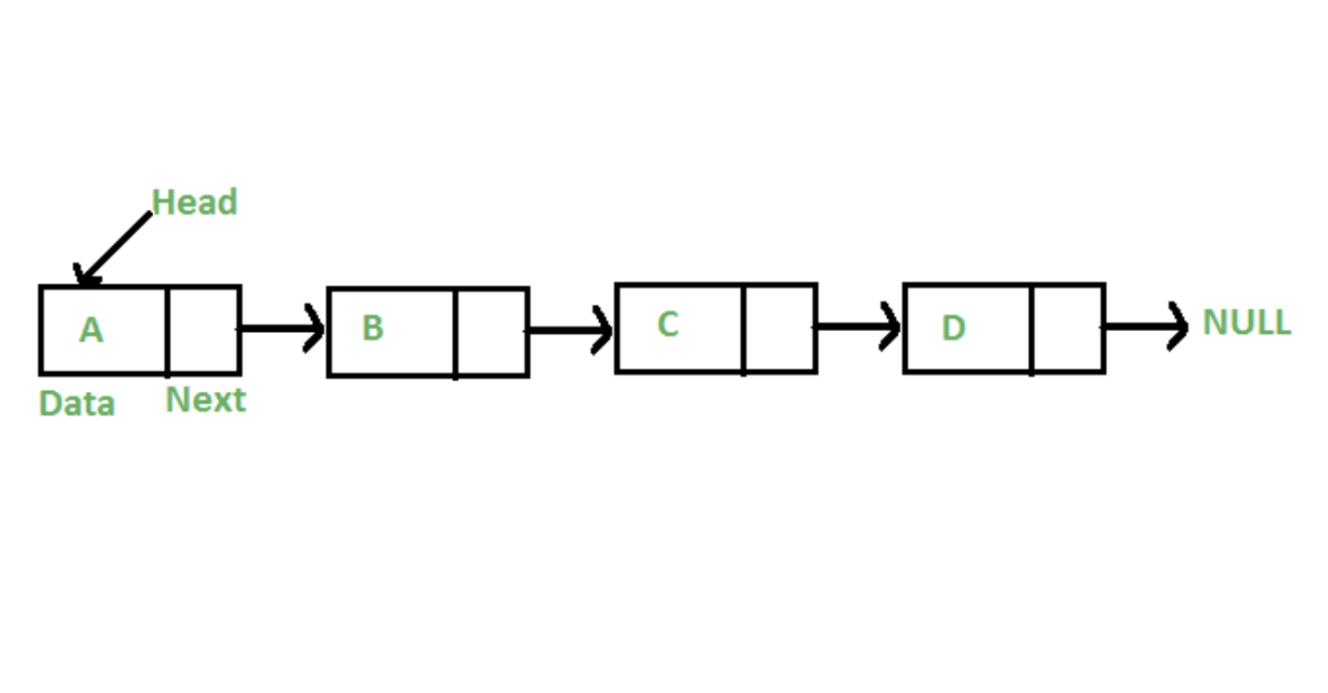
연결 리스트 (Linked List)
1. 정의
- 노드로 구성된 선형적인 자료 구조로, 각 노드가 데이터를 담고 있고, 다음 노드를 가리키는 포인터로 연결되어 있음
- 종류: 싱글 연결 리스트(next), 이중 연결 리스트(next, prev), 원형 연결 리스트
2. 시간 복잡도
- 참조 : O(n), 랜덤 접근이 불가능
- 탐색 : O(n), 배열과 동일
- 삽입/삭제: O(1), 중간에 연결된 포인터를 끊고, 새로운 노드를 추가하거나 노드 하나를 삭제하면 되기 때문
3. 연결 리스트의 종류
싱글 연결 리스트(Singly Linked List)
- 한 방향으로만 데이터가 연결된 형태
이중 연결 리스트(Doubly Linked List)
- 양방향으로 데이터가 연결된 형태

원형 연결 리스트(Circular Linked List)
- 마지막 노드와 첫 번째 노드가 연결되어 원을 이룸
- 원형 싱글 연결 리스트와 원형 이중 연결리스트가 존재
참조> 랜덤 접근과 순차적 접근
-
랜덤 접근: 배열과 같이 인덱스를 통해 임의의 위치에 접근하는 것
-
순차적 접근: 연결 리스트와 같이 처음부터 차례대로 접근하는 것
-
연결리스트는 순차적 접근만 가능하며 랜덤 접근은 불가능
스택(Stack)
후입선출(LIFO)의 성질을 가지는 자료구조. 가장 마지막에 들어간 데이터가 가장 먼저 나온다
- 재귀적인 함수, 깊이 우선 탐색에 사용
1. 시간 복잡도
- n번째 참조: O(n)
- 가장 위(앞) 부분 참조: O(1)
- 탐색: O(n)
- 삽입/삭제 (가장 위에 삽입/삭제): O(1)
2. Java stack 관련 메서드 정리
- stack 선언
import java.util.Stack;
Stack<자료형> stack = new Stack<>();- 메서드
| 종류 | method | 반환값 |
|---|---|---|
| 삽입 | stack.push(value); | 삽입한 value |
| 삽입 | stack.add(value); | boolean true : 성공 , false (실패, stackOverflow) |
| 삭제 | stack.pop(); | 삭제한 value. 빈 stack의 경우 EmptyStackException |
| 삭제 | stack.remove(idx); | 삭제한 value. 잘못된 idx 입력시 ArrayIndexOutOfBoundsException |
| 맨위원소 반환 | stack.peek(); | 맨 위 원소 value |
| 크기 | stack.size(); | 스택에 저장된 value의 개수 |
| 빈 스택인지 확인 | stack.isEmpty(); | true/false |
| 특정 value 존재하는지 확인 | stack.search(value); | top 기준 value의 위치 (1 ~stack.size())/ 존재하지 않으면 -1 |
| 스택 값 변경 | stack.set(idx, value); | 변경 전 value , 잘못된 idx의 경우 ArrayIndexOutOfBoundsException |
| 해당 인덱스에 존재하는 값 반환 | stack.elementAt(idx); | 인덱스에 저장된 value. 잘못된 idx의 경우 ArrayIndexOutOfBoundsException |
| 스택 초기화 | stack.clear(); | 반환값 없음 |
큐(Queue)
선입선출(FIFO)의 성질을 가지는 자료구조. 먼저 들어간 데이터가 먼저 나오게 된다
- CPU 작업을 기다리는 프로세스, 너비우선 탐색, 캐시
- MQ(message queue)가 대표적
- 대규모 트래픽으로 인해 서비스 과부하가 발생했을 때, MQ를 사용하여 순차적으로 트래픽을 해결, 서비스 과부하 방지하는 장치
1. 시간 복잡도
- n번째 참조: O(n)
- 가장 앞 부분 참조: O(1)
- 탐색: O(n)
- 맨 뒤에 삽입/맨 앞에 삭제: O(1)
2. Java 큐(Queue) 관련 메서드 정리
- 선언
import java.util.Queue;
import java.util.LinkedList;
Queue<자료형> queue = new LinkedList<>();- 메서드
| 종류 | method | 반환값 |
|---|---|---|
| 삽입 | queue.add(value); | 삽입 성공 시 true, 실패시 exception |
| 삽입 | queue.offer(value); | 삽입 성공 시 true 실패 시 false |
| 삭제 | queue.remove(); | 삭제한 value. 빈 queue의 경우 NoSuchElementException |
| 삭제 | queue.remove(value); | value가 존재하고 지웠으면 true 존재하지 않으면 false |
| 삭제 | queue.poll(); | 삭제한 value. 빈 queue면 null 반환 |
| 맨앞원소 반환 | queue.element(); | 큐 head에 위치한 value, 빈 Queue 면 NoSuchElementException |
| 맨앞원소 반환 | queue.peek(); | 큐 head에 위치한 value, 빈 Queue 면 null 반환 |
| 큐 초기화 | queue.clear(); | 반환값 없음 |
| 크기 | queue.size(); | 큐에 저장된 value의 개수 |
| 빈 큐인지 확인 | queue.isEmpty(); | true/false |
| 특정 value 존재하는지 확인 | queue.contains(value); | true/false |
맵 (Map)
키 -값 pair로 이루어진, 삽입 될 때마다 자동 정렬되는 자료구조. 이진 탐색 트리의 일종인 레드 블랙 트리로 구현
1. 시간복잡도
- 참조, 탐색, 삽입, 삭제 모두 O(logn)
2. 특징
- 고유한 key값을 갖기에 중복된 key가 있을 수 없으며 key 값 기준으로 자동으로 오름차순 정렬되기에 넣은 순서대로 map을 탐색할 수 없음
- 키로 직접 값 참조가 가능
3. 예시
import java.util.HashMap;
import java.util.Map;
public class Main {
public static void main(String[] args) {
Map<String, Integer> mp = new HashMap<>();
String[] a = {"A", "B", "C"};
// map에 {key, value} 삽입
for (int i = 0; i < 3; i++) {
mp.put(a[i], i + 1);
}
System.out.println(mp.get("A"));
System.out.println(mp.size());
// key에 해당하는 요소 삭제
mp.remove("A");
// map에서 해당 key를 찾음
if (!mp.containsKey("zinna")) {
System.out.println("맵에서 해당 요소는 없습니다.");
}
// 대괄호[] 대신 put을 사용하여 삽입
mp.put("A", 100);
// map 순회
for (Map.Entry<String, Integer> entry : mp.entrySet()) {
System.out.println(entry.getKey() + " : " + entry.getValue());
}
// map의 모든 요소 제거
mp.clear();
System.out.println("map의 사이즈는 : " + mp.size() + "입니다.");
}
}셋 (Set)
고유한 요소만을 저장하는 자료구조로 중복을 허용하지 않음(중복되는 값은 제거됨), 값들이 자동 정렬됨)
1. 시간복잡도
- 참조, 삽입, 삭제, 탐색 모두 O(logn)
2. 예시
import java.util.Set;
import java.util.TreeSet;
public class Main {
public static void main(String[] args) {
Set<Integer> st2 = new TreeSet<>();
st2.add(2);
st2.add(1);
st2.add(2);
for (int it : st2) {
System.out.println(it);
}
// TreeSet 내림차순 정렬
TreeSet<Integer> Tset = new TreeSet<>(Collections.reverseOrder());
}
}3. Java HashSet과 TreeSet의 차이
| 비교기준 | HashSet | TreeSet |
|---|---|---|
| 내부 데이터 구조 | 해시테이블 사용. | 이진검색트리사용 -> 요소가 정렬된 순서 유지 |
| 정렬 | 정렬되지 않음 | 오름차순 정렬되거나, comparator에 따라 정렬됨 |
| 성능특성 | 평균적으로 O(1)이지만 해시 충돌이 많을 때 O(n) | O(logn) 균형잡힌 트리 구조이기 때문 |
| 사용사례 | 요소의 순서가 중요하지 않고, 빠른 삽입과 탐색이 필요할 때 | 요소들을 정렬된 순으로 유지해야 할 때 |

의견 나누는 것을 좋아합니다 ლ(・ヮ・ლ)