컴퓨터망
2. IPv4 주소
네트워크 계층에서, 우리는 모든 장치들 간의 글로벌 통신을 허용하기 위해
인터넷에서 각 장치를 고유하게 식별해야 한다.
이 점에서, IPv4 어드레싱이라고 불리는 일반적인 IPv4 프로토콜과 관련된 어드레싱 메커니즘에 대해 논의한다.
IPv6 프로토콜이 결국 현재의 프로토콜을 대체할 것으로 믿으며,
IPv6 주소 지정도 인식해야 한다.Introduction
IP 주소, 인터넷 주소
- TCP/IP 프로토콜의 IP 계층에서 인터넷에 연결된 각 장치를 식별하는 데 사용되는 식별자
IPv4는 32bit이다
IPv4는 unique,universal하다
- IPv4주소는 고유하다
- 각 주소가 인터넷 연결을 하나만 정의한다
- 다른 컴퓨터가 동시에 동일한 주소를 가질 수 없다
IPv4의 주소공간은 2^32개이다
주소를 정의하는 IPv4와 같은 프로토콜에는 주소 공간이 있다.
주소 공간은 프로토콜에서 사용하는 총 주소 수이다. 프로토콜이 주소를 정의하기 위해 비트를 사용하는 경우,
각 비트는 두 개의 다른 값(0 또는 1)을 가질 수 있기 때문에 주소 공간은 2^b이다.
IPv4는 32비트 주소를 사용하며, 이는 주소 공간이 2^32 또는 4,294,967,296(40억 이상)임을 의미한다.
이론적으로 제한이 없다면 40억 개 이상의 기기를 인터넷에 연결할 수 있다.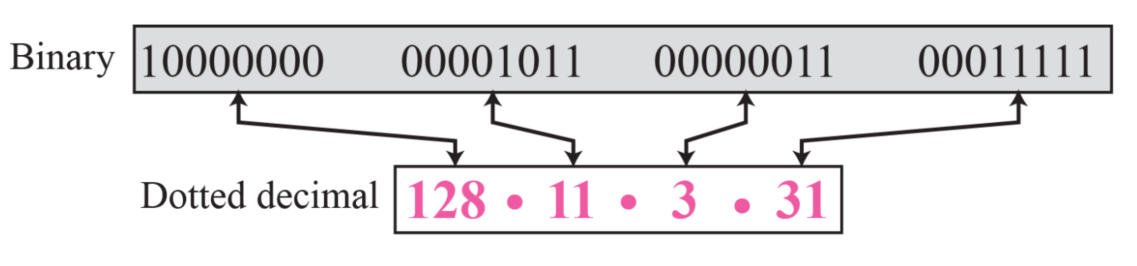
- 주소를 쉽게 읽기 위해서
Dotted-decimal notation을 사용한다- 32비트(4바이트)니 8비트씩씩 끊어서 묶는다
- 0~255까지
- 32비트(4바이트)니 8비트씩씩 끊어서 묶는다
Classful addressing
- IP 주소는, 수십 년 전에 시작되었을 때, 클래스의 개념을 사용했다.
classful addressing- 나중에 classless로 대체된다
Classes
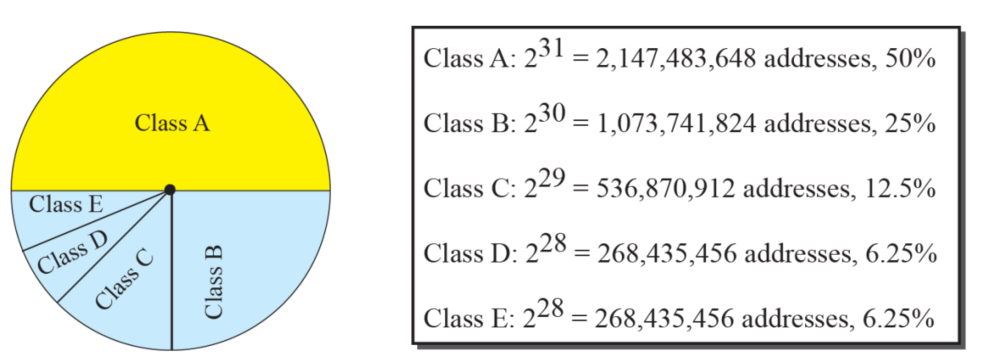
- IP 주소공간은 A,B,C,D,E 클래스로 나뉜다
recognizing Classes
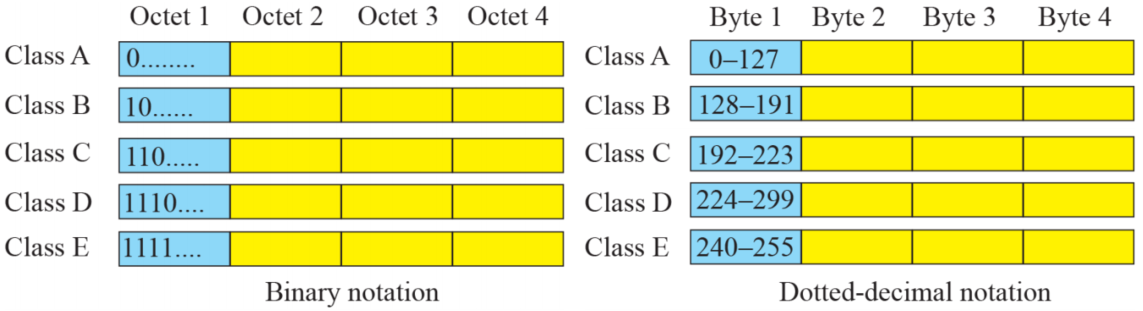
- 2진법에서 첫 비트로 주소의 클래스를 판단 가능
- 10진법에서는 첫번째 바이트 값으로 주소의 클래스 판단 가능
주소의 클래스를 찾기 위해서는 아래의 알고리즘을 사용하는 것이 좋다
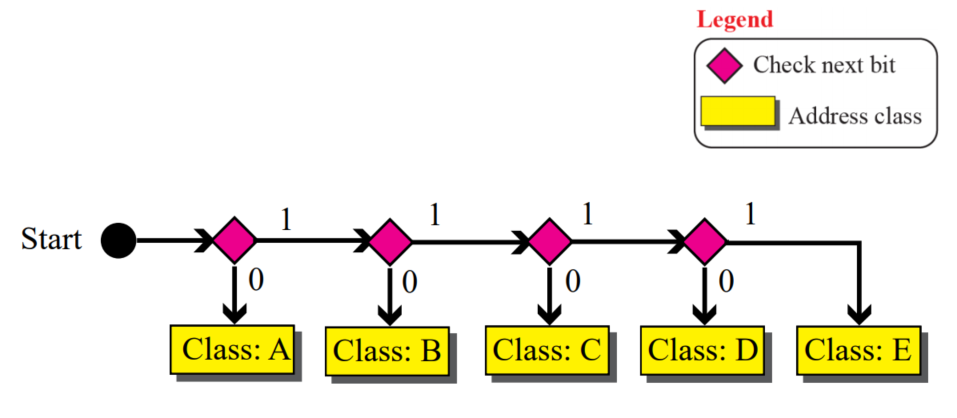
- 첫번째 비트부터 시작해서, 비트가 1이면 해당 클래스로 판단이 되는 알고리즘이다
Netid and Hostid
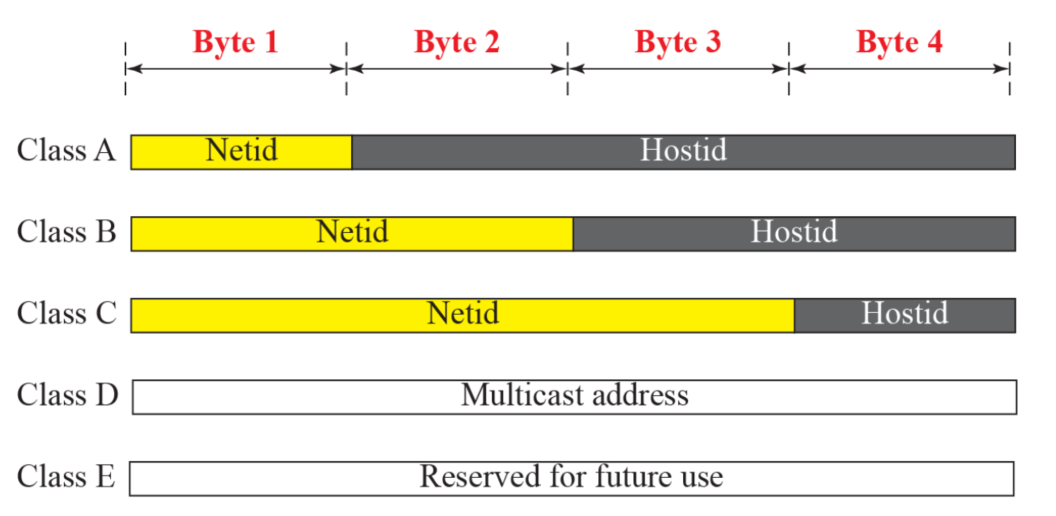
- classful addressing에서 클래스 A,B,C는 두 부분으로 나뉘어 진다
- Netid
- Hostid
- 각 부분은 주소의 클래스에 따라 나뉜다
- D와 E 클래스는 나뉘어지지 않는다
- 각 각 클래스의 용도가 다르기 때문
- D: 멀티캐스트
- E: 여분
- 각 각 클래스의 용도가 다르기 때문
Classes and Blocks
페이징처럼 netid마다 해당 network가 사용할 수 있는 hostid가 존재한다
그럼 내부단편화같은 문제가 생기지 않을까...? 라고 추측해본다Class A

- 128개의 netid 블럭을 가진다
- 8비트 중 MSB가 0이기 때문에 나머지 7개의 비트로 활용 가능
- 해당 블럭 당 2^24개의 주소를 가질 수 있다
즉 하나의 블럭 당 정말 많은 주소를 가질 수 있다
- 낭비가 된다
Class B

- 2^14개의 블럭을 가진다
- 16개 비트 중 2개의 비트가 10으로 고정이기 때문에
- 각 블럭은 2^16개의 주소를 사용가능하다
낭비가 된다
Class C

- 2^21개의 블럭을 가진다
- 24개 비트 중 3비트가 110으로 고정이기 때문
- 각 블럭은 2^8개의 주소를 가진다
각 블럭 당 주소가 너무 작다
Class D
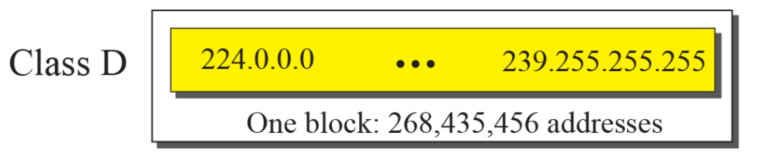
- 멀티 캐스팅을 위해 만들어진 클래스다
- 하나의 블럭이다
- 1110을 제외한 나머지 비트를 사용
Class E

- 여분의 주소이다
Two level Addressing
netid
- 네트워크를 정의한다
hostid
- 네트워크에 연결된 특정 호스트를 정의한다
classful 주소에서 부여할 수 있는 주소의 범위는 A,B,C 클래스이다
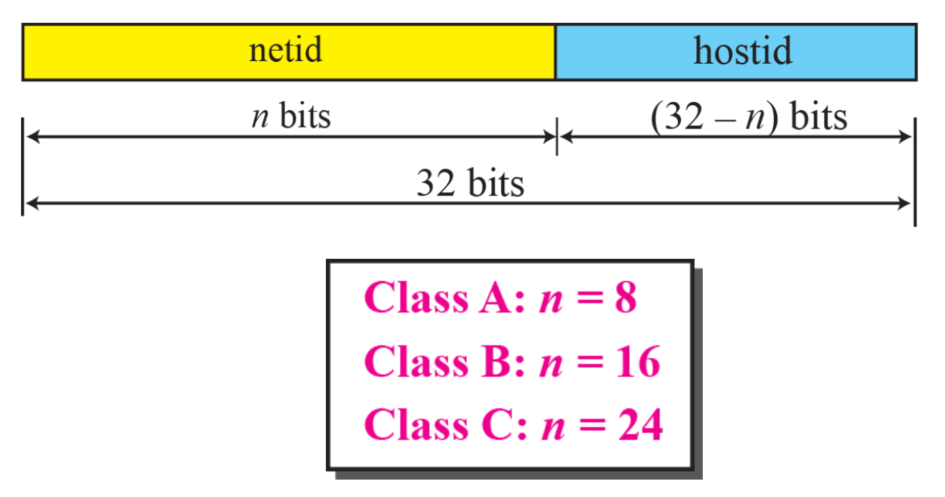
- classful에서 각 블럭은 2개의 부분으로 나뉘어진다
- netid
- hostid
- n비트가 net에 쓰인다면 32 - n 비트가 호스트에 쓰인다
- 그치만 net에 쓰이는 비트는 정해져있다
- 왜?? 클래스 때매
- A = 8
- B = 16
- C = 24
- 왜?? 클래스 때매
- 그치만 net에 쓰이는 비트는 정해져있다
Extracting information in a block
- 클래스의 블럭 별로 시작 주소와 마지막 주소를 확인할 수 있다
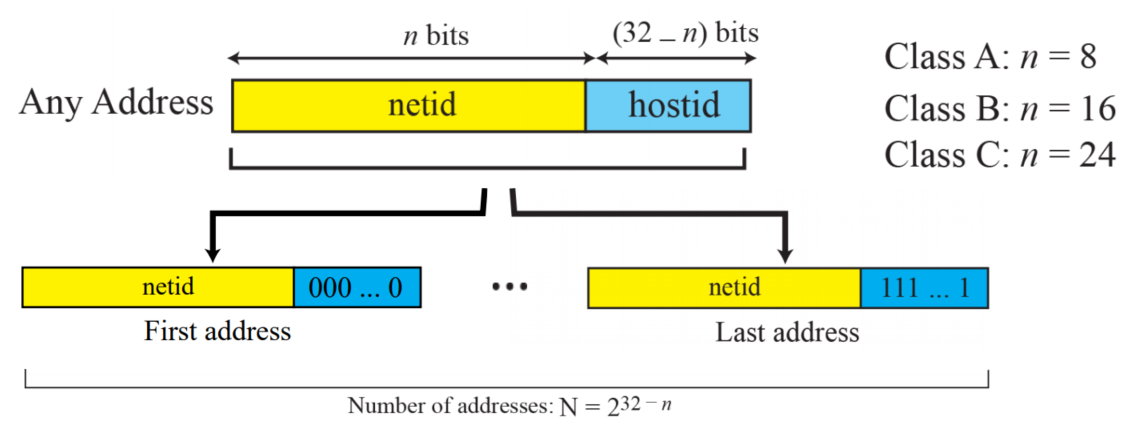
- 주소의 블럭을 안다면, 32-N비트로 호스트 부분을 찾을 수 있다
- 첫 주소를 찾기 위해, host 부분의 모든 비트를 0으로 설정할 수 있다
- 마지막 주소를 찾기 위해, host 부분의 모든 비트를 1로 설정할 수 있다
ex
73.22.17.25 주소가 주어졌을 때, 첫 주소, 마지막 주소를 찾아라
클래스 A, A의 n은 8, 그렇다면 호스트 부분은 24
시작: 73.0.0.0
마지막: 73.255.255.255네트워크 주소는 네트워크의 식별자다, net ID
Network mask
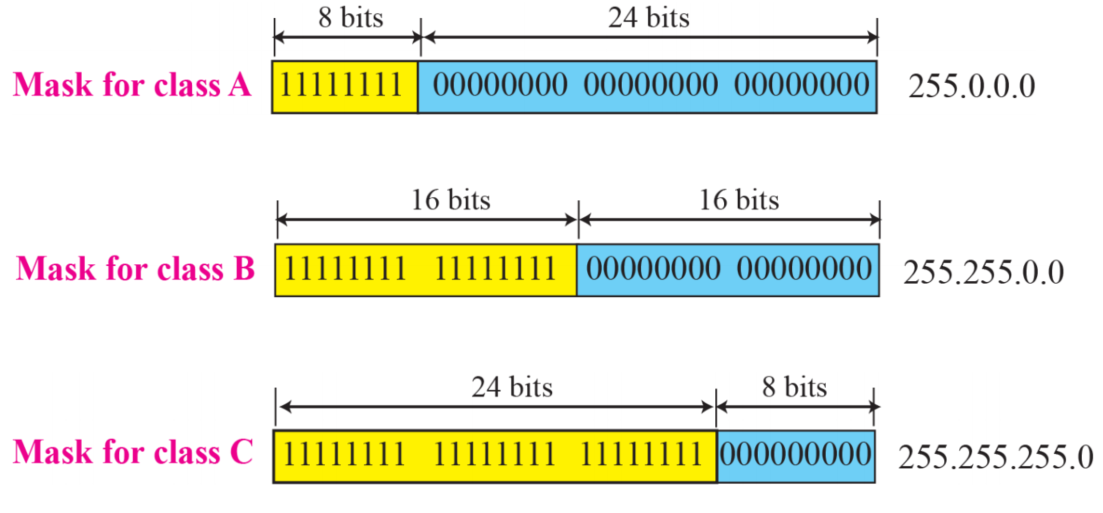
- 라우터는 패킷의 destination 주소에서 네트워크 주소를 추출하기 위한 알고리즘을 사용한다
- 네트워크 마스크가 필요하다
- 각 클래스별 해당되는 네트워크 부분 비트를 and연산을 활용해 추출한다
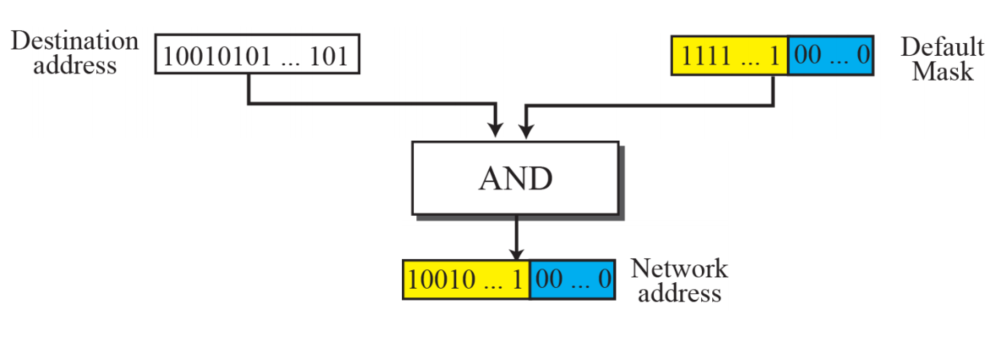
- destination 주소에 마스크를 씌워 네트워크 주소를 찾아낸다
- 마스크를 통해 블럭의 주소 수와 마지막 주소를 찾는데도 활용할 수 있다
Three level addressing; Subnetting
IP주소는 2레벨로 설계되었다.
인터넷의 호스트에 도달하려면, 네트워크에 연결 후, 호스트로 가야한다
이 후 2개 이상의 레벨이 필요한 이유가 나타났다
1. 더 나은 보안, 관리
2. 주소 고갈
=> 서브넷팅이란 개념이 등장했다서브넷팅
- 네트워크는 여러개의 작은 subnetworks로 나뉘어진다
- 각각의 서브넷은 고유한 서브넷 주소를 가지고 있다
서브넷 마스크
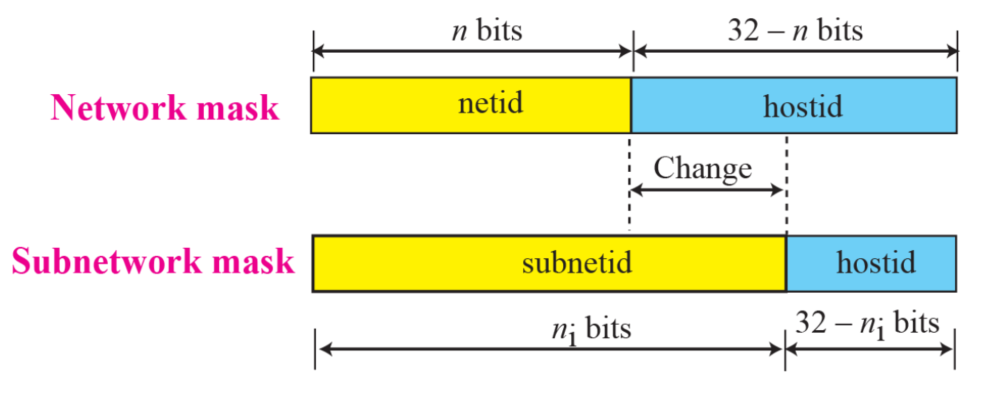
-
네트워크를 여러 서브넷으로 나눌 때, 서브넷 마스크가 필요하다
-
subnetid, hostid를 가진다
-
subnetting은 netid를 늘리고 hostid를 줄인다
supernetting
클래스 C는 호스트가 부족하기 때문에 슈퍼넷을 활용해 해결을 한다
여러 C클래스를 결합해 더 큰 범위의 주소를 만들 수 있다- 여러 개의 네트워크가 결합해 supernetwork를 만든다
- 이를 통해 여러개의 클래스 c 블럭을 기관에 할당할 수 있다
- 1000개의 주소가 필요하면 4개의 C를 줄 수 있다
supernet mask
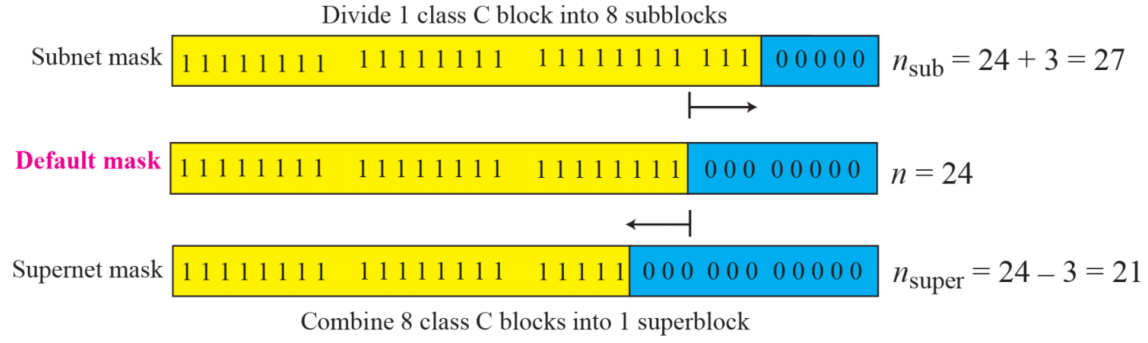
- subnet 마스크의 반대 개념이다
Classless addressing
classful에서 supernet과 subnet을 사용했지만, 주소 고갈 문제를 해결하지 못했다
그래서 classless 방법이 나왔다Two level addressing
classless에서 prefix는 network를 정의, suffix는 host를 정의한다
- prefix와 suffix부분으로 주소를 나눈다
- prefix: netid 역할을 한다
- suffix: hostid 역할을 한다
- 블록의 모든 주소는 prefix가 같고 각 주소는 다른 suffix를 지닌다

prefix의 길이 n
- 블럭의 사이즈에 의존한다
- 1,2...32까지 가능
suffix의 길이
- 32 - prefix길이
classless에서 prefix의 길이는 1~32가 가능하다
Slash notation
엥 그럼 prefix가 netid랑 같으면 classless랑 classful이랑 같은거 아님?아니다!!!
둘의 차이점
- classful
- netid의 길이는 클래스에 내재되어있다
- 주소의 클래스를 알면 netid의 길이를 알 수 있음
- 8, 16, 24
- 주소의 클래스를 알면 netid의 길이를 알 수 있음
- netid의 길이는 클래스에 내재되어있다
- classless
- prefix의 길이는 블럭 주소만 봐서 알 수가 없다
- 각 주소에 prefix의 길이를 포함해야한다
- n은 슬래시로 구분된 주소에 추가가 된다
- 이를
slash notation이라고 한다
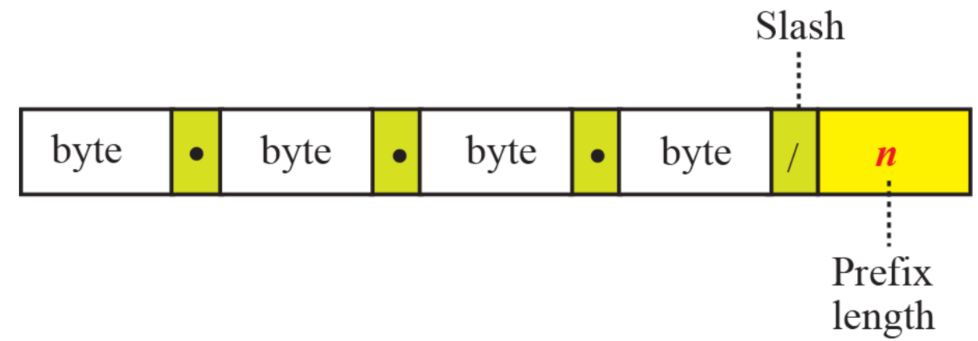
이 prefix의 길이를 보고 라우팅을 한다
classless에서, 블록을 정의하기 위해 블록의 주소 중 하나와 prefix 길이를 알아야 한다.
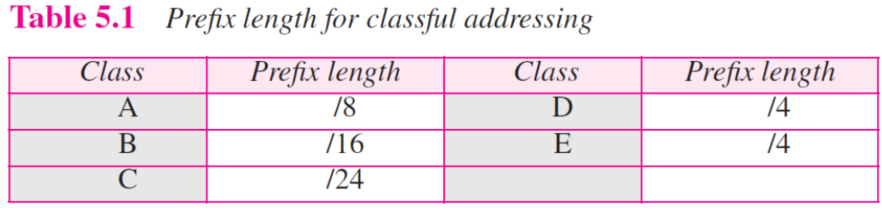
classful에 적용해보기
- classless에서 논의된 것들은 classful에 적용가능하다
- classful은 prefix가 8,16..으로 정의된 classless의 특이 케이스다
- 아래 표를 따르면 클래스 블록으로 쉽게 변경된다
Special addresses
몇몇 주소는 특별한 용도때문에 존재한다Special blocks
몇 블럭은 특별한 용도때문에 존재한다All zeros address
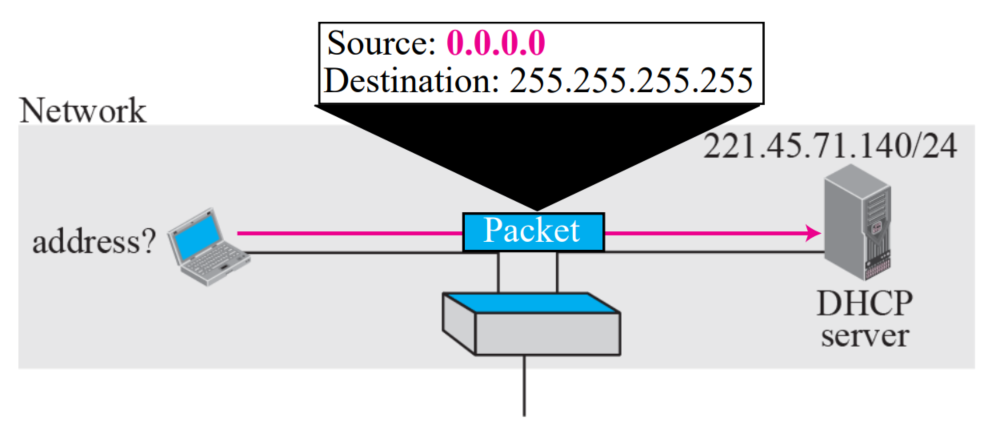
- 자신의 IPv4 주소를 모를 때, 자신의 주소를 알기위해 이 주소를 사용한다
- 0.0.0.0
All one address: limited broadcast address
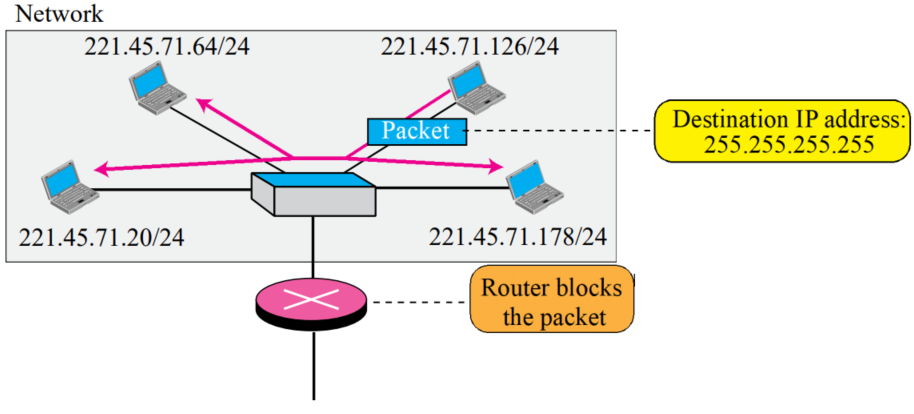
- 현재 네트워크에 broadcast를 위해 존재한다
- 255.255.255.255
- 라우터는 broadcast를 로컬에만 연결하기 위해 같은 주소를 가진 패킷을 차단한다
- 즉 자신의 네트워크안에서만 브로드캐스팅이 되게 한다
Loopback address
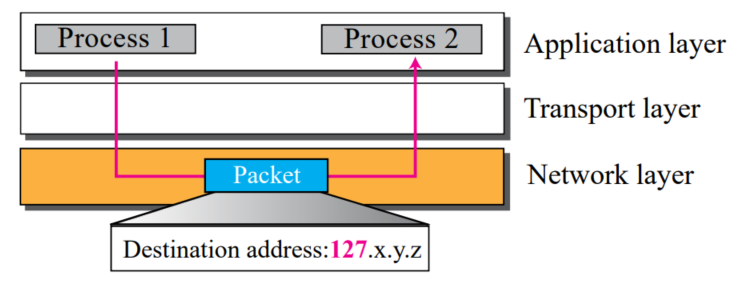
- 하나의 pc 내부에서 test를 위해 사용한다
- 127.x.y.z
- 이 주소를 사용하면, 패킷은 해당 pc를 벗어나지 않는다
private address

- 개인적인 사용을 위해 존재한다
- 주소를 별도로 사용하거나, 네트워크 주소 변환 기술과 관련된다
- 공유기에 많이 사용됨
Directed broadcast address
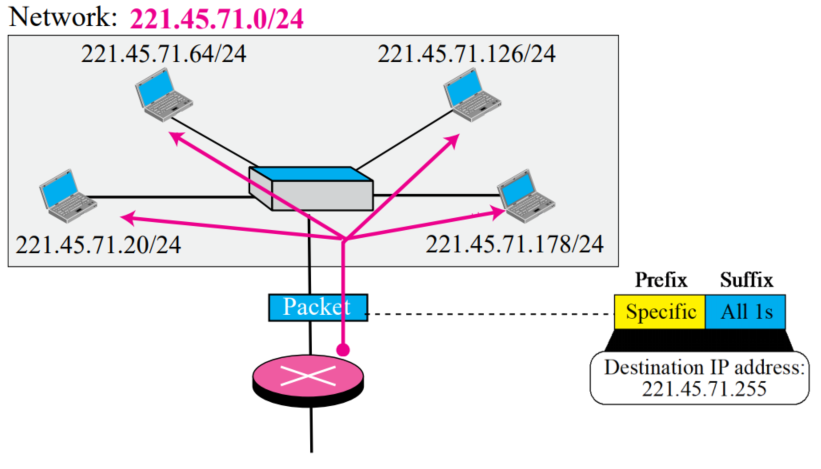
- 라우터가 특정 네트워크의 모든 호스트에 패킷을 보내는데 사용됨
- 특정 prefix에서 suffix를 모두 1로 설정
- ex) 221.45.71.255
- 특정 prefix에서 suffix를 모두 1로 설정
NAT
ISP가 소규모 기업, 가정에 주소 범위를 분배했다고 가정하자
이 후 이들이 더 큰 범위를 요구할 때, ISP의 전 후 주소는 이미 사용되어 질 수 있기 때문에 요청을 못 받아 들일 수도 있다
이러한 경우를 돕는 기술이 NAT이다private 주소를 public 주소로 변환하는 기술
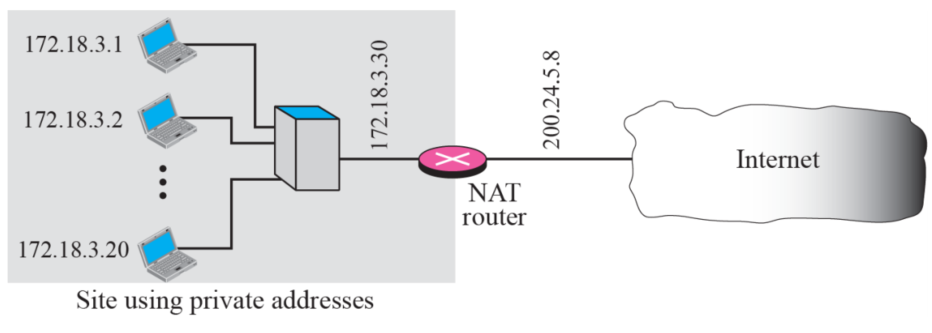
- private 네트워크는 private 주소를 사용한다
- public 네트워크에 연결된 라우터는 하나의 private 주소와 하나의 public 주소를 사용한다
- private 주소는 나머지 인터넷에서 transparent하다
- 즉 다른 친구들은 모른다
- 다른 인터넷에선 NAT 라우터만 볼 수 있다
Address resolution
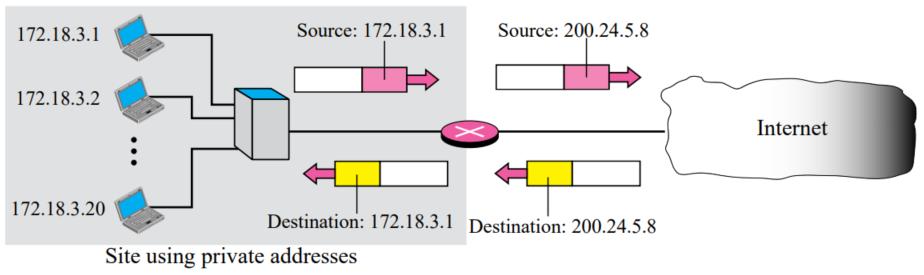
- 모든 송신 패킷은 NAT 라우터를 통해, source주소를 public NAT 주소로 바꾼다
- 모든 수신 패킷은 NAT 라우터를 통과한다
- 이 때, destination 주소(NAT 라우터 public 주소)를 private 주소로 바꾼다
어떻게 주소를 변환하지??
- NAT 라우터는 인터넷에서 들어오는 패킷의 대상 주소를 어떻게 알 수 있나??
- 각각 하나의 특정 호스트에 속하는 수십 개 또는 수백 개의 개인 IP 주소가 있을 수 있다
NAT라우터가 translation table을 통해 문제를 해결한다
1개의 IP 주소 사용 Translation
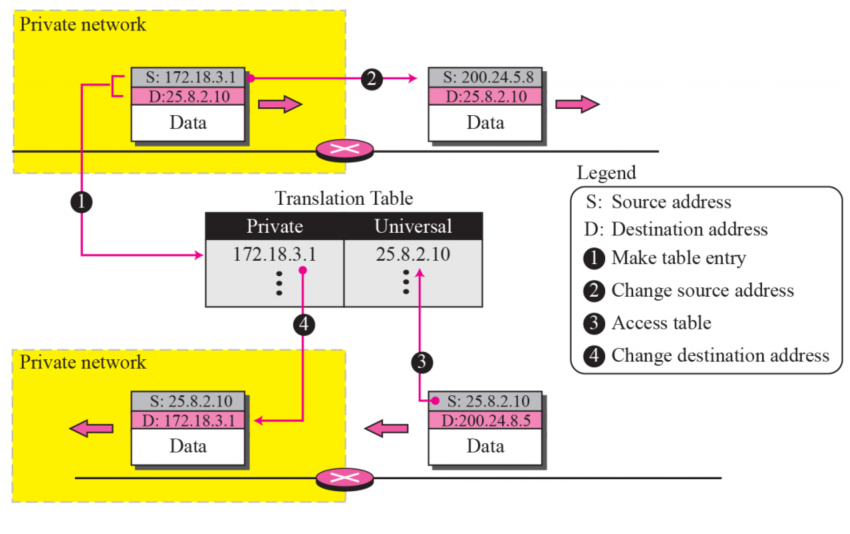
- 테이블에는 private 주소와 universal 주소(패킷의 destination 주소)만 존재
- 라우터는 송신 패킷의 source 주소를 변활할 때, 어디로 가는 지도 기록한다
- 패킷의 destination에서 응답이 오면 라우터는 패킷의 외부 주소를 활용해 패킷의 private 주소를 찾는다
IP 주소 Port 주소 둘다 사용
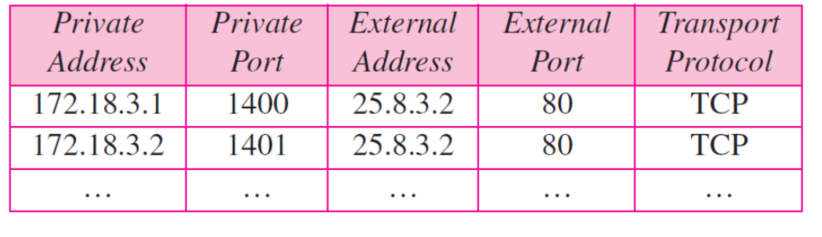
- 외부 프로그램과 private 네트워크 호스트 사이 다대다 관계를 위해서 더 많은 정보가 table에 필요하다
- table이 source, destination의 포트주소와 전송 프로토콜을 포함함으로써 정확해진다

정리