💡 집계 함수(Aggregate Function)
집계 함수의 개요..
여러 행들의 그룹이 모여서 그룹 당, 단 하나의 결과를 돌려주는 다중행 함수중 하나
-
GROUP BY 절은 행들을 소그룹화 한다.
-
SELECT 절, HAVING 절, ORDER BY 절에 사용할 수 있다.
-
WHERE절에 사용하지 않는다.
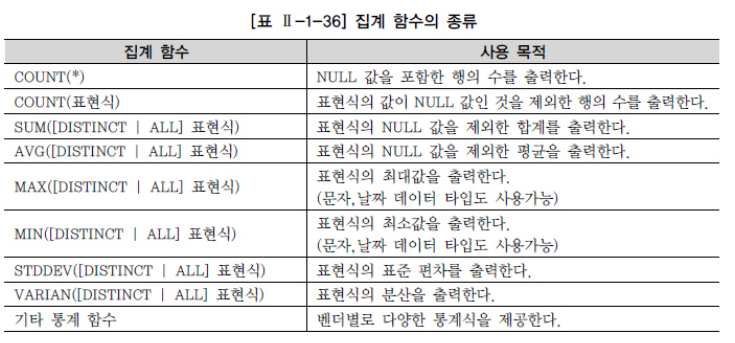
집계함수명([DISTINCT | ALL] 칼럼이나 표현식)
❗ COUNT(*) 는 NULL 값을 포함한 행의 수를 출력하는 것을 주의해야 한다.
❗ COUNT(표현식)은 NULL값인 것을 제외한 행의 수를 출력한다.
❗ GROUP BY절이 없으면 그룹핑 대상이 존재하지 않아 에러가 발생한다.
◽ GROUP BY절
WHERE 절을 통해 조건에 맞는 데이터를 조회하고나서, 2차 가공 정보가 필요할 수 있는데 이 때 GROUP BY 절을 사용한다.
GROUP BY 절은 SQL 문에서 FROM 절과, WHERE 절 뒤에 오며, 데이터들을 작은 그룹으로 분류하여 소그룹에 대한 항목별로 통계 정보를 얻을 때 추가로 사용된다.
즉 그룹핑 기준 을 설정 하는 것 이다.
SELECT [DISTINCT] 칼럼명 [ALIAS명] FROM 테이블명 [WHERE 조건식]
[GROUP BY 칼럼(Column)이나 표현식][HAVING 그룹조건식] ;
- SQL>>
SELECT POSITION 포지션, COUNT(*) 인원수, COUNT(HEIGHT) 키대상, MAX(HEIGHT) 최대키,
MIN(HEIGHT) 최소키, ROUND(AVG(HEIGHT),2) 평균키 FROM PLAYER GROUP BY POSITION;
K-리그 선수들의 포지션별 평균키는 어떻게 되는가?
◽ HAVING절
-
HAVING 절은 해석상 WHERE 절과 동일하다. 단 조건 내용에 그룹 함수를 포함하는 것만을 포함한다.
-
일반 조건은 WHERE 절에 기술하지만 그룹 함수를 포함한 조건은 HAVING 절에 기술한다.
-
GROUP BY절에 의한 집계 데이터에 출력 조건을 건다.
-
HAVING 절은 일반적으로 GROUP BY 절 뒤에 위치한다.
HAVING: GROUP BY절에 의한 집계 데이터에 출력 조건을 건다.
(↔ WHERE절은 SELECT절에 조건을 걸기 때문에 제외된 데이터가 GROUP BY 대상이 아님)
- SQL>>
SELECT POSITION 포지션, ROUND(AVG(HEIGHT),2) 평균키 FROM PLAYER
GROUP BY POSITION HAVING AVG(HEIGHT) >= 180;
HAVING 절을 이용해 평균키가 180 센티미터 이상인 정보만 표시
◽ CASE 표현을 활용한 월별 데이터 집계
집계 함수(CASE( ))~GROUP BY” 기능은, 모델링의 제1정규화로 인해 반복되는 칼럼의 경우
구분 칼럼을 두고 여러 개의 레코드로 만들어진 집합을, 정해진 칼럼 수만큼 확장해서 집계 보고서를 만드는 유용한 기법이다.
◽ 집계함수와 NULL 처리
리포트 출력 때 NULL이 아닌 0을 표시하고 싶은 경우에는 NVL(SUM(SAL),0)이나, ISNULL(SUM(SAL),0)처럼 전체 SUM의 결과가 NULL인 경우(대상 건수가 모두 NULL인 경우)에만 한 번 NVL/ISNULL함수를 사용하면 된다.
◽ ORDER BY절
-
ORDER BY 절은 SQL 문장으로 조회된 데이터들을 다양한 목적에 맞게 특정 컬럼을 기준으로 정렬하여 출력하는데 사용한다.
-
ORDER BY 절에 칼럼(Column)명 대신에 SELECT 절에서 사용한 ALIAS 명이나 칼럼 순서를 나타내는 정수도 사용 가능하다. 그러나 유지보수성이나 가독성이 떨어진다.
-
ORDER BY 절에서 칼럼명, 별명, 칼럼순서(정수)를 같이 혼용하는 것도 가능하다
-
기본적으로 오름차순 적용(ASC), 내림차순은 DESC
-
SQL 문장 맨 마지막 위치한다.
-
숫자형 데이터 타입은 오름차순으로 정렬했을 경우에 가장 작은 값부터 출력한다.
-
날짜형 데이터 타입은 오름차순 정렬했을 경우 날짜 값이 가장 빠른 값이 먼저 출력한다.
-
Oracle은 NULL 값을 가장 큰값으로 간주, 오름차순 정렬 시 가장 마지막에 위치, 내림차순은 가장 위
-
SQL Server는 NULL 값을 가장 작은값으로 간주, 오름차순 정렬 시 가장 상위에 위치한다.
-
SQL>>
SELECT PLAYER_NAME 선수명, POSITION 포지션, BACK_NO 백넘버 FROM PLAYER
WHERE BACK_NO IS NOT NULL ORDER BY PLAYER_NAME DESC;선수 테이블에서 선수들의 이름, 포지션, 백넘버를 출력하는데 사람 이름을 내림차순(DESC)으로 정렬하여 출력 키가 NULL인 데이터는 제외
▪ SELECT 문장 실행 순서

▪ Top N 쿼리
상위 n개의 데이터를 추출하는 쿼리
- SQL>>
SELECT TOP 1 item, cnt FROM sql_test_a ORDER BY item DESC, cnt DESC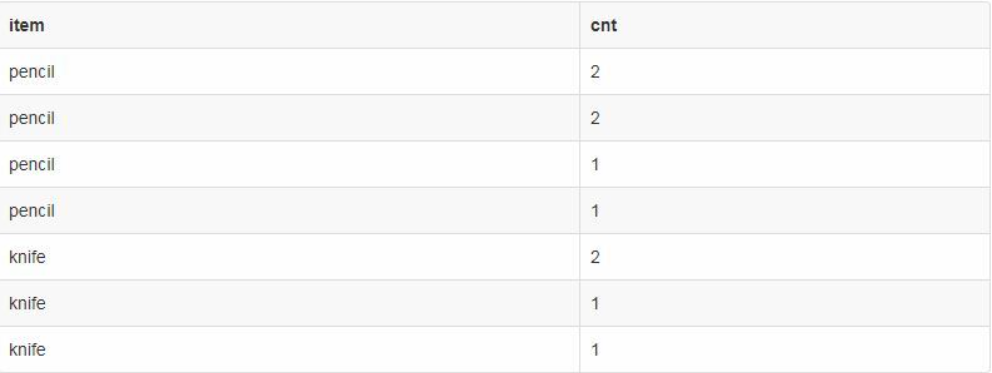
-원문-
-결과-
SELECT TOP(2) WITH TIES ENAME, SAL FROM EMP ORDER BY SAL DESC;사원 테이블에서 급여가 높은 2명을 내림차순으로 출력하는데 같은 급여를 받는 사원이 있으면 같이 출력.
- ❓ TOP WITH TIES
- TOP 과 동일하게 상위 N개의 데이터를 조회한다. 하지만 동일한 데이터가 있을 경우 함께 출력된다.
- TOP WITH TIES를 사용하기 위해서는 ORDER BY 절이 반드시 함께 와야 한다. (TOP의 경우 없어도 가능) 동일한 데이터는 ORDER BY절 뒤의 오는 컬럼이 기준이 된다.
- TOP 과 동일하게 상위 N개의 데이터를 조회한다. 하지만 동일한 데이터가 있을 경우 함께 출력된다.
