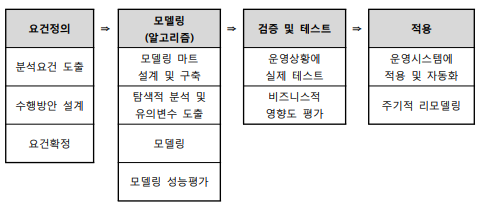
💡 데이터 분석 개요
◽ 데이터 분석 기법의 이해
-
데이터 분석에 대한 정의는 매우 다양하고 수준과 복잡성, 목적도 다르다.
-
분석은 일반적으로 조회와 고급분석으로 양분되며 고급분석은 20개 이상의 변수와 수천
건 이상의 데이터를 이용해 인사이트를 얻거나 의사결정을 하는데 직접 사용된다.
◽ 기초 지식과 소양
-
평균과 분산에 대한 이해를 토대로 집단 간 평균과 분산의 차이 , 상관관계, 독립/종속 변
수 를이용한 회귀분석 이해, R square와 p값에 대한 이해, 클러스터링(clustering) -
진정 필요한 추가 지식은 다양한 산업에 대한 이해다.
➡️ 상식수준에서 벗어난 해당 업계 신입사원 수준의 산업 분야 이해가 필요하다. -
평상시 관심을 갖고 업무와 관련지어 조금씩 늘 학습할 것 추천한다.
◽ 데이터 처리
데이터 분석은 통계를 기반으로 두고 있지만 통계지식과 복잡한 가정이 상대적으로 적은 실용적인 분야
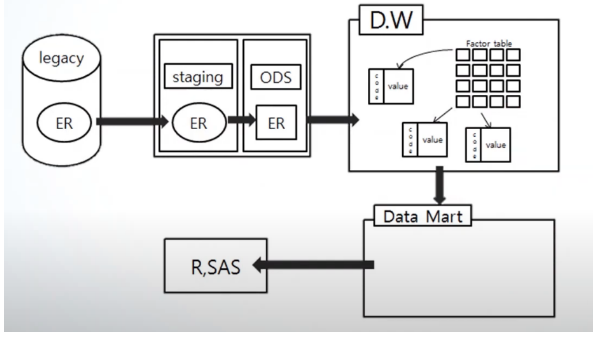
-
대기업들의 경우, 데이터웨어하우스[D.W] 와 데이터마트[D.M]을 구축해 분석 데이터를 가져와 사용한다.
-
IF) 신규시스템이나 D.W에 포함되지 못한 자료의 경우
Legacy, Staging Area, ODS에서 데이터를 가져와 D.W에서 가져온 내용과 결합 하여 활용할 수 있다.
❗ 단, 전처리 없이 D.W와바로 결합하지는 못한다.
➡️ Legacy에 직접 접근 해 데이터를 활용하는 것은 매우 위험 한 일이므로 거의사용 안한다.
➡️ Staging Area의 데이터는 운영시스템에서 임시로 저장된 데이터이므로 거의사용 안한다.
-
ODS의 데이터는 legacy의 데이터를 전처리 하여 정제된 데이터이므로 D.W나 D.M과 결합해 분석에 활용한다.
-
비정형데이터나 소셜데이터는 최종적으로 정형화된 패턴으로 처리한다.
-
기간계( 기존 운용시스템, legacy )
기간계를 통해서 모여드는 다양한 트랜잭션 데이터들을 매일 밤바다 배치작업(주로 야간에 한다)을 하며, DW로 넘기기 위한 작업 을한다.
-
스테이징영역( staging area )
임시 데이터들이 어떻게 저장 되었는지 확인하고 ODS로 넘긴다.
-
운영 데이터 저장소( ODS, Operational Data Store; 전처리구간 )
데이터들의 대한 품질을 테스트를 하고 테스트 결과로 미비한 점 은 cleansing 작업 을 하고 DW로 넘긴다.
-
Data Warehouse( DW )의 특징
-
한 번 쓰기하면
수정을 할 수 없다.(read only) -
테이블 형태로 쌓아둔다.
-
키, 값 형태로 저장한다.
-
-
Data Mart( DM )
-
DW의 데이터 테이블을 활용해서 분석에 필요로한 여러가지 유형들의 데이터들을 DM에 구성한다.
-
한 부서의 DW
-
목적에 의한 DW
-
-
분석 플랫폼
- R, SAS을 통해 최종 데이터 구조 로 가공하여 분석 업무를 실행 한다.
- 시물레이션 모델링 : 모델링에 적합한 단계별 처리시간 에 대한 분포를 파악할 수 있는 내용 과 유형, 그에 따른 특성을 속성으로 만든다.
- 최적화 : 목적함수 와 계수 값 을 프로세스별로 산출한다.
- 데이터마이닝 분류 : 분류값 과 입력 변수 들을 연관시켜, 인구통계, 요약변수, 파생변수 등을 산출
- 비정형 데이터 : 텍스트 마이닝 을 거쳐 데이터 마트 와 통합한다.
- 관계형 데이터 : 사회 신경망 분석 을 거쳐 통계값 이 데이터 마트 와 통합한다.
- R, SAS을 통해 최종 데이터 구조 로 가공하여 분석 업무를 실행 한다.
◽ 데이터 시각화
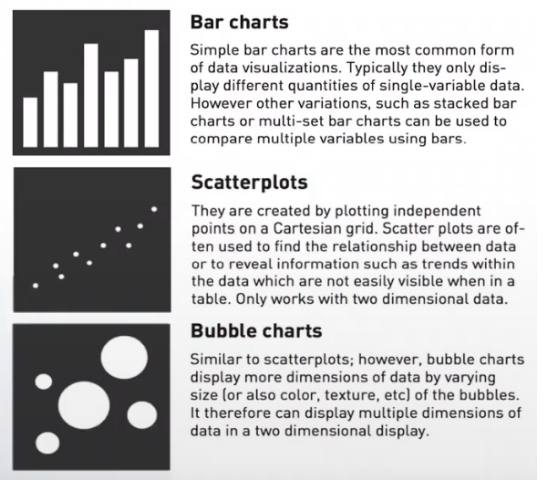
데이터분석 결과를 쉽게 이해할 수 있도록 다양한 시각화 도구를 활용해 효과적으로 결과를 전달하는 분석 방법이다.
-
시각화는 가장 낮은 수준의 분석이지만 잘 사용하면 복잡한 분석보다도 더 효율적 이다.
-
대용량 데이터를 다루는 빅데이터 분석에서 데이터 시각화는 필수 이다.
-
탐색적 자료분석(EDA)에서도 시각화는 필수이다.
탐색적 데이터 분석( EDA, Exploratory Data Analysis) ❓
✔ 대량의 데이터에서 다양한 차원과 값을 조합해 가며 특이점 이나 의미 있는 사실을 도출하고, 분석의 최종 목적을 달성해가는 과정
- SNA(사회연결망 분석)을 할 때 자주 활용된다.
◽ 공간분석[Spatial Analysis]
공간적인 차원과 관련된 속성들을 시각화하는 분석 방법
-
낮은 수준의 분석
-
지도 위에 관련 속성 들을 생성하고 크기, 모양, 선 굵기 등으로 구분하여 인사이트를 얻는다.
◽ 탐색적 자료분석[EDA, Explonatory Data Analysis]
데이터가 가지고 있는 특성 을 파악하기 위해 해당 변수의 분포 등을 시각화하여 분석하는 분석 방법
-
미국의 존 튜키교수가 1977년 발표한 저서에 EDA가 처음으로 언급했으며, 당시 주로 사용하던 확증적분석(CDA, Confirmatory Data Analysis)는 가설을 검증하는데 주로 사용되었지만 EDA는 자료를
하나의 목적으로 보지않고, 여러 방면으로 바라보기 위해 고안 되었다. -
다양한 차원과 값을 조합하여 특이한 점이나 의미있는 사실을 도출하고 분석의 최종 목적을 달성해가는 과정
-
매우 많은 시간과 자원이 필요하고 해결하려는 분야에 대한 지식, 사실 을 확보하는 단계
-
데이터의 특징과 내재하는 구조적 관계 를 알아내기 위한 기법들의 총칭이다.
-
함수를 적용하는 것이 아닌데이터 자체를 확인해서 데이터에 대한 전반적인 이해를 통해 분석 가능한 데이터인지 확인하는 단계 -
탐색적 데이터 분석을 통해 얻은 정보를 이용해 통계적 가설이나 모형을 설정해 연구하거나 의사결정에 이용해 정보의 정확도를 측정한다.
-
EDA의 4가지 주제
저항성 강조 저항적인 자료/분석은 자료의 일부 변동에 따른 영향을 비교적으로 적게 받는 것을 의미한다
즉,➡️ 이상치, 결측치, 입력 오류등의 영향을 적게 받는다.
ex) median, 사분위수, IQR 등잔차(오차) 계산 잔차(개별 관측값의 흐름에서 벗어난 값)가 있을 때 왜 이런 값이 발생했는지 파악하는 것
Residual Analysis[Regression Analysis] : 잔차분석[회귀분석]자료변수의 재표현 자료 분석을 단순화할 수 있도록 원래의 변수를 적당한 척도 로 바꾸는 것을 의미
ex) Z-score[표준점수] 등그래프를 통한 현시성 그래픽 표현을 통해 자료 안에 숨겨진 정보를 효율적으로 활용 할 수 있게 해준다.
현시성은 데이터 시각화라고도 불림
ex) 줄기와 잎 그림, Boxplot 등
◽ 통계분석
통계 ❓
어떤 현상을 종합적으로 한눈에 알아보기 쉽게 일정한 체계에 따라 숫자와 표, 그림의 형태로 나타낸 것
◾ 기술통계 (descriptive statistics)
- 모집단으로부터 표본을 추출하고, 표본이 가지고 있는 정보를 쉽게 파악할 수 있도록 데이터를 정리하거나 요약하기 위해 하나의 숫자 또는 그래프의 형태 로 표현하는 절차이다.
◾ 추측(추론)통계(inferential statistics)
- 모집단으로부터 추출된 표본의 표본통계량 으로 부터 모집단의 특성인 모수에 관해 통계적으로 추론하는 절차이다.
◾ 활용분야
-
정부의 경제정책수립과 평가의 근거자료로 활용(통계청의 실업률, 고용률, 물가지수 )
-
농업 : 재해에 강한 품종의 개발 및 개량
-
의학 : 임상실험의 결과 분석
-
경영 : 제품개발, 품질관리, 시장조사, 영업관리 등
-
스포츠 : 체질향상, 경기분석, 선수평가 등
◽ 데이터마이닝
대표적 고급분석 이며, 데이터에 있는 패턴을 파악해 예측하는 분석
-
대용량의 자료로부터 정보를 요약하고 미래에 대한 예측 을 목표로 자료에 존재하는 관계, 패턴, 규칙 등을 탐색하고, 이를 모형화 함으로써 이전에 알려지지 않은 유용한 지식을 추출하는 분석 방법 이다.
-
데이터가 크고 정보가 다양할수록 보다 활용하기 유리한 최신 기법
-
다양한 수학 알고리즘을 통해 데이터베이스의 데이터로부터 의미있는 정보를 찾아내는 방법
-
반드시 다양한 옵션을 부여하는 것이 아니라 충분한 시간 이 있을 때만 다양한 옵션을 줘서 시도한다.
-
성능에 너무 집착할 경우 분석 모델링의 주목적인 실무적용에 반해 시간을 낭비 할 수 있으므로 훈련 및 테스트 성능에 큰 편차가 없고 예상 성능을 만족하면 중단해야한다.
-
성능은 정확도(Accuracy), 정밀도(Precision), 디텍트 레이트(Detect rate), 리프트(Lift) 로 평가한다.
◽ 데이터마이닝 방법론
◾ 1) 데이터베이스에서의 지식탐색 (knowledge discovery in database)
- 데이터웨어하우스에서 데이터마트를 생성하면서 각 데이터들의 속성 을 사전분석 을 통해 지식을 얻는 방법이다.
◾ 2) 기계학습(machine learning)
- 인공지능의 한 분야로, 컴퓨터가 학습할 수 있도록 알고리즘과 기술을 개발하는 분야로 인공신경망, 의사결정나무, 클러스터링, 베이지안 분류, SVM 등이 있다.
◾ 3) 패턴인식(pattern recognition)
- 원자료를 이용해서 사전지식과 패턴에서 추출된 통계 정보를 기반으로 자료 또는 패턴 을 분류하는 방법으로 장바구니분석, 연관규칙 등이 있다.
◽ 시뮬레이션[Simulation]
-
복잡한 실제상황을 단순화해 컴퓨터상의 모델로 만들어 재현하거나 변경함으로써 현상을 보다 잘 이해하고 미래의 변화에 따른 결과를 예측하는데 사용하는 고급분석 기법
-
시뮬레이션 기법과 최적화 기법이 결합 되면서 규칙이나 조건을 정교화해 효과를 높인다.
-
과거에는 시뮬레이션 모델링을 위한 데이터 수집이 어려웠으나 빅데이터 시대가 도래함에 따라 모델링이 쉬워졌다.
-
시뮬레이션에서의 평가 기준
Throughput, Average Waiting Time, Average Queue Length, Time in System 등
◽ 최적화
-
오랜 역사 가진 고급 분석기법 으로 목적함수 값의 최대화/최소화를 목표로 한다.
-
제약조건 하에서 목표값을 개선하는 방식으로 목적함수 와 제약조건을 정의해 문제 해결
◽ 배포 및 운영
-
사용자가 개발된 데이터와 모델을 이용해 활용하는 환경도 구축해야 한다.
-
분석 및 마이닝 모델에 직접 접근 해 데이터를 조회하고 마이닝 결과를 적용해 결과를 조회할 수 있는 인터랙티브한 환경개발(RStudio Shiny)
본 게시물에 포함된 내용은 한국데이터산업진흥원에서 발행한]
[데이터 분석 전문가 가이드, 2019년 2월 8일 개정]에 근거한 것임을 밝힙니다.