컴퓨터망
19. World wide web and HTTP
World Wide Web(WWW)은 전 세계의 여러 지점에서 연결된 정보의 저장소이다
WWW는 인터넷에서 제공하는 다른 서비스와 구별되는 유연성, 휴대성 및 사용자 친화적인 기능의 고유한 조합을 가지고 있다
이 장에서는 먼저 웹과 관련된 문제를 논의한다
그런 다음 웹에서 정보를 검색하는 데 사용되는 프로토콜인 HTTP에 대해 논의한다
Architecture
- 오늘날 WWW는 브라우저를 사용하는 클라이언트가 서버를 사용하여 서비스에 액세스할 수 있는 분산 클라이언트-서버 서비스이다
- 제공된 서비스는 사이트라고 하는 여러 위치에 배포된다
- 각 사이트에는 웹 페이지라고 하는 하나 이상의 문서가 있다
- 웹 페이지에는 같은 사이트나 다른 사이트에 있는 다른 웹 페이지에 대한 링크가 포함될 수 있다
즉 웹 페이지는 단순하거나 복합적일 수 있다
EX 1
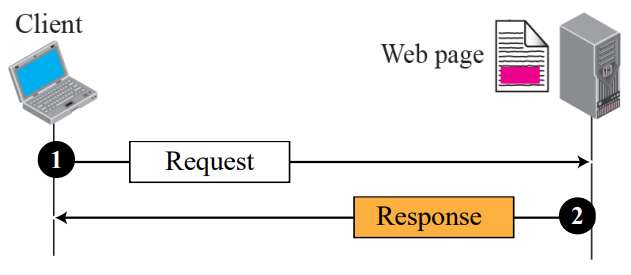
- 전체 문서는 단순한 웹 페이지입니다
- 그림과 같이 단일 요청/응답 트랜잭션을 사용하여 검색할 수 있다
EX 2
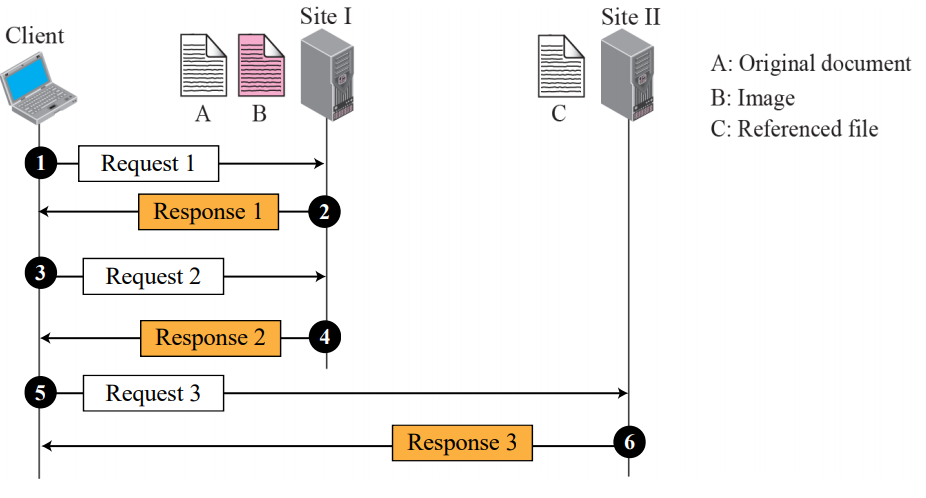
이제 다른 텍스트 파일에 대한 reference 하나와 큰 이미지에 대한 reference 하나가 포함된 문서를 검색해야 한다고 가정한다
-
기본 문서와 이미지는 동일한 사이트(파일 A 및 파일 B)에 두 개의 개별 파일에 저장됩니다
-
참조된 텍스트 파일은 다른 사이트(파일 C)에 저장된다
-
세 개의 서로 다른 파일을 다루기 때문에 전체 문서를 보려면 세 개의 트랜잭션이 필요하다
-
첫 번째 트랜잭션(요청/응답)은 두 번째 및 세 번째 파일에 대한 참조(포인터)가 있는 주 문서(파일 A)의 사본을 검색한다
-
기본 문서의 사본이 검색되고 탐색될 때 사용자는 이미지에 대한 참조를 클릭하여 두 번째 트랜잭션을 호출하고 이미지의 사본(파일 B)을 검색할 수 있다
-
사용자가 참조된 텍스트 파일의 내용을 더 보려면 해당 참조(포인터)를 클릭하여 세 번째 트랜잭션을 호출하고 파일 C의 복사본을 검색할 수 있다
-
파일 A와 B가 모두 사이트 I에 저장되어 있지만 , 그들은 다른 이름과 주소를 가진 독립적인 파일이다 이를 검색하려면 두 가지 트랜잭션이 필요합니다.
Web Client 브라우저
웹 문서를 해석하고 표시하는 브라우저
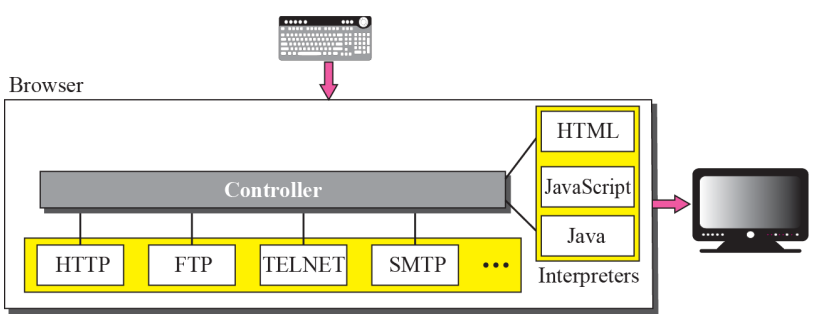
- 각 브라우저는 일반적으로 컨트롤러, 클라이언트 프로토콜 및 인터프리터의 세 부분으로 구성된다
- 컨트롤러는 키보드나 마우스로부터 입력을 받고 클라이언트 프로그램을 사용하여 문서에 액세스한다
- 문서에 액세스한 후 컨트롤러는 인터프리터 중 하나를 사용하여 화면에 문서를 표시합니다
- 클라이언트 프로토콜은 FTP, TELNET 또는 HTTP
- 인터프리터는 문서 유형에 따라 HTML, Java 또는 JavaScript일 수 있다
Web server
웹 페이지는 서버에 저장된다
클라이언트 요청이 도착할 때마다 해당 문서가 클라이언트로 전송된다
URL

- 웹 페이지에 액세스하려는 클라이언트는 파일 이름과 주소가 필요하다
- URL(Uniform Resource Locator)은 인터넷에서 모든 종류의 정보를 지정하기 위한 표준 로케이터이다
- URL은 프로토콜, 호스트 컴퓨터, 포트 및 경로의 네 가지를 정의한다
protocol
- 문서를 검색하는 데 사용되는 클라이언트-서버 응용 프로그램
- FTP, HTTP, TELNET이 있다
- 가장 일반적인 것은 HTTP입니다.
host
- 정보가 있는 컴퓨터의 도메인 이름
- 일반적으로 "www" 문자로 시작하는 도메인 이름 별칭이 지정
port
- URL은 선택적으로 서버의 포트 번호를 포함할 수 있다
- 포트가 포함되어 있으면 호스트와 경로 사이에 삽입되며 호스트와 콜론으로 구분된다
path
- 정보가 있는 파일의 경로 이름
- 경로 자체에 슬래시가 포함될 수 있다
- 이 슬래시는 UNIX 운영 체제에서 디렉터리를 하위 디렉터리 및 파일과 구분한다
- 즉, 경로는 디렉토리 시스템에서 문서가 저장되는 완전한 파일 이름을 정의
Web Document
WWW의 문서
- static
- dynamic
- active
분류는 문서의 내용이 결정된 시점을 기준으로 한다
Static Documents
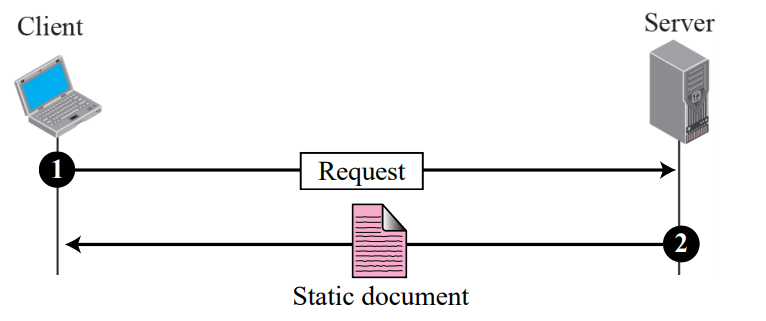
- 정적 문서는 서버에서 생성 및 저장되는 고정 콘텐츠 문서이다
- 클라이언트는 문서의 사본만 받을 수 있다.
- 즉, 파일의 내용은 파일을 사용할 때가 아니라 생성될 때 결정된다
- 물론 서버의 내용은 변경할 수 있지만 사용자는 변경할 수 없다
HTML XML XSL XHTML로 만들어진다
Dynamic Documents
- 브라우저가 문서를 요청할 때마다 웹 서버에 의해 동적 문서가 생성된다
- 요청이 도착하면 웹 서버는 동적 문서를 생성하는 응용 프로그램이나 스크립트를 실행한다
- 서버는 문서를 요청한 브라우저에 대한 응답으로 프로그램 또는 스크립트의 출력을 반환한다
- 각 요청에 대해 새 문서가 생성되기 때문에 동적 문서의 내용은 요청마다 다를 수 있다
Dynamic document using CGI
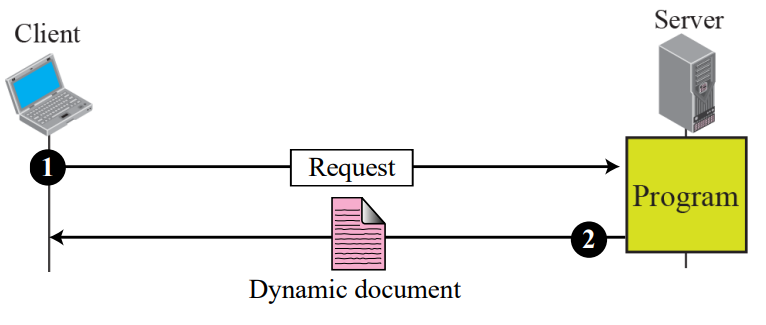
CGI(Common Gateway Interface)는 동적 문서를 생성하고 처리하는 기술이다
Dynamic document using server site script
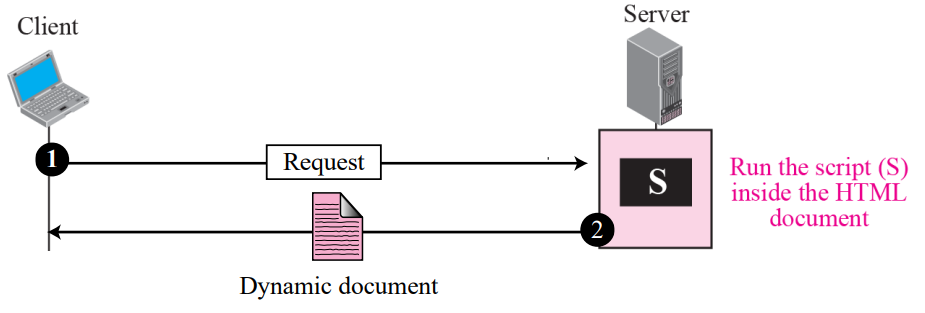
HTML을 사용하여 문서의 고정된 부분을 포함하는 파일을 만들고 다양한 섹션을 제공하기 위해 서버에서 실행할 수 있는 소스 코드인 스크립트를 포함한다
dynamic document를 서버 사이트 동적 문서라고도 한다
Active Documents
많은 응용 프로그램의 경우 클라이언트 사이트에서 실행할 프로그램이나 스크립트가 필요하다
이를 acitve 문서라고 한다
예를 들어 화면에 애니메이션 그래픽을 생성하는 프로그램이나 사용자와 상호 작용하는 프로그램을 실행하려고 한다고 가정한다
프로그램은 애니메이션이나 상호 작용이 발생하는 클라이언트 사이트에서 반드시 실행되어야 한다
브라우저가 활성 문서를 요청하면 서버는 문서 또는 스크립트의 복사본을 보낸다
그러면 클라이언트(브라우저) 사이트에서 문서가 실행된다
Active document using Java applet
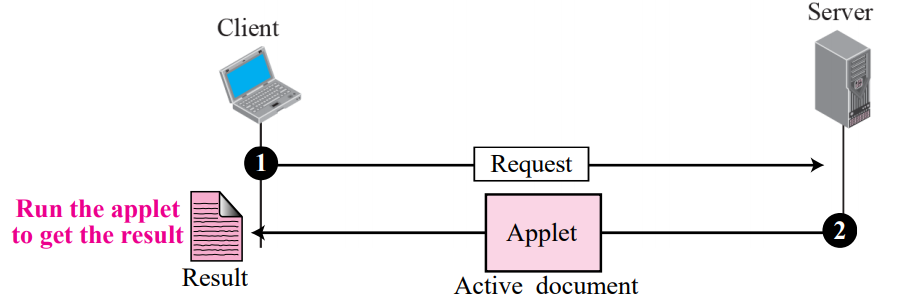
active 문서를 만드는 한 가지 방법은 Java applet을 사용하는 것
브라우저가 URL에 있는 Java applet 프로그램을 직접 요청하고 applet을 수신한다
Active document using JS
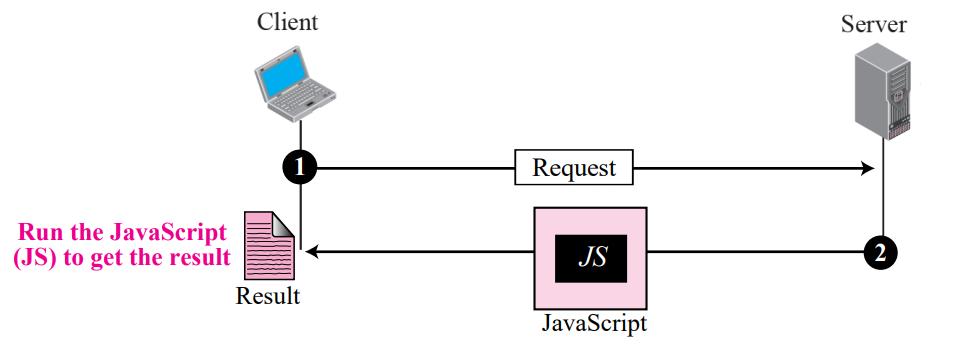
active 문서를 클라이언트 사이트 active 문서라고도 한다
HTTP
HTTP(Hypertext Transfer Protocol)는 주로 World Wide Web의 데이터에 액세스하는 데 사용되는 프로토콜이다
HTTP는 FTP와 SMTP의 조합과 같은 기능을 한다
파일을 전송하고 TCP 서비스를 사용한다는 점에서 FTP와 유사하다
그러나 하나의 TCP 연결만 사용하기 때문에 FTP보다 훨씬 간단하다
별도의 control connection이 없다
클라이언트와 서버 간에 데이터만 전송된다
HTTP는 TCP를 사용하고 80번 포트번호를 사용한다
Http Transaction
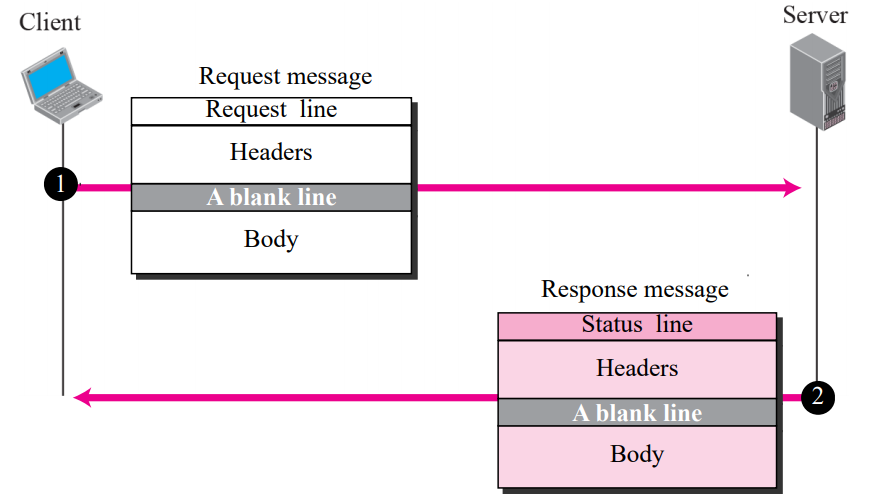
그림은 클라이언트와 서버 간의 HTTP 트랜잭션을 보여준다
HTTP는 TCP 서비스를 사용한다
클라이언트는 request을 보내 트랜잭션을 초기화한다
서버는 response을 보내 응답한다
Request message format
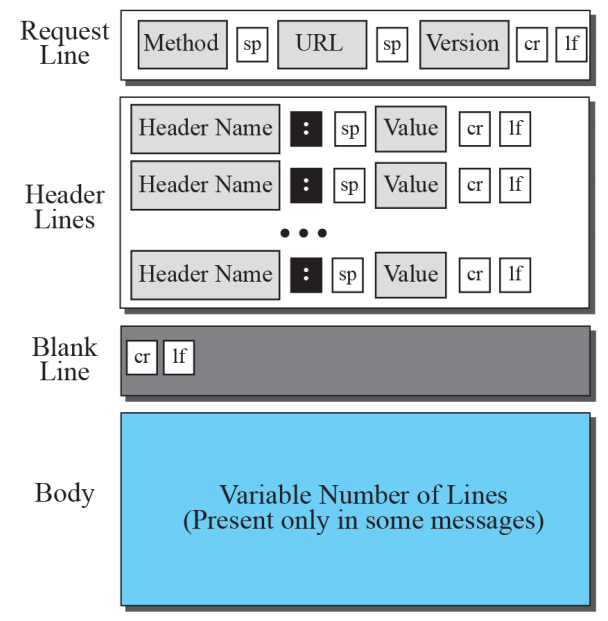
Request line
request 메시지의 첫 번째 줄을 request line이라고 한다
이 줄에는 세 개의 필드가 있다
필드는 메소드, URL 및 버전이라고 한다
이 세 개는 공백 문자로 구분해야 한다
두 문자 끝에 줄 바꿈이 뒤따르는 캐리지 리턴이 줄을 종료한다
MEthod
메소드 필드는 요청 유형을 정의합니다.

두 번째 필드인 URL은 해당 웹 페이지의 주소와 이름을 정의한다
세 번째 필드인 version은 프로토콜의 버전을 제공한다
Headerline
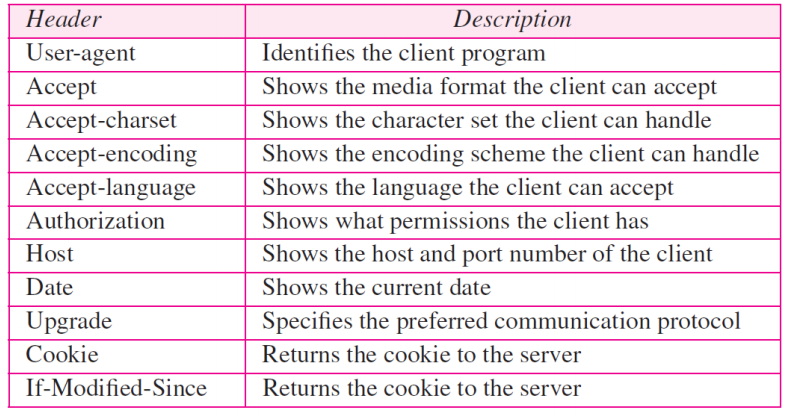
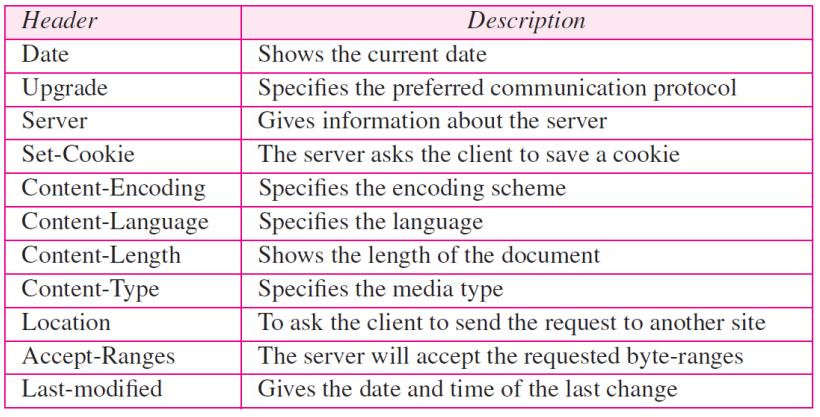
각 header line은 클라이언트에서 서버로 추가 정보를 보낸다
각 헤더 행에는 헤더 네임, 콜론, 공백 및 헤더 값이 있습니다
헤더 네임
Response message
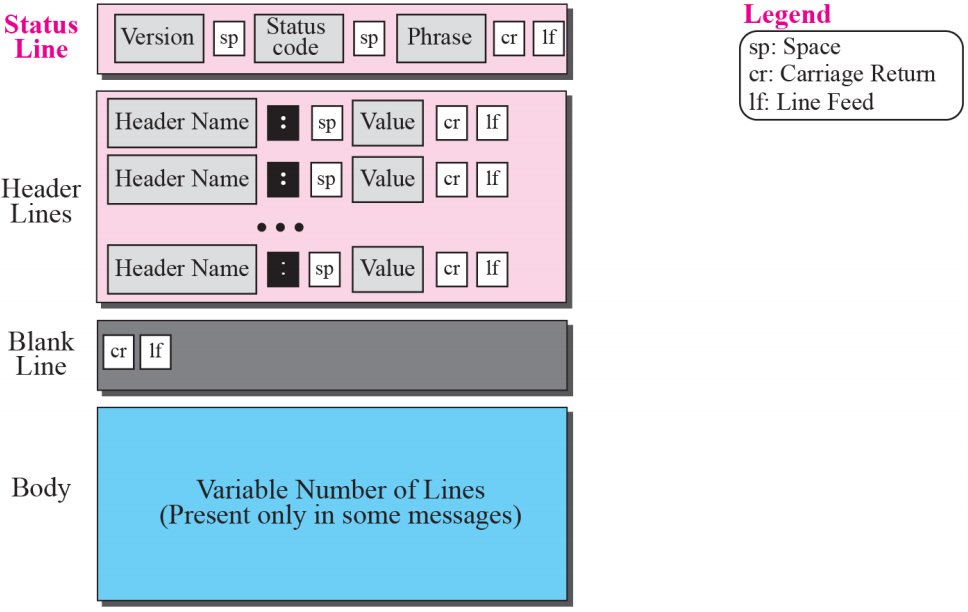
Status line
응답 메시지의 첫 번째 줄을 Status line이라고 한다
이 줄에는 공백으로 구분되고 캐리지 리턴과 줄 바꿈으로 끝나는 세 개의 필드가 있다
첫 번째 필드는 HTTP 프로토콜의 버전을 정의한다
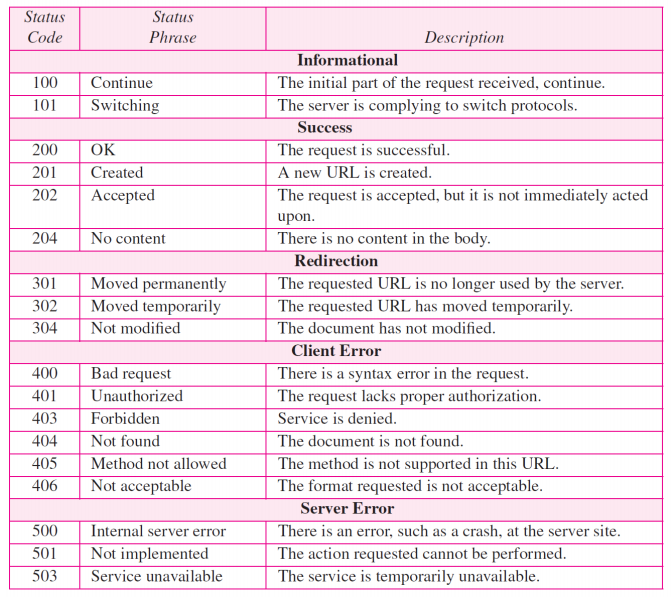
status code 필드는 request의 상태를 정의한다
Header line
상태 줄 다음에 0개 이상의 응답 헤더 줄이 있을 수 있다
각 헤더 행은 서버에서 클라이언트로 추가 정보를 보낸다
각 헤더 line에는 헤더 이름, 콜론, 공백 및 헤더 값이 있다
Ex 문서 저장
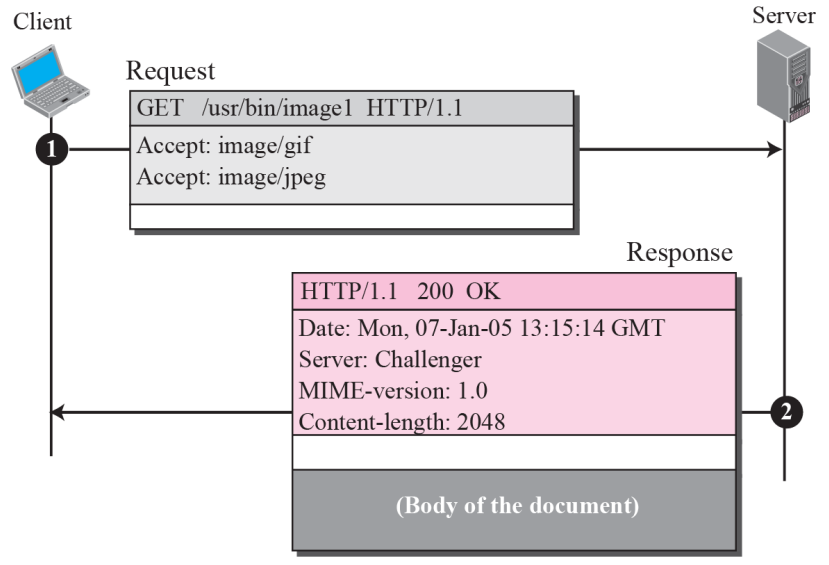
GET 메소드를 사용하여 경로가 /usr/bin/image1인 이미지를 검색한다
request line은 메소드(GET), URL 및 HTTP 버전(1.1)을 보여준다
헤더에는 클라이언트가 GIF 또는 JPEG 형식의 이미지를 허용할 수 있음을 보여주는 두 줄이 있습니다
응답 메시지에는 request line과 4줄의 헤더가 포함된다
헤더 행은 문서의 날짜, 서버, MIME 버전 및 길이를 정의한다
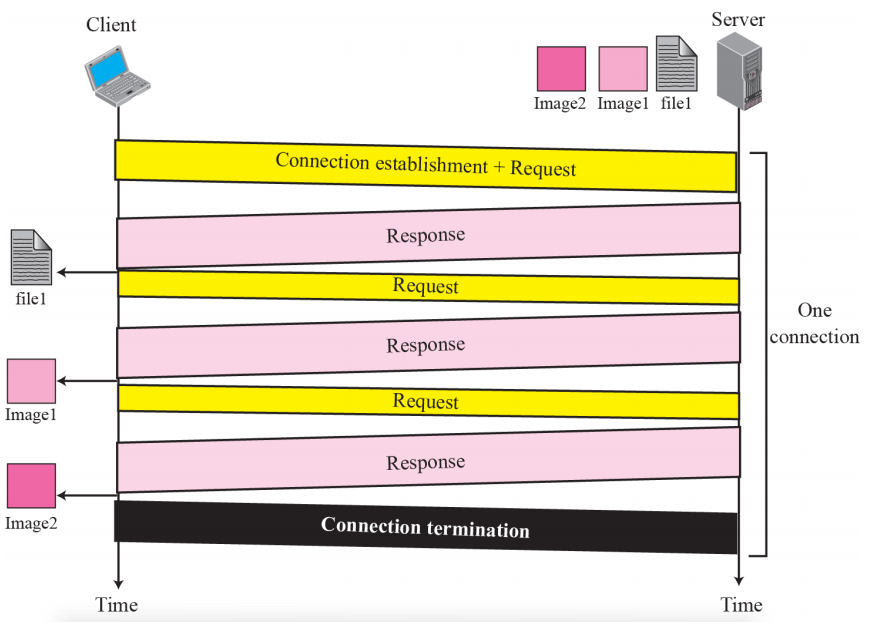
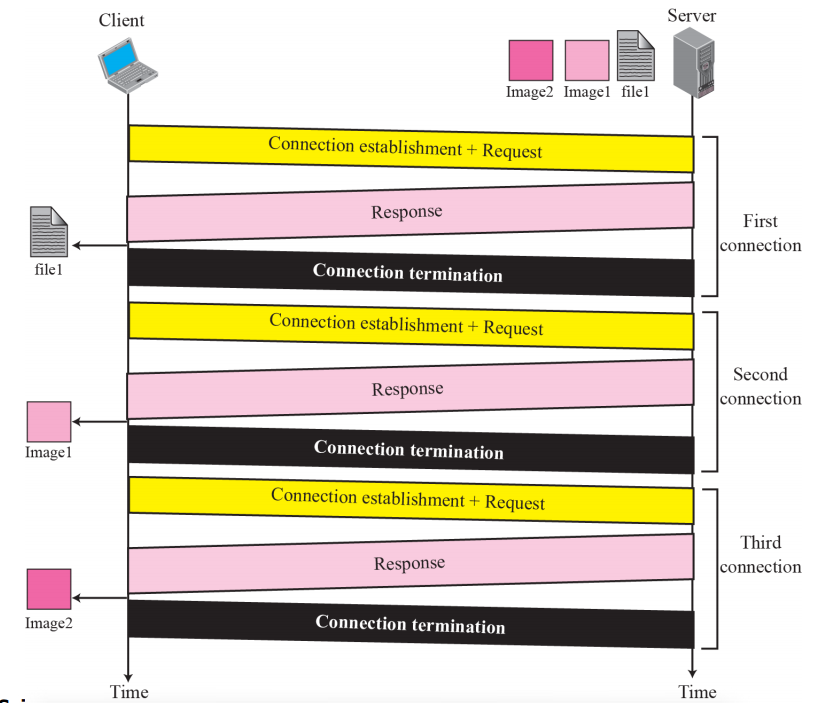
Nonpersistent connection
nonpersistent connection에서는 각 요청/응답에 대해 하나의 TCP 연결이 만들어진다
- 클라이언트는 TCP 연결을 열고 요청을 보낸다
- 서버가 응답을 보내고 연결을 닫는다
- 클라이언트는 EOF를 만날 때까지 데이터를 읽는다 그런 다음 연결을 닫는다
이 전략에서 파일에 다른 파일의 N개의 다른 그림에 대한 링크가 포함되어 있으면 연결을 N + 1회 열고 닫아야 한다
Persistent connection
persistent 연결에서 서버는 request를 보낸 후 추가 request를 위해 연결을 열어 둔다
서버는 클라이언트의 request가 있거나 timeout일 경우 연결을 닫을 수 있다
HTTP 1.1은 persistent connection을 기본으로 한다