Deep Learning tutorial
1.data 업로드
2.data확인
3.data preprocess
-data를 딥러닝 모델 안에 넣고 잘 train 될 수 있게 하는 모든 행위
-tensorflow, normalization, data pre-processing, flatten, one- hot encoding
one-hot encoding
- 단어 집합의 크기를 벡터의 차원으로 하고, 표현하고 싶은 단어의 인덱스에 1의 값을 부여, 다른 인덱스는 0을 부여하는 단어의 벡터 표현 방식
-one-hot encoding을 하면 'categorical_crossentropy', 안하면 'sparse_categorical_crossentropy'로 loss 선택
4.모델 만들기
-model = sequential([layer1, layer2,...])/ add메소드/ sequential을 함수 안에 넣기
5.모델의 학습과정 설정(compile)
-optimizer/ loss설정/ metrics
6.모델 학습(fit)
7.학습과정 graph
8.최종 test
How to solve the over&under fit issue
-Underfitting일때
1.try bigger network
2.train longer(Epoch수를 늘림)
3.others
-Overfitting일때
1.get more data
2.regularization
3.dropout
4.train time줄이고 small network
val set의 error가 큼 -> overfitting에서 관찰-> |wi|이 너무 큼 -> 훈련과정에서 너무 크지 않게 제한시키자
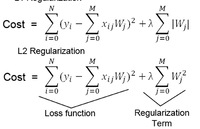
Regularization
1. cost에 일정 값을 더해서 fit의 시점을 늦추는 방식
2.L1보다는 L2를 사용
3.람다는 hyperparameter이며 람다가 클수록 regularization 효과가 커짐
4.'Weight Decay'로 불림
Dropout
-다른 node들은 결과에 영향을 미치지 않고 특정 node에 weight가 너무 커짐 -> train할 때 Random하게 노드를 쉬게하자
1.매 학습마다 설정한 drop rate만큼 random하게 node를 지워서 학습시킨다
2.다른 node들이 지워졌다 복원되었다가를 반복(특정 node에 의존 하는 것 해결)
3.regularizer와 달리 dropout layer가 따로 존재(dropout layer는 실질적인 layer는 아님)
-바로 위의 layer를 dropout함
-dropout layer의 rate
))버릴 unit의 비율을 결정(0~1사이 값)
))rate를 크게 할 수록 dropout 효과가 큼
