처음으로 하는 논문 리뷰!
선택한 논문은 Attention Is All You Need이다.
현재 NLP분야에서 최고존엄인 BERT모델이 이 논문에서 제안한 Transformer 아키텍쳐의 Encoder를 바탕으로 하고 있다.
Abstract
Transformer는 RNN과 CNN을 사용하지 않고, Attention으로만 구성된 sequence 처리 모델이다. 번역 성능 측정 평가지표인 BLEU에서 적은 훈련 비용으로 좋은 점수를 기록했다.
Introduction
이 논문에서 제안하는 것은 Transformer이다. 이전의 모델인 RNN, LSTM, GRU같은 Recurrent model들은 순차적으로 계산되어 hidden states를 생성하기 때문에 병렬처리가 불가능하다는 근본적인 단점이 있다. Transformer는 Attention 메커니즘만을 활용하여 이 단점을 해결한다.
Model Architecture
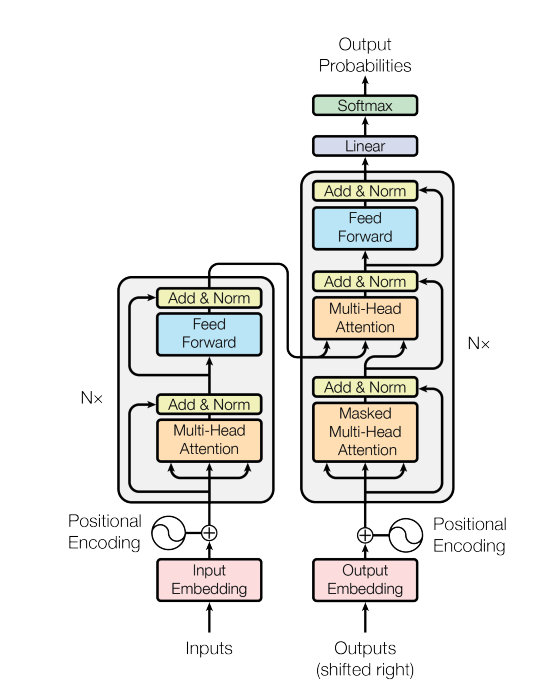
Transformer 모델은 다음과 같은 구조를 가지고 있다. Encoder와 Decoder는 모두 self-attention과 fully connected layer를 포함한다.
Encoder & Decoder
Encoder
- 6개의 동일한 레이어 스택으로 구성된다.(N=6)
- 스택마다 2개의 sub layer가 있는데, 첫 번째는 다중 Multi-Head Attention이고, 두 번째는 Feed Forward 네트워크이다.
- 이 두개의 sub layer에 대해 residual connection을 사용하고, layer normalization을 진행한다.
- 각 sub layer의 출력은 LayerNorm(x + Sublayer(x))
- residual connection을 용이하게 하기 위해 모든 레이어의 차원은 512차원으로 임베딩한다.
Decoder
- Encoder와 동일한 구조에 하나의 layer가 추가되었다. 이는 인코더 스택의 output에 대해 Multi-Head Attention을 수행하는 layer이다.
- Decoder는 순차적으로 결과를 만든다. 만약 i번째 position인 단어를 predict한다고 하면, i보다 전에 있는 output에만 의존하여 predict한다. 이를 위해 masking을 이용한다.
Attention
Attention에 대한 설명은 이곳을 참고
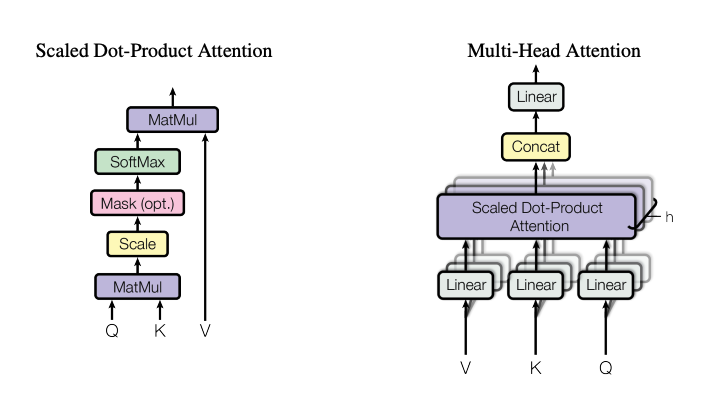
Scaled Dot-Product Attention
Scaled Dot-Product Attention의 input은 차원의 query, key와 차원의 value로 구성되어 있다. query와 모든 key를 내적하고, 각각 로 나눈 뒤, softmax를 취해 value에 대한 weight를 얻는다.
실제로는 모든 query들이 matrix Q로, key와 value역시 matrix K, V로 Packed되어 한번에 계산이 된다.
output이 도출되는 식은 다음과 같다.
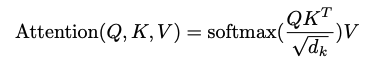
Multi-Head Attention
Multi-Head Attention은 단일 어텐션을 수행하는 대신, , , 차원에 대해 학습된 queries, keys, values Linear를 h번 (병렬적으로) 계산하는 것이다. 각각의 output에 대해 concat한 뒤 Linear projection하여 최종 결과 vector를 얻는다.

Applications of Attention in our Model
Attention을 적용하는 방법은 sub layer에 속해있는 Attention마다 다르다.
-
encoder-decoder attention layer (Decoder에 위치)
query : decoder내의 이전 layer의 output
key, value : encoder의 최종 output
input sequence의 모든 position 접근 가능 -
self-attention layer (Encoder에 위치)
query, key, value 모두 이전 encoder layer의 output
input sequence의 모든 position 접근 가능 -
self-attention layer (Decoder에 위치)
query, key, value 모두 이전 decoder layer의 output
input sequence의 모든 position 접근 불가
-> 해당 position이전의 position까지만 접근 가능하다. decoder의 auto-regressive 성질을 유지하기 위해 접근 불가한 단어의 위치에 대해 -inf에 가까운 매우 작은 수를 더해주고, softmax를 취하여 값이 0에 수렴하도록 하는 masking 방식을 이용한다.
Positional Encoding
Transformer에는 단어의 위치를 알려주는 Positional Encoding layer가 있다. 이를 encoder와 decoder 하단에 배치해준다. 이 역시 embedding과 동일한 차원을 가지며 이로써 두 벡터가 더해질 수 있다.
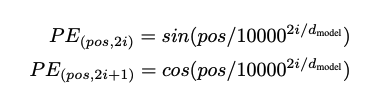
논문에서는 sin과 cosine함수를 적용하여 positional encoding을 하였는데, 두 방식이 거의 동일한 결과를 냈다. 결론적으로는 sinusoidal version을 선택하였는데, 이는 모델이 훈련되는 동안 마주친 길이보다 더 긴 sequence에 대해서도 처리할 수 있기 때문이다.
Why Self-Attention
다른 기법들과 Self-Attention을 비교한 결과,
- layer당 총 계산 복잡도가 줄어든다.
NLP에서는 input되는 sequence의 길이 n은 보통 embedding 차원(d)보다 작은 경우가 대부분이다. - 병렬처리가 가능한 계산이 늘어난다.
- 보다 더 긴 장거리 학습의 가능하다.

side benefit으로, 어텐션을 이용할 경우 구해진 attention distribution이 시각화(!)가 가능하여 사용하는 모델의 설명력을 높여준다.
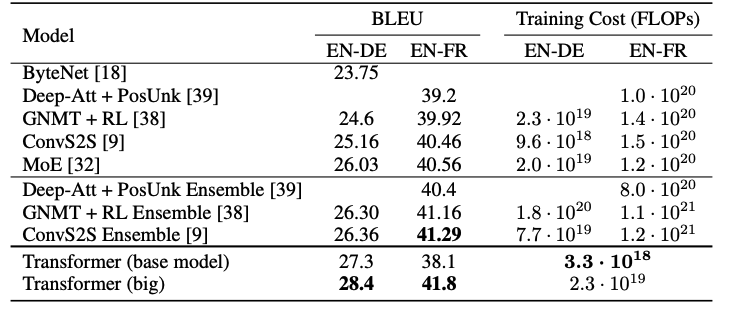
Train & Result
'English-to-German and English-to-French newstest2014'에서 SOTA를 달성하였다.
NVNIA P100 GPU 8대로 기본 모델은 12시간, big 모델은 3.5일을 학습시켰다.
Reference
논문 리뷰는 처음이라 다른 논문 리뷰를 참고해가며 조금 감을 익혔다.
https://velog.io/@changdaeoh/Transformer-%EB%85%BC%EB%AC%B8%EB%A6%AC%EB%B7%B0
