http://futurelab.creatorlink.net
REVIEW
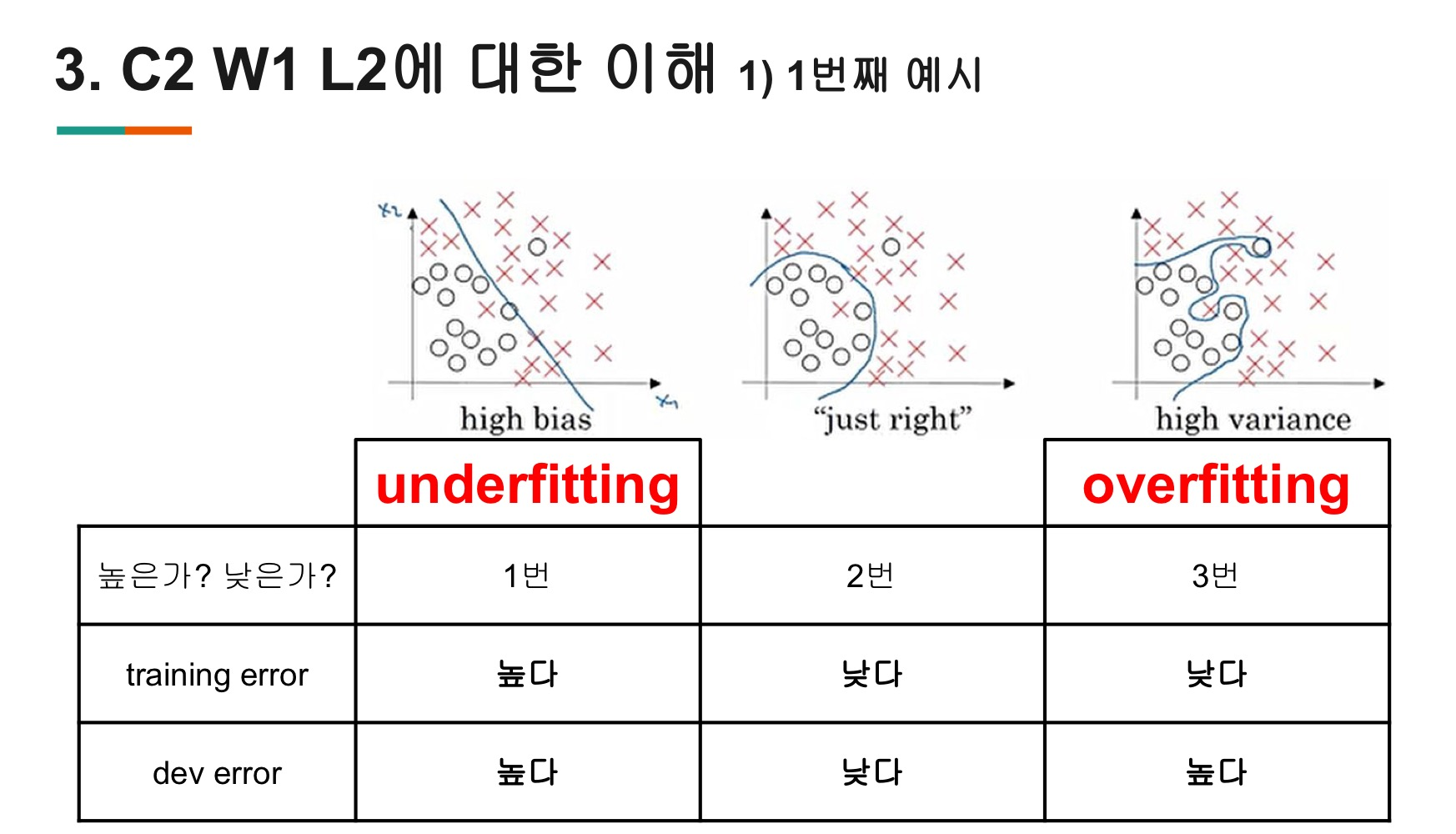
Hidden layer가 추가되면 XOR연산을 해결할 수 있음
n[l] = l번째 layer의 noded의 수
W[l].shape = input의 shape와 곱해지고 1번째 node의 수의 dim
Hyper Parameter : 원하는 대로 정할 수 있는 parameter
-> learning rate, number of Layer, number of unit of each layer, activation function, GD(gradient descent)를 몇 번 할 것인지(= 몇 epoch을 돌 것인지)
Hold Out Validation
어떤 HP(hyper prameter)가 좋은지? 어떻게 train해야하는지?
data가 한정적일때 무작정 forward_propagation -> backward_propagation X
(정답을 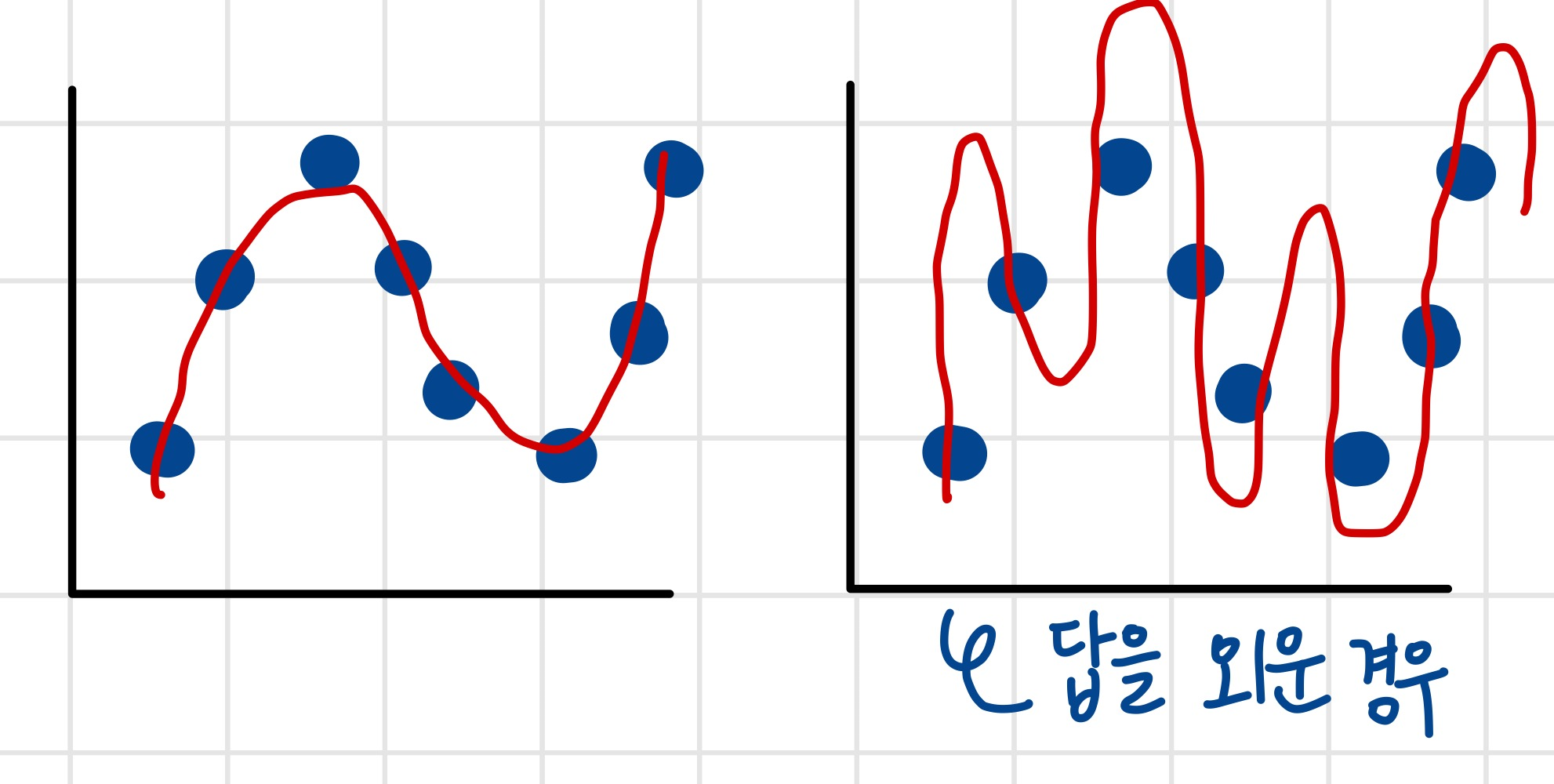 외워 버릴 수 있음) = Bias_variance trade off
외워 버릴 수 있음) = Bias_variance trade off
=>모든 data로 training할 수 없기 때문에 data split가 필요
data split (train_set, val_set, test_set)
학습시키는 data, 검증하는 data 따로 split
1) training set
-
학습 시키는 data
-
최적의 parameter를 찾는 과정 = gradient descent = parameter update
-
fit하는 과정
2) validation set -
내가 선택한 모델 (hyperparameter의 조합)이 최적의 모델인지 validation set으로 검증
-
결과의 따라 tuning 함
-
여러번 evaluate할 수 있음
-
이 data로 gradient descent하지 않음
3)test set -
수차례 검증을 마치고 최종 test에 사용하는 data
-
결과의 따라 tuning할 수 없음
-
한번만 evaluate 함
-
이 data로 gradient descent하지 않음
Fit
-
train의 동의어
-
특정 data를 학습하는 과정
-
training set뿐 아니라 test set까지도 예측
1) underfit:
학습 초반 모델은 initialization 직후여서 최적의 parameter가 아닌 상황. 예측을 잘 못한 상황
2) fit:
train 할 수록 점점 training data에 잘 맞춰짐. 하지만 unseen data에도 잘 맞을수 있음
3) overfit:
과도하게 학습 하ㅏ보면 향후 존재할 unseen data는 빗나가게 됨
=>중간중간 학습하지 않는 data로 overfit을 확인해야함 -> validation set을 설정