Initialization
1.zero initialization
문제점-> row symmetric(node를 여러개 설정했음에도 1개인 효과를 갖음)
-> vanishing gradient(W[i] = 0이 되면 dW[i] = 0이 됨)
해결-> np.random.randn*0.01
2.Random Initializaion
fan-in: 들어오는 layer의 unit개수 => n[i-1]
fan-out: 현재 layer의 unit개수 =>n[i]
문제점-> fan-in이 길수록 출력되는 fan-out의 값이 커짐 -> gradient exploding
->fan-in이 짧을수록 출력되는 fan-out의 값이 작아짐 -> gradient vanishing
해결->fan-in에 반비례한 초기화 상수를 사용해야함
3.Xavier Initialization
fan-in과 fan-out 모두 고려한 방식
문제점: ReLU를 쓰면 layer별 output이 0 주변에 과도하게 몰림
4.He Initialization
fan-in만 고려, ReLu계열에 특화
Mini-Batch Gradient Descent
batch: 우리가 가진 전체 training data
1번 학습할때 (gradient descent),data 전체(batch)를 사용
1 epoch할때 batch size만큼 묶어서 진행 (기본 batch size는 32/ 50000/32 = 1562...xx이므로 총 1563번 진행됨)
mini batc: 단일 train iteration에서 gradient descent하는데 사용하는 data의 총 개수
epoch: data 전체를 train한 횟수
크기- epoch< mini batch< batch
Batch Gradient Descent:한번에 모든 data train
Mini Batch Gradient Descent: 한번에 mini batch만 train
Stochastic Gradient Descent(SGD): 한번에 1개의 data 씩만 train
==> 이론과 실제 코딩에서 사용하는 용어가 다름
mini batch => batch_size: 단일 train iteration에서 gradient descent하는데 사용하는 data의 총 개수
Mini Batch Gradient Descent=> SGD + batch_size: 한번에 batch size씩만 train
batch_size가 클수록 더 정확한 gradient를 계산하는 경향이 있음/클수록 좋음/2의 거듭제곱으로 설정/
Optimizer
(gradient)
1.SGD
random하게 추출한 mini_batch씩 gradient descent진행
문제점: gradient가 dimension 별로 차이가 크면 minimum을 찾기 어려움
해결: 관성
gradient에 관성을 주는 경우 or learning rate에 관성을 주는 경우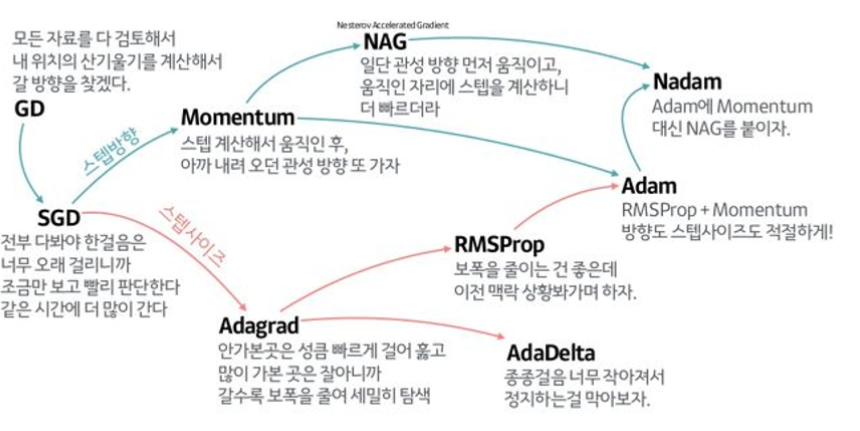
2.SGD + Momentum
3.NAG
(learning rate)
4.Adagrad
5.Rmsprop
6.Adam
