미래연구소
http://futurelab.creatorlink.net/
Activation Function
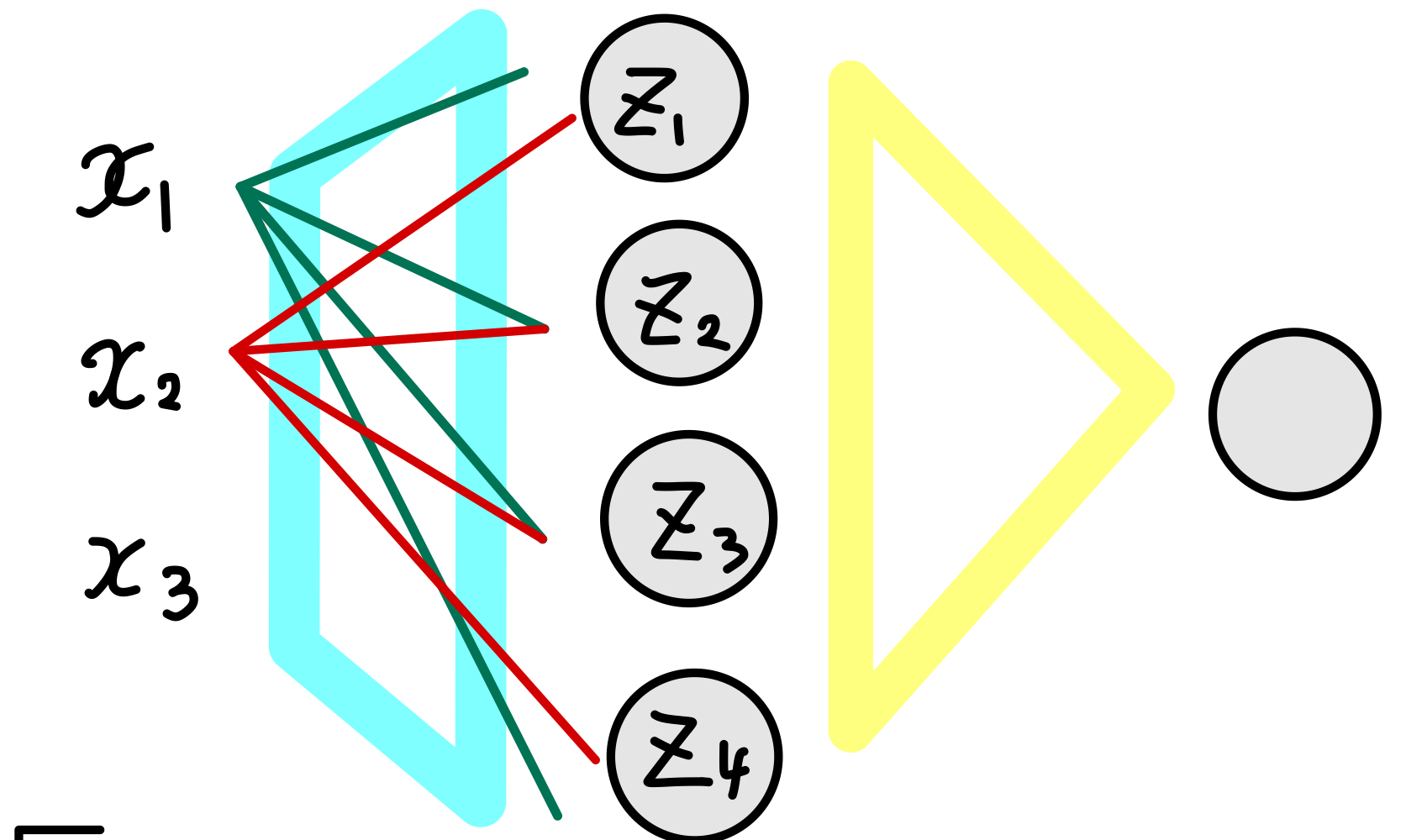
- Z(1)=w(1)X+b(1)
=[w(1)X(1)+b(1) w(1)X(2)+b(1) ...]
Z에 sigmoid함수를 씌어 activation값을 구함
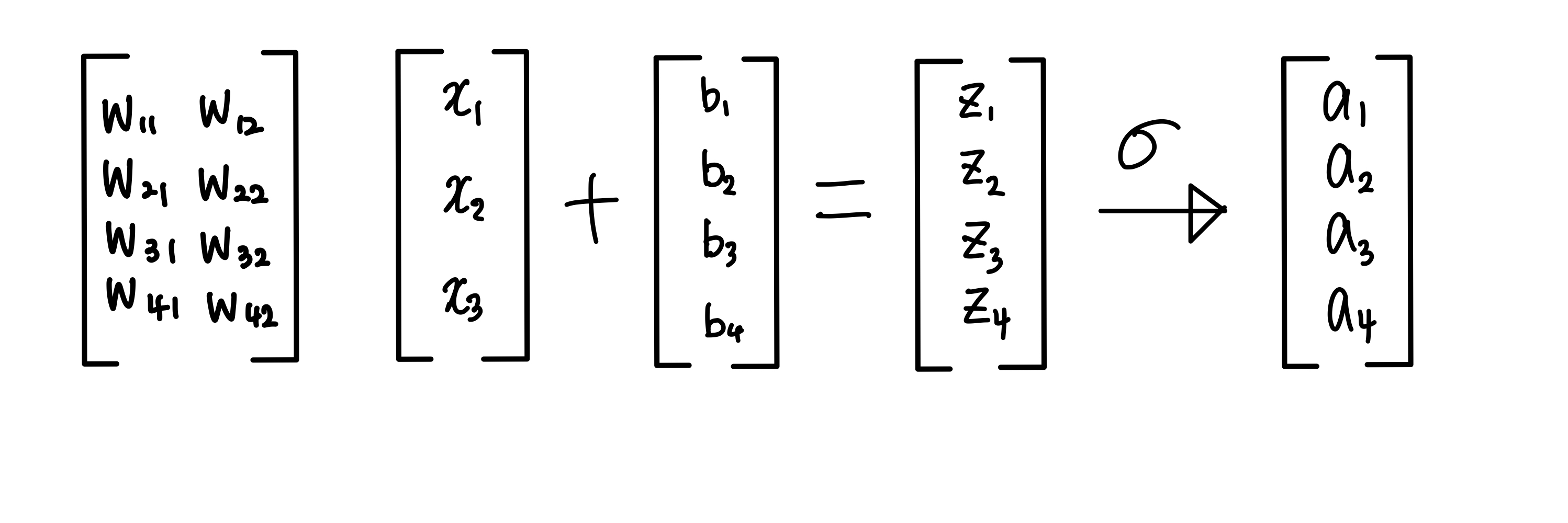
Data의 개수를 n개, Data의 dim nx개:
X=[x1, x2, x3 ..., xn] -> (nx, n)
Zi[l][k]: k번째 data로 붙터 얻은 l번째 layer의 i번째 component
- Activation Function
*activation이 non-linear해야 하는 이유:
activation이 linear하다는 것은 일차함수 꼴을 나타낸다. 하지만 딥러닝은 binary에 가장 이상적인 함수를 찾아야 하기 때문에 gradient desxent에 따라 w와b 값을 변형하며 최적의 함수를 찾는다. 비선형성을 적용하며 선형성만으로는 설명할 수 없는 것을 설명하게 된다.
*vanishing gradient:
activation의 미분계수가 0에 가까워지면 gradient descent가 일어나지 않으며 학습이 잘 일어나지 않게된다.
*Sigmoid: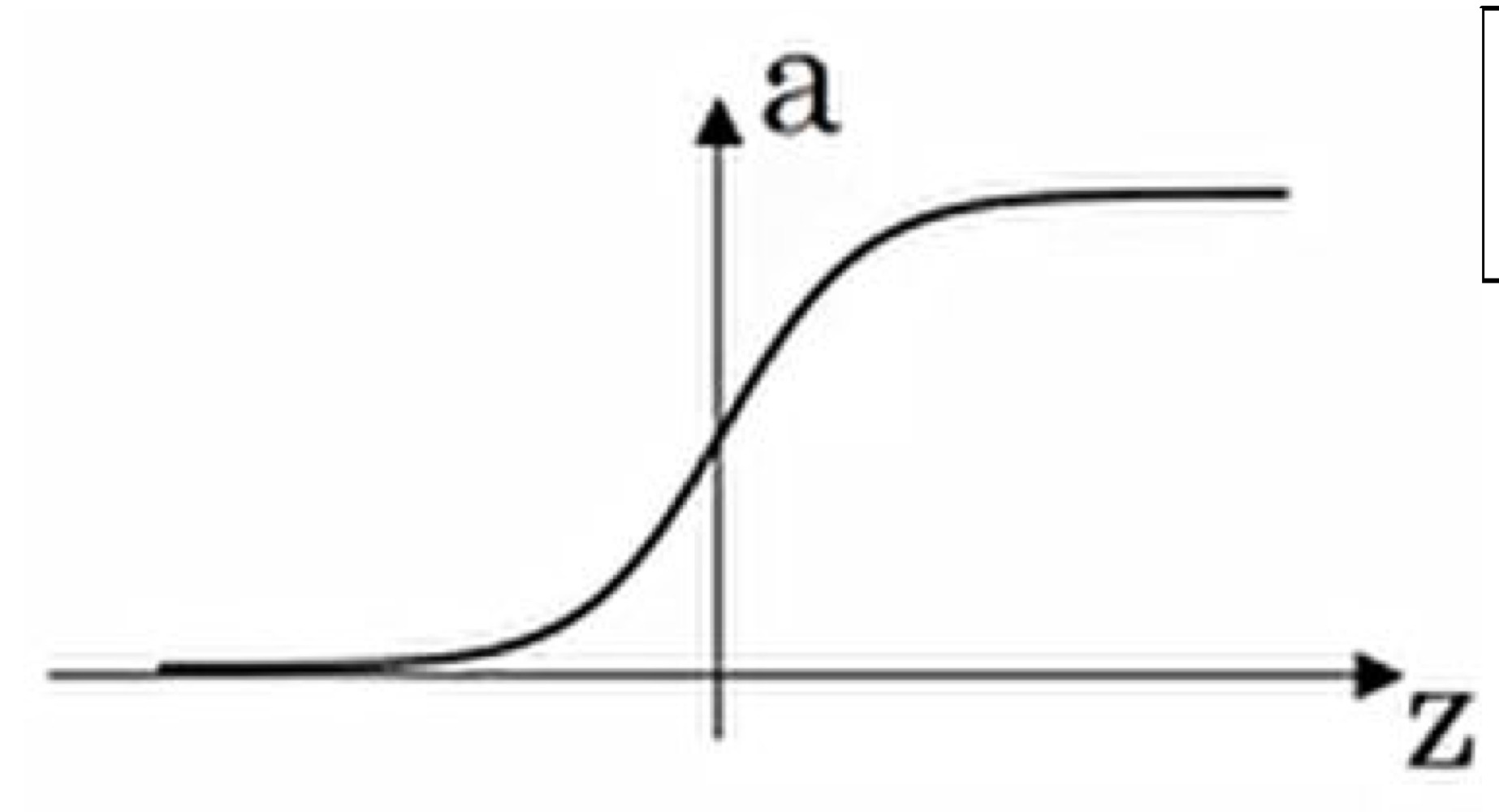
장점: binary classification의 output layer라는 특수한 상황에 적합
단점: gradient descent 속도 저하
*tanh(hyperbolic tangent)
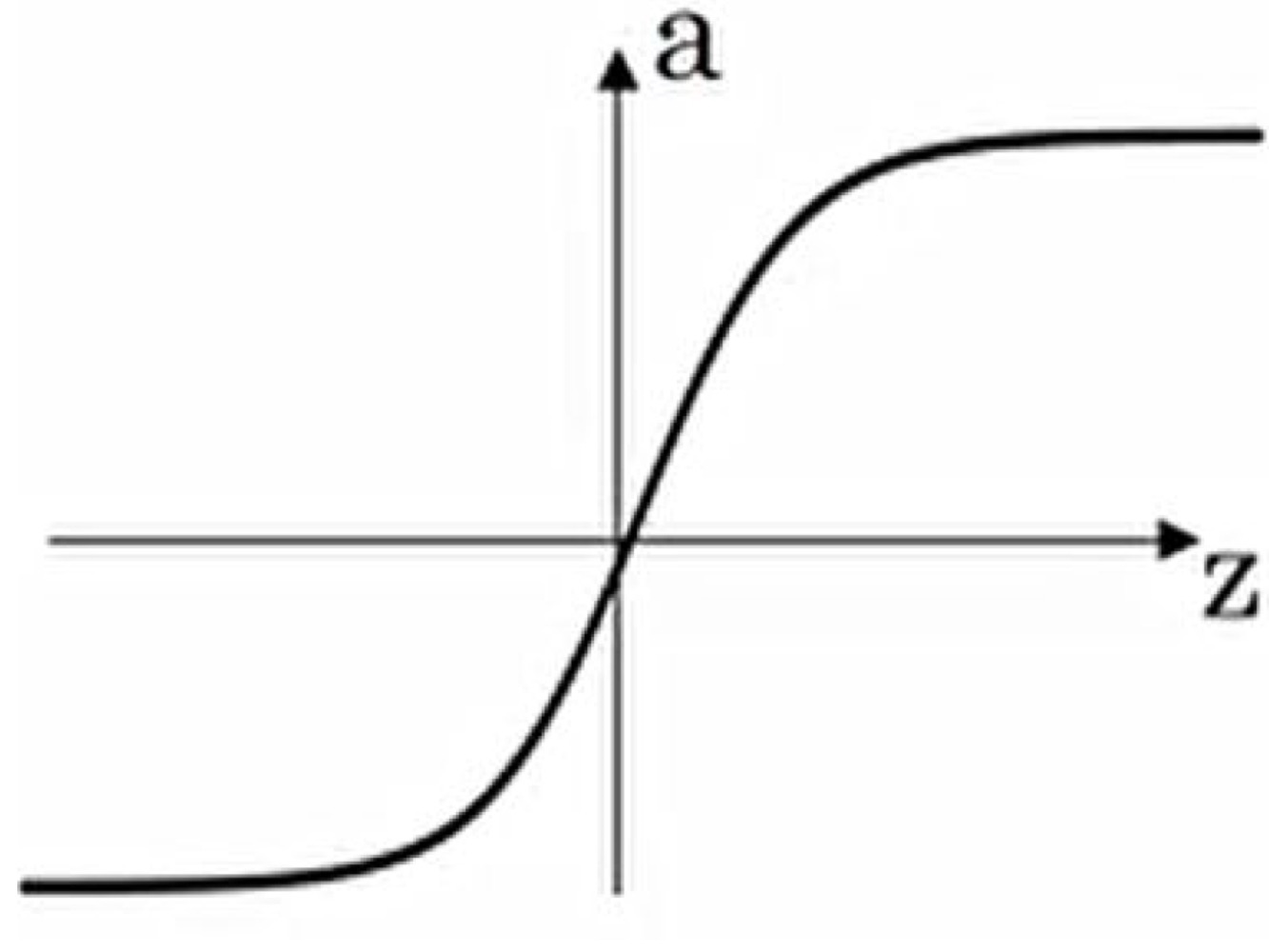
장점: sigmoid보다는 vanishing gradient가 덜함
단점: gradient descent 속도 저하
*ReLU(Rectified Linear Unit)
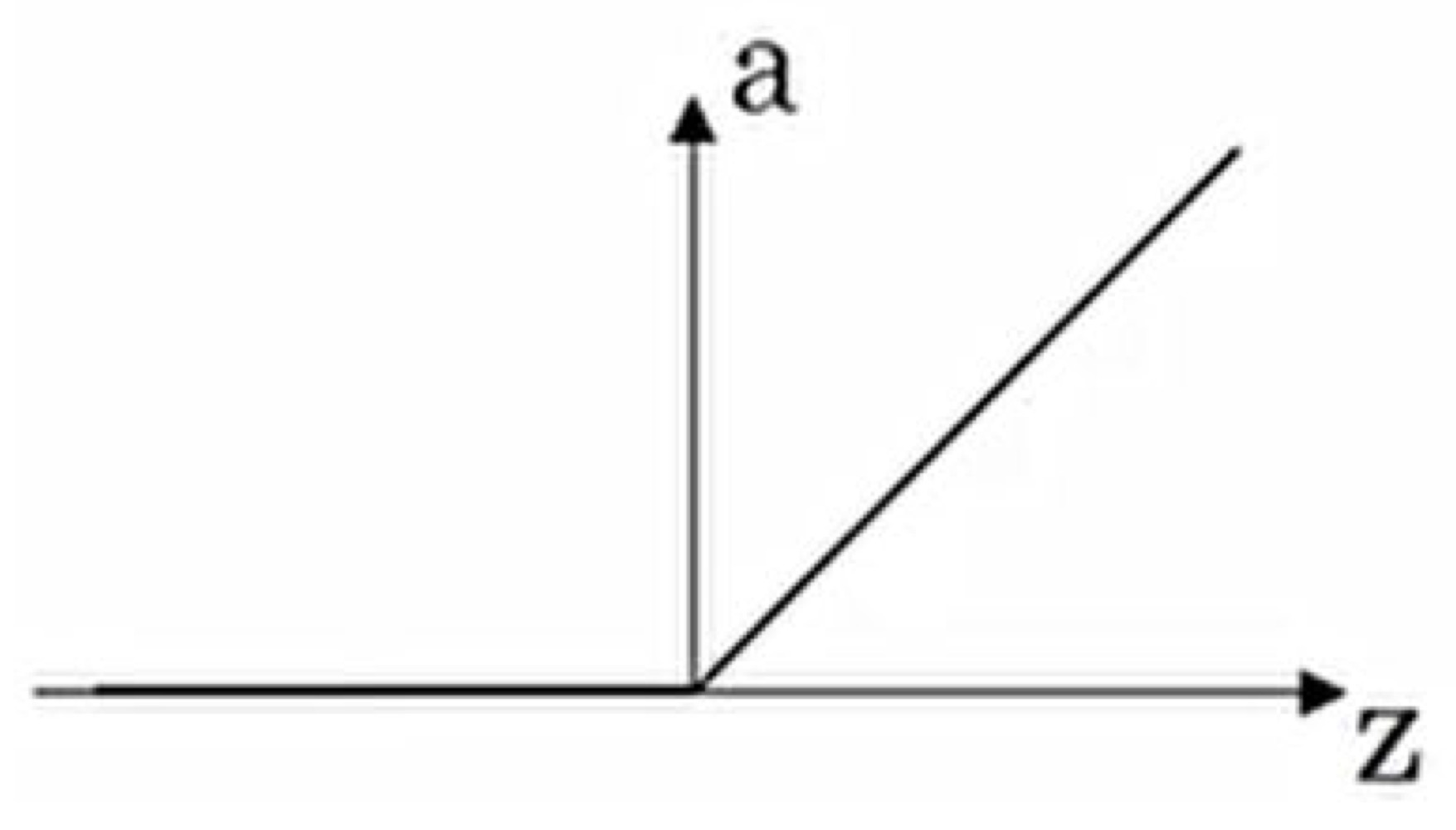
장점: sigmoid, tanh의 vanishing gradient 문제 해결
단점: 그래도 절반이 gradient가 0 (dying ReLu)
*Leaky ReLU
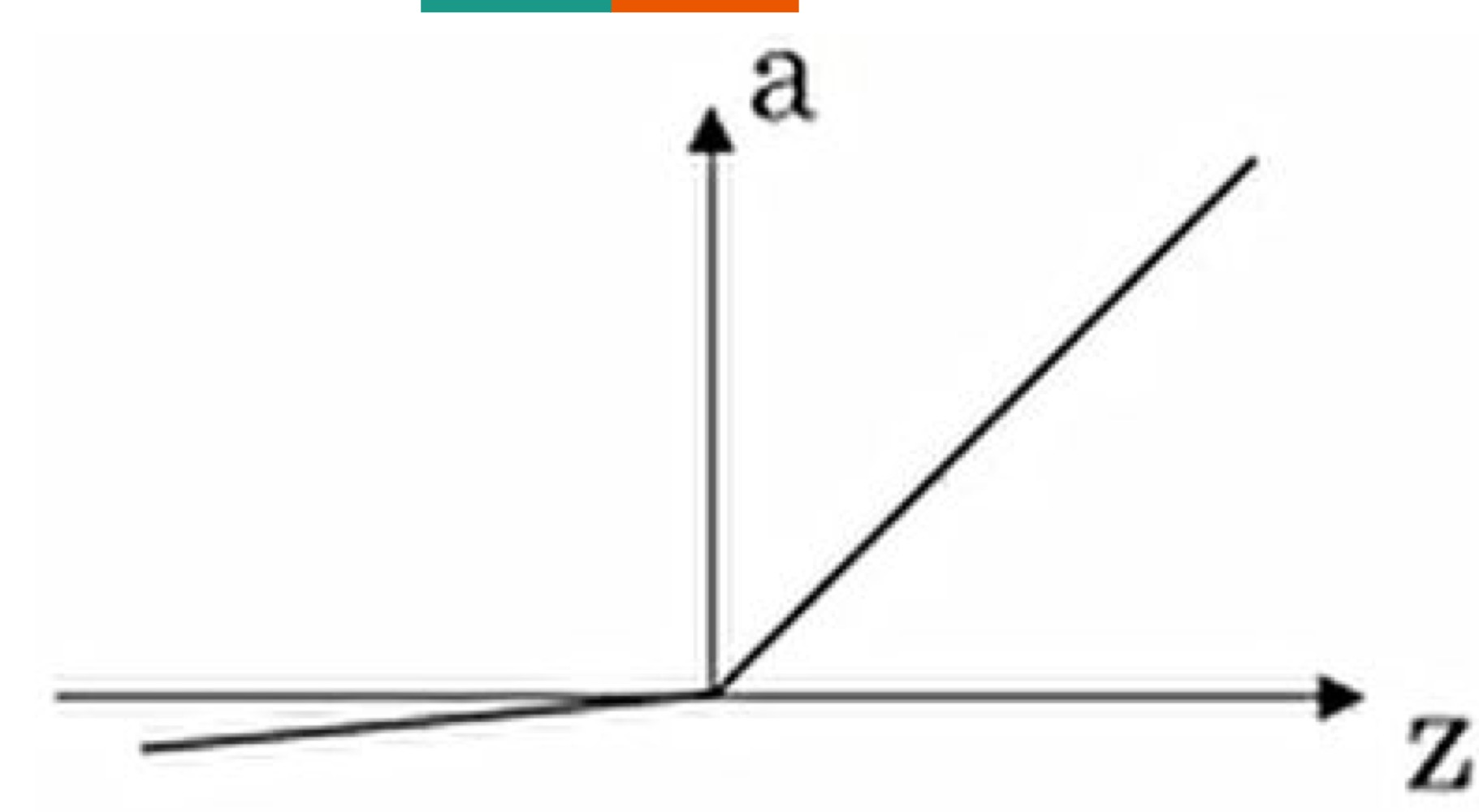
장점: dying ReLu현상을 해결(GAN과 같은 train이 어려운 경우에 사용)

