
이전 포스트에 이어서 MySQL Query문에 대해 알아보자.
🏹 MySQL Query
Table 생성하기
Database를 생성한 후 Table을 생성한다.
DROP tables table01;
CREATE TABLE table01 (
id INT NOT NULL AUTO_INCREMENT,
name VARCHAR(10),
dept VARCHAR(10),
salary INT,
PRIMARY KEY (`id`));
INSERT into table01 values(null, '호랑이1', '경영', 100);
INSERT into table01 values(null, '호랑이2', '개발', 150);
INSERT into table01 values(null, '호랑이3', '영업', 300);
INSERT into table01 values(null, '호랑이4', '개발', 700);
INSERT into table01 values(null, '호랑이5', '영업', 500);
INSERT into table01 values(null, '호랑이6', '경영', 500);BETWEEN
주어진 값 사이에 존제하는 데이터를 가져온다.
아래 두 쿼리문은 동일한 의미의 쿼리문이다.
SELECT *
FROM table01
WHERE salary BETWEEN 200 and 600;
SELECT *
FROM table01
WHERE salary >= 200 <= 600;OR
SELECT *
FROM table01
WHERE dept='개발' or dept='경영' or '영업';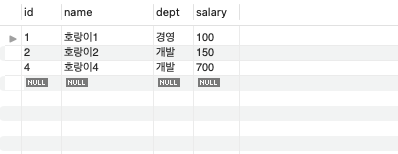
IN
SELECT *
FROM table01
WHERE dept in ('개발', '경영', '영업');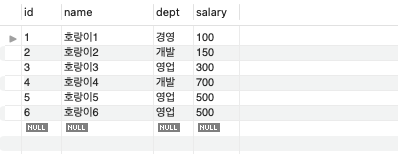
ANY, ALL
min과 max를 통해 any와 all을 이해해보자.
- max보다 작으면
x < any - max보다 크면
x > all - min보다 작으면
x < all - min보다 크면
x > any
제일 작은 수보다 큰 모든 값을 찾아라
SELECT *
FROM table01
WHERE salary > ANY(
SELECT salary FROM table01 WHERE salary BETWEEN 200 AND 700
);
-- 700, 500, 500, 999
-- 내부 쿼리의 최솟값(300)보다 큰 값들을 return
SELECT *
FROM table01
WHERE salary < ANY(
SELECT salary FROM table01 WHERE salary BETWEEN 200 AND 700
);
-- 내부 쿼리의 최댓값(700)보다 작은 값들을 returntable02를 생성하고 계속 이어서 any와 all을 알아보자.
CREATE TABLE table02 (
id INT NOT NULL AUTO_INCREMENT,
eno INT,
name VARCHAR(10),
salary INT,
PRIMARY KEY (`id`));
INSERT into table02 values(null, 10, 'tiger1', 100);
INSERT into table02 values(null, 20, 'tiger2', 200);
INSERT into table02 values(null, 30, 'tiger3', 300);
INSERT into table02 values(null, 40, 'tiger4', 400);
INSERT into table02 values(null, 10, 'tiger5', 500);
INSERT into table02 values(null, 20, 'tiger6', 600);
INSERT into table02 values(null, 30, 'tiger7', 700);
INSERT into table02 values(null, 10, 'tiger8', 800);
INSERT into table02 values(null, 20, 'tiger9', 350);
INSERT into table02 values(null, 30, 'tiger10', 999);다음의 문제를 풀어보자.
20번 부서에서 최고 연봉을 받는 사원의 이름을 출력하라는 문제가 있을때,
다음과 같은 과정으로 문제를 해결할 수 있다.
SELECT * FROM table02 WHERE eno=20;
-- 문제: 20번 부서에서 최고 연봉을 받는 사원의 이름 출력
-- 1) 최고 연봉을 받는 사원의 연봉 찾기
SELECT max(salary) FROM table02 WHERE eno=20;
-- 2) Sub Query 사용
SELECT name FROM table02 WHERE salary = 600;
-- 3) 위의 쿼리에서 600 대신, Sub Query를 넣어준다.
SELECT name
FROM table02
WHERE salary = (
SELECT max(salary)
FROM table02
WHERE eno=20
);비슷한 예제로,
20번 부서의 최고 연봉보다 작은 연봉을 받는 직원을 검색할 때,
다음과 같은 과정으로 문제를 해결할 수 있다.
-- 문제: 20번 부서의 최고 연봉보다 작은 연봉을 받는 직원을 검색하세요.
-- 1) 최고 연봉을 받는 사원의 연봉 찾기
SELECT max(salary) FROM table02 WHERE eno=20;
-- 2) Sub Query 사용
SELECT name FROM table02 WHERE salary = 600;
-- 3) 위의 쿼리에서 600 대신, Sub Query를 넣어준다.
SELECT *
FROM table02
WHERE salary < (
SELECT max(salary)
FROM table02
WHERE eno=20
);📣 QUIZ) 같은 문제를 통계함수(max)를 사용하지 않고, ANY를 통해 풀어보자!
일반적으로 ANY를 활용하면 성능이 좋아진다.
-- ANY를 활용하기
SELECT *
FROM table02
WHERE salary < ANY (
SELECT salary
FROM table02
WHERE eno=20
);
-- ANY를 활용하기 + 20번 부서인 사람 제외
SELECT *
FROM table02
WHERE salary < ANY (
SELECT salary
FROM table02
WHERE eno=20
) AND eno != 20;통계 함수
SELECT min(salary) from table01;
SELECT max(salary) from table01;
SELECT sum(salary) from table01;
SELECT avg(salary) from table01;
-- count()
-- variance, steddev: 표준편차, 분산표준 편차(Standard Deviation)는 데이터 집합의 분산(Variance)을 측정하는 통계적인 지표이다.
데이터의 편차(Deviation)를 측정하여 데이터가 얼마나 평균으로부터 퍼져 있는지를 나타낸다.
표준 편차는 데이터의 분포와 퍼진 정도를 나타내는 중요한 통계 지표이다.
값이 작을수록 데이터가 평균 주위에 모여 있고, 값이 클수록 데이터가 퍼져 있는 것을 의미한다.
분산(Variance)은 표준 편차의 제곱으로, 데이터의 변동성을 측정하는 지표이다.
표준 편차와 분산은 데이터의 분포와 변동성을 이해하고 비교하는 데 유용한 통계적인 도구이다.
🏹 MySQL Query - JOIN
CROSS JOIN
JOIN은 데이터베이스에서 두 개 이상의 테이블을 연결하여 관련된 데이터를 결합하는 작업이다. JOIN을 사용하면 여러 테이블의 데이터를 하나의 결과 집합으로 가져올 수 있다.
CROSS JOIN은 JOIN의 한 유형으로, 두 개의 테이블 간의 "카르테시안 곱"을 생성하는 작업을 수행한다. 카르테시안 곱은 한 테이블의 모든 행과 다른 테이블의 모든 행을 조합하여 결과 집합을 생성한다.
이를 알아보기 위해 table03, table04를 생성해보자.
-- cross join: 교차조인(데카르트곱 or 카테시안곱)
CREATE TABLE table03 (
id INT NOT NULL AUTO_INCREMENT,
name VARCHAR(10),
eno INT,
salary INT,
PRIMARY KEY (`id`));
INSERT into table03 values(null, '홍길동', 20, 100);
INSERT into table03 values(null, '이순신', 10, 200);
INSERT into table03 values(null, '안중근', 30, 300);
INSERT into table03 values(null, '임꺽정', 20, 400);
DROP TABLE table04;
CREATE TABLE table04 (
id INT NOT NULL AUTO_INCREMENT,
eno INT,
nickname VARCHAR(10),
PRIMARY KEY (`id`));
INSERT into table04 values(null, 10, '장군');
INSERT into table04 values(null, 20, '의적');
INSERT into table04 values(null, 30, '의사');총 12개의 결과가 나오게 된다.
-- 교차조인(묵시적 표현)
SELECT * FROM table03, table04;
-- 교차조인(명시적 표현), ansi join
SELECT * FROM table03 CROSS JOIN table04;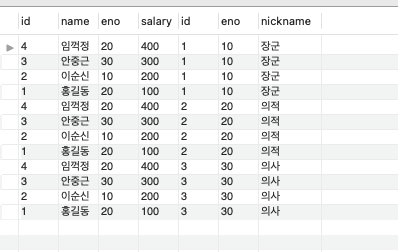
INNER JOIN
SELECT * FROM table03
INNER JOIN table04;이렇게만 문장을 사용하면 교차 조인과 같은 결과를 나타내게 된다.
이것은 내부 조인을 잘못 사용하고 있는 형태이다.
항상 조건(ON)을 동반해야 올바른 문장이다.
SELECT * FROM table03
INNER JOIN table04
ON table03.eno = table04.eno;INNER JOIN을 활용하는 step을 적어본다면 다음과 같다.
1) table03에서 row 1개를 가져온다.
2) on 조건을 검색한다. (table04와 비교)
3) 만족되는 row끼리 join
Filter 조건
SELECT * FROM table03
INNER JOIN table04
ON table03.eno = table04.eno -- 조인에 대한 조건
WHERE salary > 250; -- 필터 조건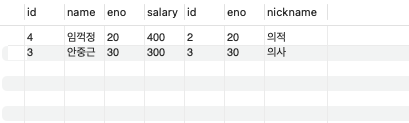
SELECT * FROM table03, table04
WHERE table03.eno = table04.eno;-- 조인 조건
SELECT * FROM table03, table04
WHERE table03.name = '홍길동'; -- 조인 조건
SELECT * FROM table03, table04
WHERE table03.eno = table04.eno -- 조인 조건
and salary > 250; -- 필터 조건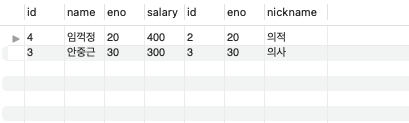
조인조건과 필터 조건을 명확히 구분해야 원하는 결과를 얻을 수 있다.
Table의 Alias(별칭)을 활용한 쿼리문
아래의 두 쿼리는 동일한 쿼리문이다.
SELECT * FROM table03, table04
WHERE table03.eno = table04.eno -- 조인 조건
and salary > 250; -- 필터 조건
SELECT * FROM table03 a, table04 b
WHERE a.eno = b.eno -- 조인 조건
and salary > 250; -- 필터 조건Column 명이 같은 경우 아래와 같이 명확하게 명시해주어야 한다.
SELECT name, a.id 테이블1, b.id 테이블2 FROM table03 a, table04 b
WHERE a.eno = b.eno; -- 조인 조건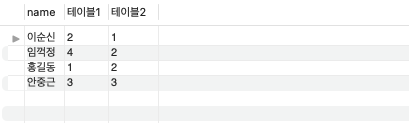
CROSS JOIN vs INNER JOIN vs 일반쿼리
SELECT * FROM table03
CROSS JOIN table04
ON table03.eno = table04.eno;CROSS JOIN과 ON을 같이 사용하면 안된다.
ON은 INNER JOIN인 경우에만 사용한다.
-- 안시 쿼리
SELECT * FROM table03
INNER JOIN table04
ON table03.eno = table04.eno
WHERE salary > 250;
-- 일반 쿼리
SELECT * FROM table03, table04
WHERE table03.eno = table04.eno
AND salary;두 쿼리는 같은 쿼리이다. JOIN을 활용하는 경우에는 ON 과 WHERE을 사용하는 반면 일반 쿼리에서는 WHERE과 AND를 사용한다.
📣 QUIZ) JOIN을 활용한 문제 1
우선 다음과 같이 사람이 등록된 테이블과 직업이 등록된 테이블을 생성하자.
CREATE TABLE table05 (
id INT NOT NULL AUTO_INCREMENT,
pno INT, -- 직업번호
name VARCHAR(10),
PRIMARY KEY (`id`));
INSERT into table05 values(null, 101, '이순신');
INSERT into table05 values(null, 102, '홍길동');
INSERT into table05 values(null, 100, '안중근');
INSERT into table05 values(null, 102, '임꺽정');
INSERT into table05 values(null, 100, '윤봉길');
INSERT into table05 values(null, 101, '강감찬');
CREATE TABLE table06 (
id INT NOT NULL AUTO_INCREMENT,
cno INT, -- 직업번호
name VARCHAR(10),
PRIMARY KEY (`id`));
INSERT into table06 values(null, 100, '의사');
INSERT into table06 values(null, 101, '장군');
INSERT into table06 values(null, 102, '의적');이 때 이순신의 직업이 무엇인지 찾는다면?
정답은 아래와 같다.
SELECT a.name 이름, b.name 직업
FROM table05 a
INNER JOIN table06 b
ON a.pno = b.cno
WHERE a.name = '이순신';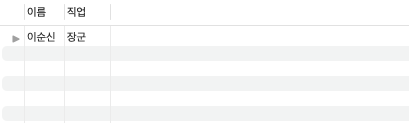
📣 QUIZ) JOIN을 활용한 문제 2
우선 다음과 같이 사람이 등록된 테이블과 과목 및 학점이 등록된 테이블을 생성하자.
DROP TABLE tableA;
CREATE TABLE tableA (
id INT NOT NULL AUTO_INCREMENT,
pno INT, -- 직업번호
name VARCHAR(10),
PRIMARY KEY (`id`));
INSERT into tableA values(null, 100, '홍길동');
INSERT into tableA values(null, 101, '이순신');
INSERT into tableA values(null, 102, '안중근');
INSERT into tableA values(null, 103, '임꺽정');
INSERT into tableA values(null, 104, '강감찬');
DROP TABLE tableB;
CREATE TABLE tableB (
id INT NOT NULL AUTO_INCREMENT,
name VARCHAR(10),
num INT,
pno INT,
PRIMARY KEY (`id`));
INSERT into tableB values(null, '국어', 4, 103);
INSERT into tableB values(null, '영어', 3, 104);
INSERT into tableB values(null, '수학', 2, 102);
INSERT into tableB values(null, '사회', 1, 101);
INSERT into tableB values(null, '체육', 2, 103);
INSERT into tableB values(null, '생물', 2, 102);이 때 2학점을 가르치는 교수의 이름을 출력하는 쿼리를 작성하면?
SELECT distinct a.name FROM tableA a, tableB b
WHERE a.pno = b.pno
AND num=2;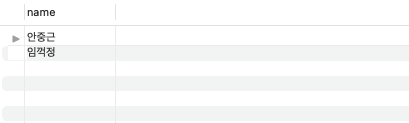
Natural Join
공통 column이 하나일 때, 알아서 그 column을 join해준다.
테이블을 생성해보자.
DROP TABLE table01;
CREATE TABLE table01 (
a_id INT NOT NULL AUTO_INCREMENT,
name VARCHAR(10),
eno INT,
salary INT,
PRIMARY KEY (`a_id`));
INSERT into table03 values(null, '홍길동', 20, 100);
INSERT into table03 values(null, '이순신', 10, 200);
INSERT into table03 values(null, '안중근', 30, 300);
INSERT into table03 values(null, '임꺽정', 20, 400);
DROP TABLE table02;
CREATE TABLE table02 (
b_id INT NOT NULL AUTO_INCREMENT,
eno INT,
nickname VARCHAR(10),
PRIMARY KEY (`b_id`));
INSERT into table04 values(null, 10, '장군');
INSERT into table04 values(null, 20, '의적');
INSERT into table04 values(null, 30, '의사');아래의 세 쿼리문은 같은 쿼리문이다.
SELECT * FROM table01
NATURAL JOIN table02;
SELECT * FROM table01
INNER JOIN table02
ON table01.eno = table02.eno;
SELECT * FROM table01, table02
WHERE table01.eno = table02.eno;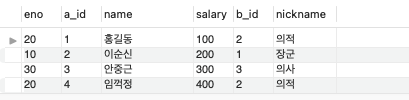
USING
그런데 만약 중복되는 column 명이 존재한다면?
USING을 사용해서 기준이 되는 column을 지정할 수 있다.
우선 중복되는 column이 존재하도록 테이블을 다시 생성하자.
DROP TABLE table01;
CREATE TABLE table01 (
id INT NOT NULL AUTO_INCREMENT,
name VARCHAR(10),
eno INT,
salary INT,
PRIMARY KEY (`id`));
INSERT into table01 values(null, '홍길동', 20, 100);
INSERT into table01 values(null, '이순신', 10, 200);
INSERT into table01 values(null, '안중근', 30, 300);
INSERT into table01 values(null, '임꺽정', 20, 400);
DROP TABLE table02;
CREATE TABLE table02 (
id INT NOT NULL AUTO_INCREMENT,
eno INT,
nickname VARCHAR(10),
PRIMARY KEY (`id`));
INSERT into table02 values(null, 10, '장군');
INSERT into table02 values(null, 20, '의적');
INSERT into table02 values(null, 30, '의사');id, eno column이 테이블 2개에 중복되어서 존재한다.
이떄 다음과 같이 USING을 사용해서 한개의 column을 지정할 수 있다.
SELECT * FROM table01
JOIN table02 USING(eno);Non-equi JOIN
Non-equi JOIN(비등가 조인)은 조인 조건에서 등호(=)를 사용하지 않고
비교 연산자(>, <, >=, <=, <>)를 사용하여 두 테이블을 조인하는 방식이다.
비등가 조인은 두 테이블 사이에 일치하는 조건을 설정하고,
조건에 맞는 데이터만을 가져오는데 사용된다.
-- 등가 조인
SELECT name, grade FROM tableA t1
INNER JOIN tableB t2
ON (t1.salary >= t2.lowsalary and t1.salary <= t2.hisalary);
-- 내부 조인
SELECT name, grade FROM tableA t1
INNER JOIN tableB t2
ON (salary BETWEEN t2.losalary and t2.hisalary);
-- 일반 조인
SELECT name, grade FROM tableA t1
INNER JOIN tableB t2
WHERE salary BETWEEN t2.losalary and t2.hisalary;SELF JOIN
SELF JOIN(셀프조인)은 하나의 테이블 내에서 자기 자신과 조인하는 것이다.
즉, 같은 테이블을 두 번 사용해서 데이터를 비교하고 연결하는 것이다.
주로 계층 구조나 이력 데이터와 같이 부모-자식 관계를 가지는 데이터를 처리할 때 사용된다.
예시를 통해 알아보기 위해 우선 테이블을 생성하자.
drop table tableA;
create table tableA(
id INT NOT NULL AUTO_INCREMENT, -- 컬럼1
nickname VARCHAR(45), -- 컬럼
PRIMARY KEY (id));
insert into tableA values(null,'홍길동');
insert into tableA values(null,'이순신');
insert into tableA values(null,'안중금');
insert into tableA values(null,'임꺽정');
insert into tableA values(null,'김서방');
insert into tableA values(null,'이순신');
insert into tableA values(null,'김서방');
insert into tableA values(null,'강감찬');
insert into tableA values(null,'이순신');위의 테이블에서, 동명이인의 이름을 검색하는 쿼리를 작성해보자.
select distinct t1.nickname from tableA t1, tableA t2
WHERE t1.nickname = t2.nickname
AND t1.id != t2.id;위와 같이 tableA를 t1, t2와 같이 2번 사용한 후, 같은 nickname을 찾으면 된다.
SEMI JOIN
SEMI JOIN(세미 조인)은 한 테이블의 행들을 다른 테이블과 비교하여 일치하는 행들만 반환하는 조인이다.
즉, 첫 번째 테이블의 행이 두 번째 테이블과 일치하는지 여부만 확인하고, 일치하는 행들만 결과에 포함시킨다.
일치 여부만 확인하고 실제로 조인된 데이터를 반환하지는 않는다.
세미 조인은 주로 서브쿼리를 사용하여 구현되며, 주로 필터링 작업이나 존재 여부 확인 등에 활용된다.
예시를 통해 살펴보기 위해 테이블을 생성하자.
DROP TABLE menu;
CREATE TABLE menu(
foodnum int,
name varchar(20)
);
DROP TABLE sell;
CREATE TABLE sell(
no int, -- 인덱스
count int, -- 판매수량
foodnum int -- 판매음식 번호
);
insert into menu values (1, '짜장');
insert into menu values (2, '우동');
insert into menu values (3, '냉면');
insert into menu values (4, '탕슉');
insert into menu values (5, '양장');
insert into sell values (1, 2, 1);
insert into sell values (2, 3, 2);
insert into sell values (3, 4, 2);
insert into sell values (4, 2, 2);
insert into sell values (5, 2, 1);다음의 과정을 통해 세미 조인을 구현해보자.
우선, sell의 테이블의 foodnum을 하나씩 출력한다.
SELECT s.foodnum FROM sell s;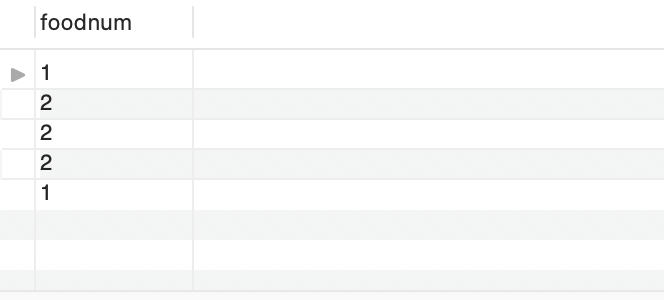
위의 쿼리를 서브 쿼리로 작성하면, foodnum에 해당하는 name을 불러올 수 있다.
SELECT *
FROM menu d
-- WHERE d.foodnum = 1 or d.foodnum = 2;
-- WHERE d.foodnum IN (1, 2, 2, 2, 1);
WHERE d.foodnum IN (SELECT s.foodnum FROM sell s);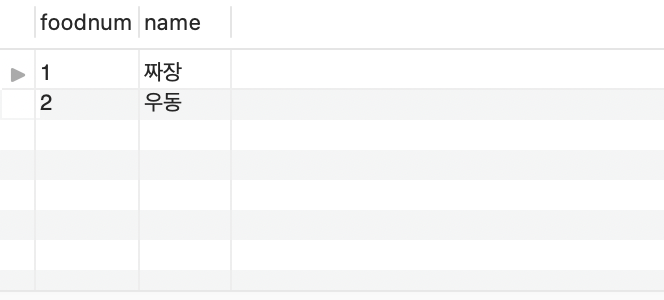
위의 쿼리에서 발전된 아래의 쿼리를 살펴보자.
SELECT *
FROM menu d
WHERE EXISTS (
SELECT * FROM sell s
WHERE d.foodnum = s.foodnum
);다음과 같이 동작한다.
1. menu table에서 row 1개를 가져온다.
2. 가져온 row가 exists 안의 문장에서 참인지 거짓인지 평가한다.
3. 참이면 row를 출력한다.
거짓이면 다음 row를 가져온다.
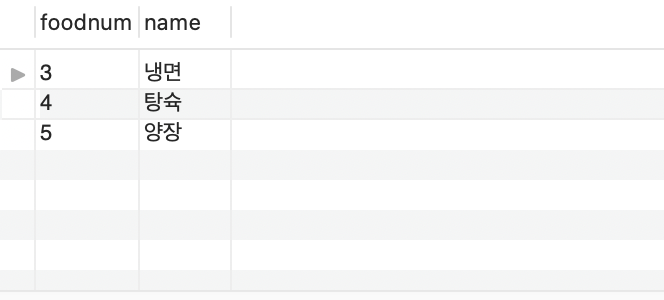
만약, NOT EXISTS를 사용한다면, 이를 안티 조인이라고 부르며 다음과 같다.
SELECT *
FROM menu d
WHERE NOT EXISTS (
SELECT * FROM sell s
WHERE d.foodnum = s.foodnum
);
🏹 JOIN 정리
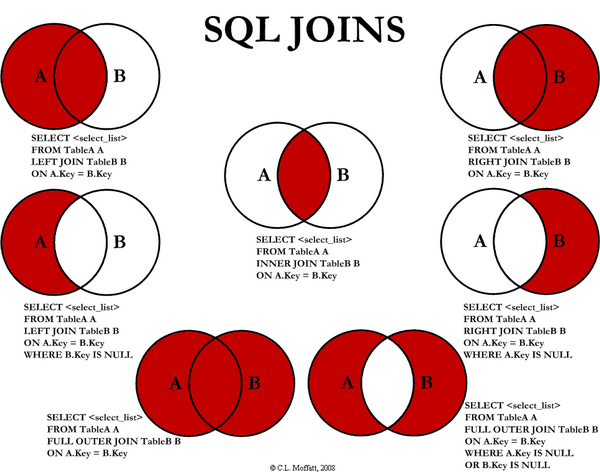
위 그림을 이해할 수 있다면 당신은 조인 마스터 ~!
- Inner Join
: 두 개의 테이블에서 일치하는 값을 기준으로 결과를 반환한다. - Left Outer Join
: 왼쪽 테이블(A)의 모든 행을 포함하고, 오른쪽 테이블(B)에서 일치하는 값들을 가져온다. 오른쪽 테이블의 값이 없을 경우 NULL로 채워진다. - Right Outer Join
: 오른쪽 테이블(B)의 모든 행을 포함하고, 왼쪽 테이블(A)에서 일치하는 값들을 가져온다. 왼쪽 테이블의 값이 없을 경우 NULL로 채워진다. - Full Outer Join
: 왼쪽 테이블(A)과 오른쪽 테이블(B)의 모든 행을 포함하고, 서로 일치하는 값들을 가져온다. 일치하지 않는 값은 NULL로 채워진다. - Cross Join
: 왼쪽 테이블(A)의 모든 행과 오른쪽 테이블(B)의 모든 행을 조합하여 결과를 반환한다.
