence에 걸쳐서 backward한다.
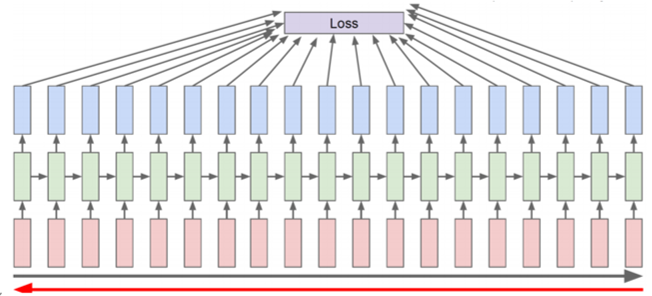
- 훨씬 이전 step의 hidden state값에 대한 update의한 gradient 전달되기 어렵다. (Vanishing gradient)
- 전체sequence 대신 sequence를 잘라서 chunk단위로 forward, backward
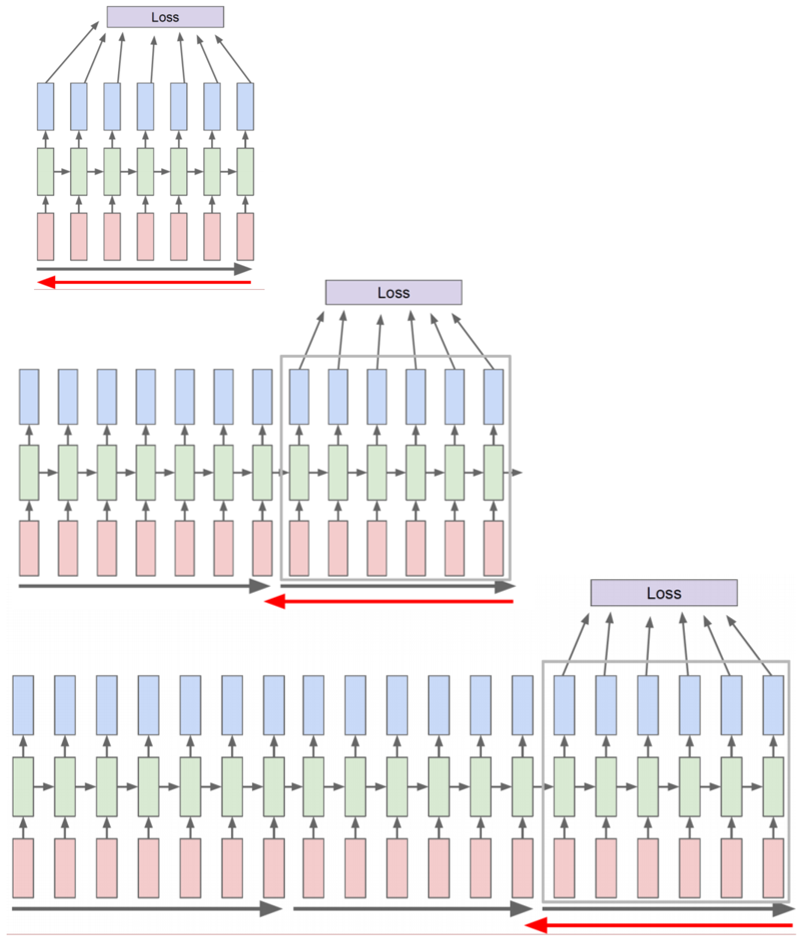
- (Question) 동일한 weight에 대해서 학습을 sequential하게 진행하면 앞에 update한 부분에 대해forgetting문제 발생하지 않을까??
- (Question) 멀리 떨어진 시점에 대한 정보 update 반영 안되는 것 아닌가?
📌 Long Short-Term Memory
- sequence내에서 멀이 떨어진 곳의 정보를 더 잘 이용할 수 있도록
cell state를 만들어 변형없이 정보를 바로 전달
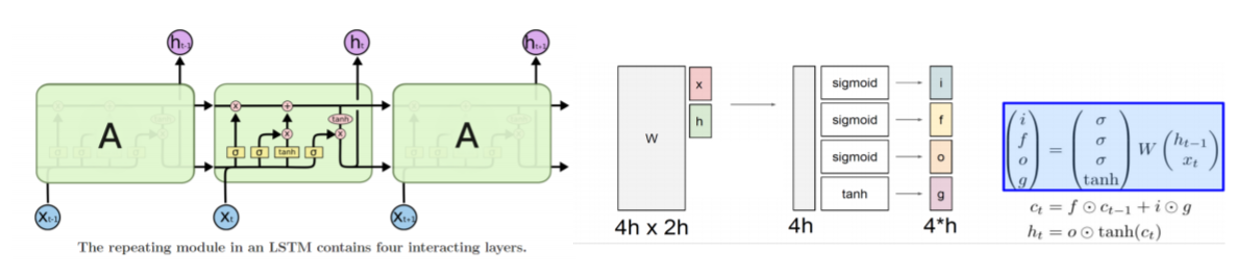
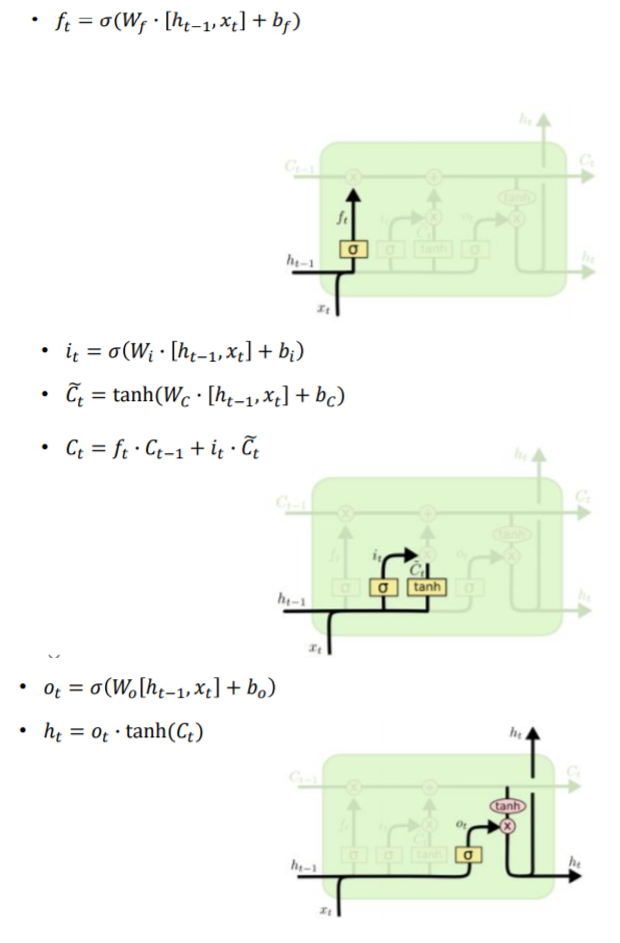
- sigmoid를 통과하는 i,f,o는 0~1사이 값으로 다른 벡터와 element-wise곱을 통해서 원래 가진 값의 일부 퍼센트만 전달할 수 있도록하는 역할
- tanh를 통과하는 g의 경우 비선형함수를 통과하여 -1~1사이의 값을 가지며 현재 step에 유의미한 정보를 담고있는 역할을 한다.
class RecurrentNeuralNetworkClass(nn.Module):
def __init__(self,name='rnn',xdim=28,hdim=256,ydim=10,n_layer=3):
super(RecurrentNeuralNetworkClass,self).__init__()
self.name = name
self.xdim = xdim
self.hdim = hdim
self.ydim = ydim
self.n_layer = n_layer
self.rnn = nn.LSTM(
input_size=self.xdim,hidden_size=self.hdim,num_layers=self.n_layer,batch_first=True)
self.lin = nn.Linear(self.hdim,self.ydim)
def forward(self,x):
h0 = torch.zeros(self.n_layer, x.size(0), self.hdim).to(device)
c0 = torch.zeros(self.n_layer, x.size(0), self.hdim).to(device)
rnn_out,(hn,cn) = self.rnn(x, (h0,c0))
out = self.lin(rnn_out[:,-1 :]).view([-1,self.ydim])
return out
R = RecurrentNeuralNetworkClass(
name='rnn',xdim=28,hdim=256,ydim=10,n_layer=2).to(device)
loss = nn.CrossEntropyLoss()
optm = optim.Adam(R.parameters(),lr=1e-3)
print ("Done.")
x_numpy = np.random.rand(2,20,28)
x_torch = torch.from_numpy(x_numpy).float().to(device)
rnn_out,(hn,cn) = R.rnn.forward(x_torch)
out = R.lin.forward(rnn_out[:,-1:]).view([-1,ydim])
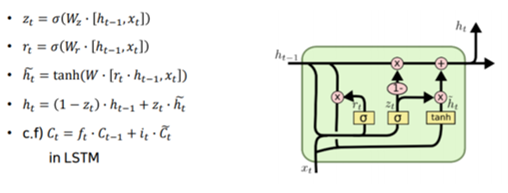
📌 GRU
- LSTM의 경량화
- cell state와 hidden state의 일원화
gru = nn.GRU(
input_size=embedding_size,
hidden_size=hidden_size,
num_layers=num_layers,
bidirectional=True if num_dirs > 1 else False
)
output_layer = nn.Linear(hidden_size, vocab_size)
📌 Language Modeling
- 단어, 문자 등의 기본단위 값에 대해서 이전 정보를 이용하여 순차적으로 예측해나가는 태스크
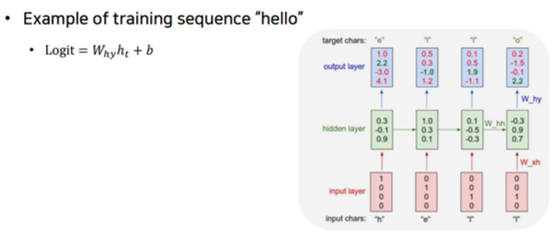
- Teacher Forcing 없이 이전에 예측값을 입력값으로 이용하여 진행
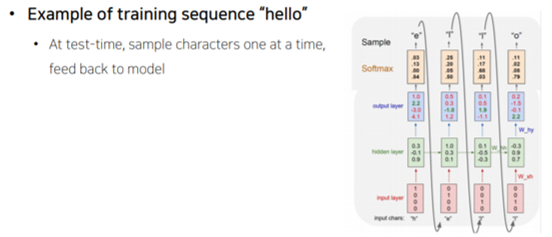
for t in range(max_len):
input_emb = embedding(input_id).unsqueeze(0)
output, hidden = gru(input_emb, hidden)
output = output_layer(output)
probs, top_id = torch.max(output, dim=-1)
print("*" * 50)
print(f"Time step: {t}")
print(output.shape)
print(probs.shape)
print(top_id.shape)
input_id = top_id.squeeze(0)