Broker? Topic?
Kafka를 공부하면서 가장 많이 듣게 되는 키워드중 하나인 topic, 그리고 topic을 담당하는 broker에 대해서 공부한 내용을 정리해보려 한다.
Broker
- 카프카 애플리케이션이 설치된 server 또는 node를 지칭.
- Producer의 메세지가 전달되는 저장소인 Topic을 관리한다.
Topic
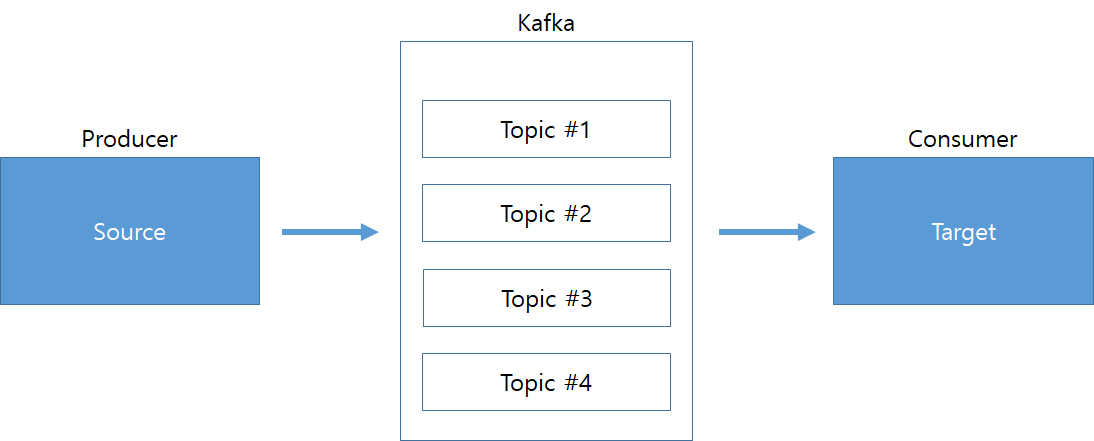
- Kafka에서 데이터를 구분하기 위한 저장소
- Producer 에서 ProducerRecord를 broker로 send 하면 topic 기준으로 메세지가 broker에 저장된다.
효과적인 Topic 처리를 위한 Partition with offset

Partition
- Topic을 나누는 단위 그룹.
- Topic의 고속 처리를 위해서 병렬화 구조를 가져가기 위해 Patition기준으로 나눔.
- 메세지별 크기, 초당 메세지 건수 등의 변수를 기준으로 적절한 patition을 나누는 것이 핵심.
* 확장 기준은 consumer의 LAG이 대표적이며 0인 경우 지연없이 모든 메세지가 처리되었음을 의미함.LAG = 프로듀서가 보낸 메세지 수(카프카에 남아 있는 메세지 수) - 컨슈머가 가져간 메세지 수
- 컨플루언트에서 제공하는 Patition 생성기준에 대한 계산법
Offset
- 각 patition별로 메세지가 저장된 위치.
- 순차 증가하는 64비트 정수로 구성.
효과적인 장애 복구
- Kafka는 broker에서 장애가 발생하게 되더라도 데이터 유실이 없이 안정적으로 서비스를 제공할 수 있음.
- broker에서 replication을 통해 메세지들을 분산 처리시키는 방식으로 안정성을 제공함.
Replication factor
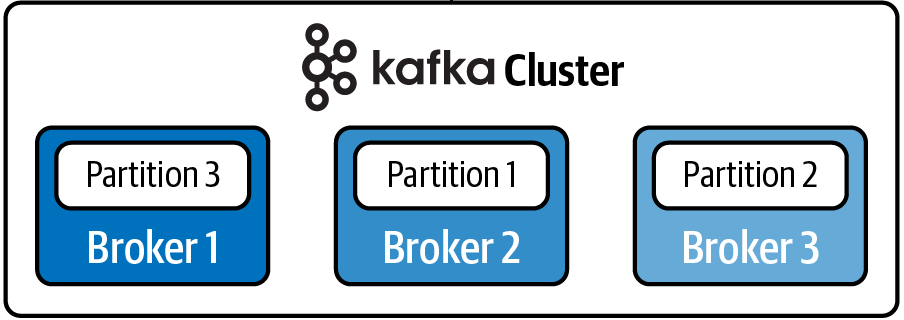
- 각 메세지들을 여러 개로 복제하여 Kafka Cluster 내의 broker들에게 분산시키는 동작.
- N개의 replication을 설정하면 N-1개까지의 broker 장애가 발생해도 분산처리를 통해 안정성을 확보가 가능.
- repliaction 설정을 통해 유지할 broker 의 수를 산정.
- 운영을 통해 적절한 설정값을 찾아야 함. 지나치게 많이 설정하면 overhead 발생. - Kafka replication factor가 진행되는 과정 참조.
leader & follower
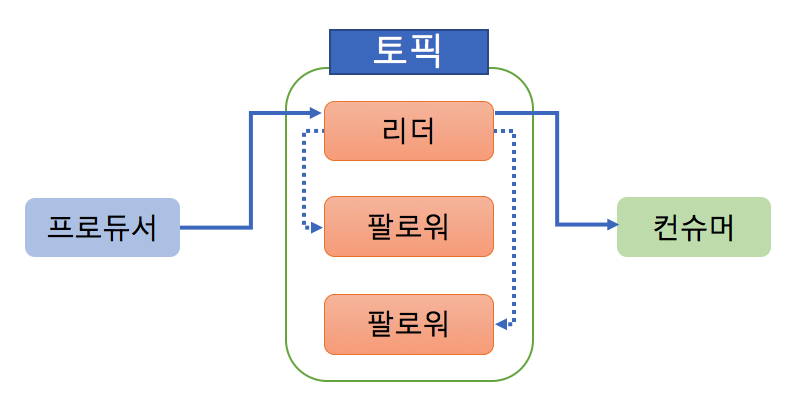
- 원본과 복사본을 구분.
- leader와 follower는 각각의 특징이 있음.
leader : 1개만 선정. 모든 읽기&쓰기 가능.
follwer : leader를 제외한 나머지 broker들을 선정. 읽기만 가능.
ISR 단위 복제 유지와 commit
- ISR(InSyncReplica) : leader & follower를 묶는 논리적 그룹으로 장애 발생시 leader 재선출이 이루어지는 그룹.
- ISR 단위로 모든 follwer들은 leader에 메세지를 복제하며, 이를 완료시 leader는 내부적으로 완료된 메세지 offset을 기준으로 commit.
- 마지막 commit에 대한 offset 위치값을 하이워터마크라 지칭함.
복구
Kafka는 replicatoin을 통해 분산 처리 구조를 수행 할 수 있고 장애가 발생했을 경우, 복제본들을 이용하여 장애 대응과 유연한 복구를 제공함.
메세지에 대한 '손실이 있는 복구'와 '손실이 없는 복구'로 정리 할 수 있음.
메세지 손실이 있는 복구
- leader와 follower 간에 commit이 진행되는 과정에서 leader에 장애가 발생할 경우, 기존 follower중 하나가 새로 leader로 선출이 진행됨.
- 새로운 leader의 선출과정에서 이전 leader가 가지고 있는 최신 메세지의 내용이 공유가 실패하면서 메세지가 유실되어 손실이 있는 복구형태로 진행됨.
장애발생후 복구시 메세지 유실되는 CASE
- leader에 신규 메세지가 전달되고 이를 하이워터마크가 생성된 상태에서 follower에 전달되기 직전에 leader에서 장애가 발생.
- leader가 가진 하이워터마크와 follower의 하이워터마크가 달라지는 현상 발생.
- follower는 자신이 가진 하이워터마크를 최신 메세지로 기준잡은 상태로 leader로 선출됨.
- 최신 정보가 빠진 신규 leader가 자기의 하이워터마크를 기준으로 follower에게 replication 진행.
- 장애에서 복구된 이전 leader는 follower로 참여하게 되며 자신이 가지고 있던 최신 메세지는 손실되고 신규 leader 기준으로 메세지 복제가 수행됨.
leaderEpoch를 이용한 손실 없는 복구
- leaderEpoch 란 메세지의 일관성을 유지 하기 위한 용도로 사용되는 controller가 관리하는 32비트 숫자 형식.
- epoch의 정보는 replication protocol에 의해 전파되고 새로운 leader가 생기면 leader의 정보를 follower에게 전달함.
- leaderEpoch를 설정하면 장애에서 복구될때 하이워터마크를 삭제하지 않고 epoch 요청을 하여 offset을 동기화하는 과정을 거치며 이로 인해 메세지가 유실되지 않고 복구가 진행됨.
장애발생후 복구시 leaderEpoch를 통해 손실없이 복구되는 CASE
- leader에 신규 메세지가 전달되고 이를 하이워터마크가 생성된 상태에서 follower에 전달되기 직전에 leader에서 장애가 발생.
- leader가 가진 하이워터마크와 follower의 하이워터마크가 달라지는 현상 발생.
- follower는 자신이 가진 하이워터마크를 최신 메세지로 기준잡은 상태로 leader로 선출됨.
- 최신 정보가 빠진 신규 leader를 상대로 이전 leader에서 leaderEpoch 요청을 통해서 최신 메세지에 대한 하이워터마크를 가짐.
- 신규 leader기준으로 follower들에게 메세지 복제가 수행됨.
LOG 생성
Segment
- broker로 전송된 메세지들의 LOG file.
* 아래와 같은 구성을 가지고 있음.xxx.index : 로그 segment에 저장된 위치, offset정보 기록파일.
xxx.log : 실제 메세지들이 저장되는 파일.
xxx.timeindex : 메세지의 타임스탬프를 기록하는 파일. - 기본적으로 broker의 local disk에 보관.(별도의 storage로 저장가능.)
- 메세지 key, value, offset, 메세지 크기 등이 저장됨.
- file의 기본 사이즈는 1GB이며 이를 초과할 경우 rolling 전략이 적용되어 새로운 segment파일을 생성하여 이어지도록 작동함.
- segment에 대한 삭제 정책이 있으며 이를 기준으로 삭제를 주기적으로 진행함.
* broker에서 log.cleanup.policy = delete가 설정되어 있어야 하며 기본으로 설정되어 있음.- 기본적으로 5분 주기로 삭제 정책이 수행됨.
- 특정 segment 삭제명령을 수동 실행 했을 경우, 기본적으로 5분뒤 삭제가 실행되는 구조.
Log Segment Compaction
- Kafka에서 제공하는 log segment 관리 정책.
- log를 삭제하지 않고 compaction에 보관함.
- 효율적인 compaction을 위해 메세지의 key값 기준 마지막 데이터만 보관함.
- consumer offset topic에서 활용. - 생성된 compaction을 기준으로 장애 발생 시 최신상태로 빠르게 복구가 가능.
- compaction이 동작하면 overhead가 발생하기 때문에 가급적 최종값에 대해서만 compaction을 설정하여 사용해야 하고 동작중일 때는 broker의 상태를 모니터링해야 함.

멈추지 않는 사람이 되고 싶어요!