물리적 메모리 관리
주소 변환
- 프로세스가 논리적 주소 가짐
- CPU가 논리적 주소 줌
- 물리적 메모리 주소로 변환해서 메모리 참조
주소 변환에 있어서 운영체제의 역할
- 없음
- 다 하드웨어가 하고 있음
프로세스가 cpu를 가지고 메모리 접근을 하는 것은
운영체제의 도움을 전혀 받지 않음
주소 변환은 무조건 하드웨어적으로 이루어짐
메모리 접근시 운영체제 역할 없음
어떤 프로세스가 cpu를 가지고 메모리 접근을 하는데 주소변환을 할 때마다
운영체제가 중간에 개입을 해야한다고 하면
CPU가 이 프로세스로부터 운영체제로 넘어가야함
넘어갔다가 다시 프로세스로 와야 함 말이 안됨
cpu
프로세스 -> 운영체제
운영체제 -> 프로세스
말이 안됨
I/O 장치 접근
- 운영체제 역할 필요
- disk 접근 등
Paging
-
하나의 프로세스가 사용하는 메모리 공간이 연속적이어야 한다는 제약을 없애는 메모리 관리 방법
-
Process의 Virtual Memory를 동일한 사이즈의 page 단위로 나눔
-
Virtual Memory의 내용이 Page 단위로 noncontiguous 하게 저장됨
-
일부는 backing Storage에 일부는 physical memory에 저장
Basic Method
- 물리 주소를 동일한 크기의 frame로 나눔
- 논리 메모리를 동일 크기의 page로 나눔
- 모든 가용 프레임들을 관리
- 페이지 테이블을 사용하여 논리주소를 물리주소로 변환
- 외부 단편화 발생 안함
- 내부 단편화 발생 가능 -> 프로그램의 크기가 반드시 페이지크기의 배수가 된다는 보장이 없기때문임.
프로그램들을 물리메모리에 올려놓을 때, 빈공간 없이 효율적으로 메모리를 올리는 방법
1. 페이징 기법
2. 세그먼테이션 기법
1. Paging(페이징) 기법
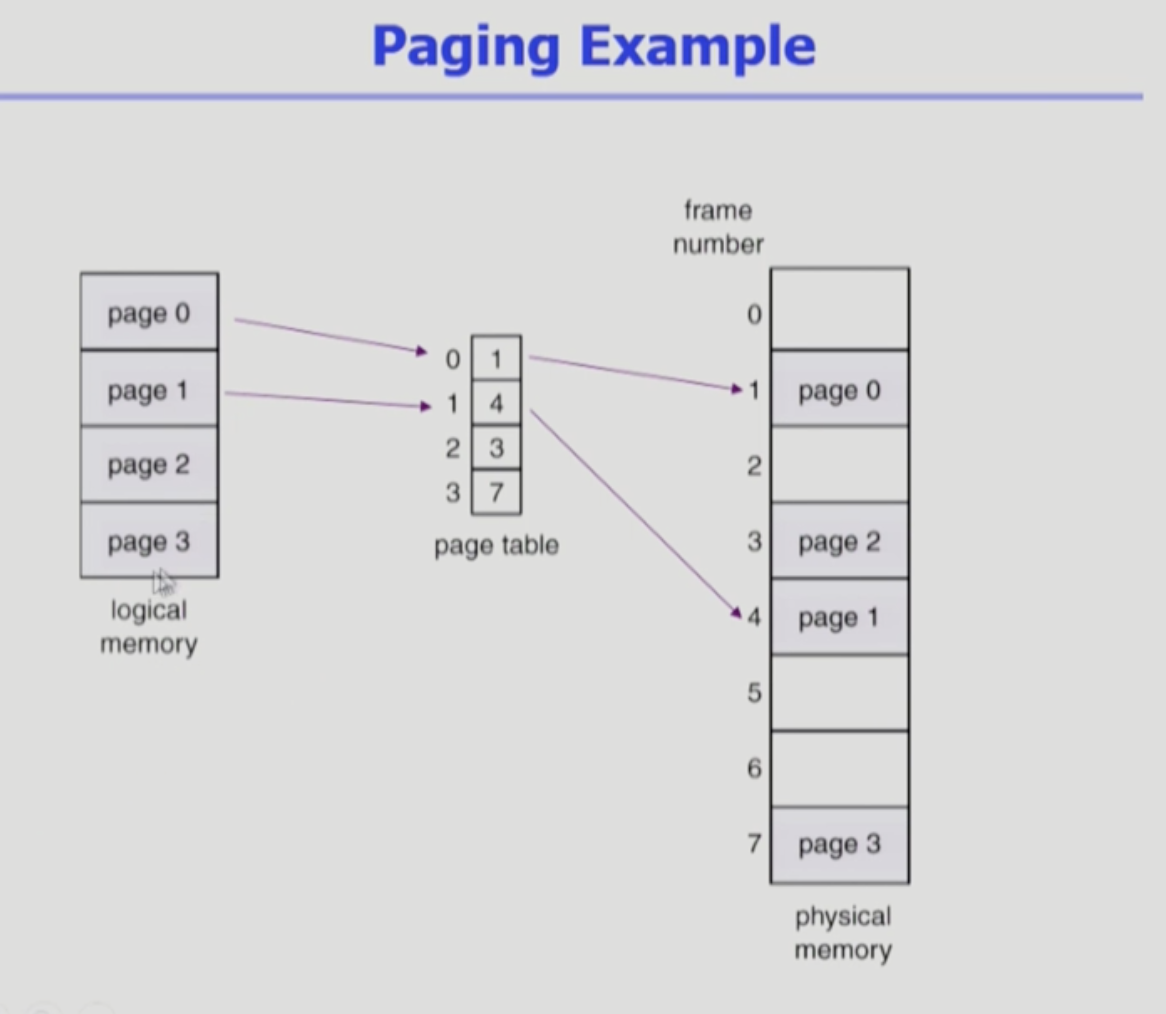
- (프로세스가 차지하는 물리적 메모리 공간) 불연속 메모리 관리 기법
- 페이지 별로 물리메모리 위에 어디에 위치하는지 주소변환이 필요함.
- 주소변환을 위해 page table(페이지 테이블)이 사용됨.
- page table : 배열. 인덱스로 접근.
- ex) 0번 페이지는 1번 페이지 프레임에 올려져 있다
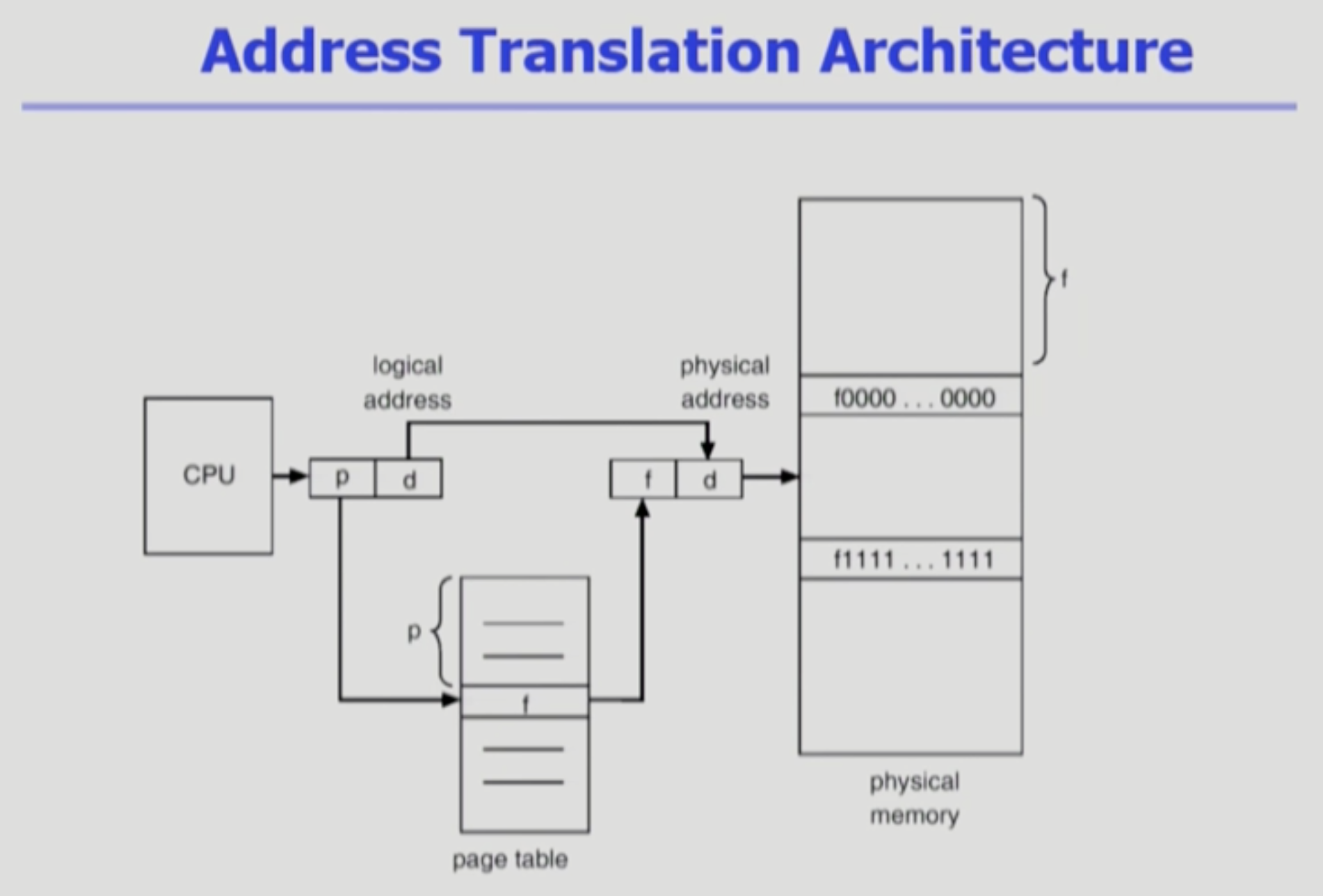
주소변환 아키텍쳐

- CPU가 페이지 테이블한테 논리주소를 준다. (p는 페이지 번호가되고, d는 얼마나 떨어져있는지 offset이 됨.)
- p로 페이지 테이블에서 f라는 페이지프레임 번호를 얻어냄.
- 논리적 주소 p를 f로 바꾸어주면 물리주소로 변환이 되는것임!
- d는 상대적 주소 = offset
페이지 테이블은 어디에 저장되어야 하나??
- 기존 MMU에서는 레지스터 2개로 주소변환
- 페이지 크기는 보통 4KB 인데, 페이지 테이블은 100만개의 공간정도가 필요
그렇담 이 100만개의 entry가 CPU의 레지스터 같은데에 들어갈 수 있겠나? 못들어감
페이지 테이블 용량 엄청 큼. 프로그램 별로 페이지 테이블이 필요
하드디스크에 넣기도 그렇고, 캐시에 들어가기도 너무 용량크고. 그래서 페이지 테이블을 메모리에 집어넣음. - 물리메모리에 접근하기 위해선, 페이지 테이블이 있는 메모리에 한번 접근하고, 그다음 원래 접근하려던 메모리에 접근하기 때문에 모든 메모리 접근 연산에는 2번의 메모리 엑세스가 필요함
페이지 테이블 구현하기

- 페이지 테이블은 main memory (RAM) 에 상주.
- 앞서 MMU에서 봤던 base register, limit register가 사용됨
- Page-table base register(PTBR)가 페이지 테이블을 가리킴
- Page-table length register(PTLR)가 테이블 크기를 보관
- 모든 메모리 접근 연산에는 2번의 메모리 엑세스가 필요. ( 페이지테이블 접근 1번, 실제 데이터 접근 1번 )
=> 2번 접근하면 느림! - 속도 향상을 위해
associative register로 구성되는 translation look-aside buffer(TLB) 라 불리는 고속의 일종의 하드웨어 캐시 임.
- 캐시 : CPU랑 메모리 사이에있는 고속의 저장소.
2. TLB (translation look-aside buffer)
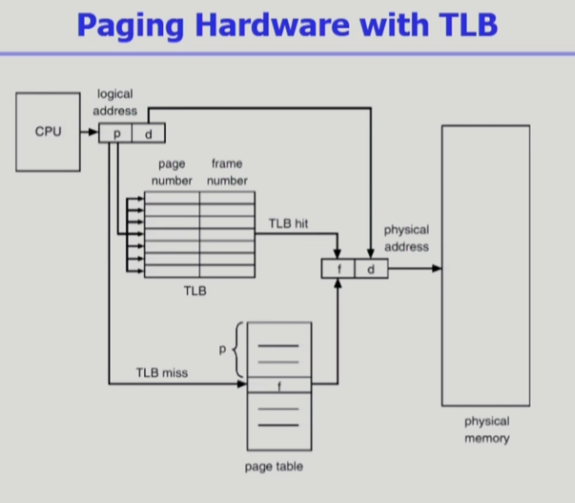
-
일종의 캐시
-
TLB는 최근에 일어난 가상 메모리 주소와 물리 주소의 변환 테이블을 저장하기 때문에 일종의 주소 변환 캐시라고 할 수 있다.
-
주소변환을 위해 캐시메모리 같이 접근 속도가 훨씬 빠른 공간이 필요해서 TLB라는것을 두었음.
( 데이터를 보관하는 캐시 메모리와는 용도가 좀 다름. 오로지 주소변환을 위한 캐시 메모리 같은것. ) -
TLB는 페이지 테이블에서 빈번하게 참조되는 entry를 캐싱하고 있습니다.
(전부 저장하고 있지는 않음, 자주 참조되는 몇개만. 메인 메모리보다 접근 속도가 훨씬 빠름)
그래서 메모리상의 페이지 테이블을 먼저 보기전에 TLB를 먼저 봅니다. -
TLB의 정보를 통해 주소변환이 가능한지? 보고 가능하면 바로 주소변환이 이루어져 물리적 메모리에 접근가능 / 메모리에 한 번만 접근 가능
-
TLB에 없는경우엔 페이지테이블에 접근해서 일반적인 주소변환을 하면 된다.
-
TLB거쳐서 주소변환하면 f(프레임 번호) 얻음.
-
TLB에도 p(페이지 번호)와 f(프레임 번호)를 쌍으로 가지고 있음. => 이것이 페이지 테이블과의 차이점!!
-
TLB에서 p가 있는지 없는지 검사하기 위해서는 전체를 다 봐야함
( TLB는 page table처럼 인덱스로 찾는게 아니라서~ ) -
전체를 다 탐색하는것을 막기위해서 Associative register를 이용해서 parallel search(병렬적으로 탐색)가 가능하도록 해두었음.
-
TLB는 컨테스트 스위치때 flush해서 한번 비움. ( 프로그램마다 p - f 값이 다를꺼니까 )
메모리 접근시간 계산

TLB에 접근하는 시간 = e (입실론, 1보다 매우 작은 값)
메인메모리 접근하는 시간 = 1
TLB로부터 주소변환되는 비율을 a (1에 가까움)
- Hit ratio = a
Effective Access Time (EAT) = (e+1)a + (e+2)(1-a) = 2+e-a
= (TLB접근+메모리접근)TLB에서 주소변환되는 만큼 + (TLB접근+메모리접근2번(페이지테이블, 원래찾으려는 메모리) TLB에서 주소변환안되는 만큼 - hit : TLB가 있는 경우
- miss : TLB가 없는 경우
- TLB 사용하지 않는 (memory access 두 번) 2 보다는 빠르다는 것을 알 수 있음
- 1 + e
3. Two-Level Page Table
이단계 페이지 테이블을 왜 쓸까?
컴퓨터에서의 목적 2가지밖에 더 있겠나?
-
속도를 빠르게 하던지
-
메모리 공간을 덜 쓰던지
-
페이지 테이블 2번 참조하기 때문에 속도는 더 걸림.
-
페이지 테이블을 위한 공간이 줄어드는 것

- 32bit 사용시 : 4GB 의 주소공간을 페이지 하나의 크기인 (4KB)로 나눠보면 => 1M(백만)개의 page table entry 가 나온다.
- page table에는 1M(백만)개의 entry가 있고 하나의 크기는 4B(32bit)가 된다.
=> 그래서 보통 페이지 테이블 하나에 4MB 정도 된다. - 이 페이지 테이블도 결국에 메모리에 들어가는거라고 했고, 각 프로그램마다 페이지 테이블도 따로 있는데 공간 낭비가 너무 심해짐
=> 그래서 2단계 페이지 테이블을 쓰겠다는 것!
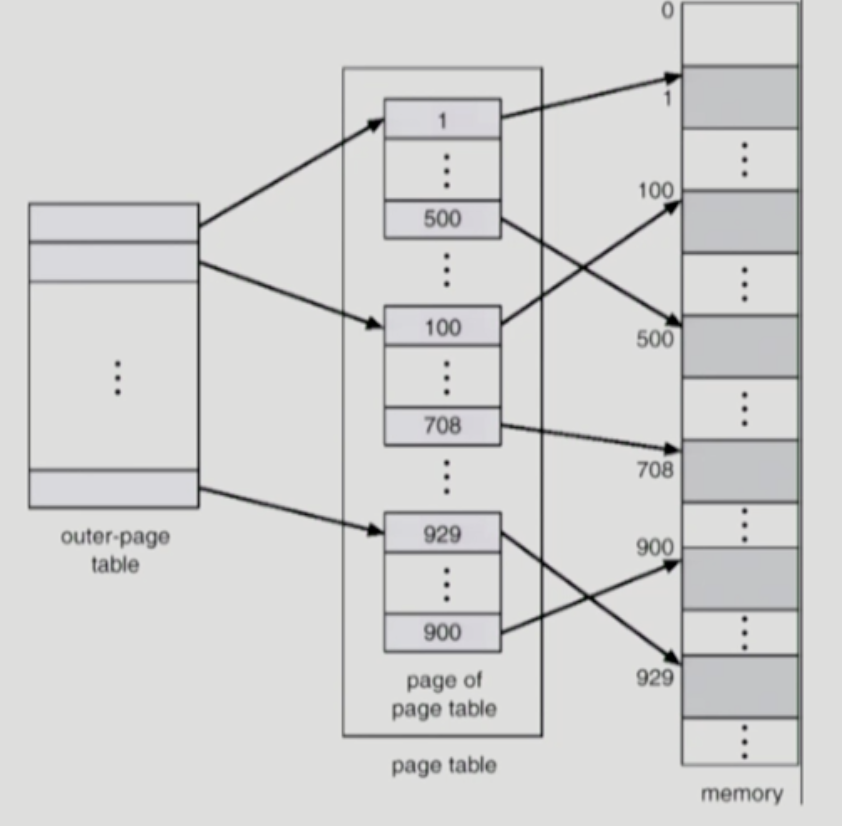

- inner page table 하나의 크기는 페이지 하나와 크기가 동일 : 4KB
- 안쪽 테이블 entry 크기 하나당 : 32bit (=4B) -> 적어도 1k개 존재
안쪽 테이블이 페이지화 돼서 들어간다.
4. Two-Level Paging Example

몇 bit 로 표현되어야 하는지 알아본다.
logical address (32-bit CPU에서 하나의 페이지 크기 4KB)
- 20bit의 page number
- 12bit의 page offset
page table 자체가 하나의 page로 구성되기 때문에, page number는 다음과 같이 나뉜다.
( 각 page entry가 4B(=32bit) )
-
10bit의 page number
-
10bit의 page offset
-
따라서, logical address는 다음과 같다.

-
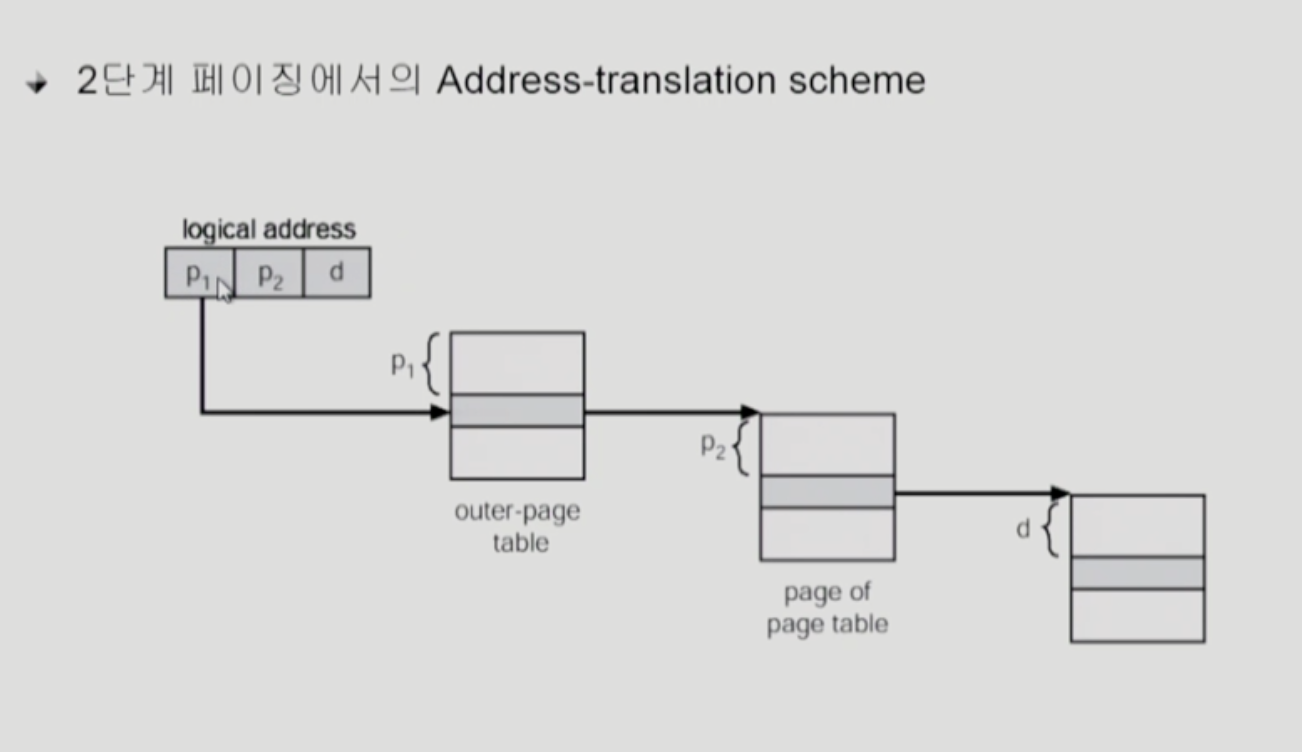
P1은 outer page table의 index
-
P2는 outer page table의 page에서의 변위 (displacement)
-
offset
- 페이지 안에서 바이트 단위로 얼마나 떨어져 있는지 구분
- 페이지 내에서 원하는 위치를 알려줌
- 12 bit 필요
- 서로 다른 4K 군데를 구분해야함
- 2의 12승 byte를 구분하기 위해 12 bit가 필요 (4KB)
(10000채의 집을 구면하려면 10진수 4자리 필요 0~9999)
정리
전체가 32bit (4G)
페이지 크기 하나 4KB (=2^12)
- offset 12 bit
- (페이지 내에서 위치를 알려줌)
- page 내부를 구분하기 위해서는 2^12 개의 bit가 필요
p2
페이지(4KB)에 들어가는 엔트리(4B)는 1K개 (2^10) -> 최대 크기 / 전체 사이즈 크기
- outer page table의 page에서의 엔트리 최대 개수
- page table은 1K개의 entry를 가지고 있으므로 page table을 구분하기 위한 bit 수는 2^10 개
p1 - outer page table의 index
[참고]
안쪽 page table (page of page table)은 원래의 page table (outer-page table)의 entry 1개를 각각 다시 page로 나눠 논 page table들을 가지고 있는 table이다. 즉 안쪽 page table 1개는 바깥쪽 table의 page 크기인 4KB의 크기를 갖게 된다. 또한 안쪽 page table 역시 entry의 크기는 4B일 것이므로 table 당 1K(1000)개의 entry를 가지게 된다.
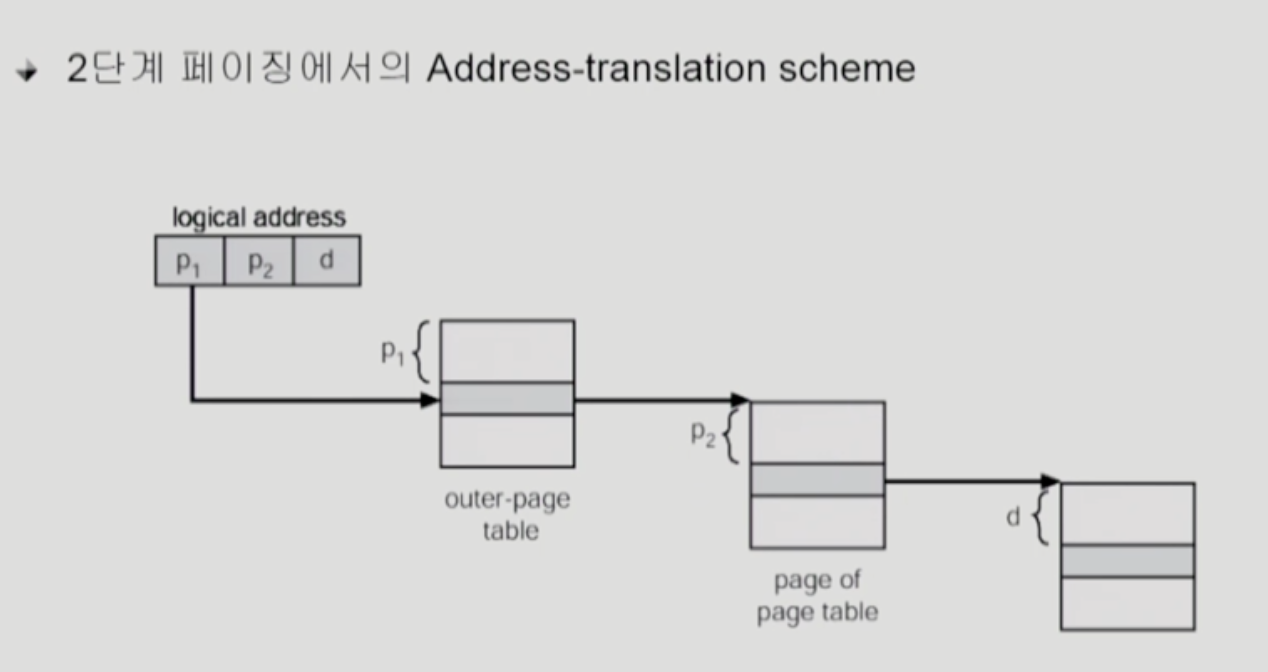
Address-Translation Scheme
-
P1은 outer page table의 index
-
P2는 outer page table의 page에서의 변위 (displacement)
-
offset
- 위에서 부터 몇번째 엔트리인지 구분
- 서로 다른 4K 군데를 구분해야함
-
안쪽 페이지 테이블 하나에 entry 1K(2^10) 개를 넣을 수 있음
1K의 엔트리 위치를 구분하기 위해 p2는 10bit 가 필요
왜냐면 1K는 2의 10승
P1은 32bit에서 -12 -10 해서 자동으로 나머지 10bit임. -
64bit 주소체계를 쓴다고 했을땐? P1,P2,d 몇비트가 필요할까? 생각해보기!
-> 주소공간 (16엑사..)
-> 페이지 하나의 크기는 (4KB) 라고 가정. => 4페타 개의 엔트리.
-> page offset => 12bit(페이지 크기에 연관된거라서 32bit, 64bit주소체계랑은 관련X)
-> 4KB안에 8B짜리 엔트리 -> 1/2K => 512개(2^9) => 9bit임....
/43bit/9bit/12bit
Two-Level Page Table
- 시간, 공간적(바깥쪽 테이블, 안쪽테이블)으로 손해
사용 이유
과거
- 프로그램을 구성하는 공간 중에서 상당 부분 사용이 안됨
- page table로 만들 때는 인덱스 방식을 사용했기 때문에 사용되지 않는 중간의 공간들의 엔트리를 안 만들 수가 없다.
K번째 엔트리를 주소 변화 하려면 다 있어야 함 - Maximum logical 메모리의 수만큼 page table이 만들어져야 함
Two-Level Page Table 사용함으로써 해결
- 바깥쪽 page table 전체 logical memory 크기 만큼 생성
- 안쪽 page table 에서는 실제로 사용이 안되는 주소는 안 만들어짐
- 포인터가 null 상태, 사용되는 메모리 영역만 만들어서 주소를 가리킴
- 얼마나 사용이 안되면 Two-Level Page Table 이 훨씬 공간 아낄 수 있나?
요약
- page table의 공간을 줄일 수 있음
- 전체 주소 공간 중 상당 부분 실제로 사용 안 됨
- 사용되지 않는 안쪽 페이지 테이블이 만들어지지 않기 때문
20 강
Multilevel Paging and Performance
- Address space 가 더 커지면 다단계 페이지 테이블 필요
- 각 단계의 페이지 테이블이 메모리에 존재하므로, logical address 의 physical address 변환에 더 많은 메모리 접근 필요
- TLB 를 통해 메모리 접근 시간을 줄일 수 있음 (바로 메모리 접근 가능)
- 4단계 페이지 테이블을 사용하는 경우
- 메모리 접근 시간이 100ns, TLB 접근 시간이 20ns 이고,
- TLB hit ratio 가 98% 인 경우
Effective memory access time = 0.98 x 120(TLB확인 20 + 실제 접근 100) + 0.02 x 520(페이지테이블 확인 400 + TLB확인 20 + 실제 접근 100) = 128ns
결과적으로 주소변환을 위해 28ns 만 소요 (100은 접근시간)
Valid (v) / Invalid (i) Bit in a Page Table
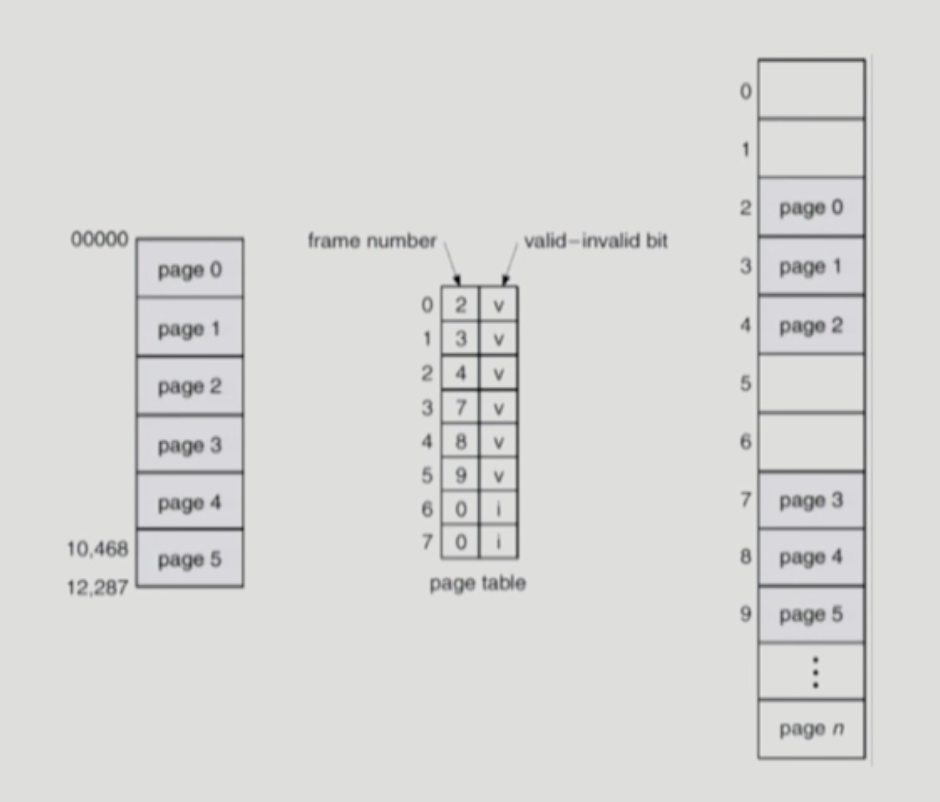
page table entry 개수
- 프로그램의 주소공간이 가질 수 있는 Maximum 사이즈 만큼 있어야 함
- 테이블이라는 자료구조상 인덱스를 통해 접근해야하기 때문
valid (v)
- 0번 페이지가 2번 frame에 올라와 있다.
invalid (i) - 사용이 되지 않는 것
- swap area에 내려가 있다.
Memory Protection

Protection bit
- 어떤 연산에 대한 접근 권한이 있는지 (read/write/read-only)
Inverted Page Table
공간 오버헤드 막아보자

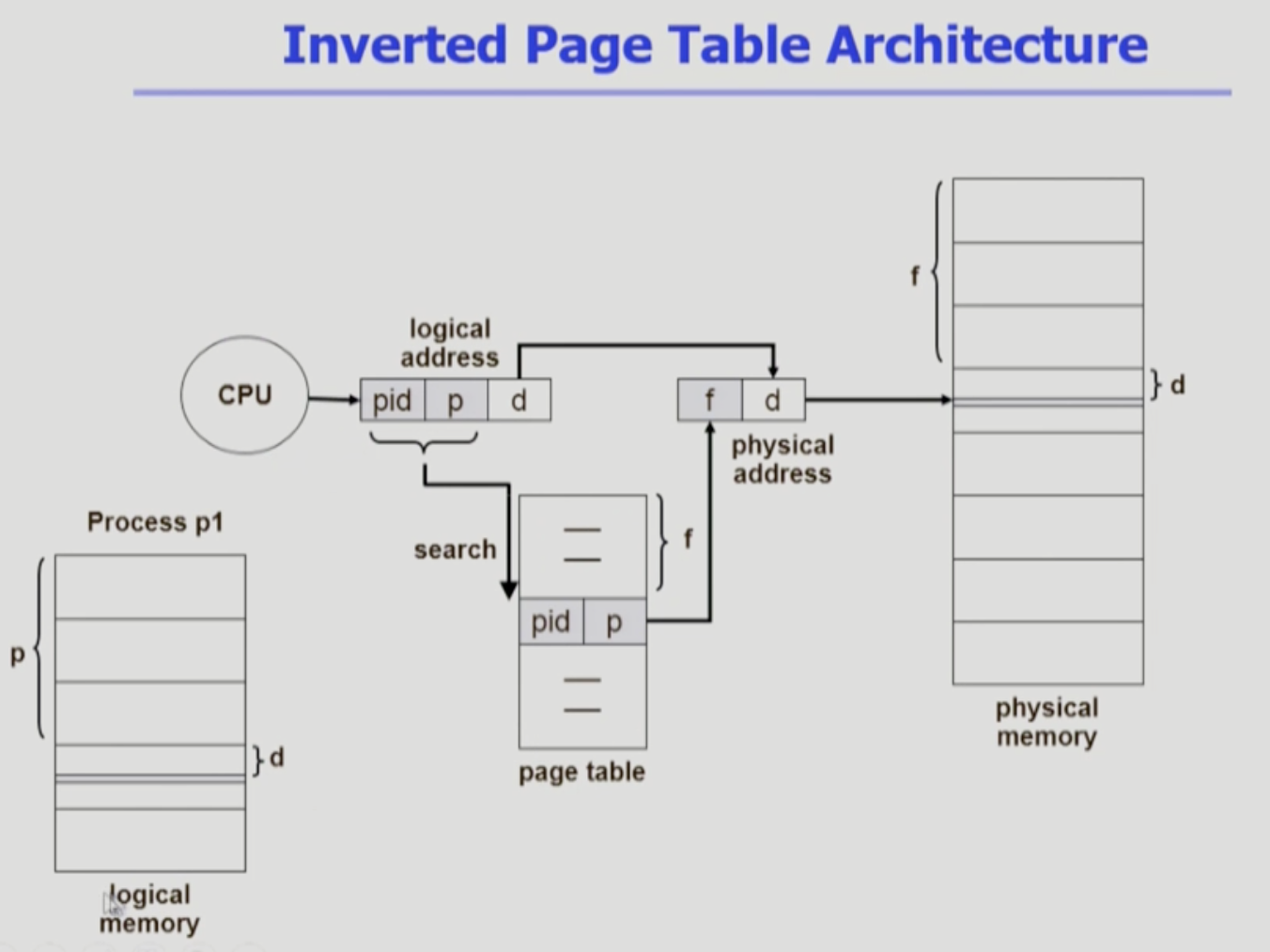
physical memory의 page frame 개수만큼 page table 존재
주소 변환 방법
- 논리 주소(p)로 물리 주소 알아내야함
- f 번째에 올라와 있음
Inverted Page Table
- page table entry를 전체 검색해야함
- 공간 낭비를 줄임
cpu -> logical address 가짐 -> pid, p를 page table에서 찾기
-> 찾으면 위에서 몇번째인지 본다 (f) -> physical memory f 에 올린다.
해결
associated register 에 넣어서 탐색하면 순차검색의 타임 오버헤드 줄일 수 있음
Shared Pages Example
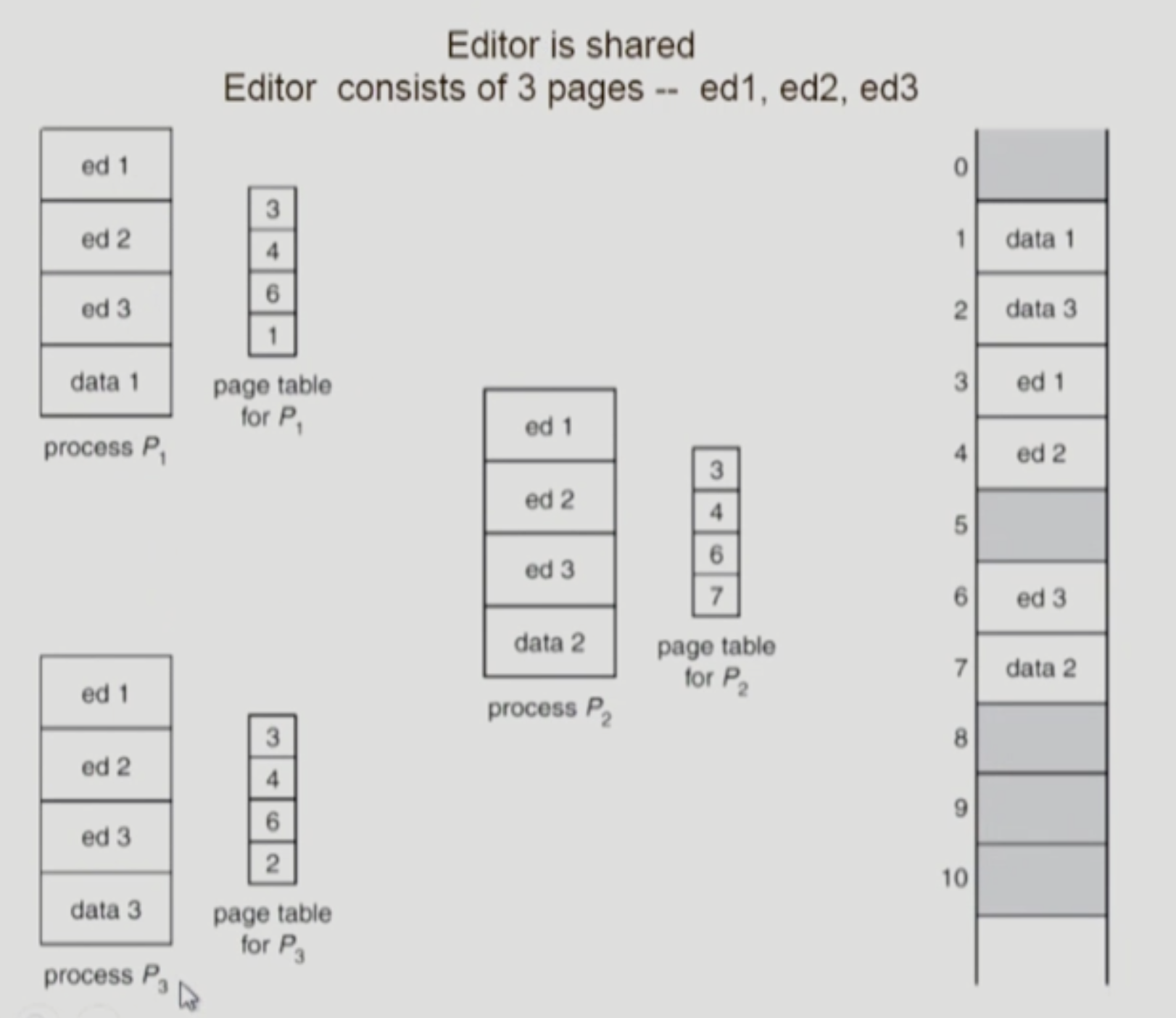
한글 3개 띄웠다고 가정
공유하는 부분은 한 개만 물리적 메모리에 올리기
Shared Page

제약 조건
- 항상 동일한 logical address를 가져야 한다
21강
Segmentation
segmentation
- 프로세스를 구성하는 주소 공간을 의미 단위로 쪼갠 것
paging
- 프로세스를 구성하는 주소 공간을 같은 단위로 쪼갠 것

Segmentation Architecture

-
cpu가 논리 주소 줌 -> s,d -> s만큼 떨어진 entry에 간다. -> 어떤 번지에 들어가 있는지 안다
-
segment 크기가 균일하지 않음 (allocation 문제 생김)
-
의미 단위로 작업을 수행하는 경우 유리 (공유, 보안에 효과적)
STBR
- segment table 이 있는 위치
STLR - 프로그램이 사용하는 segment 수
s < STLR -> trap 발생 시키기
(s : 레지스터 번호)
Segmentation Hardware
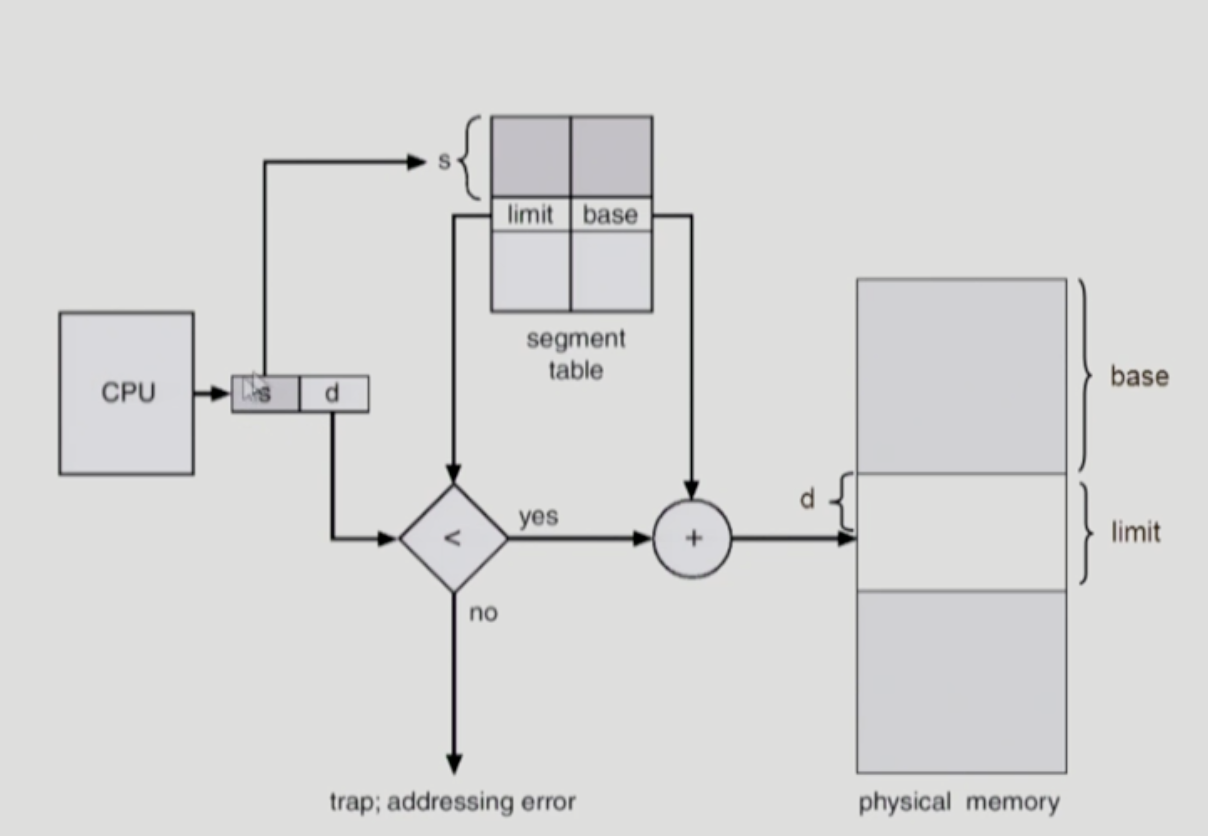
테이블 entry
- limit
- segment의 길이
- base
- 물리적인 메모리의 세그먼트 시작 위치
- d (offset)
- 얼만큼 떨어져 있는가
주소 변환 가능
base + d
segment
- 크기가 균일하지 않음
Example of Segmentation
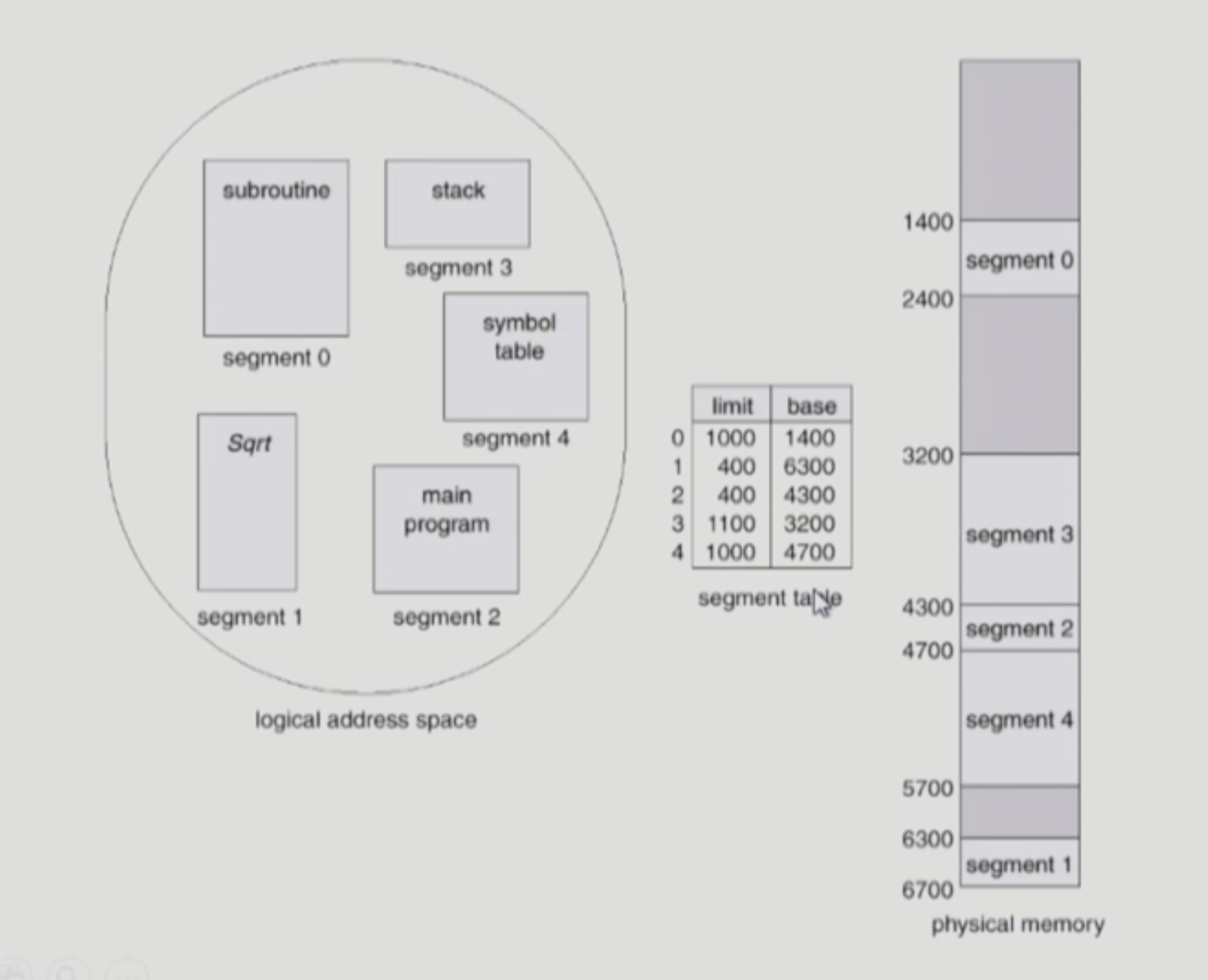
Segmentation Architecture

segmentation
- 개수가 적음
- 낭비가 적음 (테이블을 위한 메모리 낭비 관점에서)
- hole이 생긴다.
- allocation 문제
- 의미 단위의 일에 유리
paging
- 개수가 많음
- 조각이 많이 생기기 때문에 테이블을 위한 메모리 공간 낭비가 심한 쪽은 paging
- 물리적인 조각이 생기지 않는다. -> 같은 크기로 나누기 때문
- 비어있는 공간이면 언제든 사용 가능
Sharing of Segments
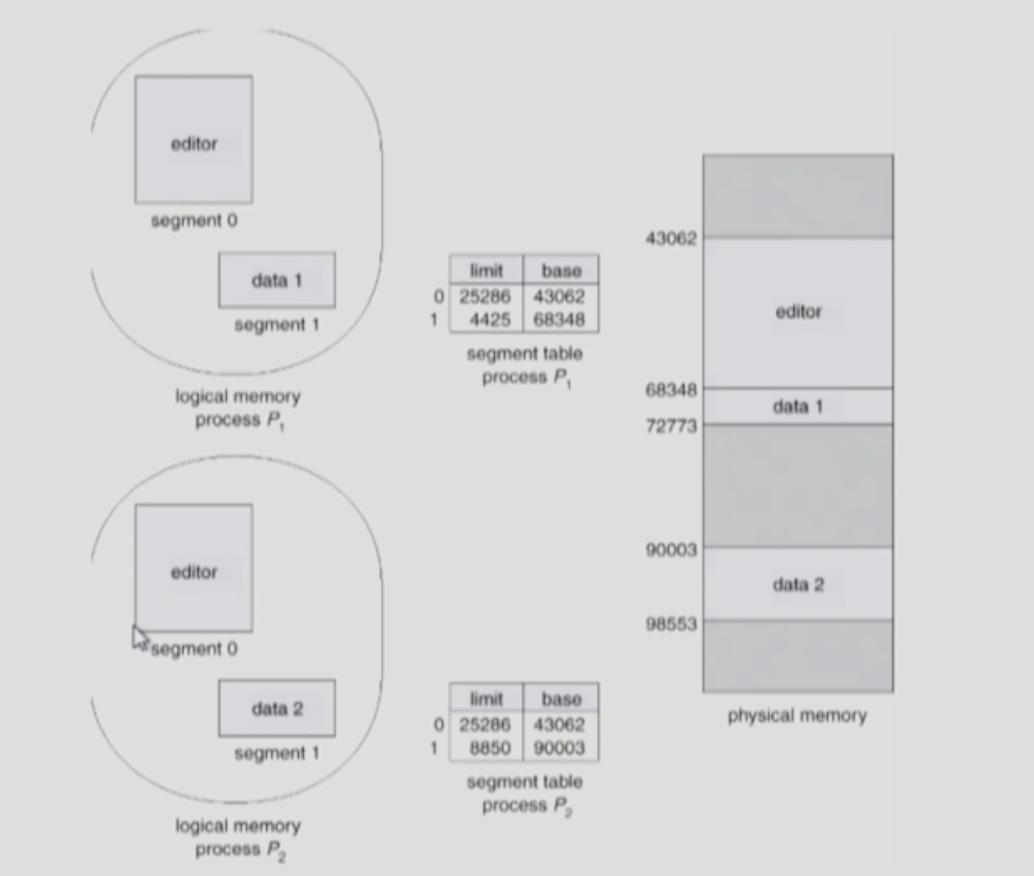
같은 논리적 주소상에 있어야 함
segment 번호가 같아야 함
ex) segment 0 43062
private segment
ex) segment 1 주소가 다르다
Segmentation with Paging
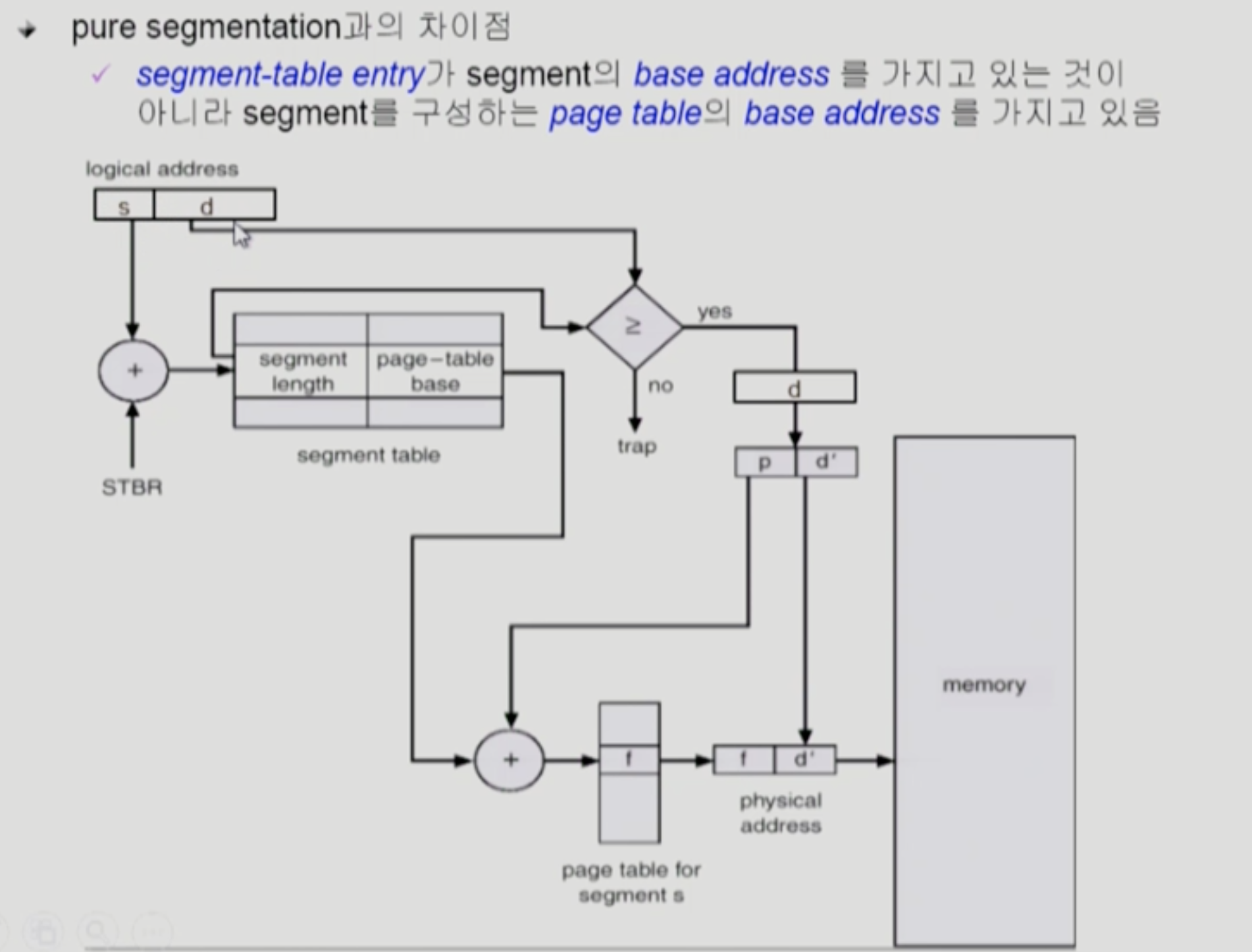
segment 하나가 여러 개의 page로 구성
- hole이 생기지 않는다.
- 물리적 메모리에는 page 단위로 올라감
주소 변환 두 단계
1. segmentation 주소 변환
-
각각의 page 별로 주소 변환
-
segment 당 page table 존재
-
page table base : page table 시작 위치
-
segment length : page table에 몇 개의 entry가 있는지
s + d
- 논리적 메모리의 주소
d <= segment length -> True
d : segment 안에서 떨어진 offset 값
2. page 주소 변환
segment offset (d) 를 자른다.
- p : 페이지 번호
- d' : 페이지 안에서 offset (얼마나 떨어져 있는지)
page table base (시작 위치) + p(page 번호) -> f (물리적 메모리의 frame 번호)
f + d'
- 물리적 메모리의 주소
현실에서 메모리 관리시 segment 따로만 사용되지 않음
STBR : 시작 위치
