Kafka?

링크드인에서 아파치 카프카라는 분산 메세징 시스템을 개발.
데이터 파이프라인을 구축할때 가장 많이 고려되는 시스템.
설계방식의 변화
- Kafka가 도입되기 전/후의 아키텍처의 특징들을 간략히 정리해 보았다.
Point to Point 방식
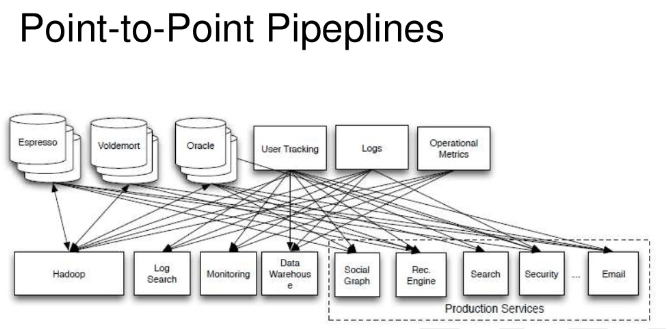
- Kafka 도입 이전의 아키텍처
- 큐를 통해서 전달할 메세지를 전달하면 받는 사람이 큐에서 메세지를 사용.
- 구조적 단점.
- point가 늘어남에 따라 데이터연동의 복잡성이 증가하게 된다.
- 데이터의 전송라인이 늘어나면 배포/장애 발생시 대응이 힘들어지는 구조.
- 변경사항이 늘어나면 유지보수가 힘들어진다.
Pub/Sub 방식
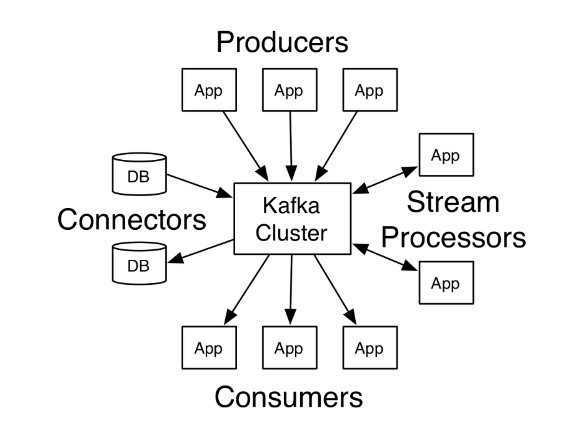
- Kafka의 아키텍처
- Publish–subscribe pattern으로 구현된 분산 메세징 시스템 구조.
- 3가지 역할군으로 구분되어 있다.
프로듀서 : 데이터를 만들어내는 역할.
컨슈머 : 데이터를 소비하는 역할.
브로커 : 프로듀서와 컨슈머를 중재하는 역할.(결합도를 낮추는 역할.) - 메세징 전달의 과정.
- 프로듀서가 브로커를 통해서 메세지를 발행.
- 구독할 컨슈머가 브로커에게 요청하여 메세지를 가져감.
Kafka의 특징
-
토픽을 통한 boardcast.
- 메세지 스트림의 추상화된 개념인 토픽 중심으로 메세지 처리가 이루어 진다.
- 컨슈머가 특정 토픽이나 이벤트에 구독을 해 놓으면 해당토픽이나 이벤트에 대한 통지를 비동기방식으로 수행한다.
- 하나의 프로듀서가 여러 토픽에 메세지를 전파 할 수 있음.
- 하나의 컨슈머가 여러 토픽에서 메세지를 읽어 드릴수 도 있음.
- 하나의 메세지에 여러 컨슈머가 읽는게 가능.
- 프로듀서가 생성한 메세지를 브로커가 위치한 서버의 파일 시스템에 저장이 가능. 이로 인해 지연처리가 가능하다.
-
프로듀서와 컨슈머를 분리함으로써 높은 처리량이 가능해지는 구조.
-
대용량 실시간 로그처리에 특화되어 있다.
-
장애대응/재처리가 용의한 구조.
- 컨슈머쪽에서 장애가 발생했을 경우, 브로커와 분리되어 있기 때문에 큰 영향을 주지 않는 구조.
- 컨슈머들이 배치처리를 가능하게 하고 에러가 발생했을 경우 전에 읽었던 데이터를 다시 읽어서 재처리를 가능하게 한다.
-
뛰어난 확장성.
- 수평적 확장(Sacle out)이 용이하다. 운영중인 프로듀서를 얼마든지 증가 시킬수 있고 컨슈머그룹안에서 컨슈머를 추가할 수 있다. 이때 컨슈머 파티션 소유권이 재분배 하는 과정(리밸런스)이 이루어지며 소속된 컨슈머들이 균등한 파티션을 할당받게 된다.
- 카프카 topic은 내부에서 파티션 단위로 관리되며 topic 파티션의 개수도 운영중에 추가 할 수 있다.
- 다른 메세징 시스템과 다르게 컨슈머에게 데이터를 전달하는 방식이 아닌 컨슈머가 브로커에게서 메세지를 가져오는 방식을 사용한다.
- 이점으로는 브로커가 컨슈머의 처리 능력을 고려할 필요가 없어지고 프로듀서와 컨슈머간 처리속도에 따른 대응이 가능한 구조가 된다.
-
Kafka에서 제공하는 표준 포맷을 통한 데이터 전달이 이루어지기 때문에 표준화가 용이함.

멈추지 않는 사람이 되고 싶어요!