데이터 과학 기초
Table chart
속성들의 타입
- 테이블 column의 값들은 모두 같은 타입을 가지고 있어야한다.
- 값들을 서로 비교할 수 있어야한다.
- DB에서 attribute는 도메인이 같아야하는 것과 같음
두가지 타입이 있다
Numerical
- 각 값들은 숫자 값을 지닌다.
- 순서를 지정할 수 있다.
- 값들의 차이는 의미가 있다.
- storage에 효율성을 준다
Categorical
- 각 값들은 고정된 값을 지닌다.
- 순서의 의미가 없을 수 있다.
- 목록들은 같거나 다르다는 차이로 의미가 있다
어떤 속성의 값이 숫자이기 때문에, 속성이 numerical이라는 것은 아니다.
ex) 만약 어떤 속성이 숫자지만 카테고리로 이용하는 것이면 numerical이랑 다르다.
- 이걸로 숫자 계산을 해도 의미가 없다
- like 성별을 1 0 으로 표현하는 방법
- 이 경우에는 값이 숫자지만, 숫자들은 categorical하게 쓰인다.Numerical Data Chart
두가지 방법이 있다.
- line
- 변화량 파악에 용이하다.
- table.plot(x_label,y_label)
- 변화량 파악에 용이하다.
- scatter
- 상호관계 파악에 용이하다.
- table.scatter(x_label,y_label)
- 상호관계 파악에 용이하다.
Line vs scatter
라인을 사용할때 = 순차적인 양적 데이터를 가질때
- x 축이 순서를 가질때
- y축의 변화가 의미가 있을 때
- x 값에 때해 하나의 y값만 있을 때
- x값이 시간이거나 거리일때
scatter를 사용할 때 = 순차적이지 않은 양적 데이터를 가질때
- 값들 사이 연관성을 찾고 싶을 때
그래프에서
적은게 더 좋다
-
꾸미는건 적게 꾸미자
-
색은 조심스럽게 골라
- 여러가지 색의 수를 최소화하자
만약 데이터가 numerical하다면,
- 그들의 상대적인 가치와 그들 사이의 차이를 보존해라
- 뭔말?
Y축의 중요성
- Y축의 값을 어떻게 하느냐에 따라 시각적 효과가 매우 달라진다.
- 두 그래프 y값이 35,39f를 가질때, y축 시작을 35부터로 하면 두 값의 차이가 매우 커보인다.
- 하지만 0부터 시작을 한다면 차이가 얼마 안나는걸 알 수 있다.
- 두 그래프 y값이 35,39f를 가질때, y축 시작을 35부터로 하면 두 값의 차이가 매우 커보인다.
차트 그리기
Line 그래프
시간에 따른 변화율을 기록할때 유용
table.plot()을 통해 그린다.
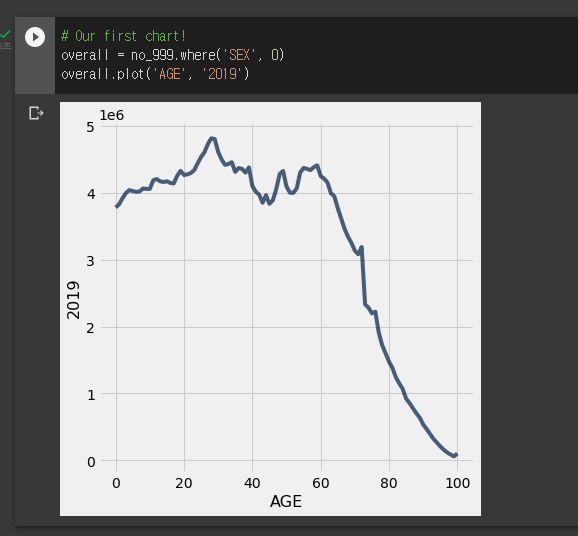
plots.title(문자열)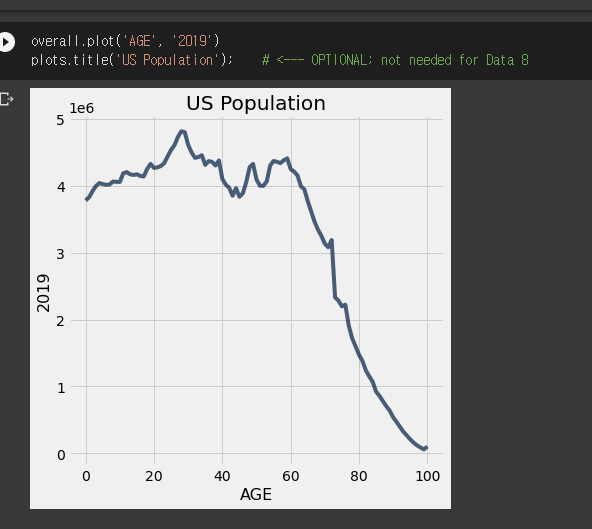
- 차트에 제목을 붙일 수 있다.
plots.ylim(원하는범위시작,범위끝)이전
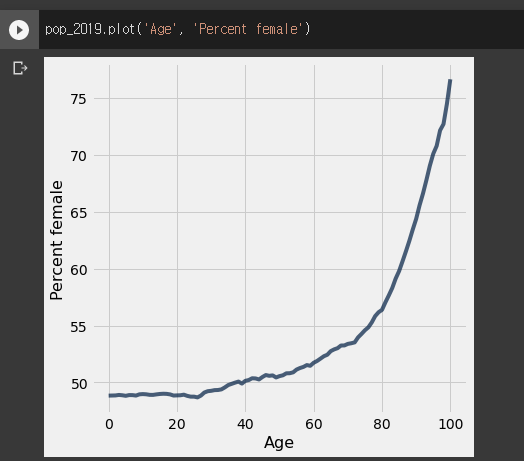
이후
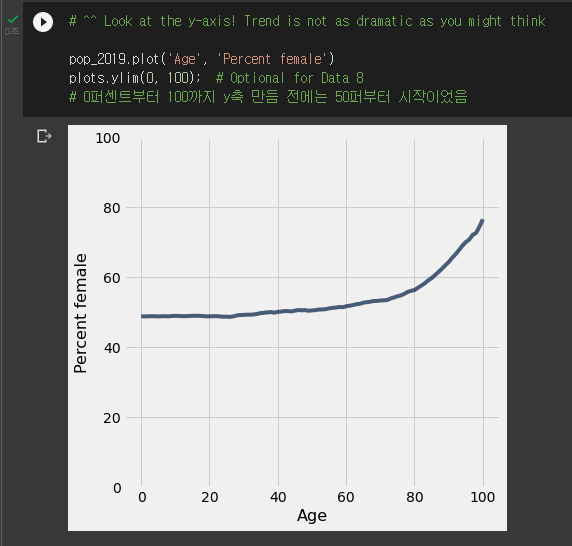
- y축의 범위를 지정할 수 있다.
- 앞서 언급한 y축의 중요성 문제의 예시라고 할 수 있다.
Scatter 그래프(산점도)
table.scatter(X축,Y축)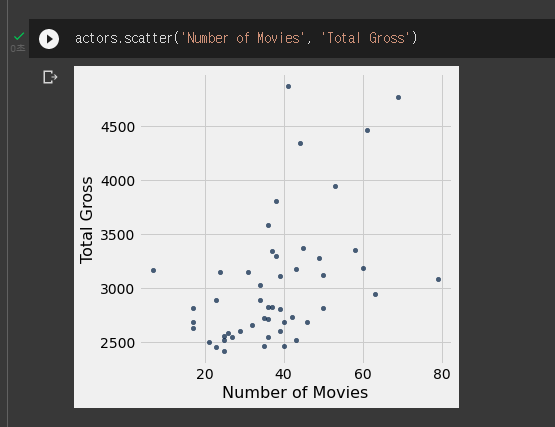
- 두 변수 간의 관계를 알고싶을때 사용
심심한 비교
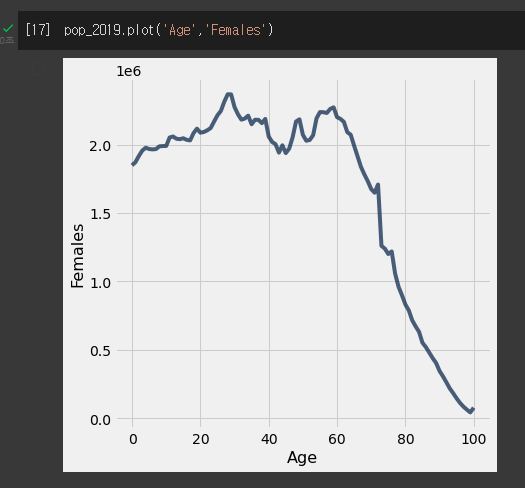
scatter 그래프와 plot그래프에서 x축과 y축이 같으면 서로 같은 그래프 모양을 나타낸다.
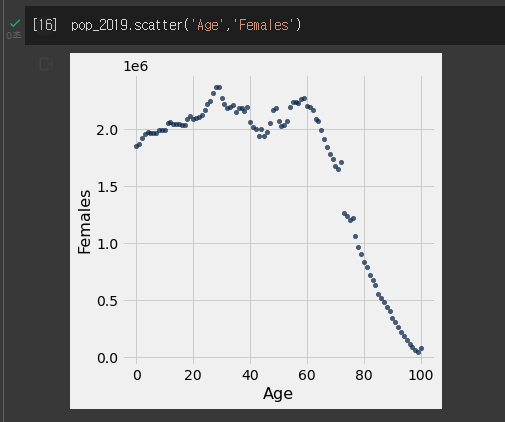
male과 female을 scatter로 비교해보았다.
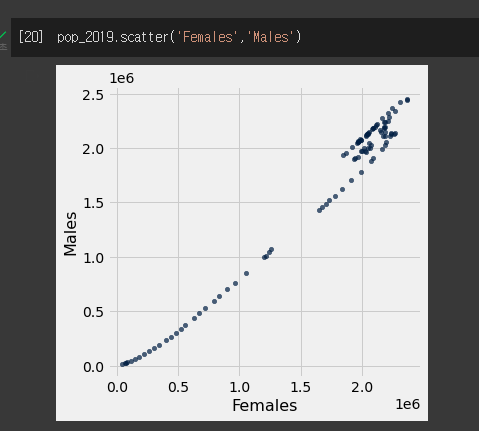
여자가 많으면 남자도 많은 것을 알 수 있는데... 이렇게 비교를 해야할까??
Age라는 순차적 증가 값이 있으니 age를 x축으로 두고 두 값의 plot그래프를 그린다면 더 비교가 쉬울 것 같다..(땡!!)
바보 같은 소리하지마 과거의 나야!! 같은 x값에 대해 여러 y값이 있는 것 같고 두 변수 사이 관계를 알아야하니 이는 scatter를 이용해야해!!
먼소리야 age라는 순차적이 값이 있으니 그냥 age를 x축으로 하고 남자와 여자 비율을 plot으로 그리는게좋을듯?
Distributions
용어
Individuals
- 특성이 기록된 것들
- row라 생각하면될듯 투플, 개체 인스턴스
Variable
- attribute(column)
- numerical or categorical하다
- 다른 값을 가진다
- 각 individual들은 하나의 값을 가진다.
- distribution을 가진다
- 변수의 각 다른 값에 대해, 그 값을 가진 빈도 - 즉 퍼센트..
- 분포, 차지하는 비율
각 individual들은 하나의 카테고리를 가진다. 다합치면 100퍼센트가 된다.
중복된 값을 선택할 수 있는 경우
- bar들의 합은 100퍼센트가 아니다.
distribution이 아니다!!
100퍼센트란 말은 그 값들.. 즉 그 값들을 다 합쳤을때, 비교 대상,,이 되는 값 원본 값만큼 크기가 같다는 것,,, 그 비교 값이 중복 값을 가진다면 비교 대상 원본 값보다 큰 값이 다 합쳤을대 나오니깐 좋지 않아요Categorical Distribution
어떤 범주 값의 분포를 뜻한다!!
즉 숫자 값에 대한 분포가 아닌 어떤 범주(단어)의 분포를 표현할때를 의미한다.
Bar chart
변수의 모든 값을 모든 빈도와 함께 표시한다.
- 하나의 바에 하나의 카테고리를
- 바의 순서를 고를 수 있다.
- 소팅하면 되니깐
- 막대 길이는 해당 범주에 있는 값의 백분율(개수)이다.
그리기
Table.barh(카테고리값,x축)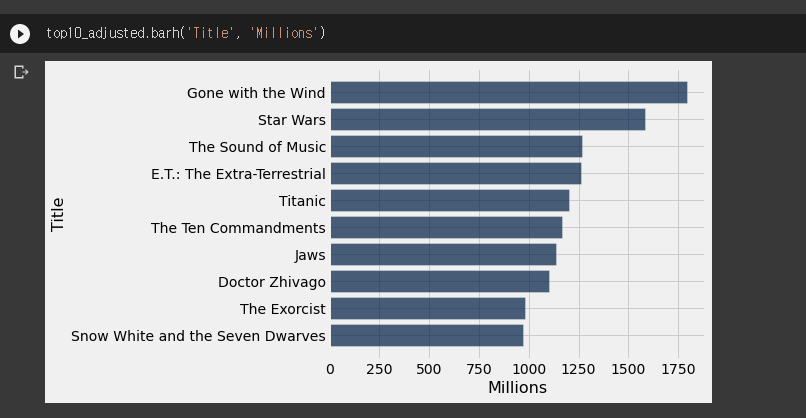
- 카테고리값들이 x값에 따라 얼마나 나타나는지 바로 표현한다.
x축은 numerical해야지 그래프가 그려진다.
Numerical Distribution
어떤 숫자의 분파를 뜻한다.
즉 단어가 아닌 어떤 숫자 값의 분포를 표현할때 의미한다.
이때는 빈을 만들어 범위를 나누어 준다.
Binning
비닝란 빈이라고 하는 범위 내에 있는 숫자 값의 수를 세는 것
- 자기 범위보다 작은 값들을 포함한다.
- 더 높은 값은 다음
빈 설정해 데이터 나누기
table.bin(칼럼명,빈)- 빈에 해당되는 칼럼의 값 개수를 나타내는 테이블을 반환한다.

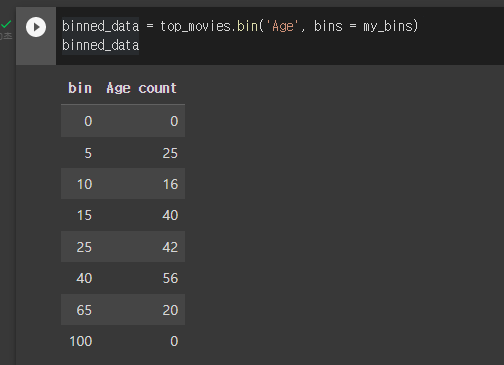
-
이렇게 하면 해당 테이블 칼럼 값들을 빈에 맞게 설정해 테이블을 반환한다.
numerical에 사용하는걸 잘 알고있어라..
-
[40,65) 빈에 값을 선택하려면 bin 40의 값을 고르면 된다.
빈 영역은 >= 인가 > 인가?
- A<=X<B이다.
- [)인걸로...
Area principle
영역은 해당 값이 나타내는 값에 비례해야 한다.
- 나타내기를 잘 해야한다.
) 번외
만약 테이블 값에서 백분율을 계산하려면??
-> 해당값/전체개수 * 100 하면 된다
히스토그램 그리기
히스토그램
- 숫자 변수의 분포를 표시한다.
- 하나의 막대가 하나의 bin에 속한다.
- Area principle을 사용한다.
- 각 영역은 bin이 나타내는 전체의 퍼센트만큼 나타내진다.
히스토그램 축
- 히스토그램은 차트의 면적이 100%가 되도록 하는 척도를 사용한다.
- 각 바의 영역은 전체에서의 퍼센트만큼 차지한다.
- 가로축은 숫자라인을 나타낸다.
- 빈의 크기는 같을 필요가 없다
- 수직 선은 rate이다.
히스토그램 높이 계산
- [40,65) 빈은 200개의 영화중 56개를 포함한다.
- 200개중 56 = 28%
- bin의 가로 = 25
- 바의 높이 = 28퍼센트/25년 = 1.12퍼센트의 높이를 가짐
높이는 밀도를 측정한다
-
높이 = 빈의 %/빈의 너비
- 빈의 퍼센트 = 높이*너비니깐
-
높이는 빈의 공간 양에 대한 빈의 데이터 백분율을 측정한다.
-
높이는 혼잡도 or 밀도를 측정한다
-
units: 가로 축의 단위당 백분율
영역은 퍼센트를 측정한다.
-
바의 영역 = 빈의 % = height * bin의 너비
-
얼마나 bin이 붐비냐??
- height(높이)를 사용
-
How many individuals in the bin?
- 영역 사용
그리기
table.hist(수평선 칼럼,빈, unit 이름,group="칼럼명")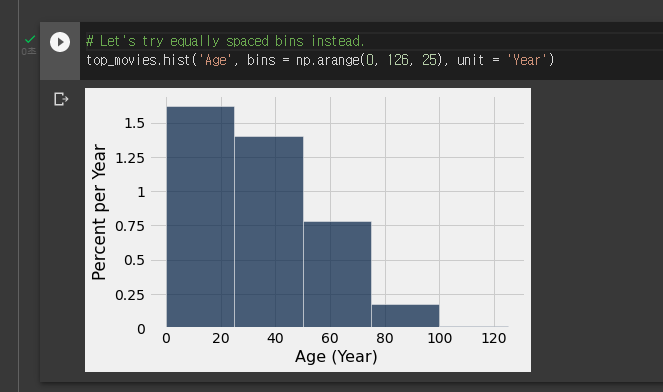
- 수평선 칼럼의 값이 빈에 맞추어 테이블에 얼마나(비율)있는지를 계산해 히스토그램으로 그려준다
-
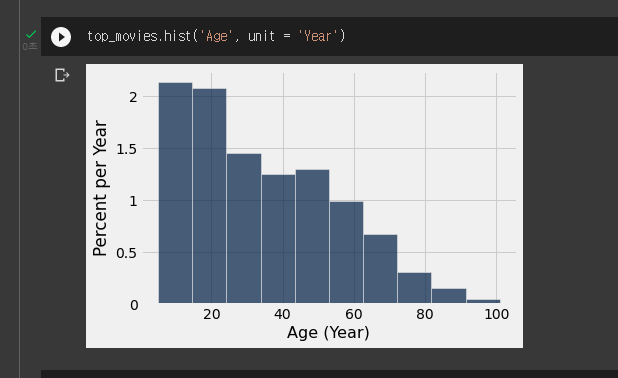
빈을 설정 안하면 제일 이쁘게 나와준다.
-
여기서 각 막대의 height이 퍼센트/막대의 width이다.
- age가 10보다 낮은 친구들이 25개 있다.
- 25/200/10 = 2.5다 첫번째 빈의 높이와 같다.
- age가 10보다 낮은 친구들이 25개 있다.
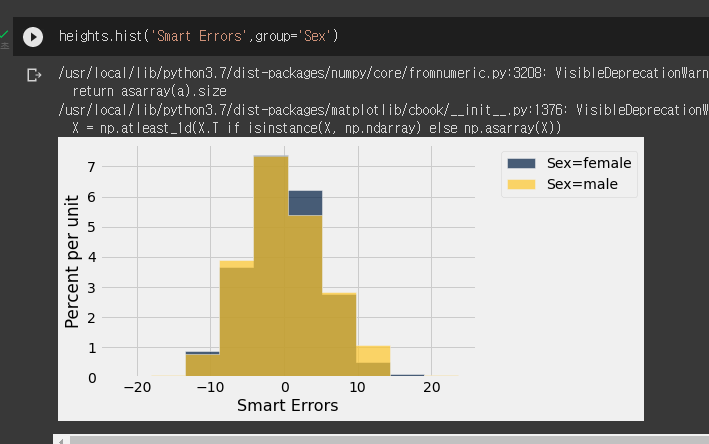
- 그룹에 칼럼을 지정하면 칼럼에 값을 그룹화해 나타낸다.
히스토그램은 수평선 값들이 테이블에 얼마나 있는지 비율을 나타내주는 그래프이다.
바그래프는 수평선 값들에 대한 수직선 비율을 알고 싶을때 쓴다
라인 그래프는 x 값이 뉴메릭일때, 순차적인 양적 데이터를 가질때
스캐터 그래프는 순차적이지 않은 양적 데이터를 가질때, 값들 사이 연관성을 알고싶을때 사용한다.
