데이터 과학 기초
function
왜 데이터를 시각화 하는가?
- 차트는 해석 가능한 방식으로 많은 정보를 전달할 수 있다.
- 사람들은 시각적 매체에서 다양한 패턴을 찾기 쉽다.
Histogram Heights
막대의 영역 = 빈의 퍼센트 = 높이 * 빈의 너비
- 빈에 얼마나 많은 사람(투플)이 있는가
- 영역 사용
- 빈이 얼마나 빽빽한가
- 즉 빈의 간격이 얼마나 빽빽한것인가를 의미한다.
- 높이 사용
- 쓸데없이 구간을 잡으면 높이가 높게 나올 수 있음
차트들을 사용할 시기
line graph
- 연속적인 데이터
scatter plot
- 두개의 numeric 값들 사이 관계를 알기 위해
bar chart
- 하나의 categorical 변수의 분포 또는 categorical 변수와 숫자 변수 사이의 관계
- bin이 없어 그냥 그 값에 대한 퍼센트 or 카테고리 값들과 다른 뉴메릭 값의 관계니...
histogram
- numerical 값들의 분포
- bin을 만드니깐 numerical 값들!!
함수
함수생성은 알아서~~
Apply
- 칼럼의 모든 요소에 대해 함수를 호출한다.
- 각 입력 열 요소에 대한 함수의 출력을 포함하는
배열을 생성한다.
Table.apply(함수이름,칼럼명)Ex
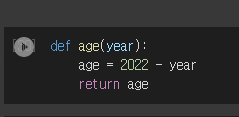

- 이름과 나이를 말해주는 함수를 만들었다.
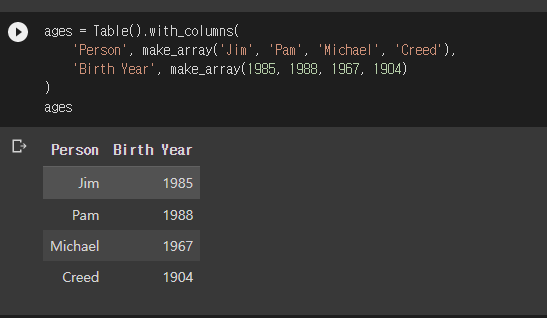
- 테이블이다.
이 테이블의 row에 함수를 다 적용하고 싶다면?? apply 사용해
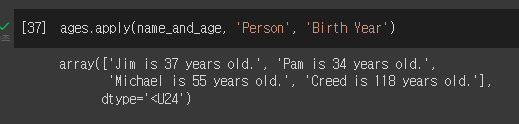
테이블이 데이터 타입이 다 number라면 col을 지정하지 않고 테이블 row마다 함수를 apply 할 수도 있다.
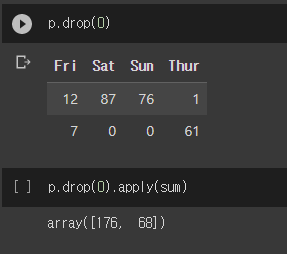
np.mean이랑 np.average랑 같다.
Grouping
Group single column
table.group(칼럼명,값을 어떻게 묶을까)group메서드는 column에 값들에 동일한 값을 가진 모든 row들을 반환한다.- 1번째 파라미터는 그룹을 할 칼럼명을 입력한다.
- 2번째 파라미터는 어떻게 값들을 결합할지 나타낸다.
- len: 값들의 개수
- list: 값들을 리스트로 반환한다.
- sum: 값들을 합한다.
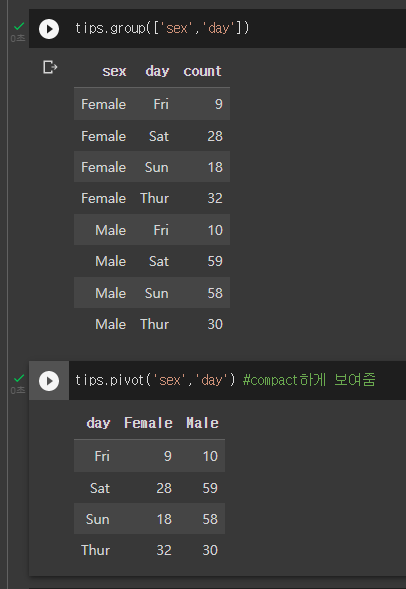
Group by Multiple Column
table.group([칼럼명,칼럼명],collect)- group 메소드는 Column의 값 조합을 공유하는 모든 row를 집계할 수도 있다.
- 1번째 파라미터는 그룹을 할 칼럼들의 리스트
- 2번째 파라미터는 어떻게 값을 묶을지
그룹 사용법
일단 테이블이다.
여기서 각 요일별 팁들의 평균을 알고 싶다면..
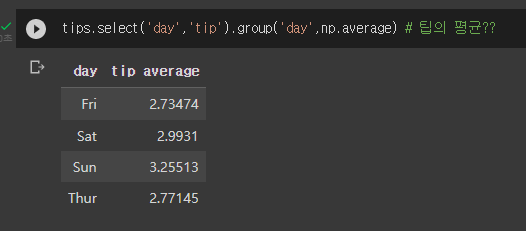
짜잔....
즉 해당 칼럼의 값들에 해당하는 값들을 계산을 할 때 사용하면된다.
테이블에서 칼럼이 여러개라면 group을 할 칼럼빼고 나머지 칼럼들이 그룹을할 칼럼에 맞춰 값들이 반환된다.
그룹을 그냥 칼럼만 명시하면 카운트만 해줌.
다른 작업을 한다면 해당 칼럼 말고 다른 칼럼에 대해 작업함
두개 이상 칼럼을 그룹핑하는거
이런 테이블이 있다.
성별과 날짜에 따른 tip의 평균을 알고싶다면..
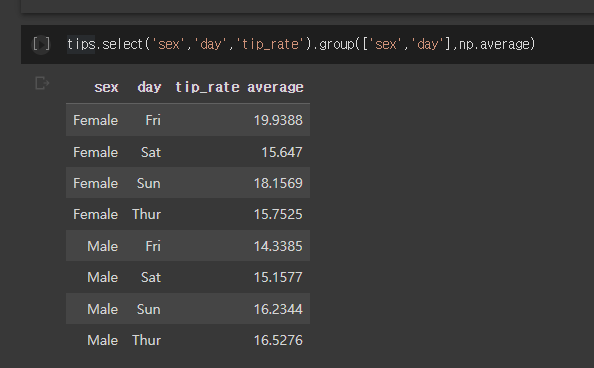
- 이렇게할 수 있다..
List
-
리스트는 값들의 연속이다.
- 값들은 각자 다른 타입을가져도 된다.
-
리스트는 table row를 생성할때 사용될 수 있다.
-
table column을 리스트로부터 만들어도 array로 변환된다.
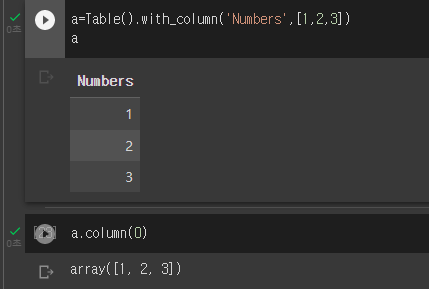
- 리스트로 테이블 칼럼을 만들고 이 값들을 array로 가져오는 모습이다.
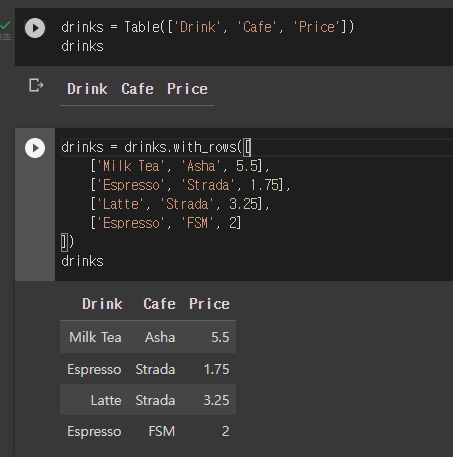
- 리스트로 테이블을 생성할 수도 있다.
Pivot Table
Pivot
table.pivot(가로축,세로축,values = 수집할 값들,collect= 수집 반환 값)-
두 범주형 변수에 따라 교차 분류
-
카운트 또는 집계된 값의 그리드를 생성한다
-
두 개의 필수 인자:
-
첫째: 그리드의 column 레이블을 형성하는 변수
- 가로 값
-
두 번째: 그리드의 row 레이블을 형성하는 변수
- 세로 값
-
-
두 개의 선택적 인수(둘 다 포함하거나 둘 다 포함안함)
-
valus = 수집할 column 이름
-
collect = 수집할 함수
-
쓰는법
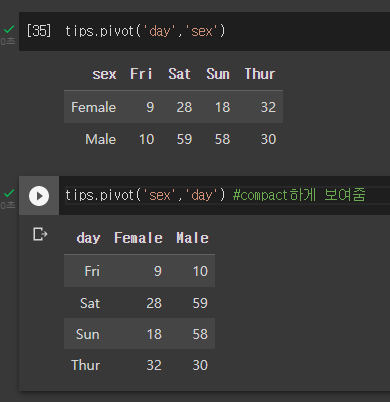
그룹과 달리 row col을 모두 지정해 compact하게 보여줄 수 있다.
첫번째 칼럼명 - 가로
두번째 칼럼명 - 세로
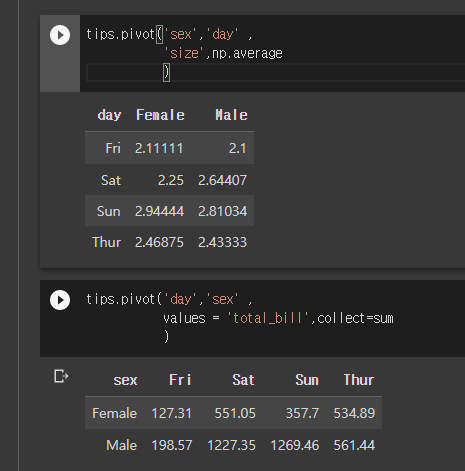
추가적 파라미터를 이용할 수 있다.
Group vs Pivot
하나의 categorical 변수에 대한 distribution을 알고싶을때
- group을 사용
- numerical은 히스토그램
두개 이상 categorical 변수의 교차 분류
- 하나의 행만 필요할때는 group 사용
- 하나는 수직, 하나는 수평적으로 나타내는게 좋을때는 pivot 사용
나의 생각인데 그냥 두개이상 변수에 대해 뭐한다면 피봇이 좋은듯
Join
두개의 테이블을 합친다.. 디비에도 있음
table.join(합칠때 이용할 칼럼,합칠 테이블,합칠때 이용할 칼럼)- 합치지 못하는 행은 반환값에 없다.
- 값이 안맞으면 합치지 못하는거
- 동일한 테이블끼리 join도 가능하다.
ex
t.join(,u,)의 한 가지 일반적인 사용
-
데이터 집합 t에는 categorical 변수 x가 있다.
-
표 u에는 해당 값의 일부 속성을 설명하는 가능한 x 값당 하나의 행이 있다.
-
조인된 테이블의 행은 t와 동일하지만, 이제 t의 각 행은 x 값의 속성을 가질 수 있다.
