[논문 리뷰] Pix2Struct: Screenshot Parsing as Pretraining for Visual Language Understanding (ICML 2023)
Paper-review
Pix2Struct: Screenshot Parsing as Pretraining for Visual Language...
https://github.com/google-research/pix2struct
transformers/src/transformers/models/pix2struct at main · huggingface/transformers
Pix2Struct: Screenshot Parsing as Pretraining for Visual Language...
Abstract
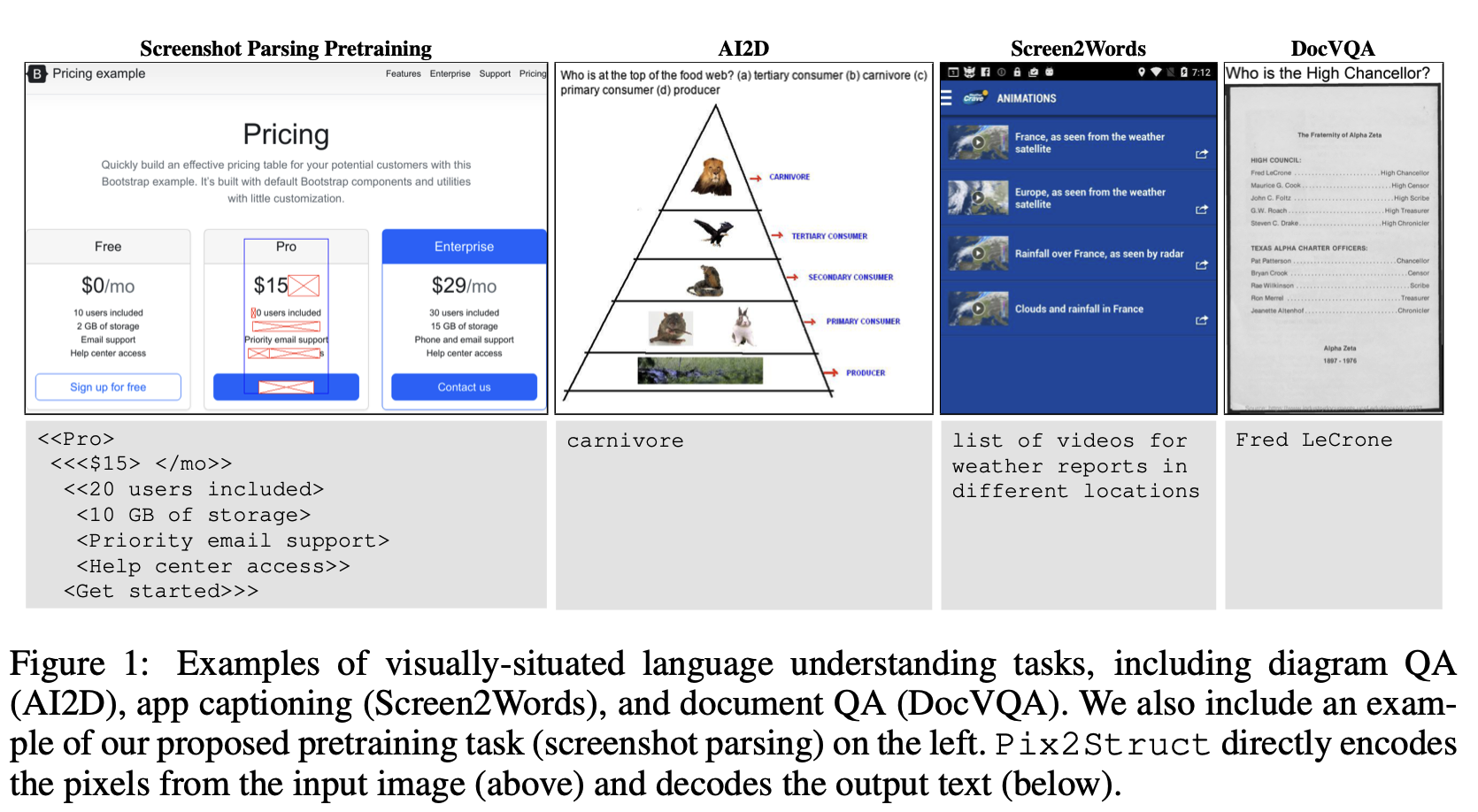
- Visually-situated 언어는 어디에서든 사용될 수 있다. 그 source가 diagram을 가진 textbooks부터 image와 table을 가진 web pages, 그리고 button과 형식을 가진 mobile app까지!
- 그런 다양함 때문에, 이전 연구들은 domain에 특정하고 data, model 구조, 목적 사이의 제한된 sharing 밖에 없었다.
- Pix2Struct : pretrained image-to-text model, 오직 visual language understanding에만 사용되고, visually-situated language를 포함하는 tasks에 fintuned 될 수 있다.
- web page의 parse masked screenshots을 학습해 pretrained되고, 이를 단순화된 HTML을 반영한다.
- Web에는 풍부한 visual elements들이 있고 html 구조로 반영되고 쉽다, 이는 pretraining data를 많이 주고, 다양한 downstream task에도 적합하다.
- 직관적으로, 이런 목적인 일반적인 pretraining signals (OCR, LM, image, captioning)들을 포함한다.
- 고유한 pretraining 전략에 더해, 다양한 해상도의 input representation을 도입하고 더 유연한 language + vision inputs의 통합을 보여주고, 질문 같은 language prompts가 input image 상단에 render된다.
- 처음으로, 우리는 단일 pretrained model이 4개의 domain (documents, illustrations, user interfaces, natural images)에서 9개 중 6개에 SOTA 결과를 달성함을 보여준다.
1 Introduction
- Language와 Vision 사이의 상호 작용에 대한 연구는 전통적으로 image와 text가 다른 채널로 구분될 수 있는 task에 집중해 왔다.
- VQA, image captioning 같은거
- 하지만, visually-situated language는 더 퍼져있는 방식이고, 이러한 modality가 서로 섞이고 상호작용 한다.

-
예를 들면, documents, tables, infographics, UIs 들은 전체적으로 사용되게 의도되었고, 글자와 이미지 사이의 명확한 경계가 없다.
-
이러한 정보의 포괄적 이해는 단어를 이해하고, 언어를 이해하고, 다양한 visual context와 협력하는 다양한 skill들이 필요하다.
-
visually-situated language 이해에 대한 이전의 연구는 산재되어 있다.
- 주 초점이 전형적으로 가능한 inputs과 tools에 대한 task-specific한 복잡한 조합 뿐이었다.
- document-understanding models은 외부 OCR systems
- UI-understanding models은 platform-specific structural metadata
- diagram-understanding models은 diagram parses.
- 주 초점이 전형적으로 가능한 inputs과 tools에 대한 task-specific한 복잡한 조합 뿐이었다.
-
Domain-specific engineering은 고해상도 환경 (e.g. 문서)에서는 효과적일 수 있다. → 풍부한 도구와 데이터가 있다면.
-
하지만, 이러한 pipelined models은 underlying data, model, architectures, objectives across domains의 공유가 부족하고, 그들의 일반적인 applicability를 제한한다.
-
또한, OCR 같은 외부 시스템에 의존하는 건 공학적 복잡도를 증가시키고, adaptability를 제한하고, 전반적인 계산 cost를 증가 시킨다.
-
최근의 연구 중 images로부터 직접 OCR-Free, end-to-end document 이해가 시도되었다 → task-specific한 engineering을 줄이고 pretraining 중 OCR outputs을 decode 하도록 학습해 inferece 중 외부 요소의 의존도를 낮추고자 했다. ⇒ 훨씬 일반적인 모델로의 진보.
-
하지만, 표면적 레벨의 text에만 집중하는건 unsupervised data에서 변환되는 knowledge의 depth를 제한한다. ⇒ Pixel-only model의 효과적인 사용은 Open challenge이다.
-
Pix2Struct를 제안. pretrained model → 순수히 pixel-level의 inputs의 단순함 + 다양하고 풍부한 web data를 사용한 self-supervised pretraining로 제공되는 generaility와 scalability와 조합
-
특히, screenshot parsing objective를 제안 → web page의 masked input에서 HTML 기반 parse 예측을 요구.
-
HTML이 text, images, layouts에 대한 clean, vital signals을 제공하고, masked inputs이 그들의 co-occurrence에 대한 joint reasoning을 유도함.
-
web에서 발견되는 다양하고 복잡한 textual + visaul elements 덕분에, Pix2Struct는 web page에 대한 풍부한 representation을 배우고, 다양한 downstream visual language understanding task에 효과적으로 전환될 수 있음을 보였다.
-
이러한 transfer를 가능하게 하는 주요 재료는 인간 독자들의 읽도록 의도된 것처럼 inputs을 시각적이고 전체적으로 처리하도록 한다.
-
ViT에 다양한 해상도의 inputs을 넣는데, 이는 문서, 그림, UI마다 매우 다양할 수 있는 원본의 가로세로비를 왜곡하는 것을 방지한다.
-
finetuing 중, 우리는 다른 inputs (VQA의 질문, UI tasks의 bounding box)를 task의 image imput으로 render 한다.
-
그 결과로, 모든 다른 inputs을 single modality로 통합하고, 이전 work의 modality combination 문제를 단순화 한다.
-
282M, 1.3B parameters에서 학습. ⇒ 각각 Pix2Struct-Base / Pix2Struct-Large.
-
C4 corpus에서 web pages 80M screenshots.
-
4 domain과 9 tasks에서 실험 ⇒ 우리 모델이 Donut (기존 pipeline이 없는 SOTA)보다 훨씬 나았다.
-
domain-specific한 pipeline을 가진 baseline과 비교했을 땐, 고해상도 (문서, 자연 이미지)에서는 SOTA에 밀렸지만, low-resource domain (illustration, UI)에서는 상당한 진전을 이루었다.
-
우리의 연구가 이러한 general-purpose methods 연구를 진흥시키면 좋겠고, language + vision의 파편화 되어 있는 결합에 새로운 적용을 가능하게 하면 좋겠다.
우리의 기여 요약
- general-purpose visually-situated language understanding을 도입, 다양한 task로 이루어졌지만, 일반적인 어려움을 가지고 있다.
- Web page의 HTML source objective에 기반한 screenshot parsing pretraining을 제안.
- 우리의 objective가 더 효과적이고, 이전 시도보다 elegant한 pixel-to-text design을 가능하게 함.
- ViT에 다양한 해상도의 input representation을 도입했고, 새로운 fine-tuning 전략 (language와 vision inputs을 직접적으로 통합) input image 위에 language prompts를 직접적으로 rendering 한다.
2 Method
2.1 Background
-
이전 연구는 주로 document와 natural image에 집중해 왔다.
- 문서 : Donut, Dessurt가 표면적 level의 feature에 기반해 pretrained했다.
- natural img : GIT2, PaLI가 대규모 image captioning data를 naturl images 데이터셋으로 잘 tranfer했다.
-
우리의 목표는 여러 task, domain에 사용될 수 있는 단일한 pretrained model을 만드는 것이다.
-
우리 model의 input은 raw pixel only의 image이고, output은 token sequence 형태의 text이다 (Donut과 유사)
-
목표는 visual판 T5를 만드는 것인데, 단순한 inputs과 outputs의 일반성이 대규모 unsupervised source의 data의 힘과 결합하는 것이다.
-
finetuning 중, downstream task에 적용하는 복잡함은 오직 data preprocessing에 달려있다.
-
visual context 없이도 text를 위한 pixel-only language modeling은 오직 최근에만 시도되었다.
- 아마 여러가지 어려운 sub-problem을 해결해야 하기 때문에.
- 높은 신뢰도로 읽는 동시에 풍부한 high-level representations을 만드는 능력은 어려운 최적화 문제이다.
- text-heavy한 inputs (긴 문서 같이)을 encoding 하는건 다양한 가로세로비의 고해상도 이미지를 처리하는 것을 의미하기 때문이다.
- 아마 여러가지 어려운 sub-problem을 해결해야 하기 때문에.
-
SOTA 문서 이해 model은 (LayoutLMv3)은 (noisy 할 수도 있는) 저해상도 image의 OCR outputs을 조합해서 만든다.
-
우리는 OCR에 의존하는게 더 일반적인 목적의 representation으로 나아가는 것을 막는다고 주장한다.
-
우리는 Pix2Struct의 다양한 구성 요소들이 이러한 문제들을 해결했음을 보인다.
- 2.2 : transformer가 다양한 가로세로비와 화질을 다루기 위해 했던 수정
- 2.3 : 우리가 제안하는 screenshot parsing objective
- 2.4 : Curriculum learning이 더 robust한 trasfer learning을 가능하게 하는가
- 2.5 : 어떻게 Pix2Struct가 textual + visual inputs을 같은 space에서 처리하는가 ⇒ finetuning 중 text inputs을 image 위에 rendering 한다.
참고 - Donut
- Clova!

- 전반적인 pipeline
- (b) : text detection, 위치 뽑아내기
- (c) : 각각의 box recognizer로 들어간다.
- (d) : 인식된 글자와 위치가 들어가서 최종적인 구조를 만듦.

- End-to-End model로 학습시켰다.
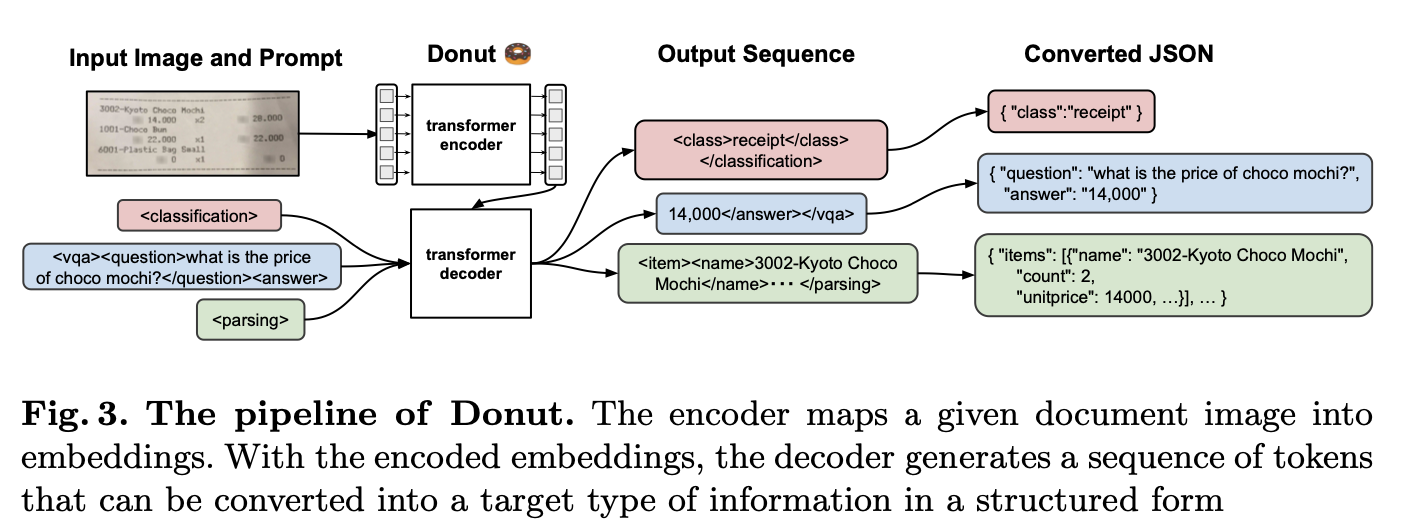
- Encoder : CNN, Transformer 다 가능. 연구에서는 Swin Transformer를 사용.
- Decoder : BART를 사용.
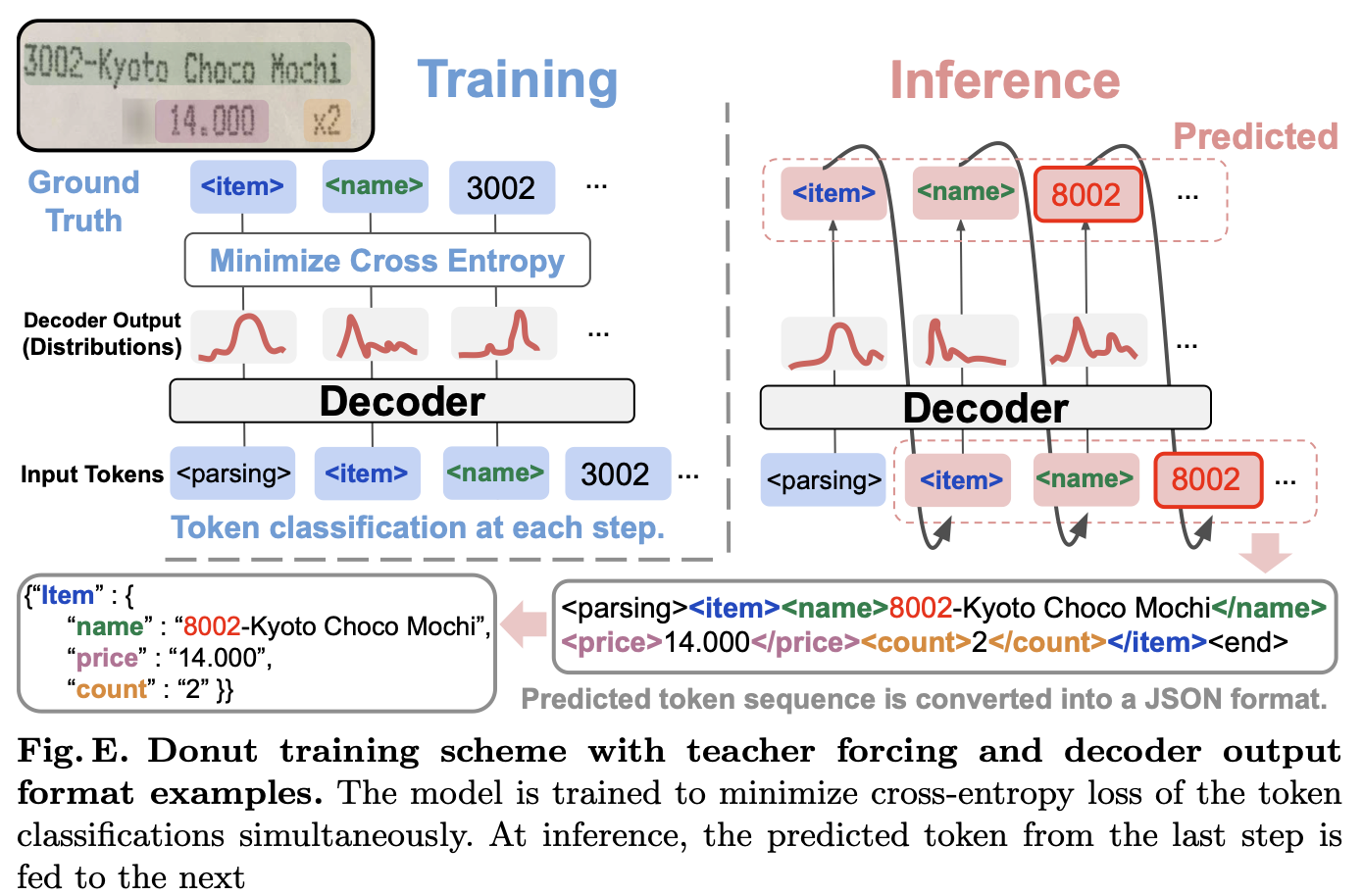
- Model input : 이전 timestep의 output이 아니라 ground truth를 input으로 사용했다.(teacher-forcing strategy)
BART

- T5는 그냥 vanilla Transformer네?
2.2 Architecture
-
image-encoder-text-decoder는 ViT.
-
model 구조는 매우 일반적. 하지만 작지만 매우 영향이 큰 변화를 도입함. → visually-situated language의 various forms에 더 robust하게 만듦.
-
fixed-size patches를 추출하기 전에, 일반 ViT는 사전 정의된 해상도로 scale을 바꾸는데, 이게 의도하지 않은 결과 두 개를 만든다.
- image를 rescaling 하면 원래 가로세로비가 깨진다.
a. 이는 문서, mobile UIs, figures에서 매우 변화하기 쉽다. - 이러한 models을 더 높은 해상도의 downstream task로 변환하는 것은 간단하지 않다.
b. model이 pretraining 동안 오직 하나의 특정한 해상도만 봤기 때문에.
- image를 rescaling 하면 원래 가로세로비가 깨진다.
-
대신, 우리는 input image를 항상 up 또는 down scale해서 주어진 sequence length에 맞는 최대의 patches를 뽑아낼 수 있게 했다.

- Appendix A. 이전 방식은 input image를 고정된 해상도로 rescale 했는데, 문서나 webpage에서 엄격한 가로세로비의 왜곡을 가져온다.
- model이 다양한 해상도를 모호하지 않게 다루기 위해서, input patches를 위해 2차원 절대값 positional embedding을 사용한다.
- 표준 ViT에서 이러한 변화와 함께, robustness 관점에서 두 가지 이점이 있다 :
- 우리가 실험했던 domain에서 일반적이었던 극단적인 가로세로비
- sequence length와 resolution의 on-the-fly (즉석) 변화
2.3 Pretraining
- Pix2Struct pretraining의 목적은 input image의 underlying 구조를 표현하는 것이다.
- 종국에는, web corpus에서 input images와 target text 쌍의 self-supervised pairs를 만드는 것이다.
- pretraining corpus 안의 각각의 web page에 대해, screenshot과 HTML source를 모으는 것부터 시작한다.
Screenshot parsing inputs & outputs
-
screenshot과 HTML은 pretraining 동안 rich하고 dencse한 learning signal을 확실히 만들 수 있게 수정된다.
- 이러한 수정본은 page의 semantics을 보존하는 것과 실용적인 decoder sequence 길이를 요구하는 것 사이의 reasonable한 trade-off이다.
-
HTML DOM tree를 다음으로 농축 시킨다.
- visible elements를 가지거나 그의 자손들의 node만 남기고
- node가 visible elements를 포함하지 않고 오직 하나의 child만 가지고 있으면, chained nesting을 제거하기 위해 singleton child를 아무 grandchildren으로 바꾼다.
-
각각의 node에서, filename과 대체 text로 표현되는 text와 image에 대한 정보만을 남긴다.
-
더 많은 정보가 보존될 수도 있는지에 대한 연구는 미래에 맞긴다. (element tag, bounding boxex, title, URL 등등)
-
decoder sequence length는 linearized 될 때 predefined된 sequence length에 fit 하는 largest subtree를 찾음으로서 더 감소한다.
-
bounding box가 가리키는 chose subtree로 cover 되는 영역 또한 screenshot에 그려진다.
-
더 나은 context modeling을 위해, BART-like의 learning signal을 도입했다 ⇒ 전체 subtree를 decoding 할 때 50%의 text를 masking 했다.
- 이 masked 영역은 선택된 subtree의 text에서 랜덤하게 sample된 영역이고, crossed-out의 불투명한 boxes를 쳤다.
Comparison to existing pretraining strategies
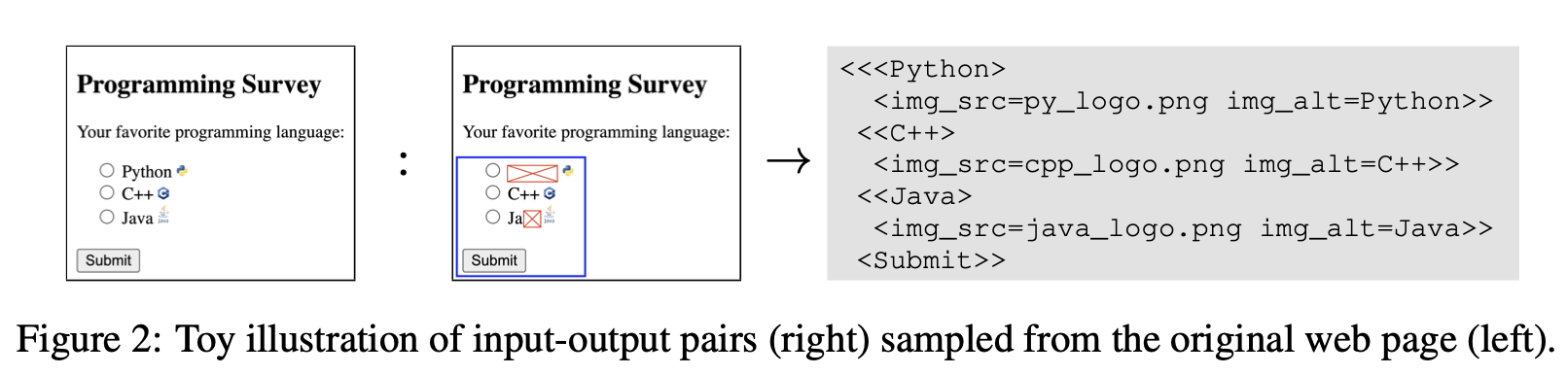
- 우리가 제안한 screenshot parsing은 여러 잘 알려진 pretraining 전략들을 연상케 하는 signals을 틈 없이 연결했다 :
- parse의 unmasked 부분을 복원하는건 언어를 이해하는데 사전에 필요한 기술인 OCR과 유사하다.
- OCR preatraining은 Donut에서 제안되었는데, synthetic renderings 또는 예측된 OCR outputs을 사용했다.
- Figure 2에서, <C++>을 예측하는 것은 이러한 learning signal을 실증한다.
- parse에서 masked parts를 복원하는 것은 masked language modeling(BERT)에 훨씬 가깝다.
- 주요한 차이점은, visual context가 종종 더 날카로운 예측을 위한 추가적인 힌트를 제공한다는 점이다.
- Figure 2에서, 을 예측하는 것은 이러한 learning signal을 실증한다.
- image에서 대체 이미지를 복원하는 것은 image captioning을 위해 일반적으로 사용되는 전략이다.
- 주요한 차이점은, 이 모델은 web pages를 추가적인 context로 사용하는 것이 허락된다는 점이다.
- Figure 2에서, img_alt=C++ 을 예측하는 것은 이러한 learning signal을 실증한다.
Appendix E.

2.4 Warming Up With a Reading Curriculum
- 우리는 screenshot parsing task에 대해 Pix2Struct를 직접 pretrain 할 수 있지만, naive하게 이걸 하는건 instable하고 slow learning이 된다.
- 그러나, 만약 우리가 모델을 처음에는 쉽게 읽는 법을 배우는 짧고 강렬한 “warmup” 단계에 넣는다면, 강력한 curriculum learning의 효과를 볼 수 있다.
- pretraining이 더 stable 하고 더 빨리 수렴한다.
- 더 나은 finetuning 성능을 보인다. (Section 5에서 논의할 것)

- 특히, 우리는 흰색 배경에 랜덤한 색과 폰트의 text snippets의 이미지를 만든다.
- 모델은 쉽게 original text를 decode할 수 있다.
- 이런 방식은 Dessurt model에서도 사용되었고, Donut의 pretraining의 단순화 된 version으로 볼 수도 있다.
2.5 Finetuning
- Pix2Struct를 finetuning하는 건 단순하고, downstream data를 모호하지 않게 image inputs과 text outputs이라는 task를 반영하도록 preprocessing 하는 문제에 많은 영향을 받는다. ⇒ T5가 text-based tasks에 사용되는 방식과 유사하다.
-
이 Section에서, tasks에 대한 preprocessing 전략이 Table 1에 정리되어 있다.
- 이러한 preprocessing의 결과는 Figure 1이다.
-
Captioning은 가장 명확하다, 왜냐하면 input image와 output text가 직접적으로 사용될 수 있기 때문에.
-
Caption의 목표가 특정한 bounding box를 그리는 거라면 (Widget Captioning처럼), 우리는 target bounding box를 image 그 자체에 그려 넣는다.
-
VQA (OCR-VQA, ChartQA 등)에서, multimodal model들이 question을 위한 특별한 text channel을 일반적으로 유지했지만, 우리는 원본 이미지 상단에 직접적으로 질문을 render 했다.
- Pix2Struct는 visual modality로 question과 image를 함께 읽는다.
-
이러한 전략은 단순히 모든 input을 finetuining 중에 concat 하는 것에서 배운 것
- GPT에서 처음 제안
- NLP에서 기본처럼 사용되어 옴
-
직관적으로, 이러한 전략은 효과적인데, Pix2Struct가 input image의 다양한 부분 사이의 넓은 범위의 상호작용에 민감하게 pretrained 되었기 때문이다.
-
여러 선택지가 있는 경우에 (AI2D처럼), choices들도 이미지 상단에 넣었다.
-
가장 복잡한 시나리오는 RefExp인데, 자안여 설명이 언급하고 있을 UI 요소 중에서 선택하는 것.
-
각각의 후보에 대해, input image가 bounding box와 referring expression을 가지고 있는 training instance를 만들었고, decoding target은 “true” 또는 “false”이다.
-
우리는 training 동안 긍정적인 candidate 당 5개의 negative candidate를 만들었다.
-
Inference 동안, model이 만든 “true” score가 가장 높은 candidate를 선택했다.
3 Experimental Setup
3.1 Benchmarks
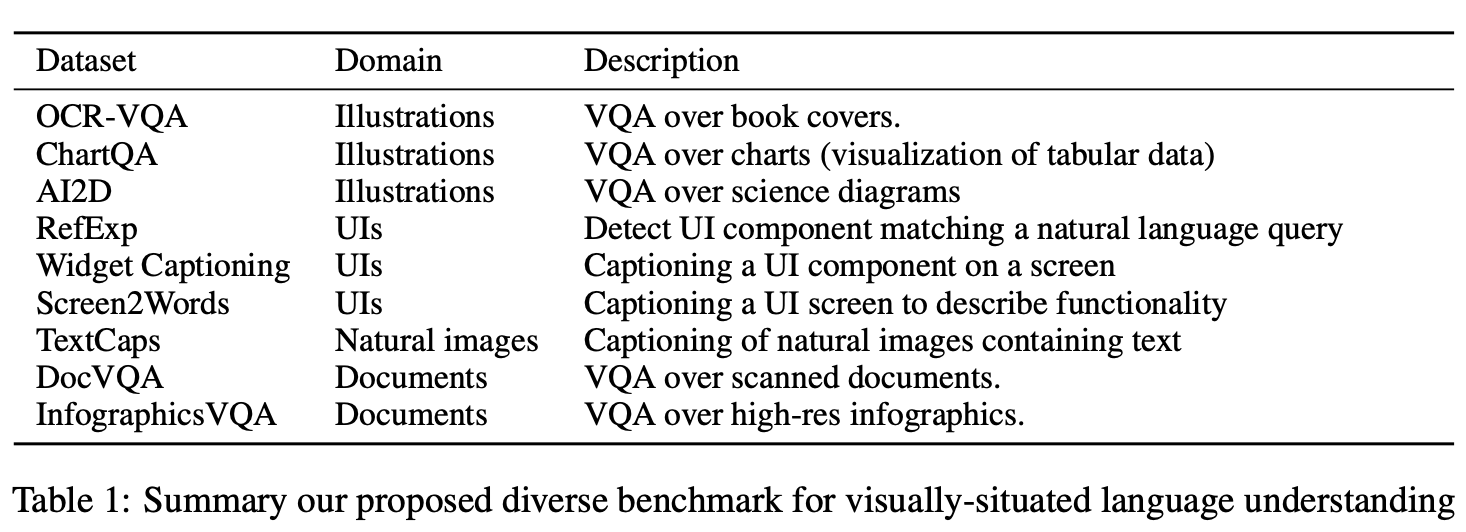
- Visually-situated language understanding의 여러 도메인 통합
- illustrations
- user interfaces
- natural images
- documents
- task-format 뿐만 아니라 다양한 domain에서 최적화 했다.
- Evaluation metrics도 각각에서 원본에 지정된 방식을 사용
3.2 Implementation and Baseline
Pretraining
- 두 가지 모델
Parameters transformer layers a hidden size steps batch size GPU base 282M 12 768 270K 3072 64 GCP TPUs large 1.3B 18 1536 170K 1024 128 GCP TPUS - 두 모델 모두 warmup stage를 거침
- BooksCorpus에서 만들어진 text
- 30K steps

Baselines
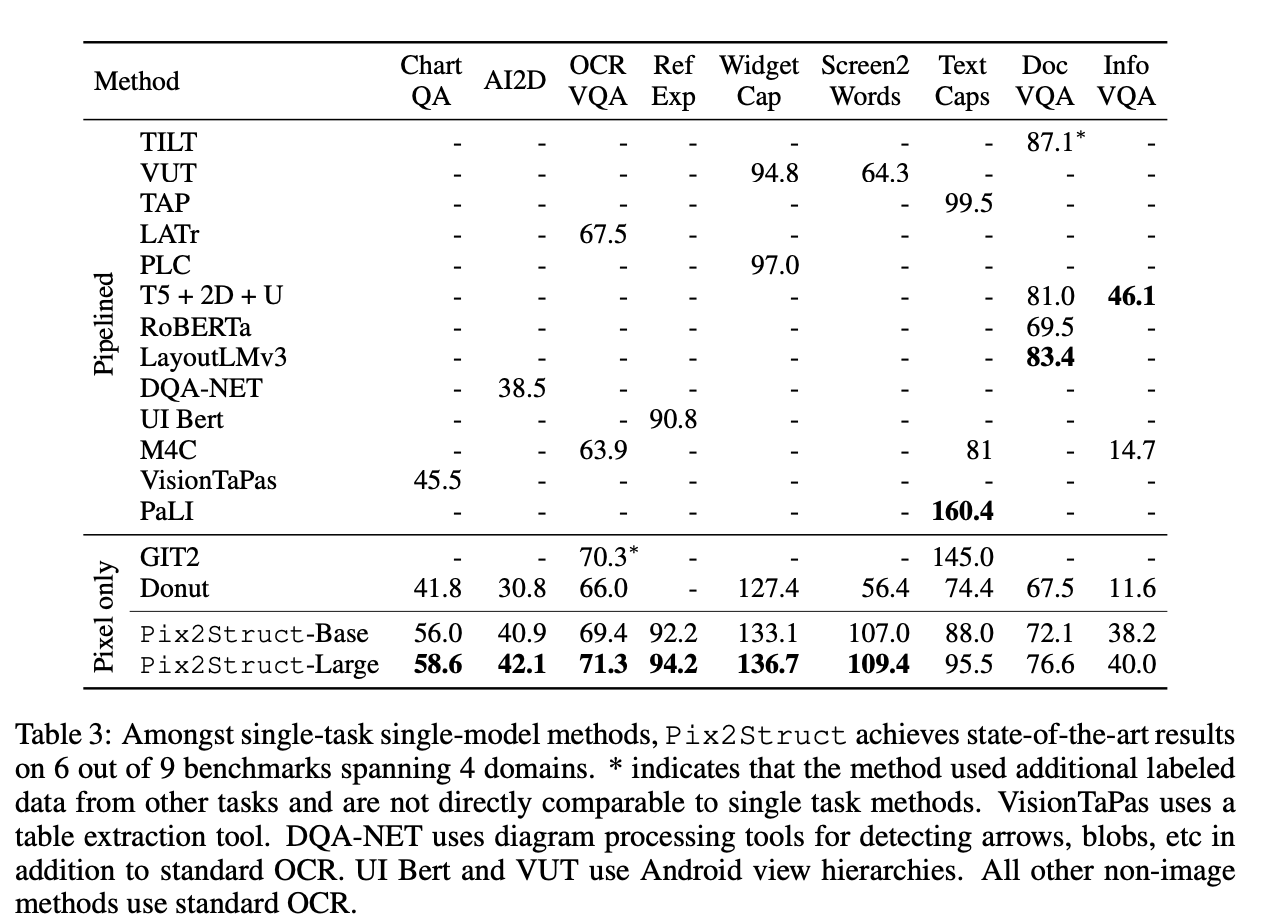
- 모든 task에 대해서 많은 수의 method를 baseline으로 확인함.
- 각각의 domain에서 SOTA와 비교.
- 많은 모델들이 ensemble, 다른 dataset에서 온 학습 데이터를 이용해 multi task, validation data를 training에 사용했다.
- 공정하고 쉬운 비교를 위해, standard split의 single-model과 single-task baseline에 집중했다.
- 여러 SOTA가 domain-specific inputs을 사용해서, 다른 domain에 비교하는게 어려웠다.
- Domain 사이의 강하고, 지속성 있는 visual baseline을 위해, 순수한 visual baseline이 사용 불가능한 경우 모든 경우에서 Donut을 finetuned해서 사용했다.
4 Results
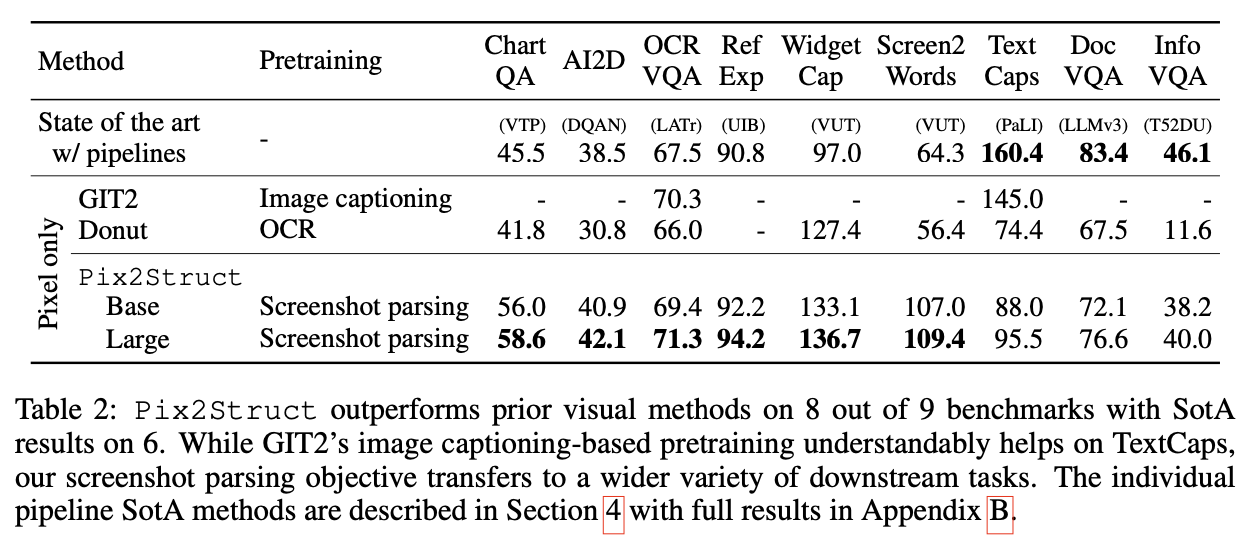
- 이전 연구와 Pix2Struct를 비교해 보겠다.
4.1 Illustrations
ChartQA
- VQA Data.
- VisionTaPas가 이전 SOTA ⇒ 큰 격차로 따돌렸다.
AI2D
- 기존 SOTA DQA-NET을 따돌림
OCR-VQA
- GIT2가 현재 SOTA.
- 12.9 image caption pairs로 학습
- 우리는 추가 데이터를 더 쓰지 않았음에도 1퍼센트 상회함.
4.2 UIs
RefExp
- UIBert가 SOTA
- Pix2Struct는 94% 정확도로 SOTA
Widget Captioning
- VUT가 SOTA
- Pix2Struct-Large가 97.0 → 136.7으로 SOTA 갱신
Screen2Words
- CIDE가 SOTA
- Pix2Struct-Large가 64.3 → 109.4
4.3 Natural Images
TextCaps
- GIT2, PaLI가 SOTA를 경신해 옴
- OCR based input 없이 finetuned 됐을 때 비교할 만한 성능을 보임.
- Pix2Struct의 Scale을 늘리면 나중에 도움이 될 듯.
4.4 Documents
DocVQA
- 이전 SOTA Docut
- DocVQA에서 9% 발전함.
InfographicVQA
-
ANLS 40 → Pix2Struct-Large
-
DocVQA, InfographicVQA에서 text-only baslines이 SOTA거나 근접하다.
- text가 많은 데이터에서 visual context가 더 적은 역할을 하고, 더 성숙한 pretrained text-based encoder가 더 좋은 성능을 낸 듯.
Common trends
- 전반적으로, 우리의 pretraining의 효율성이 강조되는 모든 분야에서 Donut을 상회하는 성능을 낸다.
- 4개의 Domain에서 9개 중 6개가 SOTA를 달성.
- base → large로 Scale을 키운 것은 모든 task에서 성능 향상.
- base가 large version에 비해 4.5배 많이 iteration 했음에도 불구하고.
- 앞으로도 Scale을 키우면 더 좋은 성능이 생기지 않을까?
5 Analysis
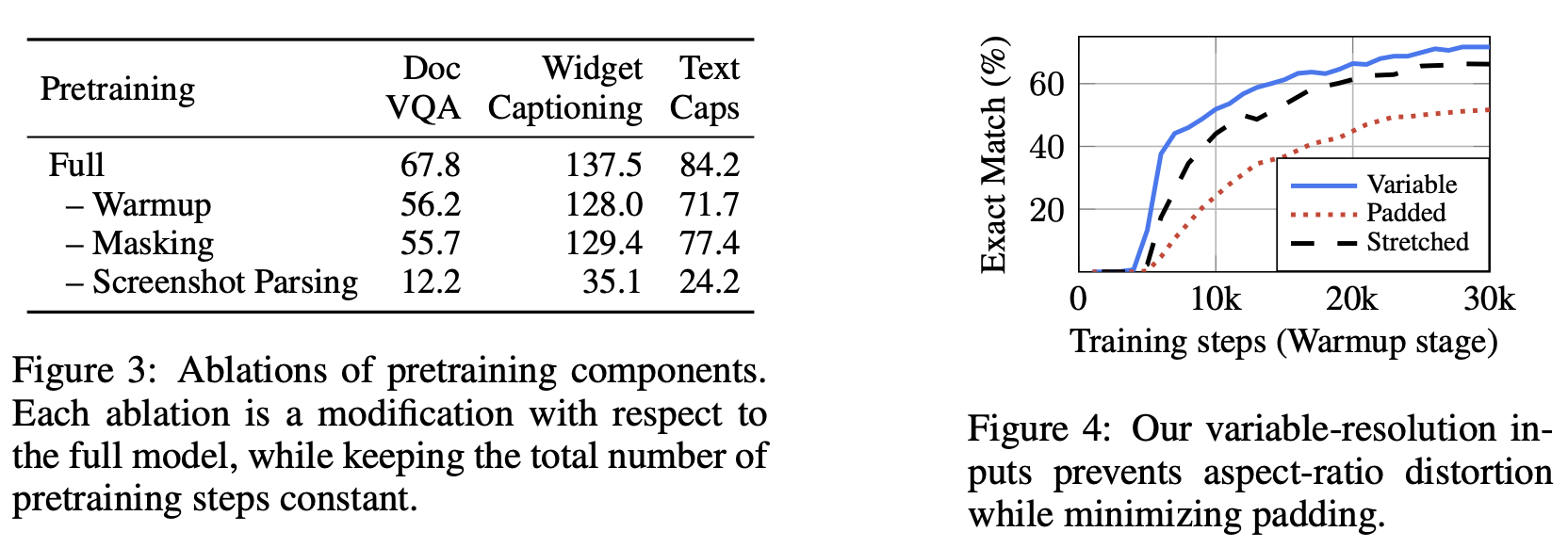
Ablating pretraining objectives
- 각각의 요소가 얼마나 영향을 미쳤는지 ablation
- Screenshot Parsing은 그 단계를 통째로 빼 버림. warmup stage를 100K 더 함
- 모든 부분이 중요하죠?
- 특히 screenshot parsing stage. ⇒ 이러면 그냥 linear text를 읽는거랑 같음.
- Warmup도 꽤 중요함.
- 많은 능력들을 필요로 하는 기술인 듯.
Ablating variable-resolution inputs
- 고정된 숫자의 patches로 바꾸는 방식 비교.
- warmup stage에서 수행됨
- Padded : aspect ratio를 유지하고, 큰 padding을 넣음 (해상도 손해)
- Strectched : 전형적인 ViT. padding은 없고 이미지를 왜곡함.
- Variable-resolution : 원본 비율도 유지하면서 budget도 최대화 하는 최고의 방법. ⇒ 더 효과적인 학습!
6 Discussion
Resolution
- Donut처럼, pretraining, finetuning 성능이 input 해상도에 큰 영향을 받는다.
- 높은 해상도는 pixel-only model에서 bottleneck으로 작용함.
- 그래서 OCR-based pipeline을 쓰는 이유기도 함.
- 하지만, Donut과 Pix2Struct에서 long range transformers의 발전이 pixel-only model의 희망을 보여줌.
The visual web
- General-purpose visual language understanding model의 첫 시도로, HTML source와 pretraining corpus, C4를 어떻게 사용할지에 집중했다.
- 하지만, web data는 더 풍부한 multimodal signals (video, interactions)을 포함한다.
- 우리는 미래의 general-purpose visual language understanding model이 더 나은 data 선별로 더 발전할 것이라 가정한다.
- 또한, text-based model처럼, web content의 해로움에 대해서도 생각해 봐야한다.
Generality
- 우리가 pixel-only model에 집중한 반면, OCR-pipeline 또는 metadata를 사용하는 것이 특정 domain에서는 좋고 심지어 필수적일 수도 있다.
- NLP에서, pretrained text based model의 scaling이 더 나은 model 구조와 Preprocessing 뿐만 아니라, 지금까지 너무 어렵다고 생각되어 온 새로운 일을 수행하는 능력까지 만들었다.
- General-purpose model이 visual language에서 더 넓은 application이 가능하리라 생각된다.
- 이러한 연구의 넓은 목적은 visually-situated language understanding의 pretraining을 text-base의 상대방과 data와 model scaling의 유사한 이점으로 향하는 길을 찾기 위한 단계이다.
7 Related Work
지금 이해가 안 되는 점
- 우리가 하고자 하는게 뭐야 그래서
- masked-image input : html output으로 학습 하는거지?
- text block이 따로 있는거지?
- 일단은 그런 듯. 근데 원본 코드에는 그냥 t5 뭐시기 호출하는게 끝임. hugging face 코드는 self-attention, cross-attention, mlp 세 개로 이루어진듯
- 그러면 text block 이 정확이 어떻게 생겨 먹은거야? ⇒ 이제 좀 이해된다. 걍 바닐라 transformer decoder네용. t5가 그 구조. self attention, cross, mlp 이 세개.
- C4 data에 html이 포함 됨? ⇒ URL을 기반으로 원본 HTML 검색
