자료구조
1. Collection
: 순서나 집합적인 데이터의 저장 공간
1-1. List
: 순서가 있는 데이터 (인덱스가 있음)
✔ add(x) : T타입의 객체인 x를 추가한다. ✔ clear() : 해당 ArrayList가 가지고 있는 원소를 모두 제거한다. ✔ contains(x) : <boolean> 해당 ArrayList가 객체 x를 원소로 가지고 있는지의 여부를 반환한다. indexOf(x) > -1과 동일하다. ✔ get(x) : <T> 해당 ArrayList가 가지는 원소의 순번 중 정수 x에 해당하는 T타입의 객체를 반환한다. ✔ indexOf(x) : <int> 해당 ArrayList가 가지는 원소 중 전달된 T타입 객체 x와 동일한 첫번째 원소의 순번(인덱스)을 반환한다. 동일한 원소가 없다면 -1을 반환한다. isEmpty() : <boolean> 해당 ArrayList가 원소를 가지고 있지 않는가에 대한 여부를 반환한다. size() == 0과 동일하다. lastIndexOf(x) : <int> 해당 ArrayList가 가지는 원소 중 전달된 T타입 객체 x와 동일한 마지막 원소의 순번(인덱스)을 반환한다. 동일한 원소가 없다면 -1을 반환한다. ✔ remove(x) : 해당 ArrayList가 가지는 원소 중 전달된 int타입에 대한 순번에 해당하는 원소를 제거한다. ✔ remove(x) : 해당 ArrayList가 가지는 원소 중 전달된 T타입의 객체와 동일한 첫번째 원소를 제거한다. ✔ set(x, y) : 해당 ArrayList가 가지는 원소 중 전달된 int타입에 대한 순번에 해당하는 원소를 T타입의 객체 y로 치환한다. ✔ size() : 해당 ArrayList가 가지는 원소의 개수를 반환한다. sort(Comparator) : 해당 ArrayList가 가지는 원소들에 대해 전달된 Comparator 방식으로 정렬한다. - Comparator.naturalOrder() : 오름차순에 대한 Comparator를 반환한다. - Comparator.reverseOrder() : 내림차순에 대한 Comparator를 반환한다. toArray() : <Object[]> 해당 ArrayList가 가지는 원소에 대한 Object 배열을 반환한다. toArray(new T[0]) : <T[]> 해당 ArrayList가 가지는 원소에 대한 T타입의 배열을 반환한다. <T>stream() : <Stream<T>> 해당 List에 대해 Stream API를 사용하기 위한 객체를 반환한다.
1-1-1. ArrayList<T>
: 동기화(Synchronization)를 보장하지 않는 리스트
- 추가 / 삭제에 대한 시간 복잡도는 O(n)
- 조회에 대한 시간 복잡도는 O(1)
1-1-2. Vector<T>
: 동기화를 보장하는 리스트
- ArrayList 쓰는거랑 동일하다.
사용법은 동일한데 ArrayList<T> Vector<T> 이 두개를 왜 나누어서 정의하고 있을까?
❗️ 멀티스레딩이 되냐 안되냐의 차이이다.
자바에서 작업을 할 때는 한 군데에서만 작업을 할 수 있는데 멀티스레딩을 하면 여러 군데에서 작업이 가능해진다.
만약static ArrayList<?>이러한 ArrayList 정적인 객체가 있다면
ArrayList는 메인스레드가 이 객체에 접근해서 작업을 하고 있을 때 다른 T1 이라는 스레드가 와서 동시에 작업이 가능하다.
예로 들어 메인스레드가 회원탈퇴를 시키고 있는데 T1이 와서 다른 작업을 한다고 했을 때 T1은 다른 작업을 진행하고 있지만 메인스레드가 회원탈퇴 시키는걸 모르고 있기 때문에 동기화를 보장하지 않는다고 한다. (동기화를 시키지 않음)
반면에
static Vector<?>이러한 Vector 정적인 객체가 있다면 메인스레드 작업이 완료 될떄까지 다른 스레드는 대기를 하게 한다. 즉, 접근을 하지 못하게 함으로 동기화를 보장하게 되는 것이다.
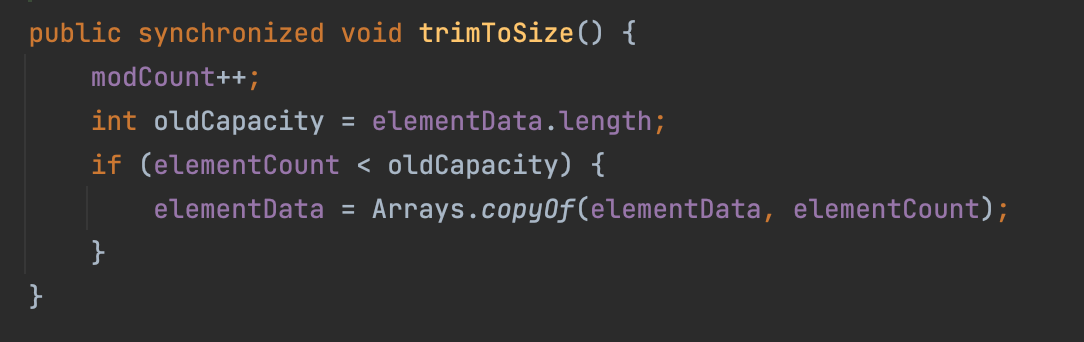
- Vector가 가진 메서드를 보면 메서드에
synchronized가 붙어있는데 synchronized가 붙으면 한번에 여러가지 작업을 못하게 하는 것을 의미한다.
1-1-3. Stack<T>
: LIFO(Last In First Out). 재귀적 호출이 필요한 경우 사용하는 리스트
- 기본적으로 Stack은 동기화를 보장한다.
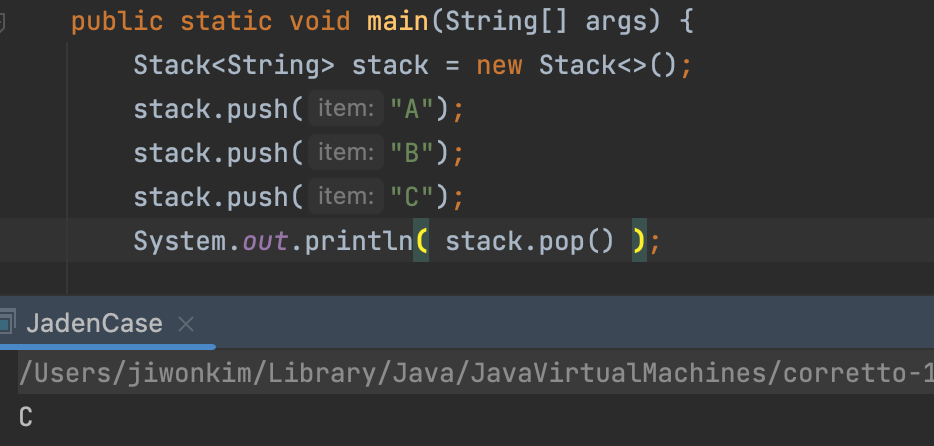
peeck() : 해당 Stack에 있는 원소 중 가장 마지막으로 push된 원소를 반환한다. pop() : 해당 Stack에 원소를 빼온다. push(x) : 해당 Stack에 원소를 추가한다.
- Stack의 특징은 pop을 하면 마지막에 넣은 애를 뺴온다.
1-1-4. LinkedList<T>
:
ArrayList<T>및Vector<T>와 유사하나 원소(노드, Node)의 접근 방법이 일반 배열이 아니고, 각 원소로 하여금 뒤의 원소에 대한 정보를 가지게하여 특정 작업에서의 속도가 보다 유리하다.
쉽게 말하여 일반 배열이 아니며 첫번째 자리에 있는 친구 스스로가 자기 다음이 누군지를 알고 있다는 것이다.
ArrayList<T>보다 추가 / 삭제가 월등히 빠르다. 단, 반복을 통한(특히 순번(인덱스)) 반복 및 조회에는 상당히 취약하다.- 추가 / 삭제에 대한 시작 복잡도는 O(1)
- 조회에 대한 시간 복잡도는 O(n) : n번 행동을 한다는 의미
- "C"라는 문자열을 추가할때 String의 인덱스 길이가 늘어나게 된다. ArrayList라고 해서 아무런 과정없이 들어가는 것은 아니다. LinkedList 또한 차례를 거쳐서 들어가게 된다.
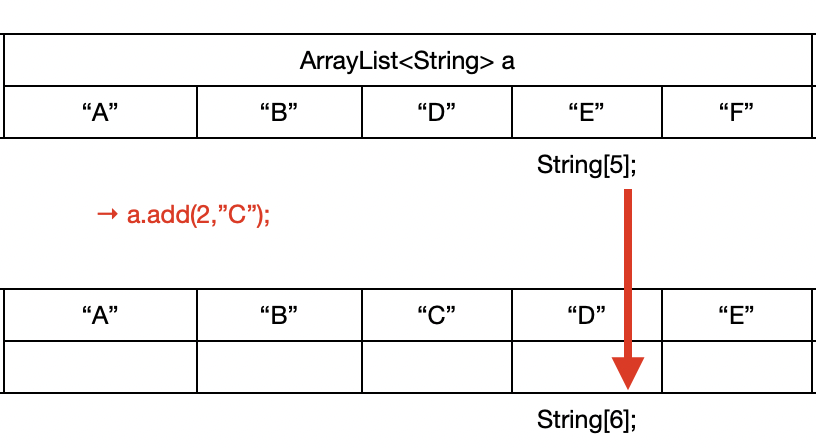
B에게 너 다음번 친구는 D가 아닌 C가 될거라는 것을 알려주고 C에게 너 다음이 D라는 것을 알려줌으로써 추가가 되는 것이다.
LinkedList가 조회에 가장 취약한 이유는 C가 어디있냐 라고 조회를 할 때 바로 그 자리로 가서 찾아 내는 것이 아니라 누구 다음, 누구 다음에 있는지에 대한 여부로 판단한다.
0번째부터 하나 하나 싹 훝여서 찾기 때문에 조회에는 취약한 것이다.
1-2. Set
: 순서가 없는 데이터(집합적, 인덱스가 없음)
1-2-1. HashSet<T>
: 원소들을 비교할 때
equals()가 아닌hashCode()로 비교한다.add(x) : <boolean> 해당 HashSet에 T타입의 객체 x를 추가한다. 단, 이미 존재한다면 추가하지 않음. - 추가를 했다면 true를, 안(못)했다면 false를 반환한다. clear() : 해당 HashSet이 가진 원소를 모두 제거한다. clone() : <HashSet<T>> 해당 HashSet이 가진 원소를 복사하여 새로운 HashSet을 반환한다. 단, 원소는 얕은 복사(Shallow Copy) contains(x) : <boolean> 해당 HashSet이 전달된 T타입 객체 x를 가지고 있는지의 여부를 반환한다. remove(x) : <boolean> 해당 HashSet에서 전달된 T타입 객체 x와 동일한 원소를 제거한다. - 무언가 제거를 했다면 true를, 제거한게 없다면 false를 반환한다. size() : <int> 해당 HashSet이 가지고 있는 원소의 개수를 반환한다. iterator() : <Iterator<T>> 해당 HashSet이 가지고 있는 원소들을 반복(Iterator) - 각 원소를 반복할 때 Interator 말고 향상된 for문으로도 사용할 수 있다.
add 할 때 이미 존재한다면 추가를 하지 않는다. 어떻게 비교를 해서 존재하는지 안하는지 알 수 있을까?
"A" → ["A"] 똑같은 걸 추가하려고 한다면 hashCode로 비교해서 같으면 add하지 않는다.
HashSet은 순서가 없기 때문에 특정한 순서에 있는 것을 뽑아오지 못하는데 그럴 때 사용하는 것이 iterator()이다.
- HashSet에 존재하는
size라는 메서드를 이용해서 for문을 돌릴 수 는 있지만 인덱스를 이용해서 뽑을 수 없다. = ArrayList의 get같은게 안된다.
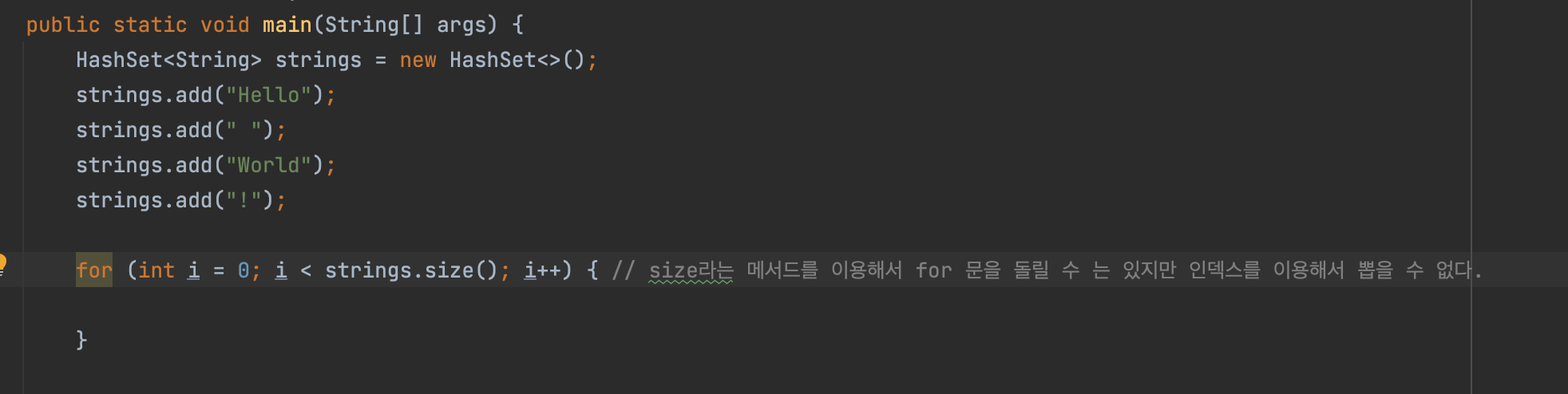
- 이러한 과정을 거쳐야지만 뽑아낼 수 있다.
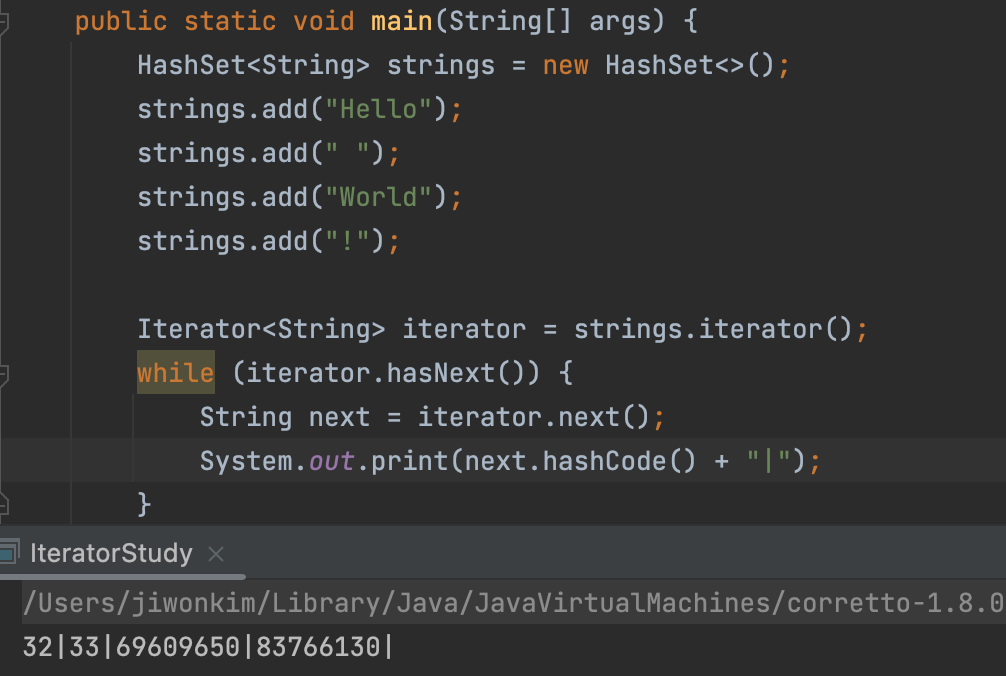
- 순서가 뒤죽박죽으로 나와서 hashCode를 찍어봤더니 hashCode가 가장 적은 순서부터 출력이 된다.
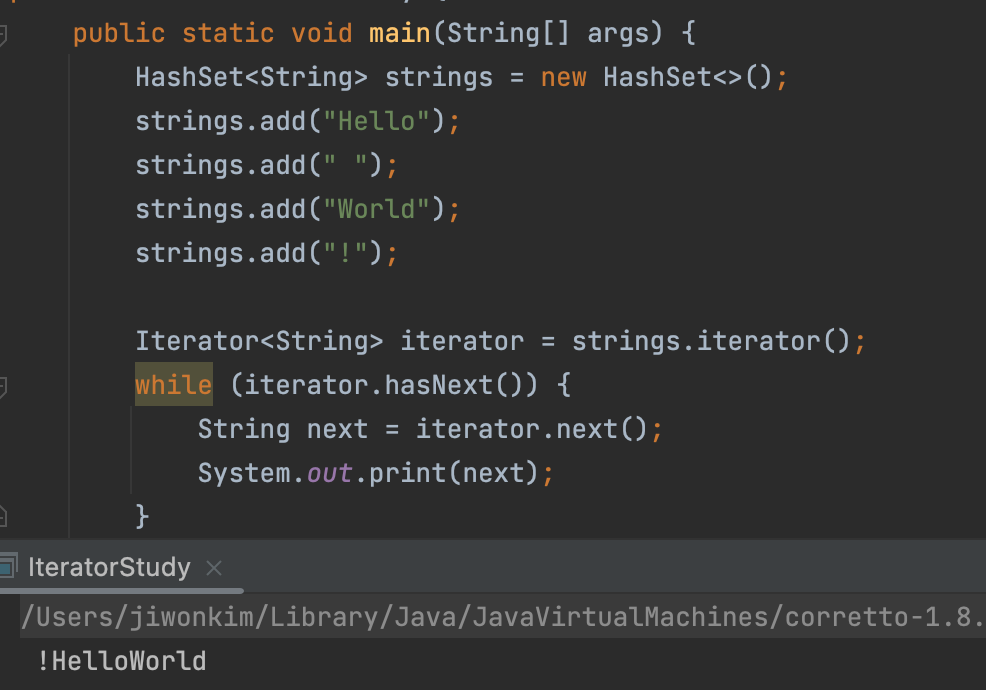
- 향상된 for문을 사용해도 똑같은 결과가 나오는 것을 볼 수 있다.
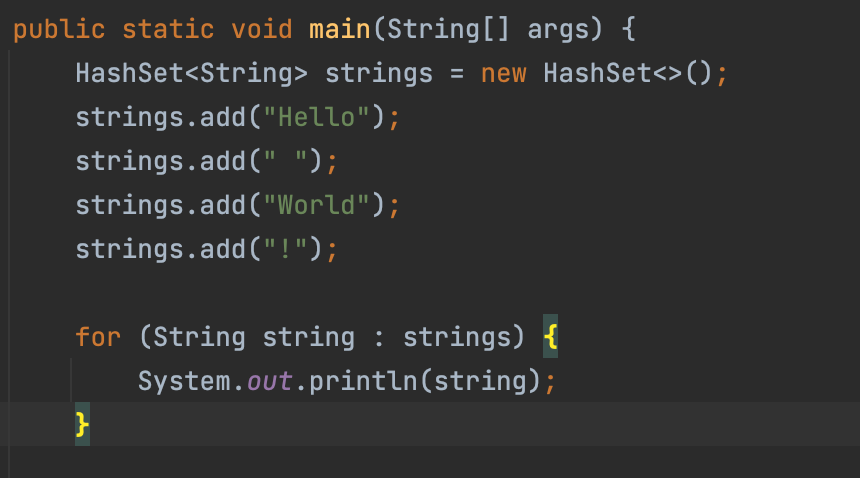
1-2-2. SortedSet<T>
: 정렬이 유의미한 값들에 대한 Set이다.
1-2-2-1. TreeSet<T>
: 이진 탐색 트리(Binary Search Tree) 구조로 레드-블랙-트리(Red-Black-Tree) 기법을 활용하여 값을 추가하며 시간 복잡도가 낮다. 최대 O(n/2)
- 프로그램이 어떠한 알고리즘을 통해 정렬을 해주는 것일까?
TreeSet을 사용하지 않고~.add(8);추가를 하려면 하나를 추가할 때마다 다 비교해야한다. 만일 숫자가 백만개라면 백만개를 세어 비교하여 추가해야한다. 그래서 나온게 TreeSet이다.
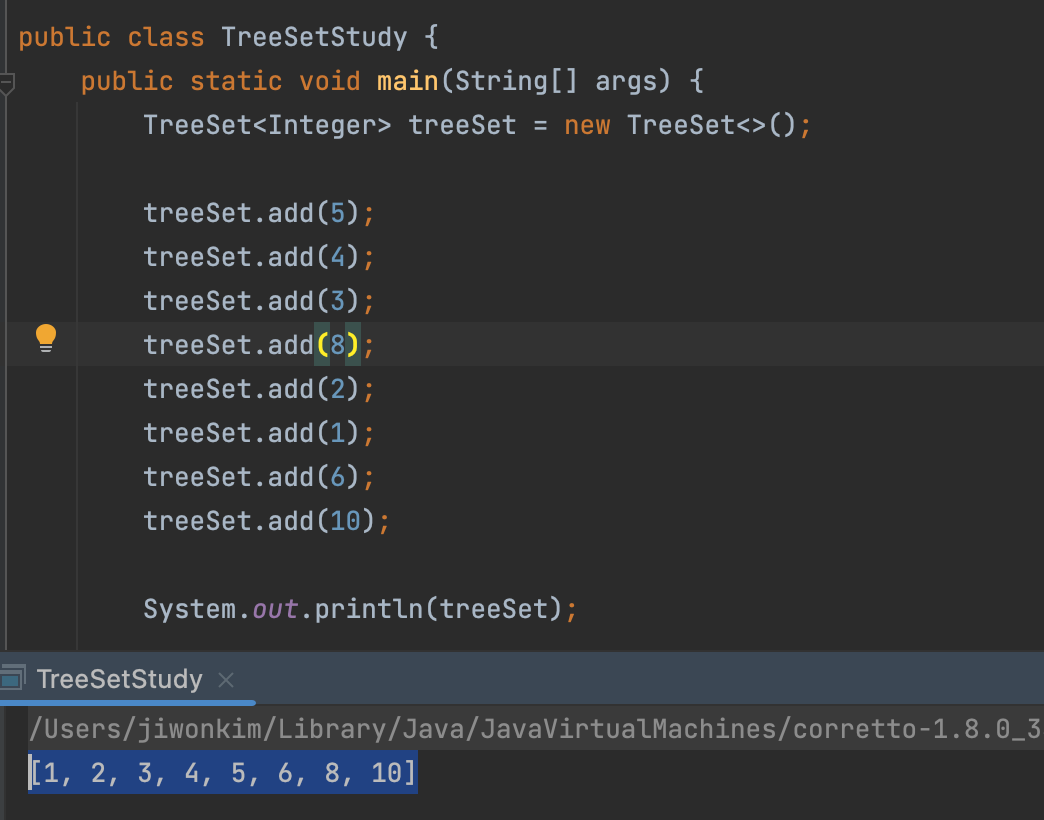
처음부터 따져보도록 해보자.
태초에는 아무것도 없으니treeSet.add(5);을 그냥 추가한다.
다음 추가하는treeSet.add(4);는 좌우로 큰지 작은지 비교하여 5보다 작으니 왼쪽에 추가한다. (트리형태로 추가)
쭉...가다가treeSet.add(8);을 만나면 5보다 크기 때문에 오른쪽에 추가가 된다.treeSet.add(10);이라면 비교를 2번 (5보다 큰지 작은지 + 8보다 큰지 작은지)만 하는 꼴이 된다. 몇번 비교하지 않았는데도 정렬이 잘 되기 때문에 속도가 아주 빠르다.
2. Map
: 키와 값 쌍(Key-Value Pair) 으로 이루어진 데이터의 저장 공간
✔︎ clear() : 해당 Map이 가지는 모든 쌍을 제거한다. ✔︎ containsKey(K) : <boolean> 해당 Map이 전달된 K타입의 객체를 키로 가지는 쌍이 있는지의 여부를 반환한다. containsValue(V) : <boolean> 해당 Map이 전달된 V타입의 객체를 값으로 가지는 쌍이 있는지의 여부를 반환한다. ✔︎ entrySet() : <Set<Map.Entry<K, V>>> 해당 Map이 가지는 키와 값에 대한 쌍을 Map.Entry 타입을 제네릭으로 하는 Set을 반환한다. 키와 값 쌍을 반복해야할 때 사용한다. ✔︎ get(K) : <V> 해당 Map에서 K타입 객체를 키로 가지는 쌍의 V타입 값을 반환한다. - 없다면 null을 반환한다. getOrDefault(K, V) : <V> 해당 Map에서 전달 받은 K타입 객체를 키로 가지는 쌍이 있다면 그 쌍의 값을, 없다면 전달 받은 V타입 객체를 반환한다. 여기서 전달인자 V를 null로 지정하면 그냥 get과 같음. isEmpty() : <boolean> 해당 Map이 쌍을 가지고있지 않은가의 여부를 반환한다. ✔︎ keySet() : <Set<K>> 해당 Map이 가지는 쌍들의 키를 Set으로 반환한다. ✔︎ put(K, V) : <V> K타입 객체를 키로, V타입 객체를 값으로 가지는 쌍을 추가한다. - Map이 가지는 키는 중복될 수 없음으로 만약 이미 존재하는 키에 대한 쌍을 put했다면 기존에 존재하는 키-값 쌍에서 값을 새로운 V타입 객체로 지정한 뒤 기존의 값을 반환한다. 만약 기존에 키-값 쌍이 없었다면 null을 반환한다. putIfAbsentK, V) : <V> 해당 Map이 가지는 쌍 중 전달 받은 K타입의 객체를 키로하는 쌍이 없다면 put하고 null을 반환하지만 이미 존재한다면 해당 쌍의 값을 반환하고 추가는 하지 않는다. ✔︎ remove(K) : <V> 해당 Map이 가지는 쌍 중 전달된 K타입 객체를 키로 가지는 쌍이 있다면 제거하고 이의 값을 반환한다. - 없다면 null을 반환한다. replaca(K, V) : <V> 해당 Map에서 전달된 K타입 객체를 키로 가지는 쌍이 있다면 그 쌍의 값을 전달된 V타입 객체로 대체한 뒤 기존의 값을 반환한다. - 만약 그러한 쌍이 없다면 null을 반환하며 추가하지도 않는다. ✔︎ size() : <int> 해당 Map이 가지는 쌍의 개수를 반환한다. ✔︎ values() : <Collection<V>> 해당 Map이 가지는 쌍들의 값을 Collection으로 반환한다.
2-1. HashMap<K, V>
: 키와 값쌍(Key-Value Pair) 으로 이루어져있다.
- 동기화를 보장하지 않는다.
2-2. HashTable<K, V>
: HashMap<K, V>와 같으나 동기화를 보장한다.
2-3. SortedMap<K, V>
: 키 값에 대한 정렬이 유의미한 쌍들에 대한 Map이다.
2-3-1. TreeMap<K, V>
: 키에 대해 이진 탐색 트리(Binary Search Tree)구조로 레드-블랙-트리(Red-Black-Tree) 기법을 활용하여 값을 추가하며 시간 복잡도가 낮다. 최대 O(n/2)
- 대체할게 없음으로 null이 뜬다. 똑같은 Key를 가지는 값을 추가하지 못한다.
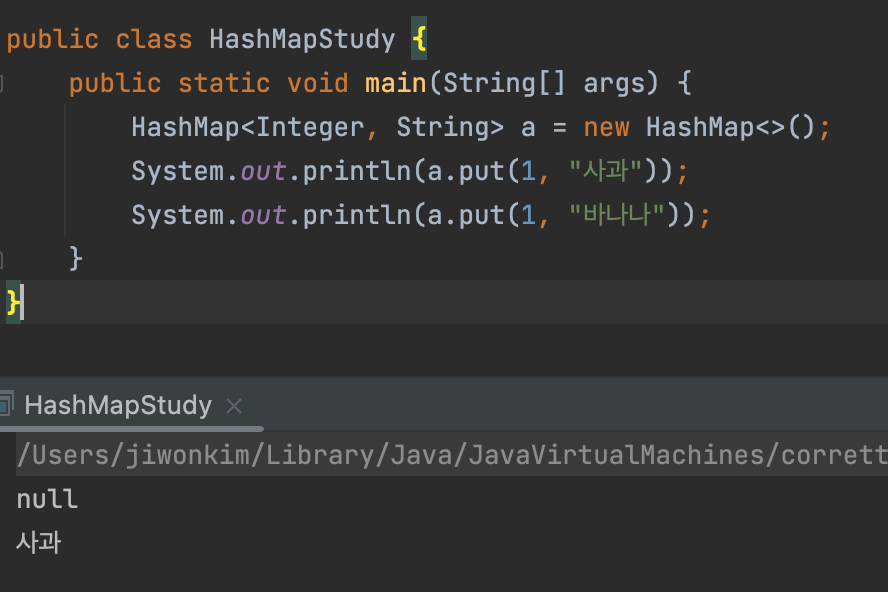
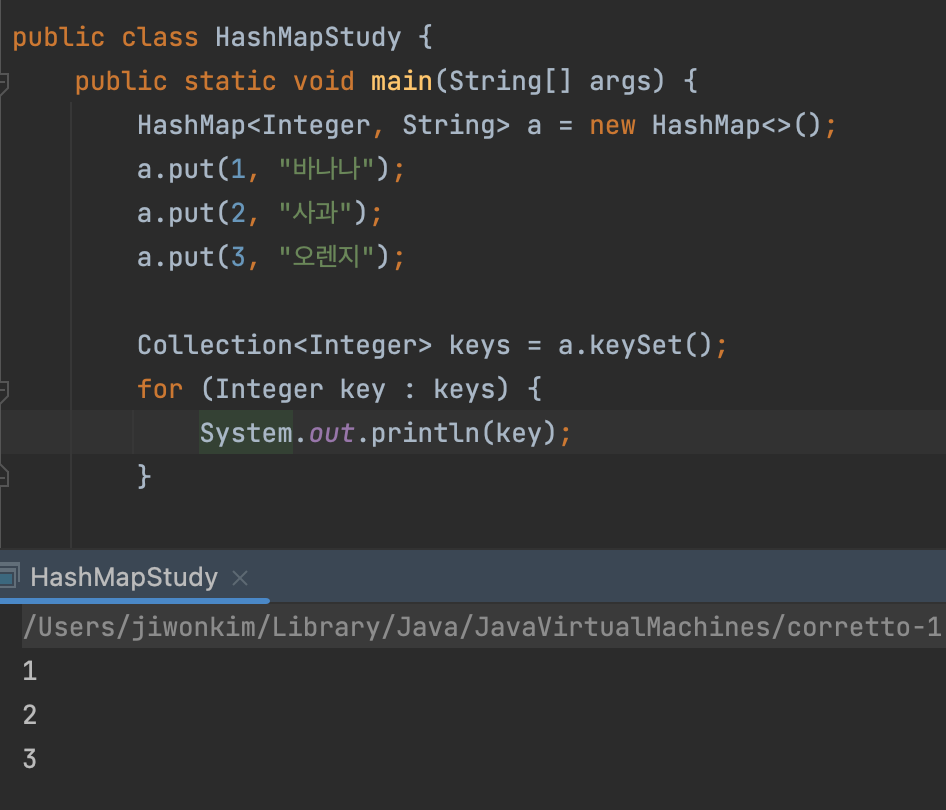
keySet()
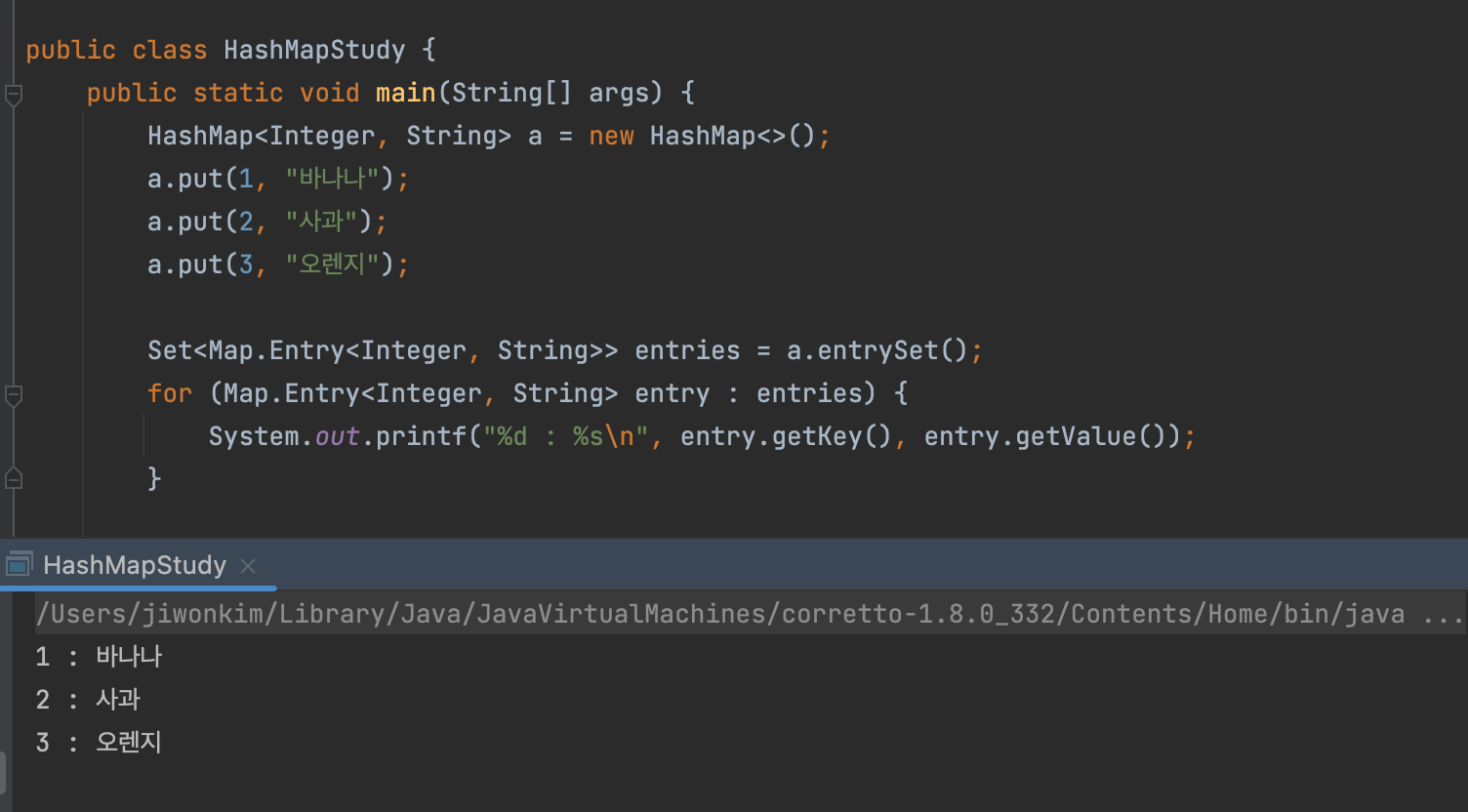
entrySet()
제네릭(Generic)
제네릭(Generic)
: 제네릭은 하나의 타입(클래스, 인터페이스)만 이용해서 이가 처리해야하는 타입에 대해 동적인 대처를 할 수 있게 하기위해 사용한다.
- 대표적인 예로는
List<E>와Set<T>등이 있다. 'List'라는 하나의 인터페이스를 이용하여 이가 담을 수 있는 원소의 타입을 무한정으로 이용할 수 있다.가령, List<Object> List<Integer> List<Login> List<String>
(클래스 이름)<제네릭,...>혹은(인터페이스 이름)<제네릭,...>방식으로 사용할 수 있음.- 제네릭
<T extends 타입>방식으로 제네릭 타입에 대해 부모 클래스 및 구현하는 인터페이스와의 관계를 지정하여 제한할 수 있다. (타입이 인터페이스라 하여도 implements 키워드를 사용하지 않음.)- 제네릭 이름의 제한은 없으나 주로 한 자, T, E, V, K 등을 많이 사용한다.
- 다이나믹 제네릭 타입은 물음표(?) 기호로 나타내며 이는 제네릭에 해당하는 타입에 대한 객체의 제한을 뚜렷하게 두지 않고자 할 때 사용한다. 단, extends 키워드를 통해 제한할 수는 있음.
- 메서드의 반환타입 앞에 제네릭을 설정하여 메서드 내에서 임의의 타입을 사용할 수 있다.
- 제네릭 메서드를 호출할 때에는 메서드 이름 앞에 그 타입을 명시한다.
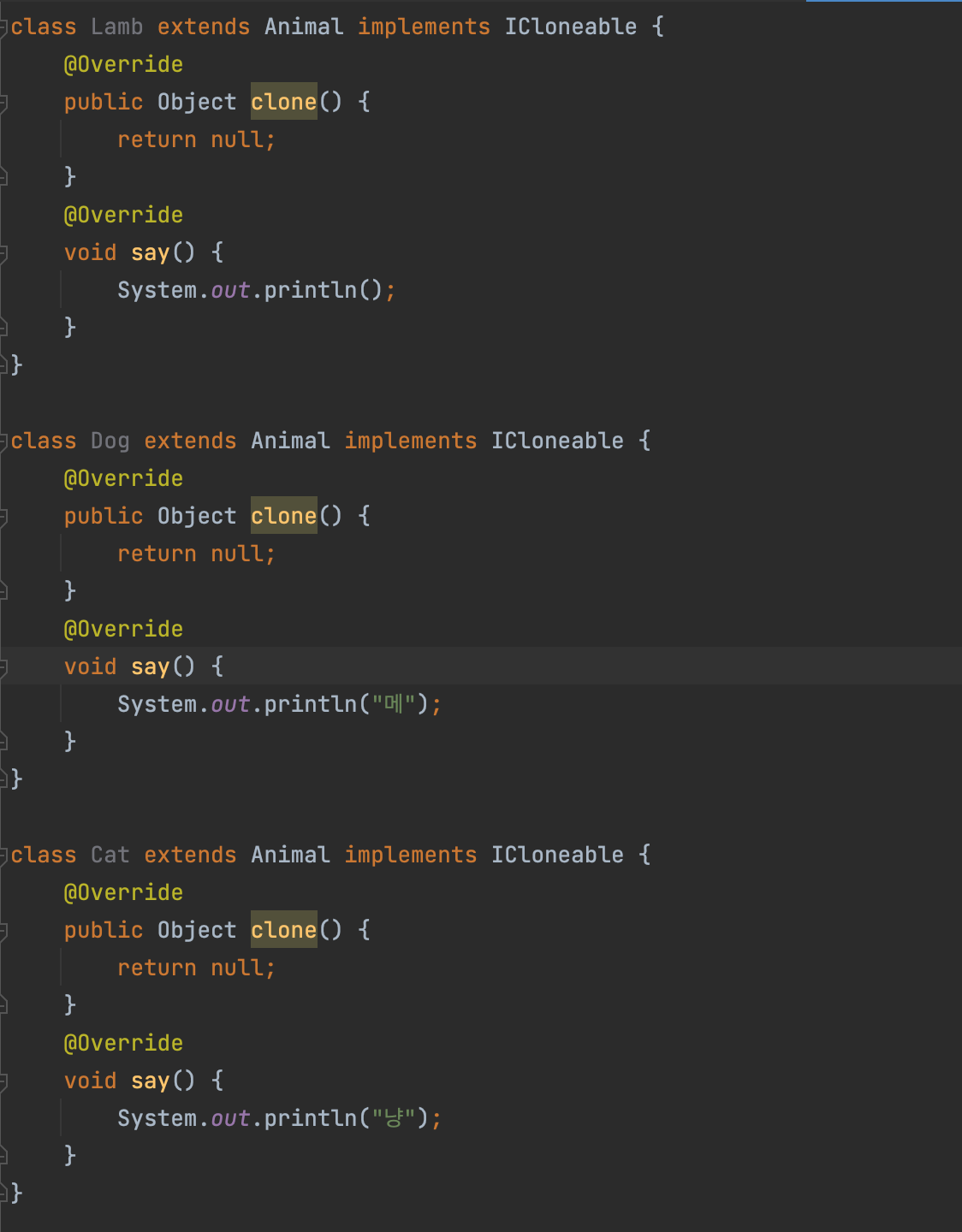
public Lamb clone() { } // 복제
- 복제를 하려면 이렇게 다 적어줘야하는데 동물이 많아지면 많아질수록 힘들다.
그래서 복제가 가능한 타입이다 라는 것을 알려주기위해 ICloneable 인터페이스 생성하자.
- ICloneable 인터페이스에 clone이라는 메서드를 만드는데 void로 둘 수 없다. 이 상황에서는 Obejct 타입을 쓰는 방법 밖에 없다.
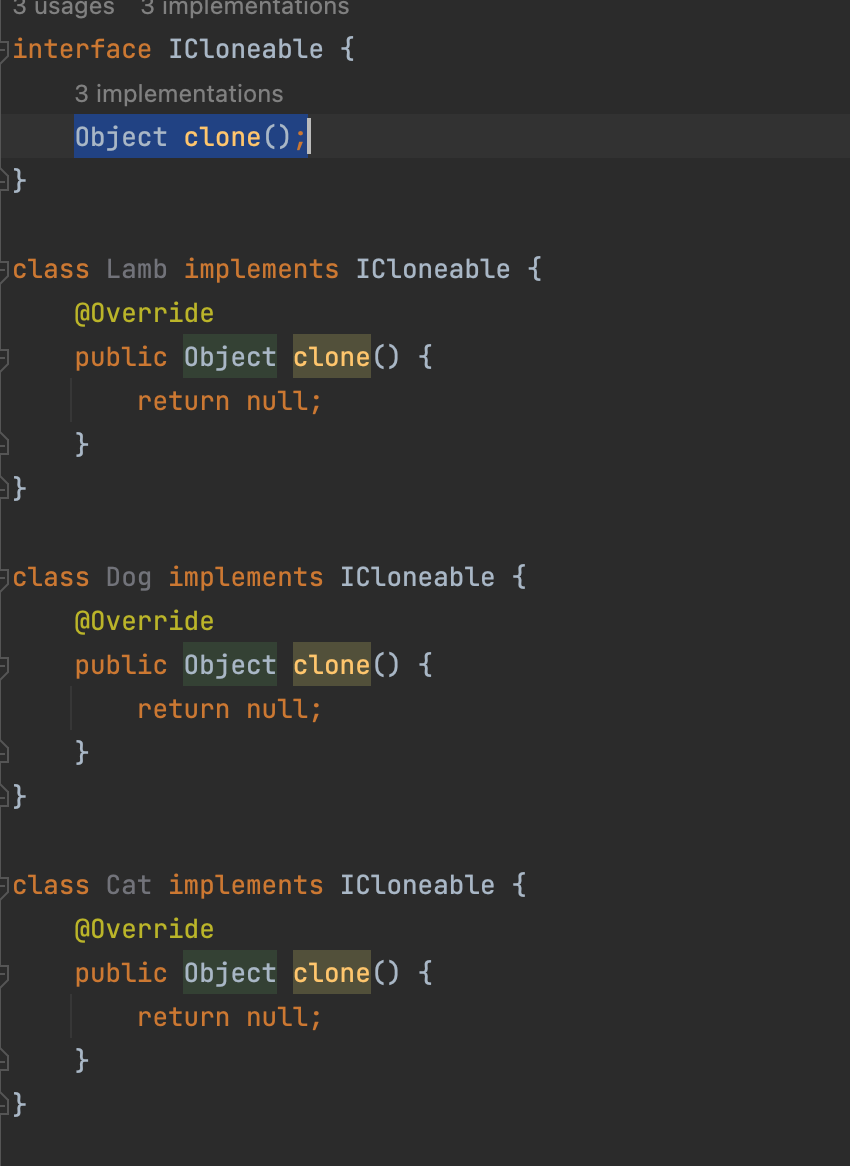
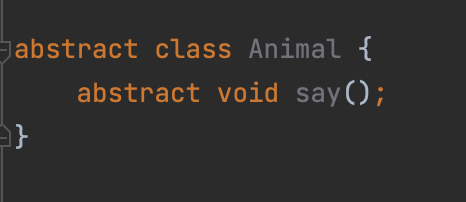
동물 세마리를 묶을 수 있는 타입 : Animal
- 추상적으로 Animal 클래스 생성
- 모든 동물들에게 상속받게 하고 메서드를 구현하게 한다.
3~4분 정리부분
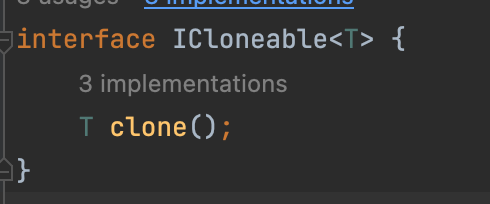
interface ICloneable<T> { T clone(); }
- 이렇게 사용이 가능한데
<T>는 제네릭 타입이며 가상의 타입이다.
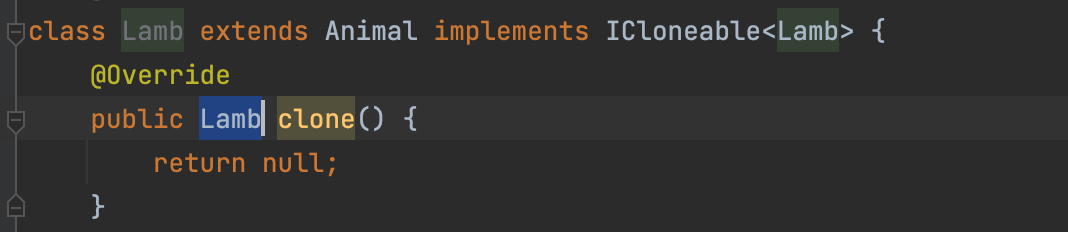
- 참조받고 있는 클래스들도 자신의 타입으로 ICloneable을 참조할 수 있도록 해주자.
즉, T 자리에 Lamb이 들어가게 되고 clone이 반환하는 타입이 T가 아닌 Lamb이 된다.
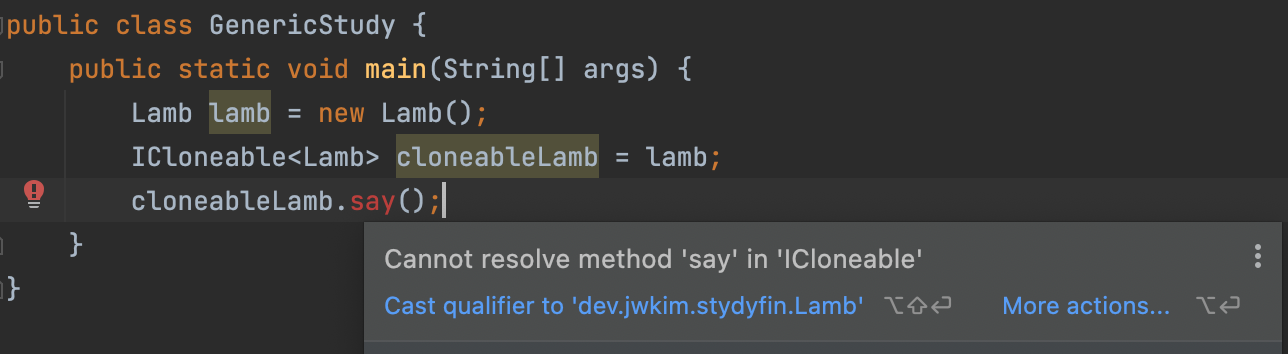
- Object가 아닌 Lamb이 된다.

- ICloneaeble이 clone이라는 메서드만 가졌기 때문에 clone만 가능하고 say는 못한다.
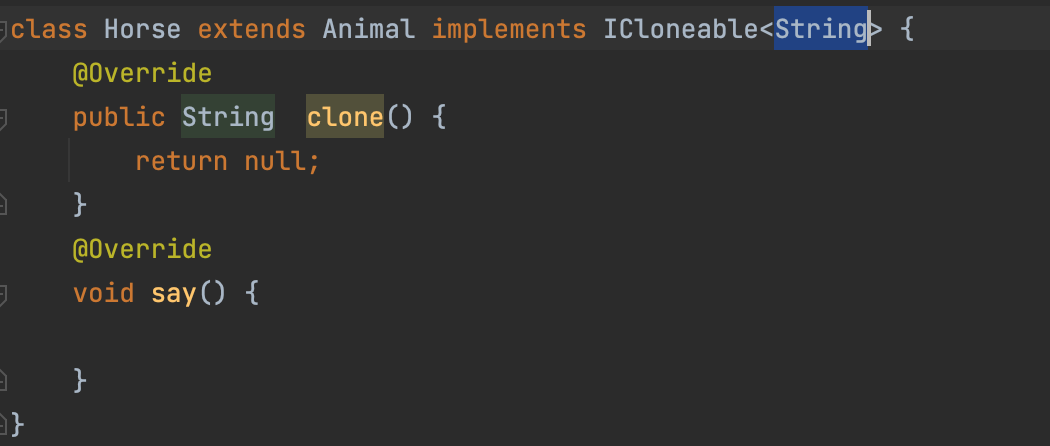
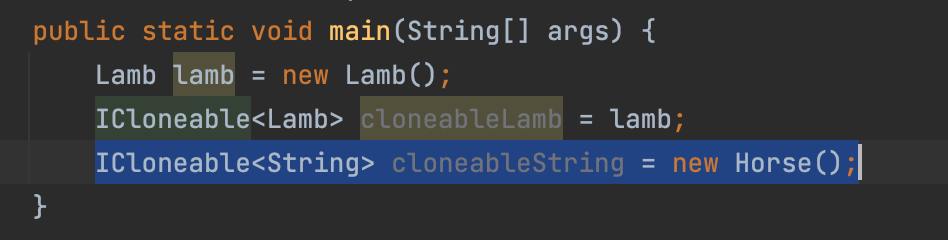
- T자리에 String이 들어올 수 있으며 즉, String 타입으로도 만들 수 있다는 의미이다.
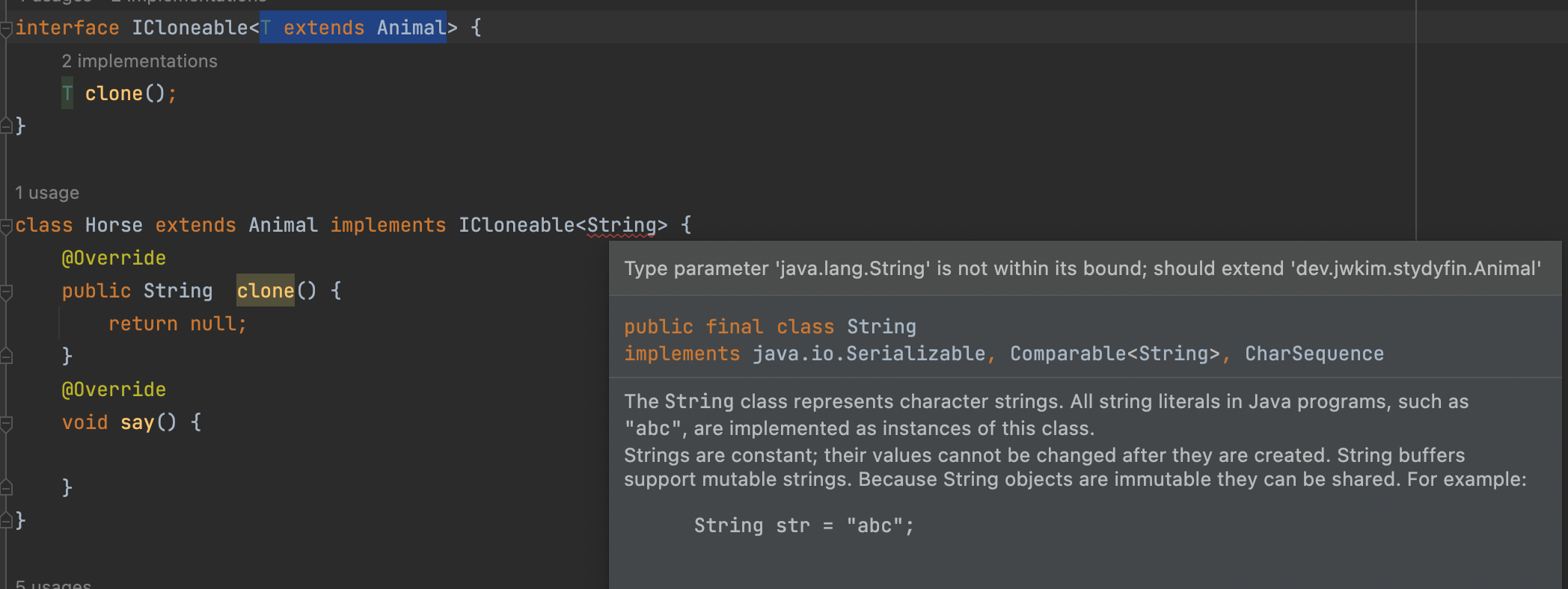
이러한 방대한 모든 타입에 대해서 사용하지 못하도록 T 타입에 대해서 제한을 걸 수 있다. T를 상속받게 하자.
<T extends Animal>
- Animal을 상속받게 해보았더니 Horse의 ICloneable 타입을 String을 더 이상 사용하지 못하게 되었다. 반면에 Lamb은 Animal을 상속받기 때문에 여전히 사용이 가능하다.
이러한 제네릭을 이용하기에 좋은 것은 Tuple이라는 것이 있다.
Entry VS Tuple
Entry : 키-값 쌍
Tuple : 값만 두개Tuple 클래스 생성
- 두 개의 제네릭 사용이 가능하다.
빌더 메서드(= 체인 메서드) 로 사용하기 위해서 build로 getter setter 생성하자.public X getX() { return x; } public Tuple<X, Y> setX(X x) { this.x = x; return this; } public Y getY() { return y; } public Tuple<X, Y> setY(Y y) { this.y = y; return this; }

public static void main(String[] args) { Tuple<String, String> tp = new Tuple<String, String>() .setX("X값임") .setY("Y값임"); System.out.println( tp.getX() ); System.out.println( tp.getY() ); }
- 메인에서 체인메서드로 사용이 가능해진다.
Collections Framwork(API)
Collections Framwork(API)
: java.util.Collection 의 사용을 쉽고 빠르게 하기위해 존재한다. (유틸리티)
정적 메서드
<T>max(x)
:
<T>전달된 Collection을 상속 받는 자료 구조이면서 그 제네릭이 Comparable을 상속(구현) 받는 객체 x가 가지는 원소들 중 가장 큰 것(Comparable에 의해 비교된)을 반환한다.
<T>min(x)
:
<T>전달된 Collection을 상속 받는 자료 구조이면서 그 제네릭이 Comparable을 상속(구현) 받는 객체 x가 가지는 원소들 중 가장 작은 것(Comparable에 의해 비교된)을 반환한다.public static void main(String[] args) { List<Integer> numbers = new ArrayList<>(); numbers.add(1); numbers.add(2); numbers.add(5); System.out.println( Collections.<Integer>max(numbers)); // 5 System.out.println( Collections.<Integer>min(numbers)); // 1 }
sort(x)
: 전달된 Collection을 상속 받는 자료 구조이면서 그 제네릭이 Comparable을 상속(구현) 받는 객체 x가 가지는 원소를 오름차순으로 정렬한다.
<T>sort(x, c)
: 전달된 Collection을 상속 받는 자료 구조이면서 그 제네릭이 Comparable을 상속(구현) 받는 객체 x가 가지는 원소를 오름차순으로 정렬한다.
reverse(x)
: 전달된 Collection을 상속 받는 자료 구조이면서 그 제네릭이 Comparable을 상속(구현) 받는 객체 x가 가지는 원소의 순서를 뒤집는다.
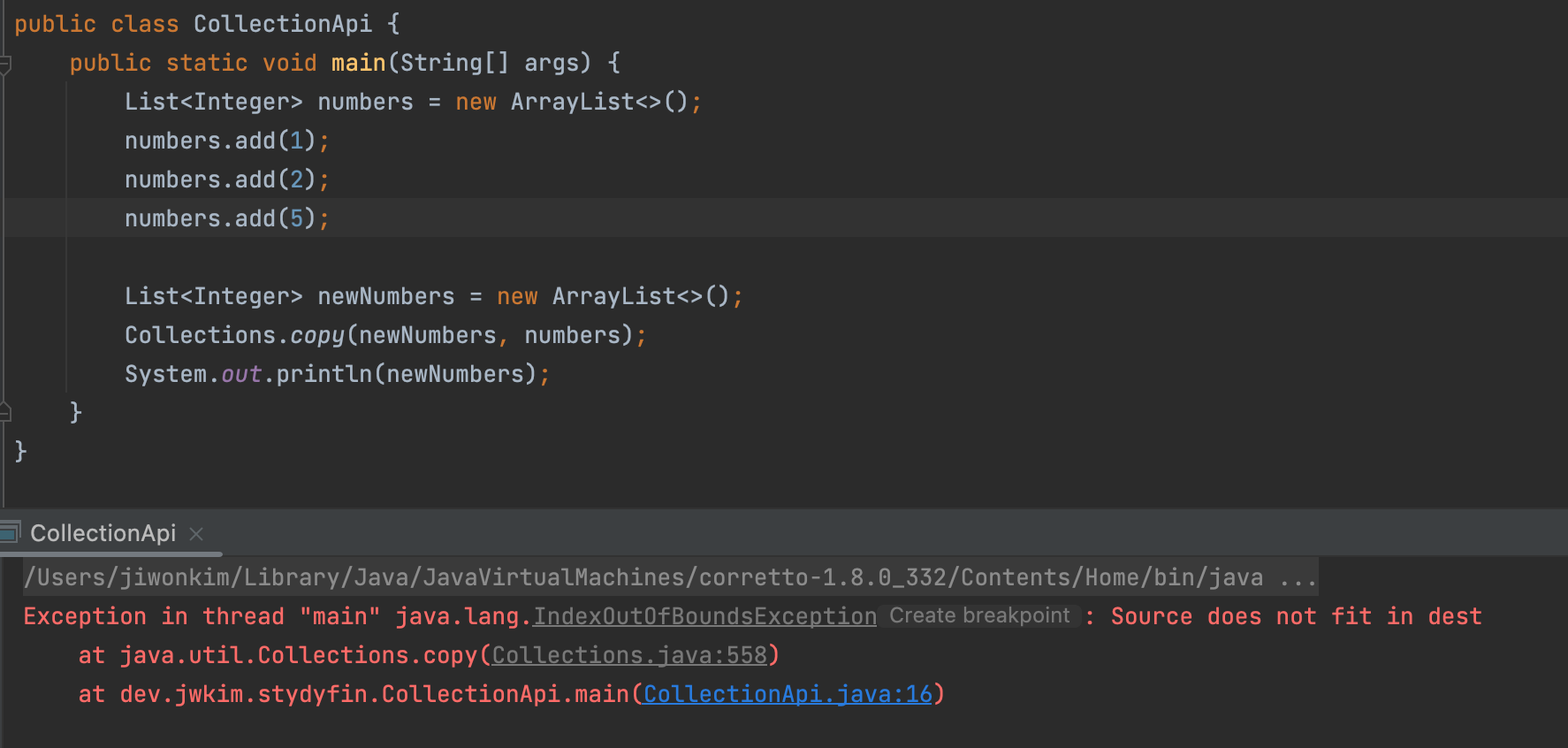
copy(x,y)
: 전달된 y Collection 객체가 가지는 원소를 x Collection 객체에 복사한다. 이 때 복하사한 값을 붙어넣을 Collection 객체의 크기는 원본 Collection 객체의 크기 이상이여한다.
- newNumbers List의 크기를 정해주지 않았기 때문에 오류가 발생한다.
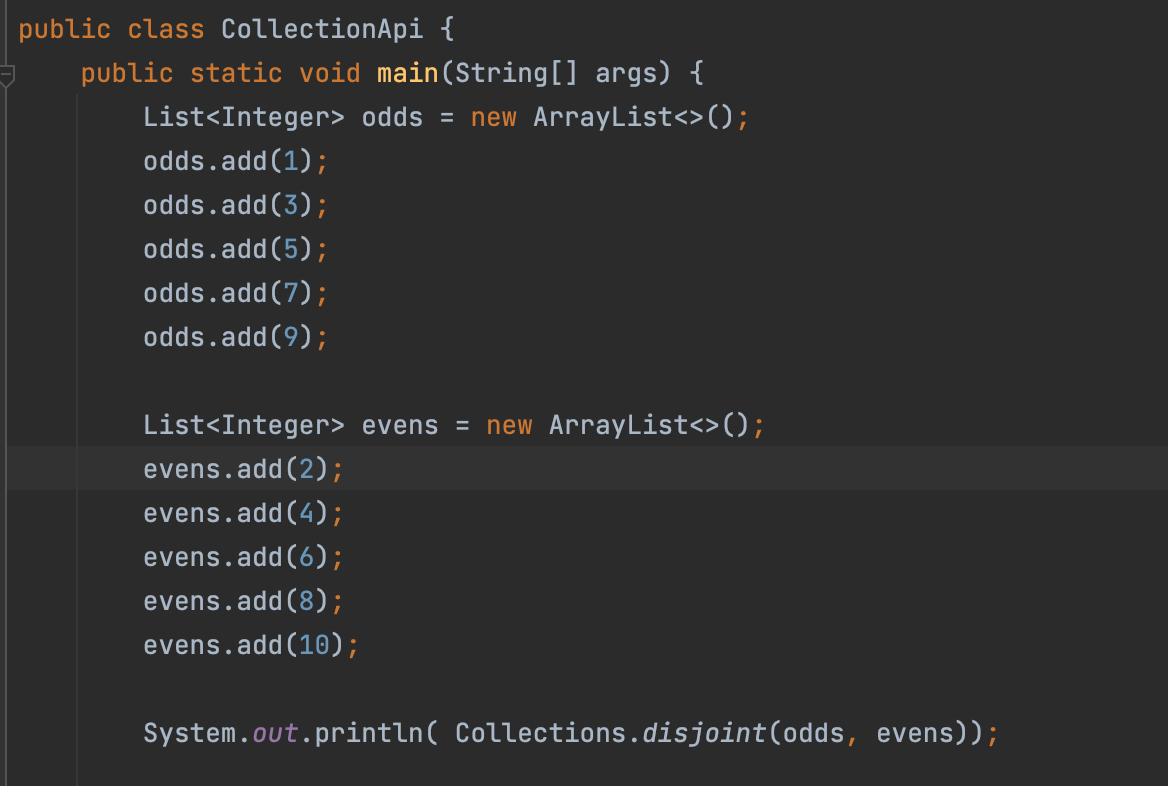
disjoint(x, y)
:
<boolean>전달된 x와 y Collection 객체의 원소중 겹치는(동일한) 원소가 하나도 없다면 true를, 하나라도 있다면 false를 반환한다.
- true가 뜨게되고 겹치는게 하나라도 있다면 false를 반환한다.
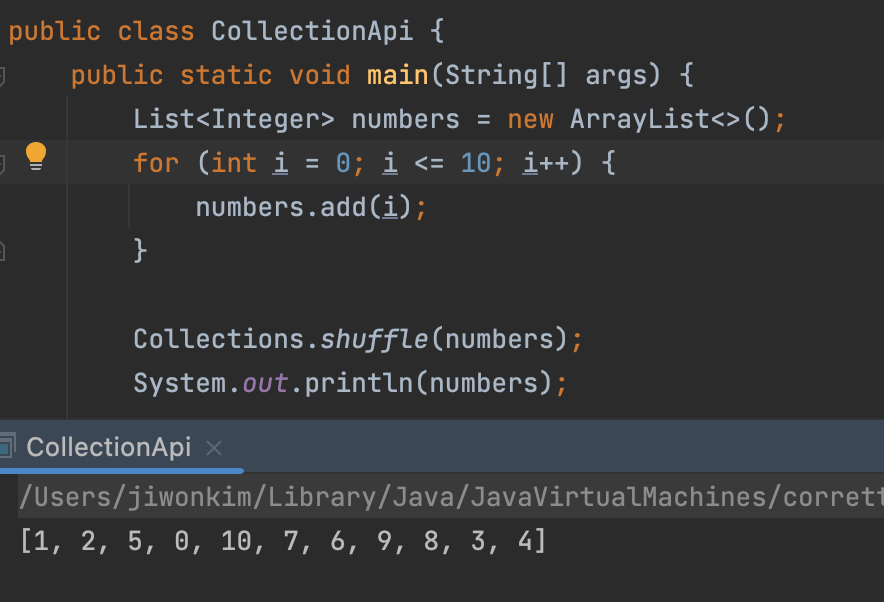
shuffle(x)
: 전달된 x Collection 객체가 가지는 원소의 순서를 무작위로 섞는다.
- 할때마다 결과는 다르게 출력된다. 중복이 없다는 장점이 있다.
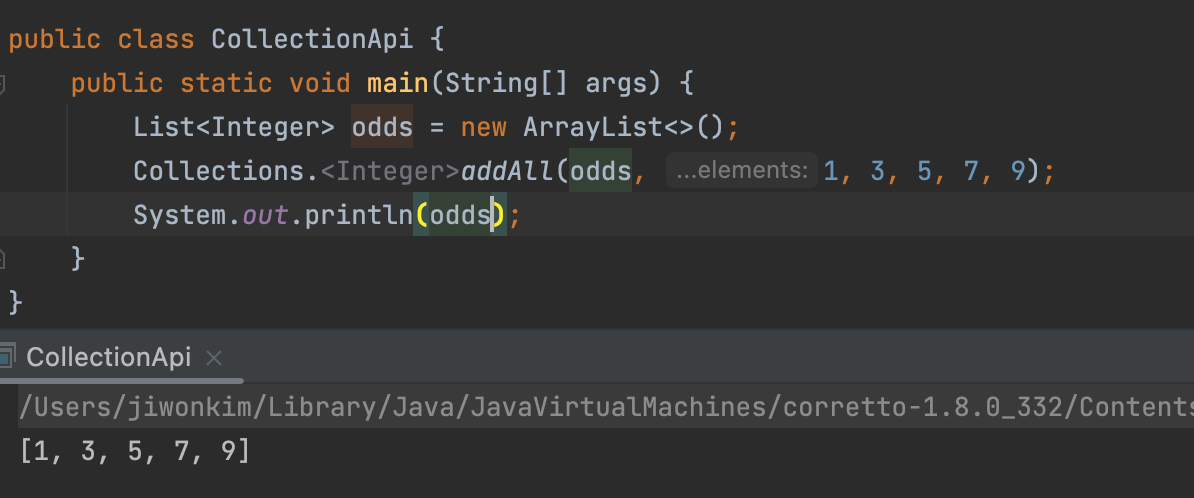
<T>addAll(x, v...)
: 전달된 x Collection 객체에 전달된 T타입의 객체 v(들)을 추가한다.
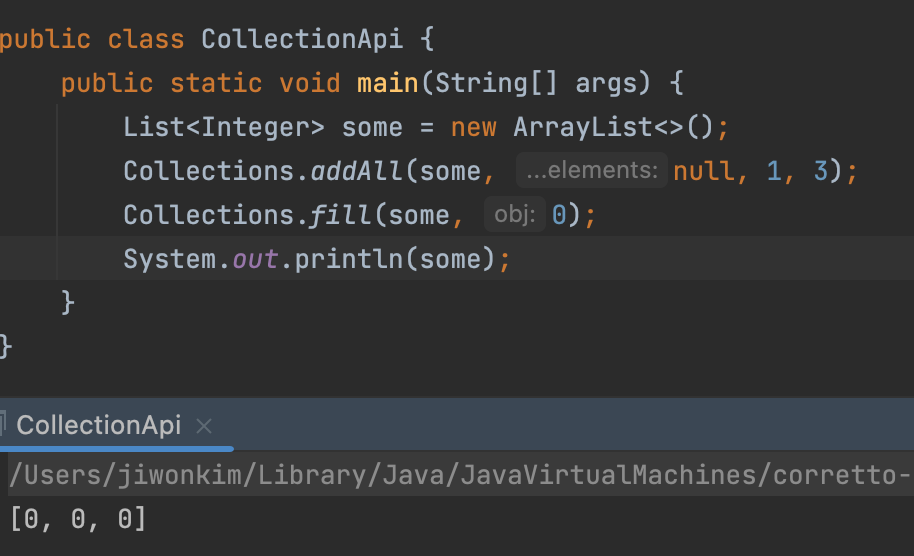
fill(x, v)
: 전달된 x List의 원소를 모두 v로 지정한다.
- 모두 0으로 지정했기 때문에 0만 나온다.
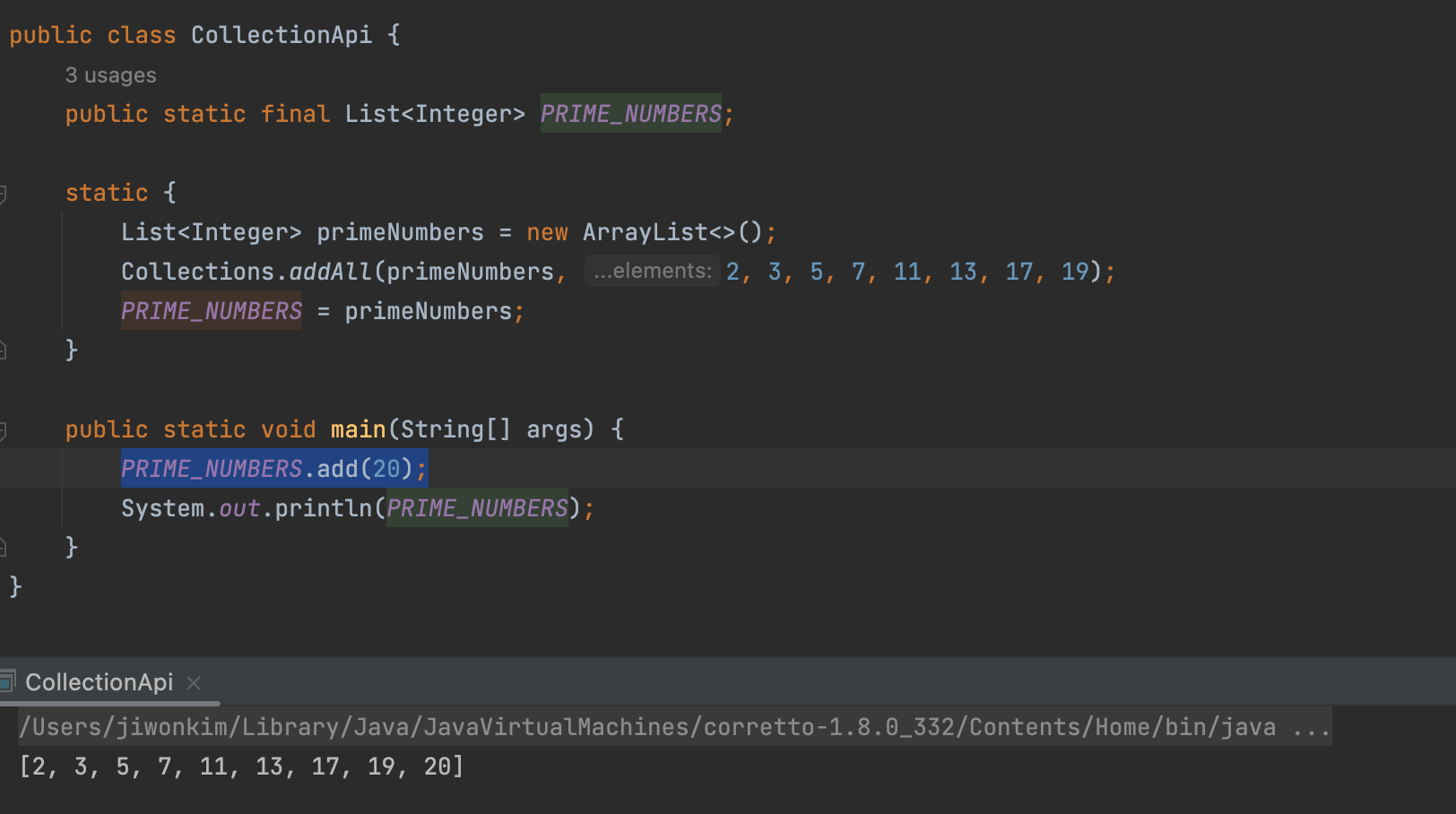
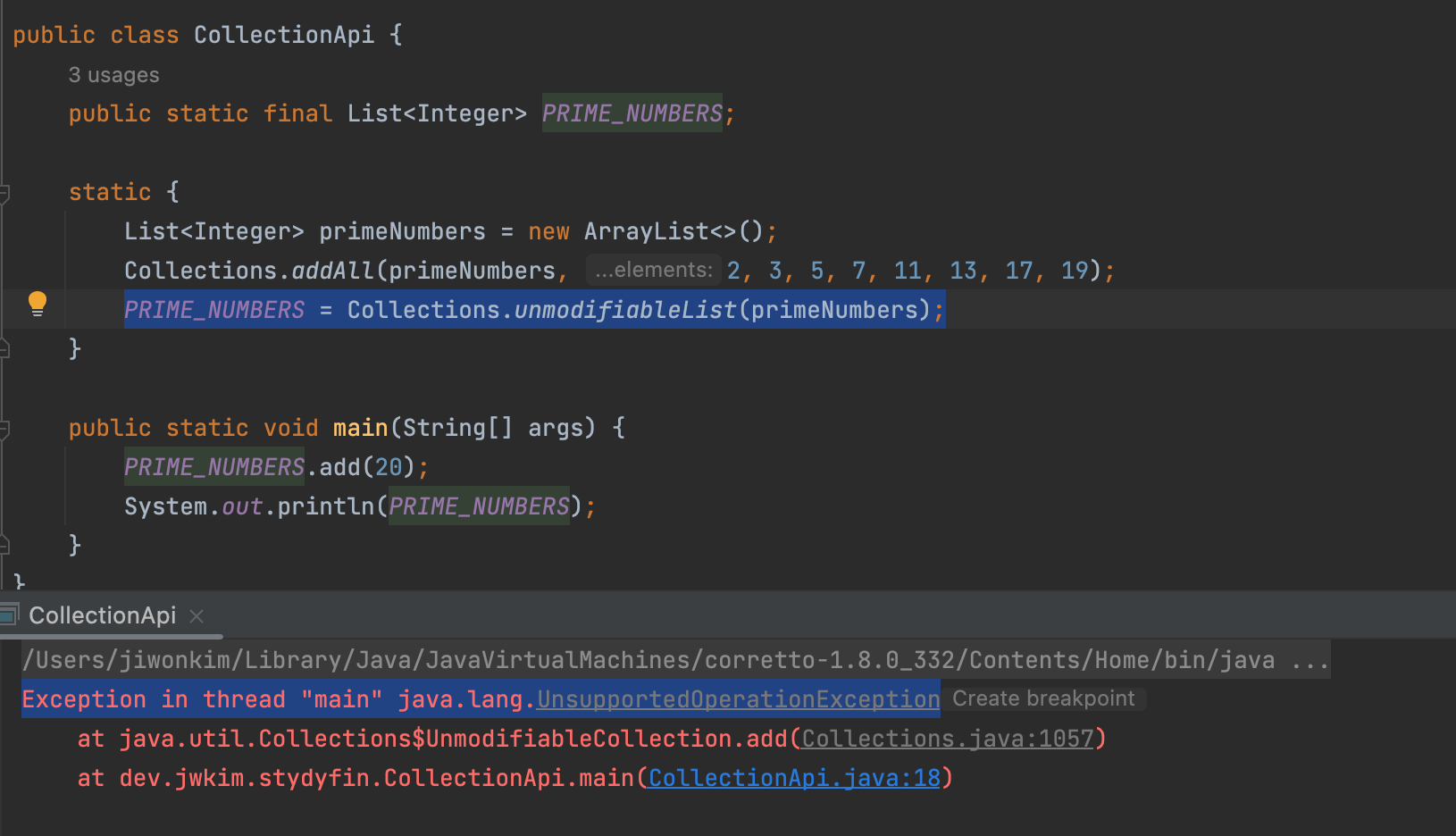
<T>unmodifiableList(x)
:
<List<T>>전달 받은 x List를 더 이상 추가/삭제할 수 없는 리스트로 만들어 반환한다.
- 그 외 unmodifiable 어쩌고 시리즈 있음.
- 어떤 개발자가 20이라는 소수가 아닌 수를 PRIME_NUMBERS에 실수로 집어넣을 수도 있다. 이것을 막기위해서
unmodifiableList을 사용한다.
Arrays Framework(API)
Arrays Framework(API)
java.util.Arrays 자바 배열과 관련된 편의 기능을 제공한다.
정적 메서드
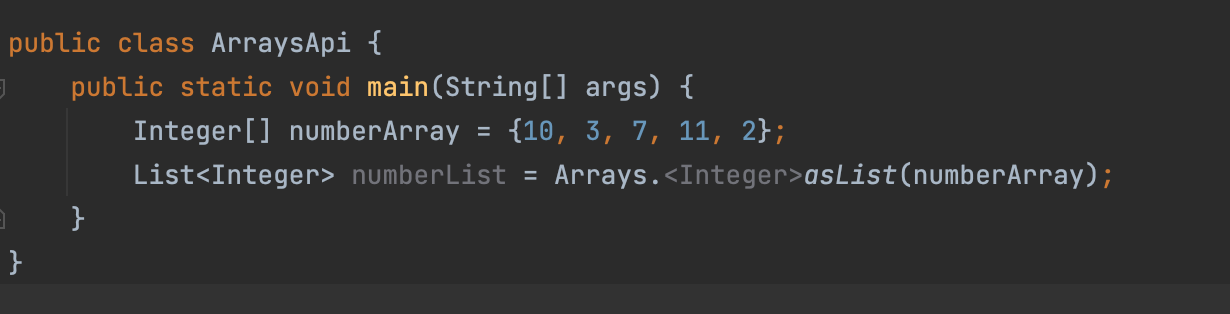
<T>asList<T[]>
:
<List<T>>전달된 T타입의 배열을 T타입을 제네릭으로 가지는 List로 반환한다.
- 위 numberArray 배열을 List 로 변경하고 싶을 떄 사용.

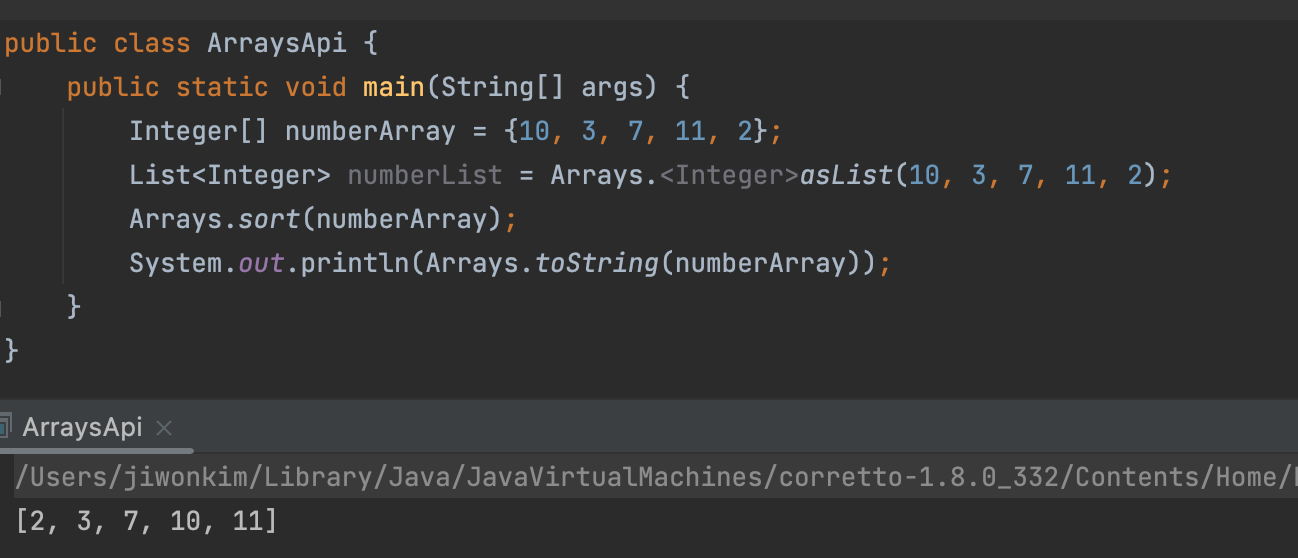
sort(x[])
: 전달된 x타입의 배열을 오름차순으로 정렬한다.
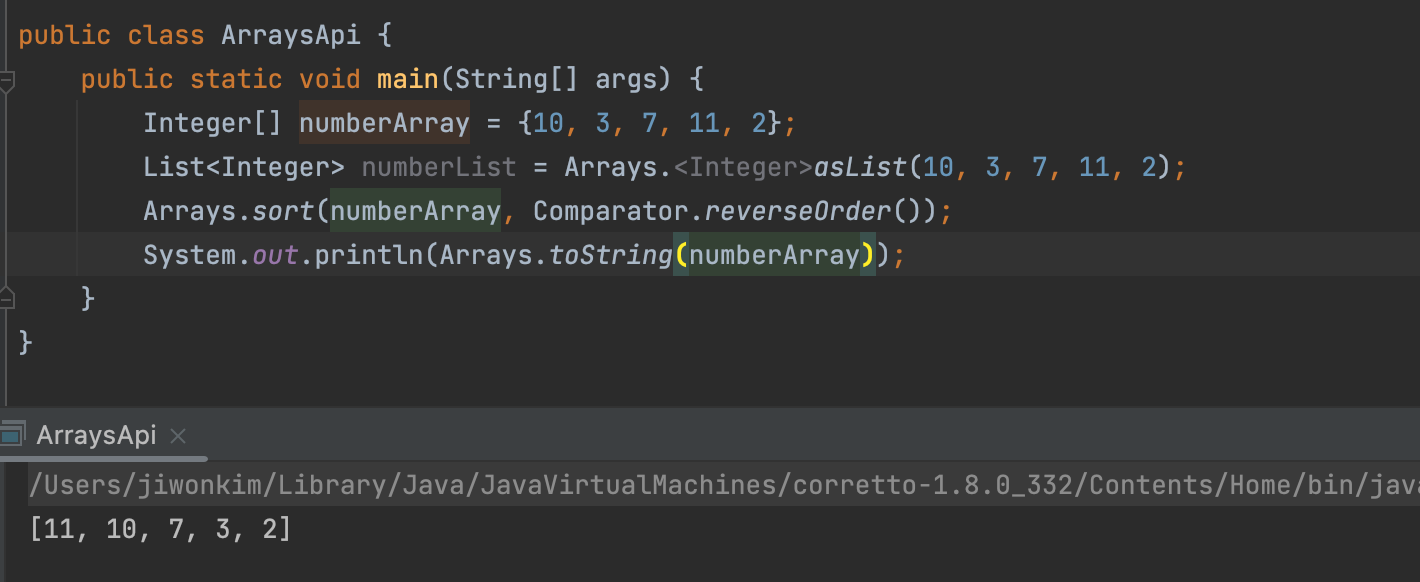
<T>sort(T[],c)
: 전달된 T타입의 배열을
Comparator<T>타입의 객체인 c형식으로 정렬한다.
toString(x[])
:
<String>전달된 x타입의 배열을 [a, b, c,...] 형식의 문자열로 변형하여 반환한다.
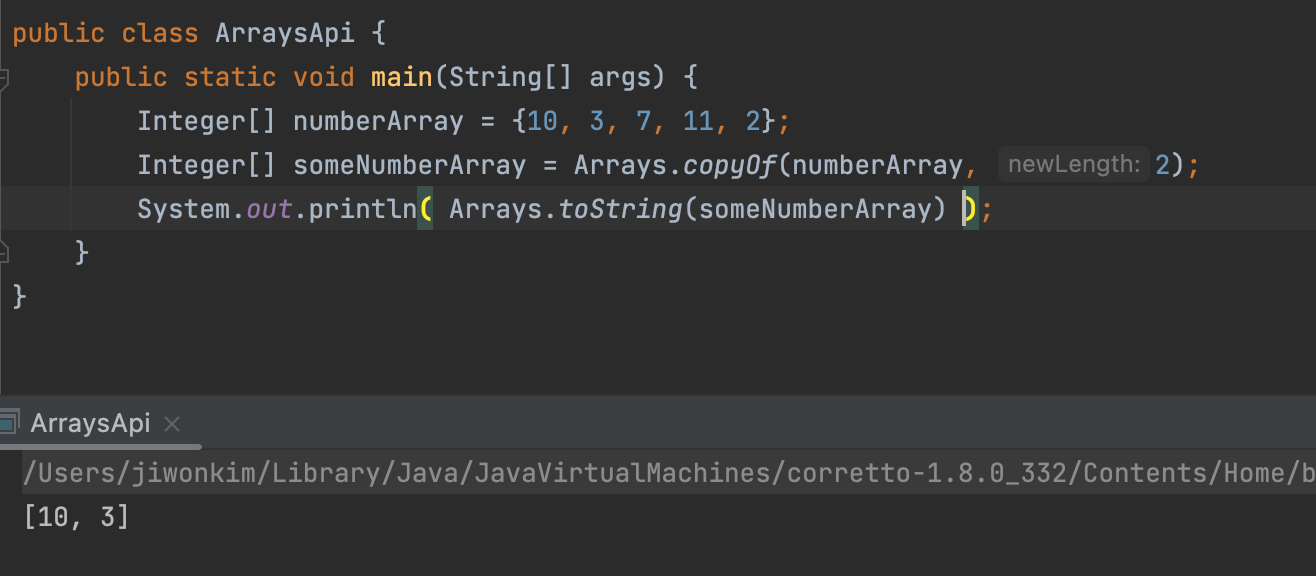
<T>copyOf(T[], x)
:
<T[]>전달된 T타입의 배열의 원소 중 (앞) x개만 뽑아 새로운 배열로 반환한다.
<T>stream(T[])
:
<Stream<T>>전달된 T타입의 배열에 대해 Stream API를 실행하기 위한 객체를 반환한다.
Stream API
Stream API
: 배열과 List에 대한 처리를 쉽고 빠르게 하기위한 편의 기능을 제공한다.
람다(표햔)식 (Lambda Expression)
(매개변수,...) -> { 구현부 } 방식의 익명 함수 (Annoymous Function)
- 단, 매개 변수가 단 한 개일 때에는 매개변수 좌우의 괄호를 생략할 수 있다.
함수형 인터페이스(Functional Interface)
: (추상) 메서드를 한 개만 가지는 인터페이스. 인터페이스에 @FunctionalInterface 어노테이션을 붙인다.
- Stream API는
Stream<T>타입의 객체에 대해서 사용할 수 있다.
비정적 메서드
filter(x)
:
<Stream<T>>해당 스트림에 대해 전달된Predicate<T>타입인 x를 만족하는 원소만 가지는 스트림을 반환한다.
- numbers List 에서 홀수만 뽑아서 담으려고 했을때 일반적으로는 이렇게 작성을 해야한다. 이렇게 길게 작성하지 않기 위해 stream을 사용한다.
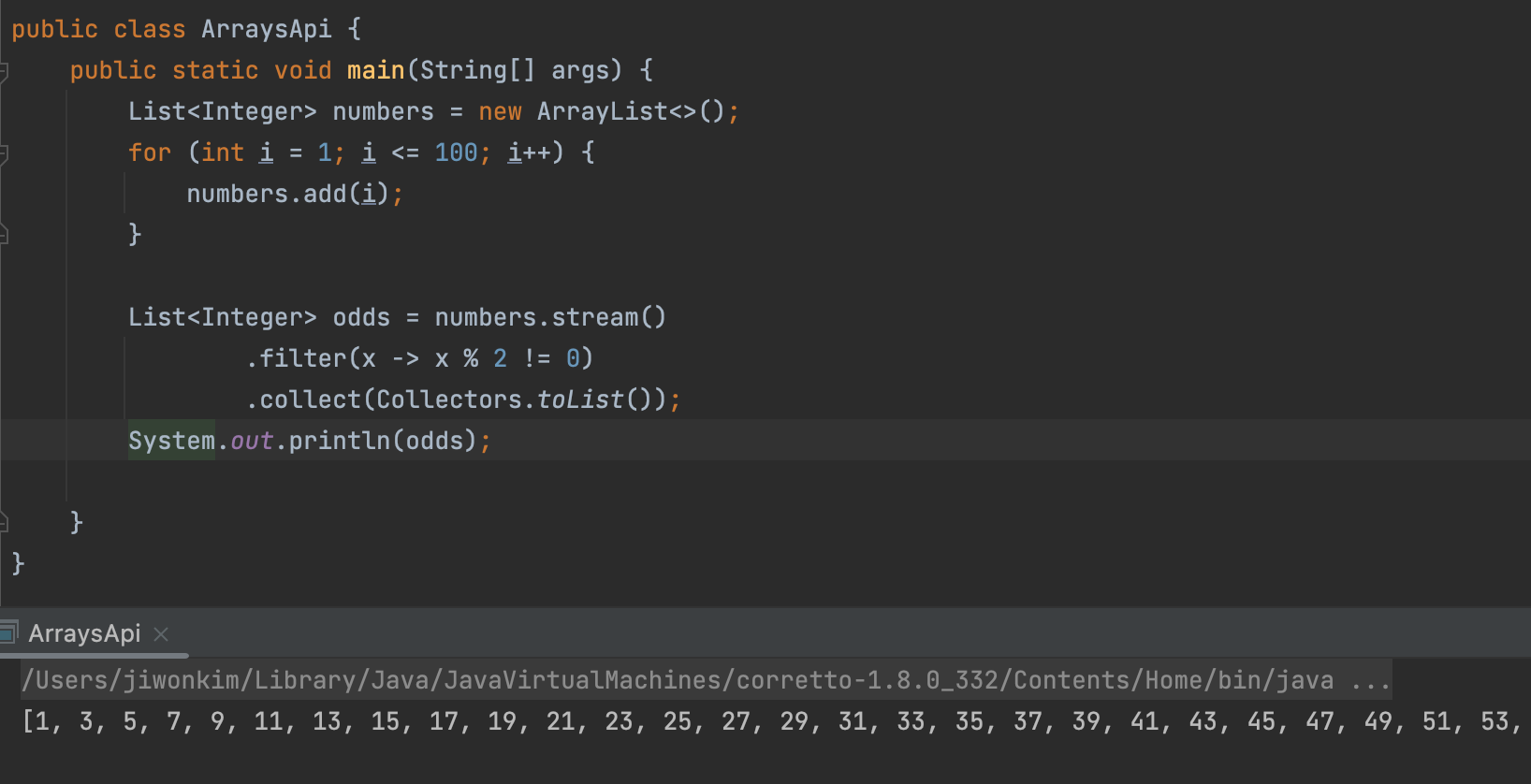
List<Integer> numbers가 가진 각 원소 : x 라고 하고 람다식으로 작성한다.List<Integer> odds = numbers.stream() .filter(x -> x % 2 != 0) .collect(Collectors.toList()); System.out.println(odds);
map(x)
:
<Stream<T>>해당 스트림에 대해 전달된Predicate<T>타입인 x에 대해 가지고 있는 모든 원소를 연산한 뒤 이를 원소로 가지는 스트림을 반환한다.
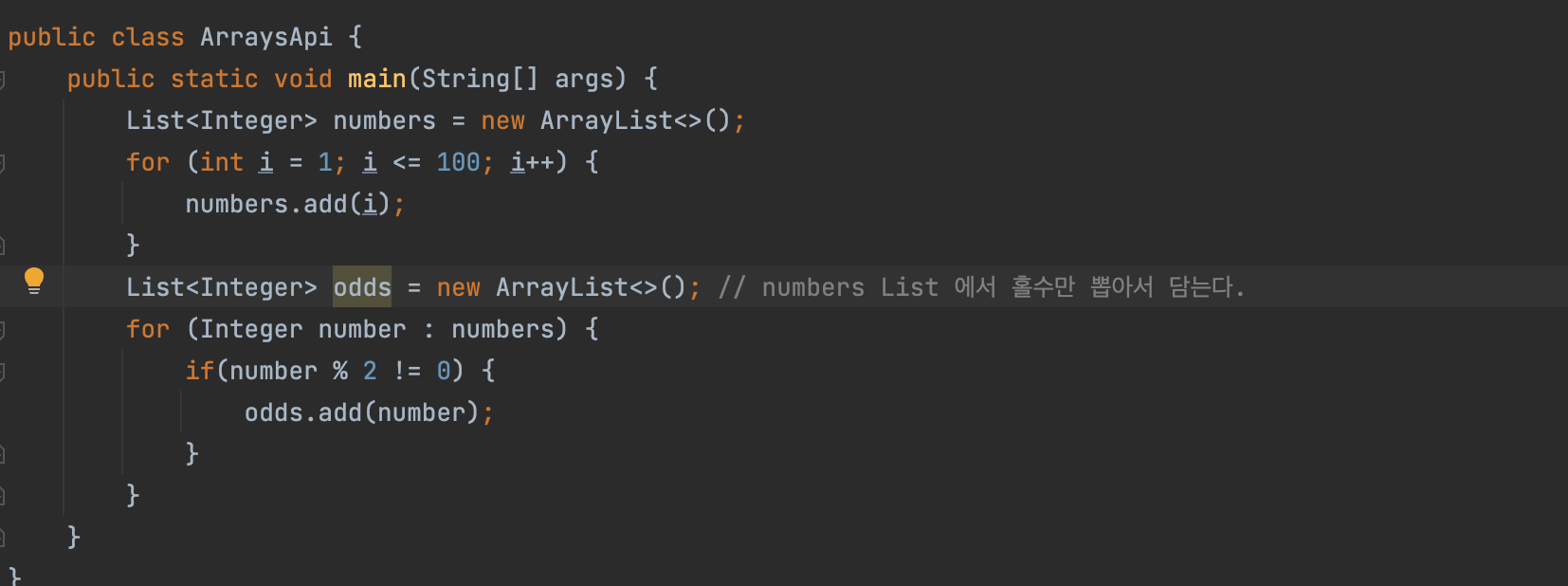
filter와 map의 차이점
[1, 2, 3, 4, 5] → .filter(x -> x % 2 == 0) [2, 4] 를 뱉어내며 처음의 Stream의 길이와 다른 길이의 Stream이 나올 수도 있다. 그에 반해 map은 [1, 2, 3, 4, 5] → .map(x -> x * 2) [2, 4, 6, 8, 10] map을 해서 나오는 Stream의 길이는 항상 같다. → .map(x -> x % 2 == 0) 이라면 [false, true, false, true, false] 이라는 같은 길이의 Stream을 반환한다.
anyMatch(x)
:
<boolean>해당 스트림이 가지고 있는 원소 중 전달된 Predicate 타입인 x에 대해 하나라도 참인가에 대한 여부를 반환한다.
allMatch(x)
:
<boolean>해당 스트림이 가지고 있는 원소 중 전달된 Predicate 타입인 x에 대해 전체가 참인가에 대한 여부를 반환한다.
noneMatch(x)
:
<boolean>해당 스트림이 가지고 있는 원소 중 전달된 Predicate 타입인 x에 대해 전체가 거짓인가에 대한 여부를 반환한다.
findFirst(x)
:
<Optional<T>>해당 스트림이 가지고 있는 원소 중 전달된 Predicate 타입인 x에 대해 참인 첫번째 원소에 대한 Optional을 반환한다.
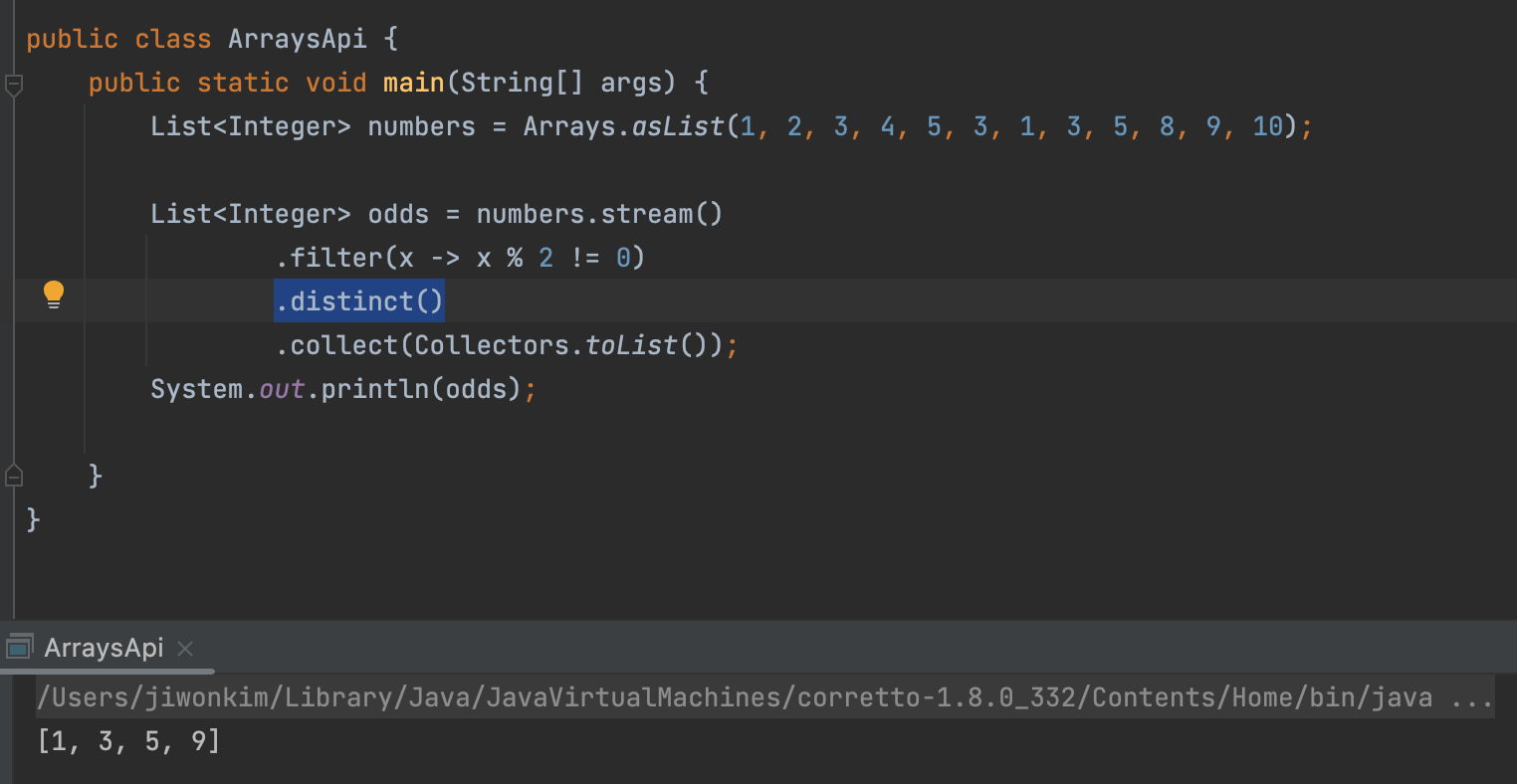
distinct()
:
<Stream<T>>해당 스트림에 대해 전달된Predicate<T>타입인 x를 만족하는 원소만 가지는 스트림을 반환한다.
<R, A>collect(c)
:
<R> Stream<T>에 대해Collector<? super T, A, R>타입인 c객체의 방식으로 원소를 모아 반환한다.
.collect(Collector.toList())하면<Stream<T>>를List<T>로 반환한다.
모든<Stream<T>>는 T타입에 대한 Stream 객체를 반환하는데 List로 받아와야 for을 돌리든 개발을 진행할 수 있다. 그렇기 때문에 collect을 사용한다. Stream 을 사용할 때 얘를 마지막에 적어주는 종지부라고 생각하면 쉽겠다.
.collect(Collector.toList())
어노테이션 (Annotaition)
어노테이션 (Annotaition)
: 어노테이션은 변수, 메서드, 클래스, 인터페이스 등의 속성이나 상태를 알리기 위해 사용한다.
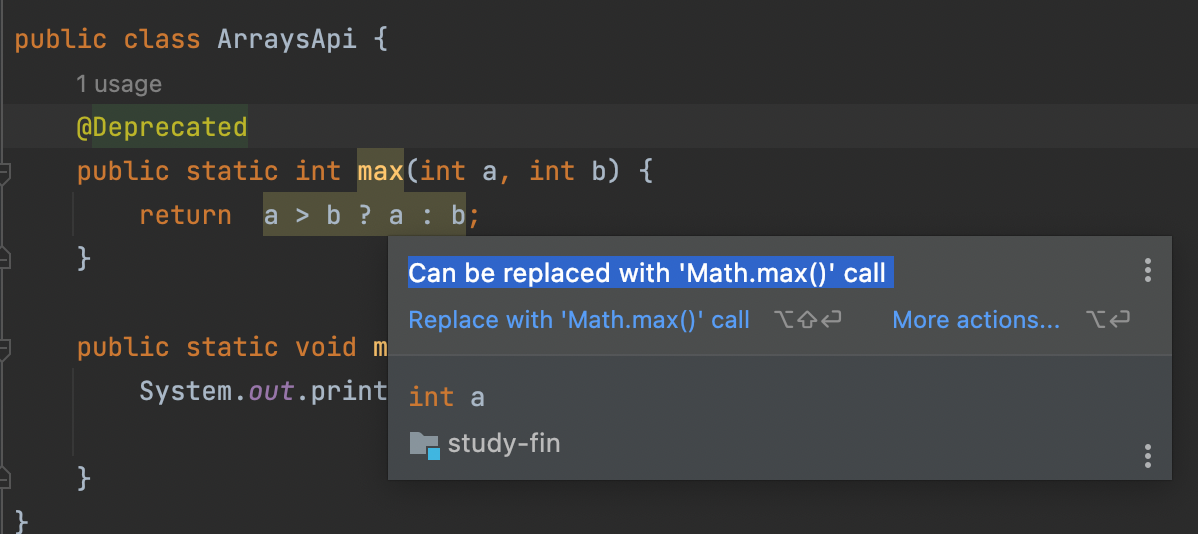
@Deprecated
: 해당 메서드 혹은 클래스/인터페이스 등이 더 이상 사용되어져서는 안 되며, 앞으로 삭제될 것이라는 점을 알림.
- 얘 말고 다른 것을 사용하라는 것을 알려주기 위해서 해당 어노테이션을 사용하게 된다.
@Override
: 해당 메서드가 재정의되었음을 알림. (생략 가능, 근데 하면 안 됨)
@FunctionalInterface
: 해당 인터페이스가 함수형 인터페이스(Functional Interface)임을 알림.
Optional
: 값이 null인 어떠한 타입에 대해 유연히 대처할 수 있는 수단을 제공한다.
정적 메서드
<T>of(x)
:
<Optional<T>>T타입을 제네릭으로 가지는 Optional 객체를 반환한다.
- 이 때 Optional이 가지고 있는 값은 T타입의 객체 x이다. 단, 이 때 x는 반드시 null이 아니어야함.
<T>ofNullable(x)
:
<Optional<T>>위<T>of(x)와 같으나 x가 null일 수도 있는 상황에 사용한다.
<T>empty()
:
<Optional<T>>아무런 값도 가지지 않은 T타입을 제네릭으로 가지는 Optional 객체를 반환한다.
비정적 메서드
get()
:
<T>Optional 객체가 가지고 있는 T타입의 객체를 반환한다.
- 이때 Optional이 값을 가지고 있지 않다면 NoSuchElementException 예외가 발생한다.
isPresent()
:
<boolean>Optional 객체가 값을 가지고 있는가에 대한 여부를 반환한다.
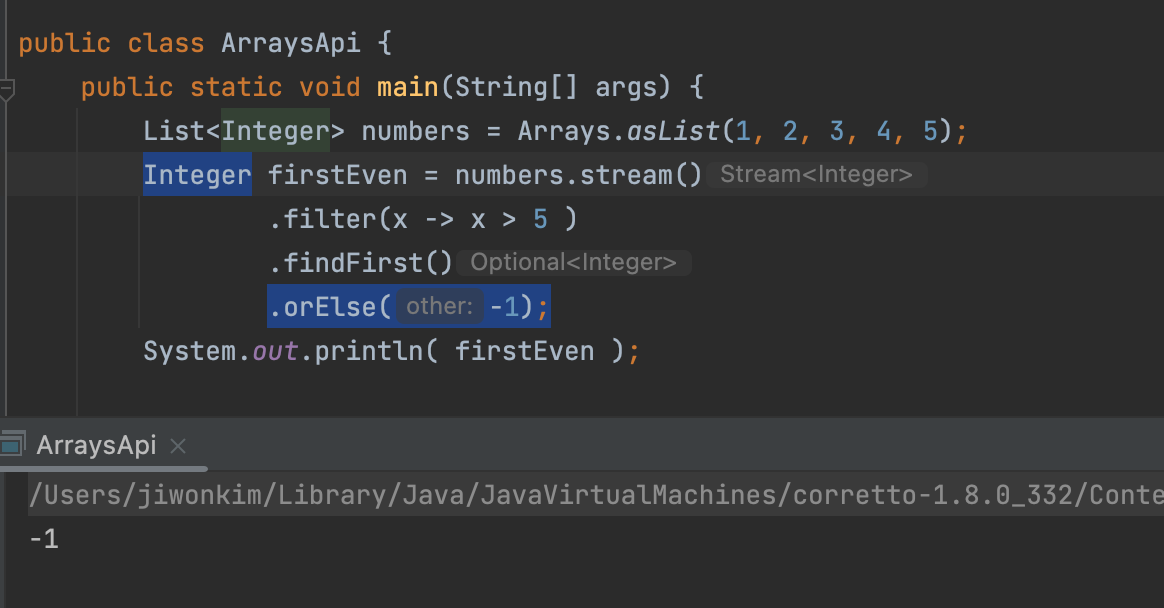
orElse(x)
:
<T>만약 Optional 객체가 값을 가지고 있다면 그 값을, 값을 가지고 있지 않다면 T타입의 객체 x를 반환한다.
- 이론은 맞지만 이렇게 사용할 수 없다.
numbers.stream()은 Stream<Integer>을 반환하고 filter을 해도 Stream<Integer> 해주는데 findFirst를 하면 Optional<Integer>을 반환해준다.
Optional<Integer>은 firstEvne의 Integer이 될 수 없기 때문에 오류가 발생한다.
- Optional 로 변경해주면 가능하다.
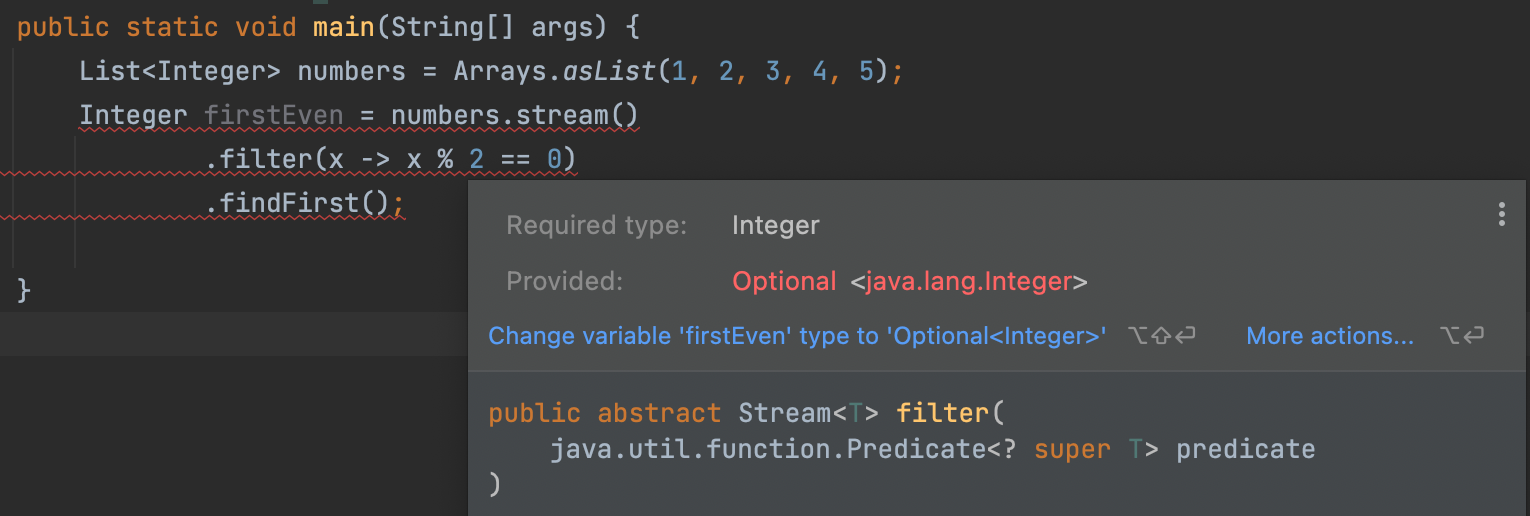
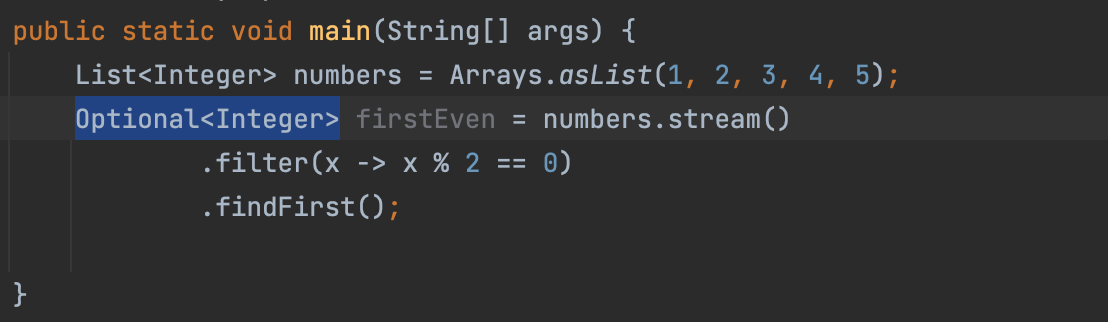
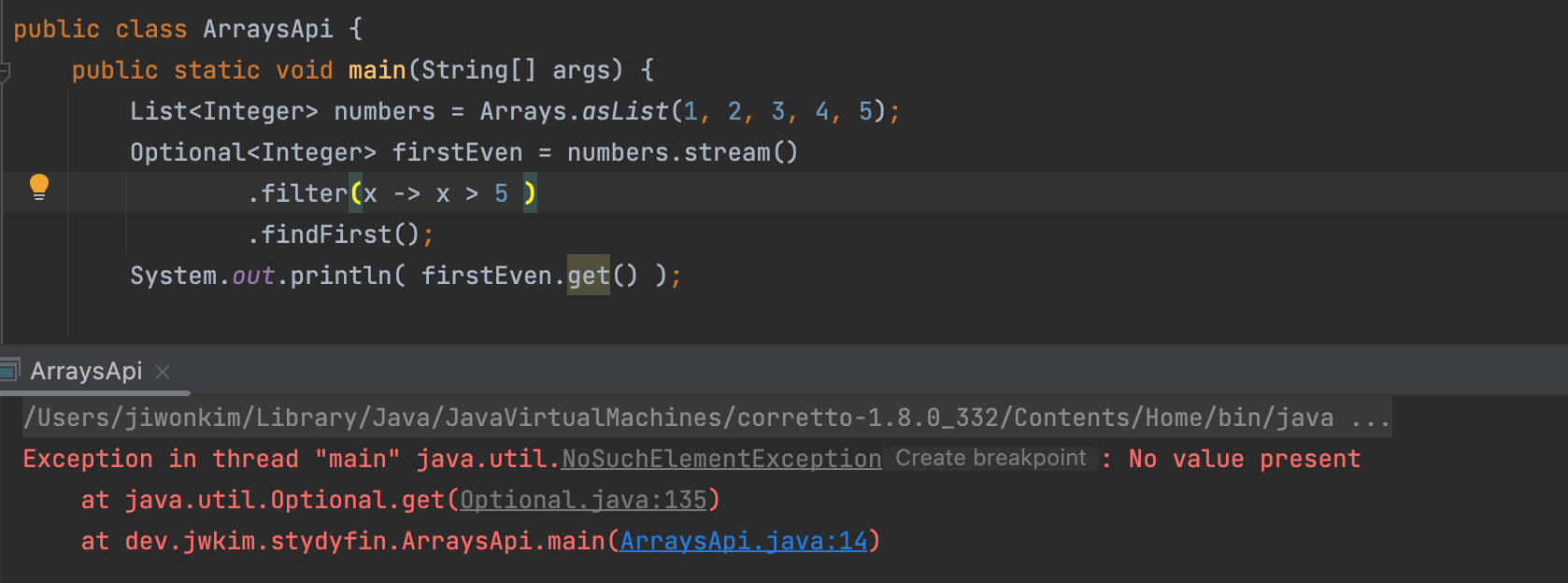
- Optional 이 값을 가지고 있지 않으니 get할 수 있는 대상이 없다. 따라서
NoSuchElementException라는 예외가 발생하게 된다.
- 그러한 예외를 피하기 위해 orElse(x) 메서드를 사용한다.
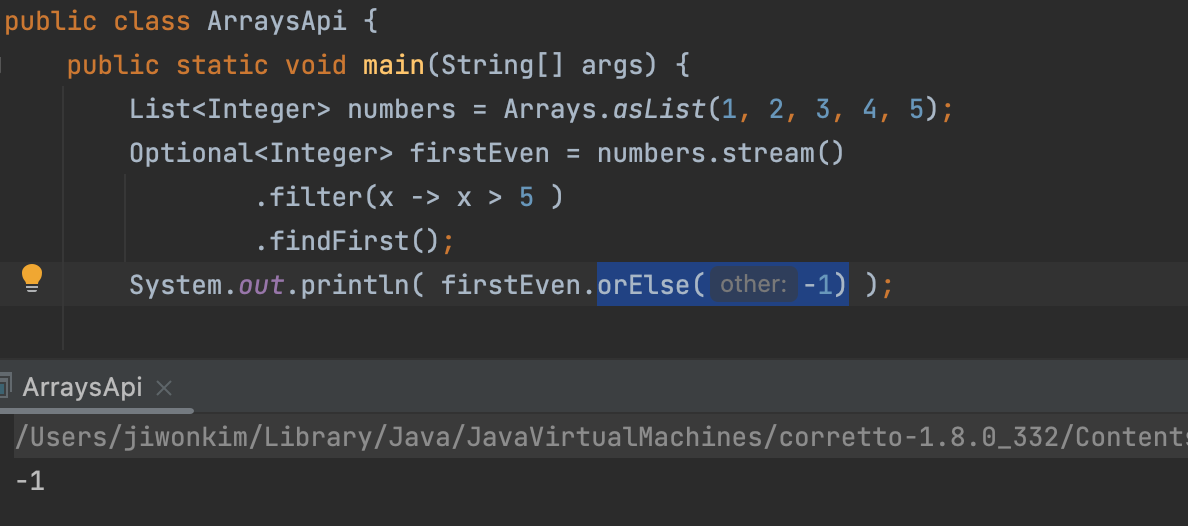
이렇게 작성하는 거랑 위에 거랑 같은 의미인데 orElse는 Integer을 반환함으로 반환타입이 Optional<Integer>이 아닌 Integer가 되어야한다.
의존성 관리자 Maven
의존성 관리자 Maven
: 의존성 관리자(Dependency Manage)는 해당 프로젝트가 어떠한 다른 프로젝트에 의존적인 부분을 관리한다.
- 의존성 관리자에는 종류가 여럿 있으나 주로 메이븐(Maven, XML 타입) 혹은 그래들(Gradle, YAML 타입)을 사용한다.
- 남이 만들어 놓은 것을 가져다 쓴다라는 것을 의존성을 추가한다라고 한다.
- 의존성 검색은 주로
https://mvnrepository.com에서 한다. (다른 방법도 많음)
→ buildSystem : Maven 으로 새로운 프로젝트 생성 (mavenStudy)
<프로젝트 루트>/pom.xml
: 메이븐 의존성 관리자의 파일이고 프로젝트의 이름, 버전 및 의존성 등에 대한 정보가 적혀있다.
<groupId>dev.jwkim</groupId> <artifactId>mavenstudy</artifactId> <version>1.0-SNAPSHOT</version>
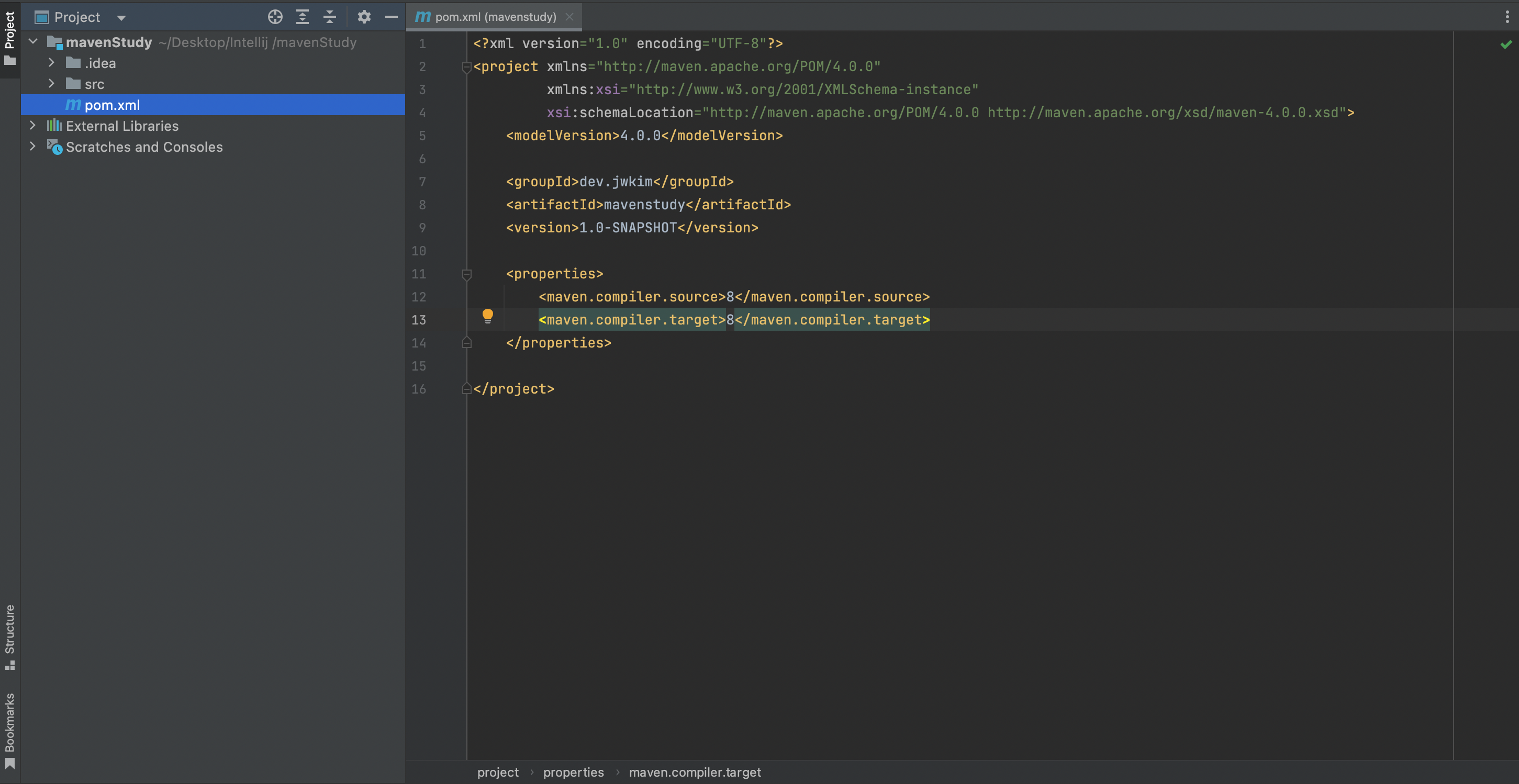
<groupId>
: 프로젝트 소유자 혹은 프롷젝트와 긴밀히 관련되어 있는 도메인의 역순
<artifactId>
: 의존성 관리자에서 식별 가능한 프로젝트의 이름
<version>
: 의존성 관리자에서 사용하는 프로젝트의 버전
<dependencies>
: 해당 프로젝트의 의존성을 나열한다.
많이 사용하는 의존성
Apache Commons Lang3 (org.apache.commons)
: Java 개발시 전역적으로 적용할 수 있는 편의 기능을 제공한다.
- 문자열, 숫자, 날짜 등과 관련된 것들의 편의기능
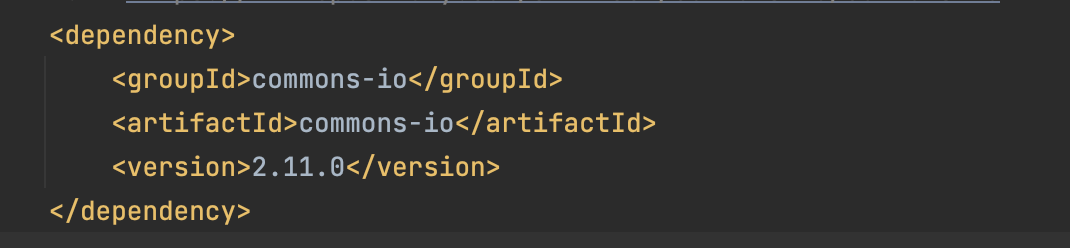
Apache Commons IO (org.apache.commons)
: 입출력과 관련된 편의기능을 제공한다.
- 파일 입/출력 등
commons lang3 / io는 대부분 개발을 할 떄 추가를 해놓고 시작한다. 그만큼 많이 사용을 한다.
JSON in Java (org.json)
: JSON 타입의 데이터 규격과 관련된 타입을 제공한다.
- JSON Object, JSON Array 등
Slf4j (rog.slf4j)
: 클래스 엔티티(Entity)와 관련된 어노테이션 및 편의기능을 제공한다.
- @Getter, @Setter 등
Apache Log4j (log4j)
: 로그와 관련된 기능을 제공한다.
- 매우 빠름
JUnit (junit)
: Java 단위 테스트(Unit Test)를 위한 기능을 제공한다.
MySQL Connector/J (mysql)
: MySQL DBMS에 JDBC 프로토콜을 이용하여 접속을 제공하기 위한 의존성
MariaDB Java Client (org.mariadb.jdbc)'> : MariaDB DBMS에 JDBC 프로토콜을 이용하여 접속을 제공하기 위한 의존성
본인이 상당한 개발 실력을 가진게 아니라면 의존성을 사용해야한다.
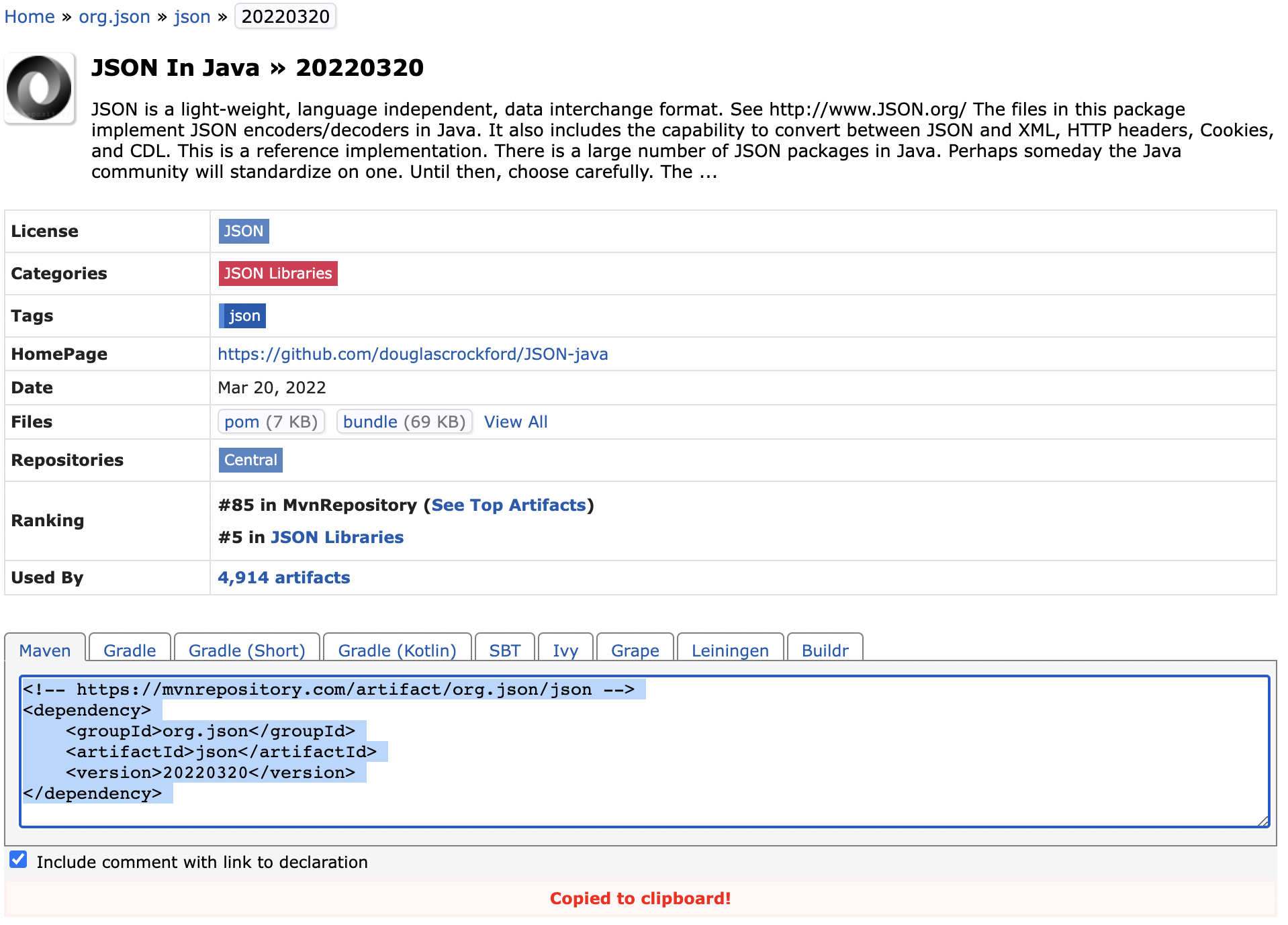
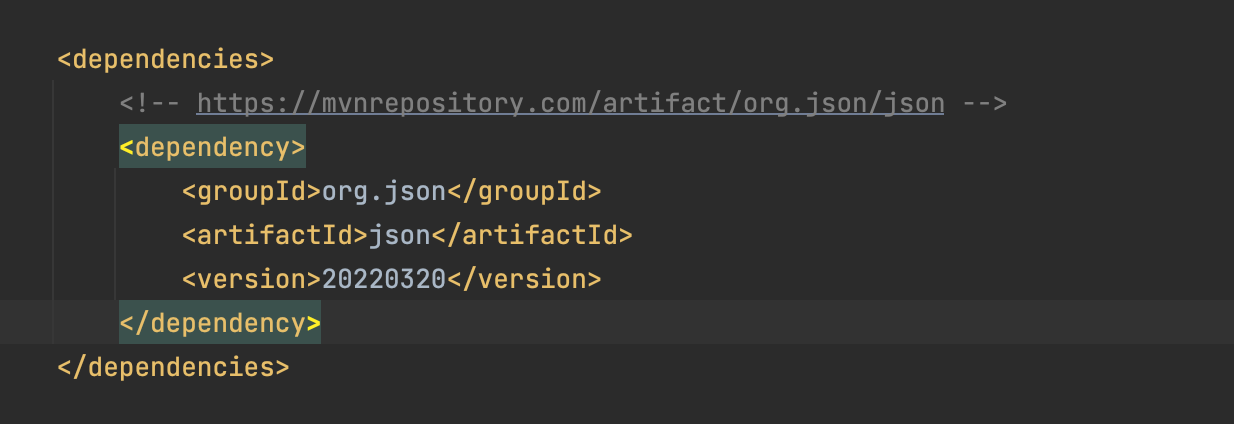
Dependency : JSON in Java
org.json : groupId JSON : artifactId
- 특별한 일이 아니면 최신버전을 사용한다.
- dependency 복사해서 pom.xml에 추가
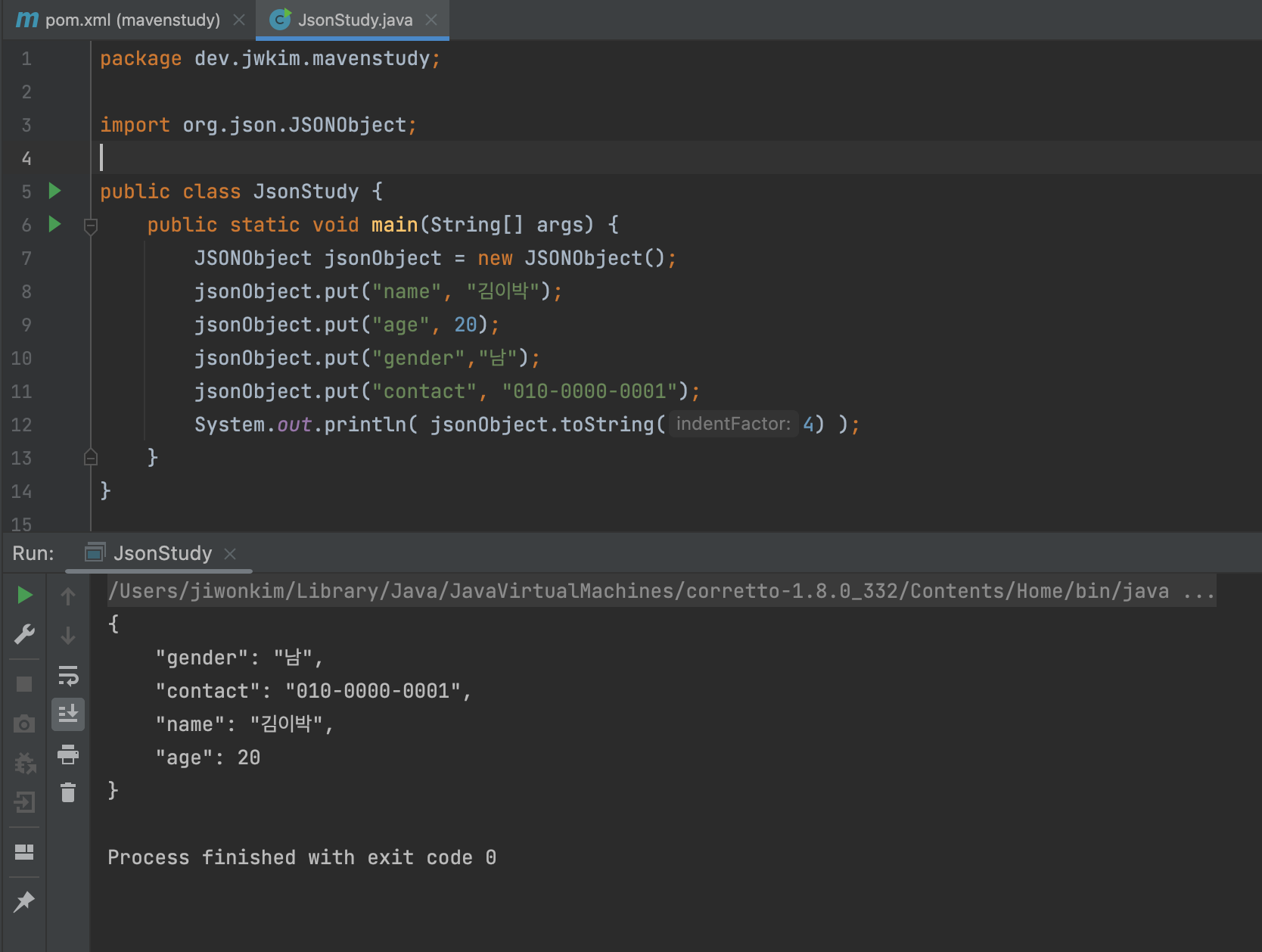
- 클래스에서 사용이 가능해진다.
- 물론 반대로도 가능하다.

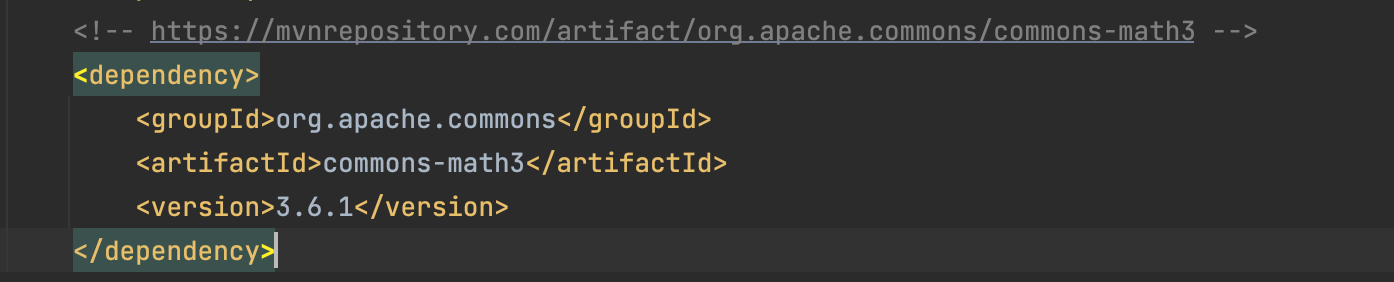
Dependency : apache commons math
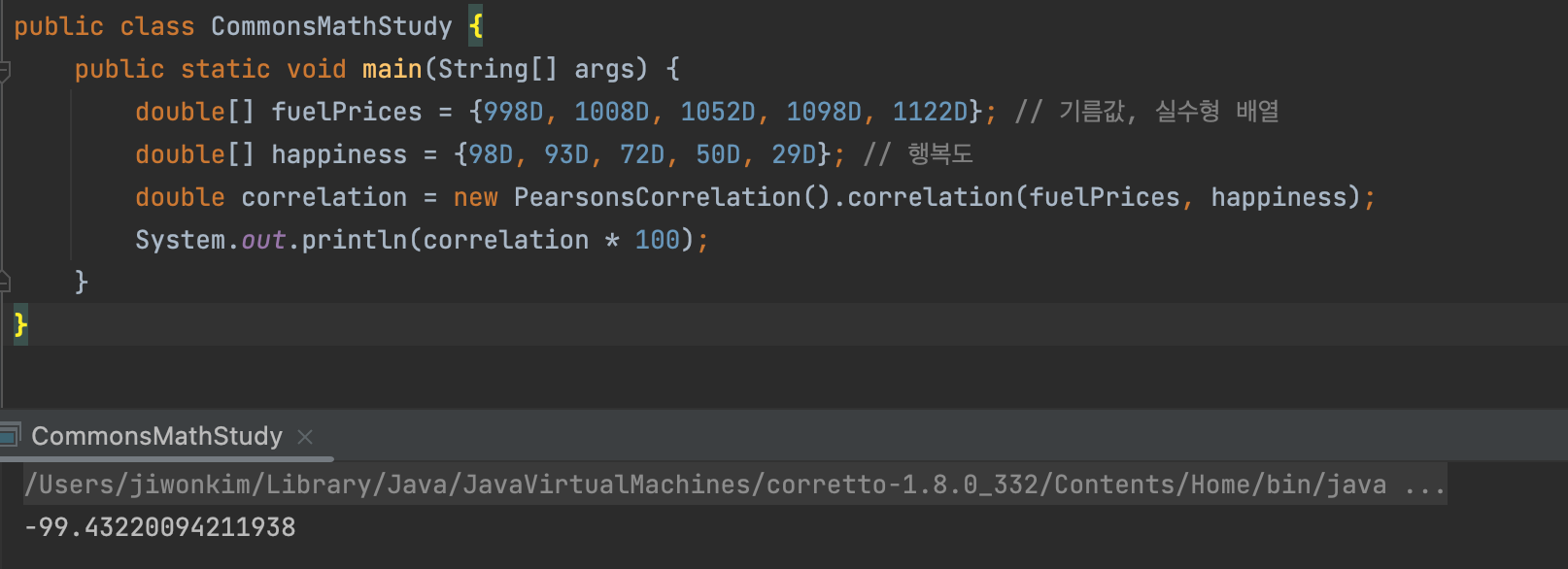
- 기름값이 올라감에 따라 행복도가 떨어지고 있다. 이 두 실수형 배열의 상관관계도를 계산해라 라고 했을 때 매우 힘들 것이다. 그렇기 떄문에 의존성을 사용해보자.
- 실수형 배열 두개를 받는
PearsonsCorrelation메서드를 사용해보자.
- 쉽게 계산이 된 것을 확인할 수 있다.



Dependency : apache commons lang
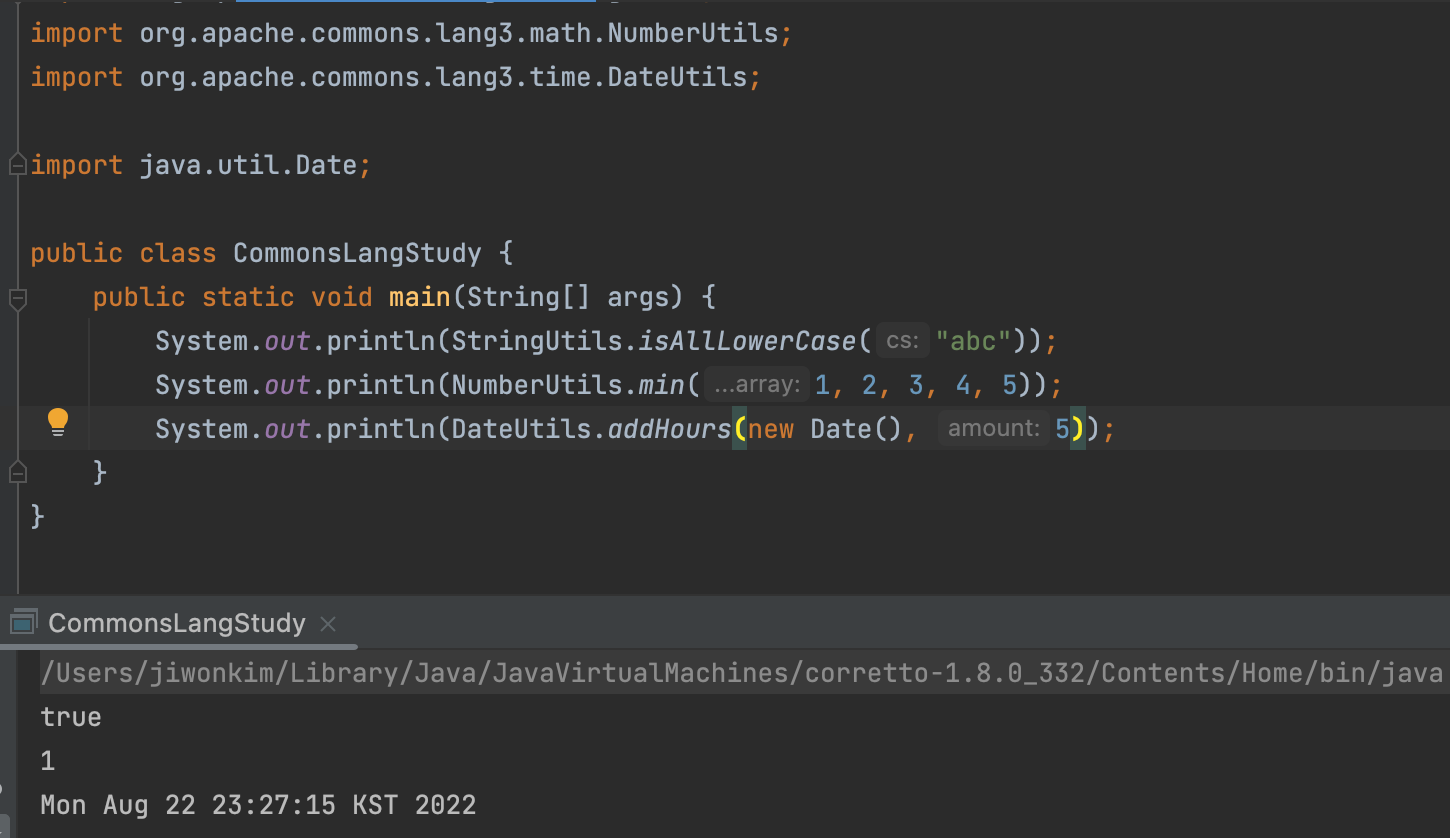
- 유틸리티성 클래스를 제공한다.
StringUtils.isAllLowerCase("abc") : 모두 소문자로 이루어져있는가에 대한 여부를 반환해주는 메서드 NumberUtils.min(1, 2, 3, 4, 5) : 최소 숫자 반환 메서드 DateUtils.addHours(new Date(), 5) : 시간을 더해서 반환해주는 메서드

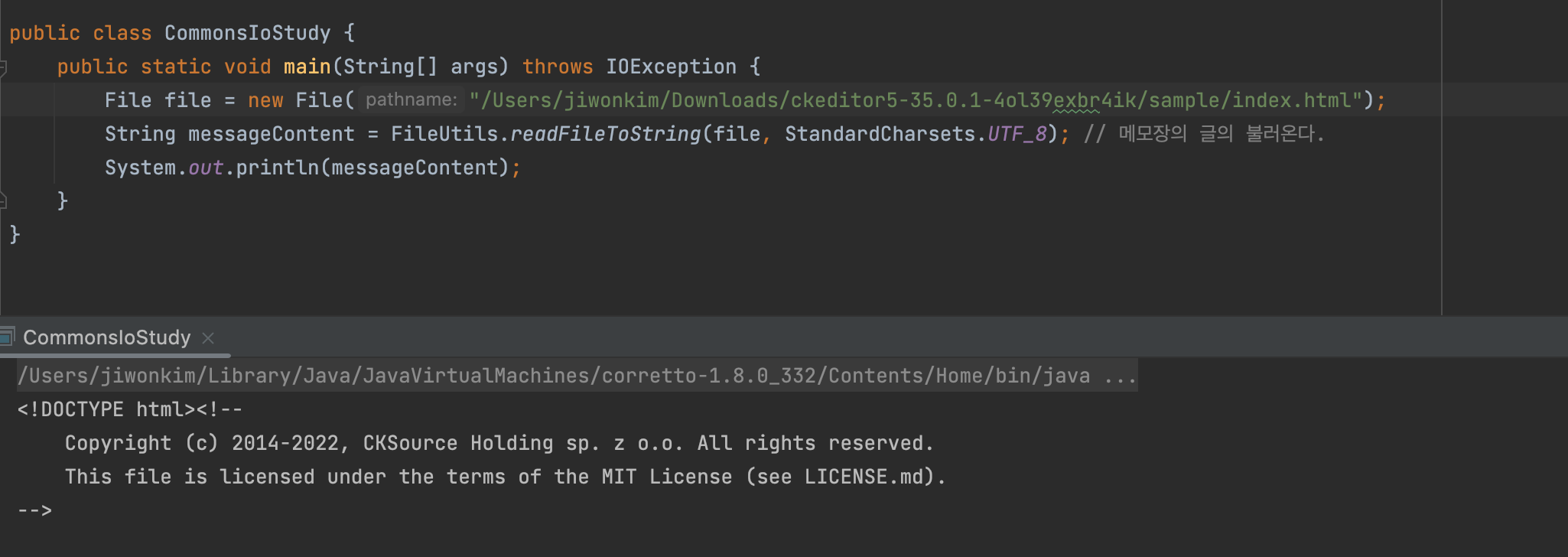
Dependency : apache commons io
- 해당 파일의 내용을 불러온다.

단위 테스트
: 프로젝트 전체를 실행하여 특정 기능을 테스트하는 것이 아닌 그 특정 기능을 분리하여 단위별로 테스트하는 것.
- 개발과 동시에 하나씩 하면서 해보는 편이다.
- 단위 테스트를 하는 방법은 많지만 JUnit 의존성을 추가하여 이를 통해 단위 테스트를 실시한다.
- 단위 테스트를 위한 클래스는
프로젝트/src/text/java안에 작성한다.
- 테스트용 그

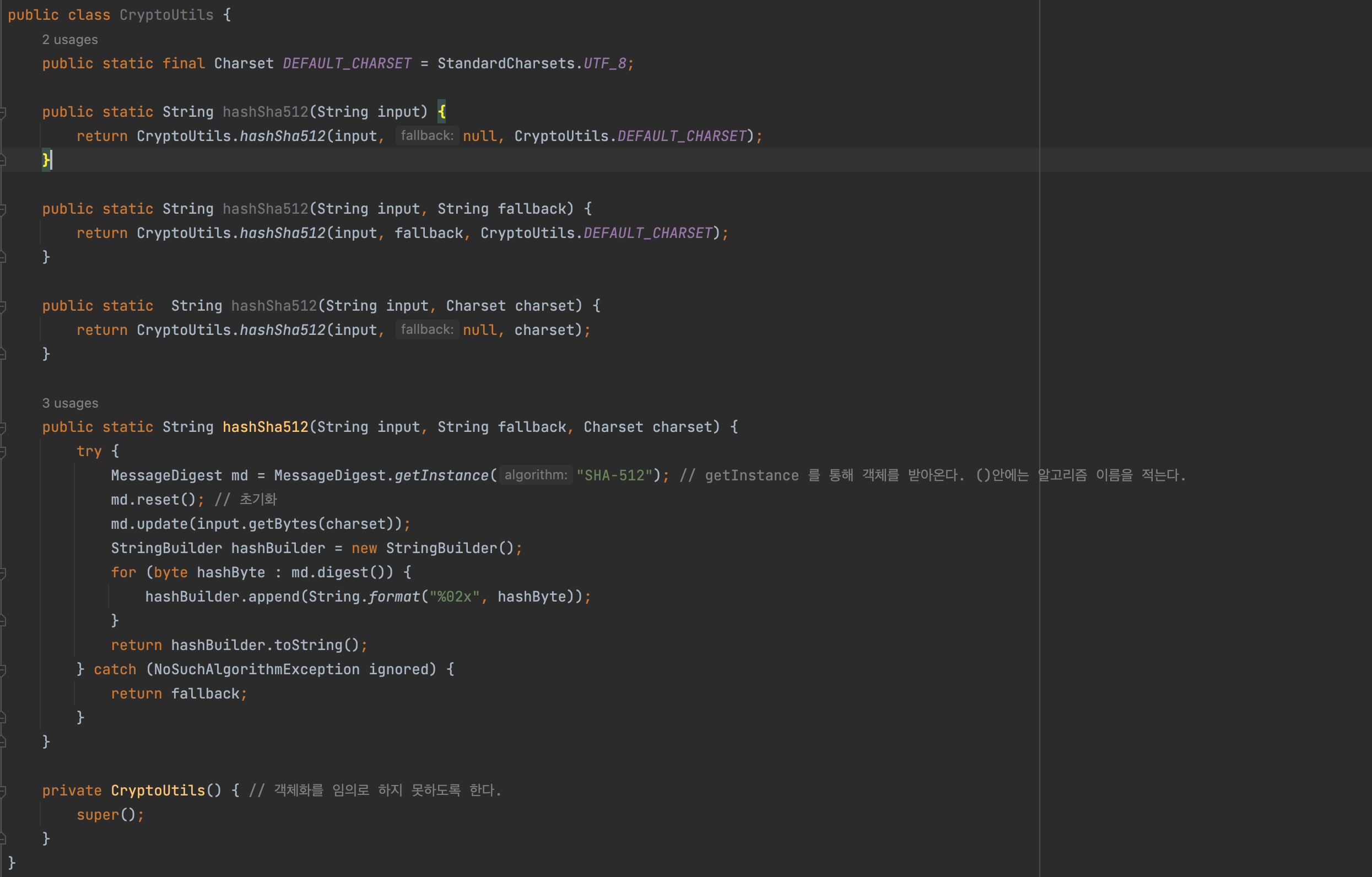
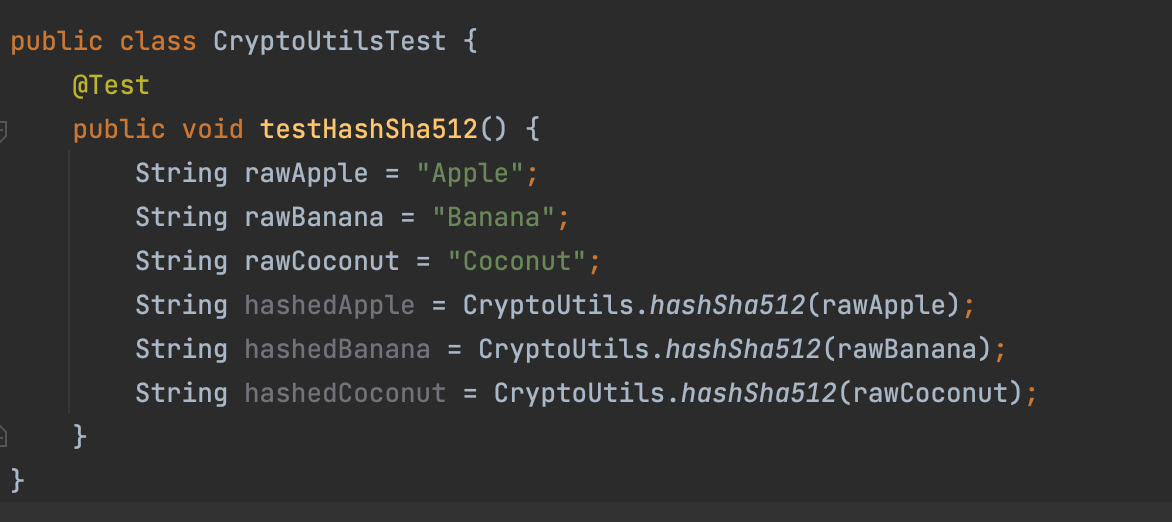
단방향 암호화 로직을 짜서 정상적으로 해싱이 되는지 테스트를 하자.
-> CryptoUtils 클래스
이제 테스트할 클래스를 만들어 CryptoUtils의 로직이 잘 짜져있는지 테스트 해보자.
- 테스트할 대상이 되는 클래스와 동일한 패키지 구조아래에 '대상 클래스 이름 + Test' 라는 이름을 가지는 테스트용 클래스를 만든다.
- 테스트용 클래스내에 메서드의 이름은 'test + 테스트할 대상 메서드 이름'으로 짓는다.
- 테스트 메서드에는 @org.junit.Test 어노테이션을 붙인다. (그래야 실행 됨)
- 이러한 과정을 통해서 테스트를 해볼 것이다.
hashedApple이 이렇게 해싱이 되는지 테스트 해보면 된다.
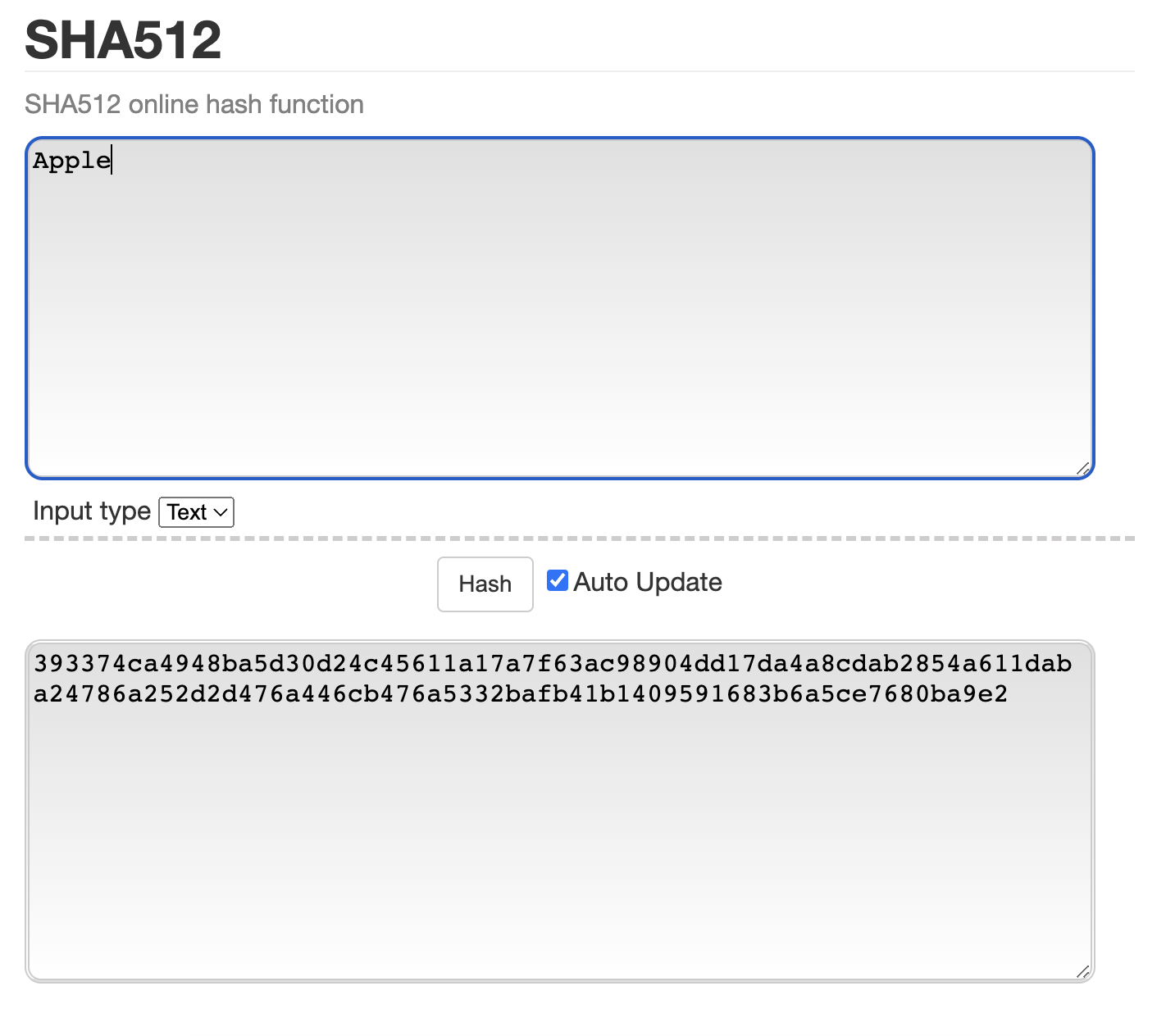
그전에 Assert에 대해서 알아야한다.
Assertion (가정 설정)
: org.junit.Assert 클래스 활용
정적 메서드
assertEquals(x, y)
: 참조 타입 객체 x와 y에 대해 .equals 메서드가 참이라고 가정. 거짓일 경우 테스트 실패.
assertNotEquals(x, y)
: 참조 타입 객체 x와 y에 대해 equals 메서드가 거짓이라고 가정. 참일 경우 테스트 실패.
assertSame(x, y)
: 참조 타입 객체 x와 y가 동일한 객체임을 가정. 다른 객체인 경우 단위 테스트 실패. ( == 비교 )
assertNotSame(x, y)
: 참조 타입 객체 x와 y가 다른 객체임을 가정. 같은 객체인 경우 테스트 실패. ( != 비교 )
assertArrayEquals(x, y)
: 참조 타입 배열 객체 x와 y에 대해 각 원소가 가지는 참조 타입 객체에 대한 .equals 메서드 결과가 모두 참임을 가정. 거짓일 경우 테스트 실패.
assertFalse(x)
: 주어진 조건 x가 거짓임을 가정. 참일 경우 테스트 실패.
assertTrue(x)
: 주어진 조건 x가 참임을 가정. 거짓일 경우 테스트 실패.
assertNull(x)
: 주어진 값 x가 null이라고 가정. null이 아닌 경우 테스트 실패.
assertNotNull(x)
: 주어진 값 x가 null이 아니라고 가정. null인 경우 테스트 실패.
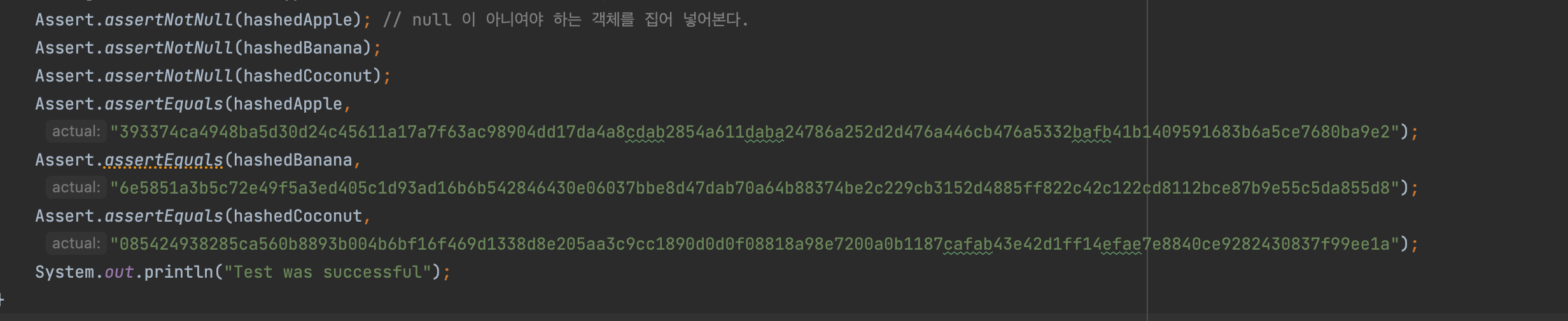
- hashing 된 애들이 null이 아님을 테스트하고 해싱된 결과랑 equals 한지 테스트한다.
Assert.assertNotNull(hashedApple); ↑ null 이 아니여야 하는 객체를 집어 넣어본다.Assert.assertEquals(hashedApple, "~~");
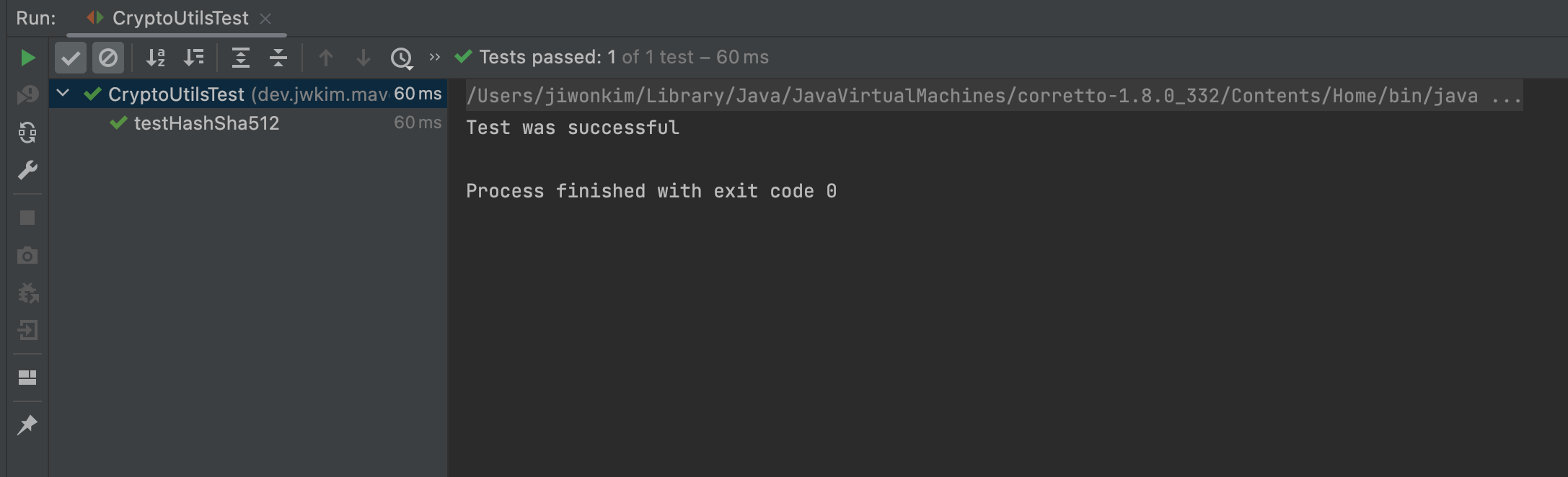
- 정상적으로 Test 통과를 했다는 결과를 볼 수 있다.
M2 로컬 저장소(Local Repository)
: 다른 프로젝트에서 개발했던 내용을 의존성으로 사용하기 위해 존재하는 개념이다. (mvnrepository.com의 나만의, 오프라인버전)
라이프 사이클(Life Cycle, 생애주기)
실행하는 라이프 사이클보다 하위 단계의 라이프사이클도 전체 자동 실행된다.
가령, install 실행시 clean → validate → compile → test → package → verify 가 모두 실행된 후 install이 실행된다.
원래는 알파벳순서대로 나열이 되어있을 것이다.
clean
: Maven을 통해 compile하거나 package하는 등의 행위로 인해 생긴 결과물을 제거한다.
validate
: 프로젝트 구조나 정보가 올바른지 확인만 한다.
compile
: 프로젝트가 가지고 있는 Java 파일을 Class 파일로 컴파일한다.
- compile을 누르면 target 이라는게 생기고 들어가보면 .java 파일이 아닌 .class 라는 파일로 저장이 되어있다.
test
: 테스트로 등록된 클래스의 메서드에 대한 검사를 실시한다.
package
: 'compile' 라이프사이클에서 생성된 class 들을 묶어서 JAR 혹은 WAR 파일로 만든다.
verify
: 'package' 된 파일이 올바른지 확인하고 테스트한다. (최종 점검)
install
: 최종 점검까지 끝난 패키지를 로컬 저장소에 저장한다. (기본적으로 M2)
site
: 프로젝트용 사이트를 생성한다.
deploy
: 설정된 Maven 원격 저장소에 해당 프로젝트를 배포한다.
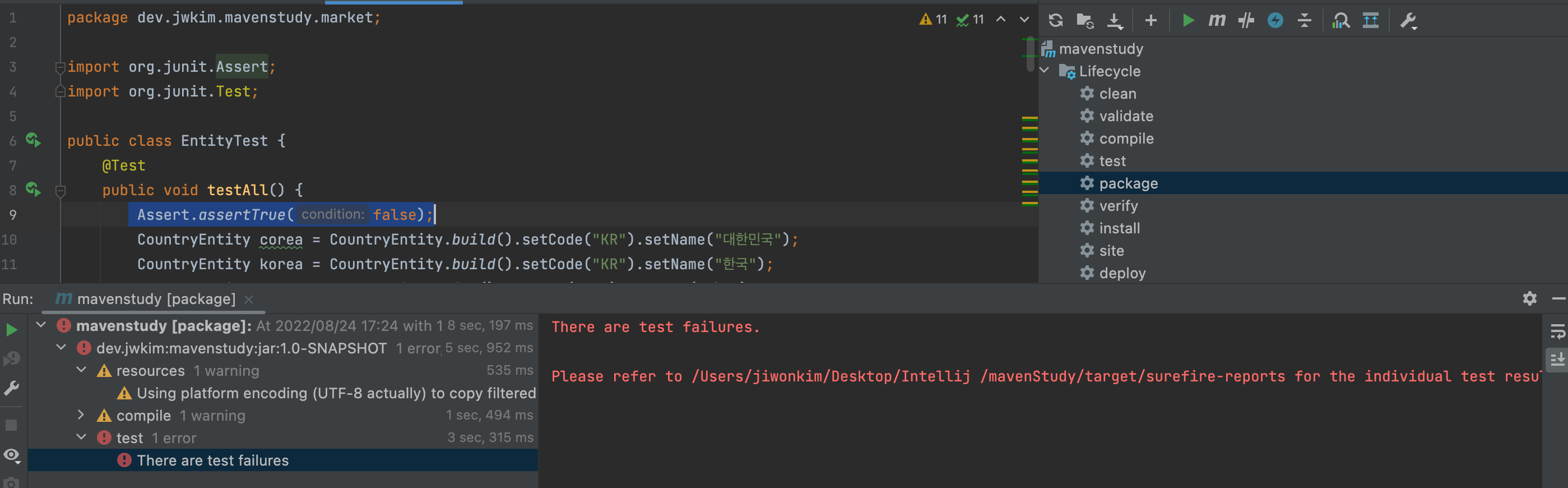
- Test를 실패하게끔 코드를 적어놓고 Package에서 실행을 해보았다.
테스트 실패가 뜨는 것을 당연한 것이고
- target에서 보면 class 파일이라는 것은 생겼지만 JAR 파일이 생기지 않았다. 즉, test를 실패했음으로 그아래의 단계인 package 가 그 다음으로 실행되지 않았기 때문에 JAR 이 생기지 않은 것이다. 그렇기 때문에 실무에서 test를 잘 사용해서 대참사를 막는 것이 중요하다.
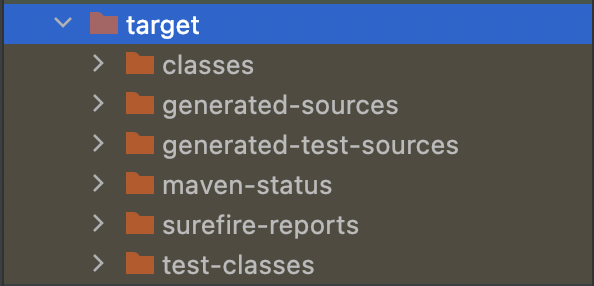
Java 코드를 class(확장명임) 파일로 바꿔주고 다 따로 들고다닐 수 없기 때문에 얘네를 묶어서 압축시킨다. 그렇게 압축된 것이 JAR(WAR)이다.
JAR(WAR)이 JVM에게 전달해주는데 JVM은 하드웨어에 직접 접근을 하지 않음으로 Kernel을 통해 절차를 밟는다.
JVM이 다시 압축을 풀어서 kernel을 통해 하드웨어가 이해할 수 있도록 기계어(?)로 변경을 해줌으로써 하드웨어에 전달을 할 수 있게 된다. (Java는 우리가 이해하기 쉽도록 적은 것이고 그대로 보내게 되면 하드웨어는 읽을 수 없다. )
