Decision Tree
의사결정트리(Decision Tree)란?
- 의사결정트리는 일련의 분류 규칙을 통해 데이터를 분류, 회귀하는 지도 학습 모델 중 하나이며,
- 결과 모델이 Tree 구조를 가지고 있기 때문에 Decision Tree라는 이름을 가집니다.
- 아래 그림을 보면 더 쉽게 이해가 가능합니다.

- 위 그림은 대표적인 의사결정트리의 예시로서, 타이타닉호의 탑승객의 생존여부를 나타내고 있습니다.
- 이렇게 특정 기준(질문)에 따라 데이터를 구분하는 모델을 의사 결정 트리 모델이라고 합니다.
- 한번의 분기 때마다 변수 영역을 두 개로 구분합니다.
- 결정 트리에서 질문이나 정답은 노드(Node)라고 불립니다.
- 맨 처음 분류 기준을 Root Node라고 하고
- 중간 분류 기준을 Intermediate Node
- 맨 마지막 노드를 Terminal Node 혹은 Leaf Node라고 합니다.
- 결정 트리의 기본 아이디어는, Leaf Node가 가장 섞이지 않은 상태로 완전히 분류되는 것, 즉 불순도gini, entropy)가 낮아지도록 만드는 것입니다.
Criterion의 정의
분리기준(split criterion)
: 어떤 입력변수를 이용하여 어떻게 분리하는 것이 목표변수의 분포를 가장 잘 구별해 주는지에 대한 기준
• 목표변수의 분포를 구별하는 정도 : 순수도 or 불순도
- 순수도 : 목표변수의 특정 범주에 개체들이 포함되어 있는 정도
- 부모마디의 순수도에 비해서 자식마디들의 순수도가 증가하도록 자식마디를 형성함
Scikit learn 공식문서에서 정의하는 criterion
criterion{“gini”, “entropy”, “log_loss”}, default=”gini”
The function to measure the quality of a split. Supported criteria are “gini” for the Gini impurity and “log_loss” and “entropy” both for the Shannon information gain, see Mathematical formulation. Note: This parameter is tree-specific.
지니 불순도
1. 지니 불순도란?
지니불순도라는 것은 데이터 분석에서 흔히 의사결정나무에서 사용되는 클래스개수에 따른 케이스들의 불순한 정도를 나타내는 척도이다.
지니불순도가 필요한 이유는 의사결정을 하는데 있어서 최적의 분류를 위한 결정을 계속해서 맞이하는데 이 결정에 사용되기 때문이다. 이 변수로 인해서 분류를 거쳤을 때 지니불순도가 얼마나 되는가? 를 생각할 수 있게된다.
2. 공식

- 지니 지수의 최대값은 0.5이다.
3. 예제
- 범주 안에 빨간색 점 10개, 파란색 점이 6개 있을 때의 계산 예제입니다.

엔트로피
1. 엔트로피란?
확률 분포가 가지는 정보의 확신도 혹은 정보량을 수치로 표현한 것이다. 확률 분포에서 특정한 값이 나올 확률이 높아지고 나머지 값이 나올 확률은 낮아진다면 엔트로피가 작아진다. 반대로 여러가지 값이 나올 확률이 대부분 비슷한 경우에는 엔트로피가 높아진다. 엔트로피는 확률 분포의 모양이 어떤지를 나타내는 특성 값 중 하나로 볼 수도 있다. 확률 또는 확률 밀도가 특정 값에 몰려있으면 엔트로피가 작다고 하고 반대로 여러가지 값에 골고루 퍼져 있다면 엔트로피가 크다고 한다.
예시)
백인 10명, 흑인 10명이 한 집단에 있다고 하였을 때 , 특정 조건으로 이 집단을 2개의 집단으로 분리했다고 가정
이때 집단이 완벽히 백인과 흑인이 분리되었으면 엔트로피는 0이 된다. 반대로 백인 5명, 흑인 5명이 한집단씩 있다면 엔트로피는 1이 되며, 데이터가 불순하다라고 할 수 있다.
2. 공식

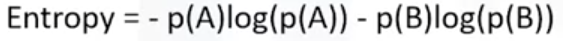
3. 예제
- 범주 안에 빨간색 점 10개, 파란색 점이 6개 있을 때의 계산 예제입니다.

- 노트 안에 초록색 공과 빨간 공 계산 예제입니다.

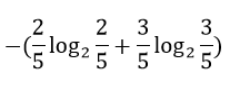
결과 : 0.9710.
log loss
1. log loss란?
- 모델이 예측한 확률 값을 직접적으로 반영하여 평가
A모델
B모델
- 동물 사진을 보고 무슨 동물인지 예측하는 두 모델
- 사자 사진을 보고 둘 다 사자를 예측
두 모델의 성능이 같다라고 한다면 A모델이 억울함 → 기껏 열심히 공부했는데 의지 상실
2. 음의 로그 함수
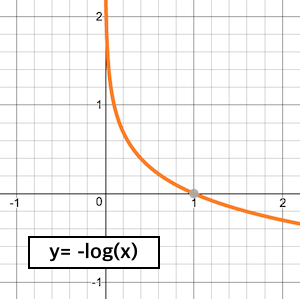
- logloss 계산할 때 사용되는 음의 로그 함수
- 1일 때 0이고, 0에 가까워질수록 기하급수적으로 증가
- logloss 값이 작을수록 좋은 모델
- 예측한 확률이 낮아질수록 큰 패널티
- 0일 때 무한대의 값, 0과 아주 가까운 수인 1e-15를 넣은 값인 34.5를 최댓값으로 사용 (변경 가능)
3. 계산식
- 관측치별로 실제 정답 예측 확률 값에 음의 로그 취하고, 평균
정답 1번 예측 확률 2번 예측 확률 3번 예측 확률 2 0.31 0.66 0.03 3 0.03 0.27 0.7 1 0.75 0.22 0.03
# 직접 계산
import numpy as np
answer = np.array([2, 3, 1])
probability = array([[0.31, 0.66, 0.03],
[0.03, 0.27, 0.7 ],
[0.75, 0.22, 0.03]])
res = 0
for ans, prob in zip(answer, probability):
temp = -np.log(l[ans - 1])
res += temp
res / len(answer)
>>> 0.353290820117393
# sklearn 활용 계산
from sklearn.metrics import log_loss
sklearn_log_loss = log_loss(answer, probability)
sklearn_log_loss
>>> 0.353290820117393참고
- Criterion
sklearn.tree.DecisionTreeClassifier
- Decision Tree
- log loss
sklearn.ensemble.RandomForestClassifier
- 지니 불순도
멋사 AI스쿨 8조 팀
