Affine Functions
Step #1. Weighted Sum :
z=w1x1+⋯+wlxl=(x)Tw
Step #2. Affine Transformation :
z=w1x1+⋯+wlxl+b=(x)Tw+b
Step #3. Affine Functions with n Features
(x)T=(x1…xl)∈R1×l
w=(w1…wl)∈Rl×1
b∈R
f((x)T;w,b)
z∈R
Activation Functions
Sigmoid (logit -> probability)
g(x)=σ(x)=1+e−x1
Tanh
g(x)=tanh(x)=ex+e−xex−e−x
ReLU
g(x)=ReLU(x)=max(0,x)
(z)T=(x1…xl)∈R1×l
w=(w1…wl)∈Rl×1
b∈R
f((x)T;w,b)
a∈R
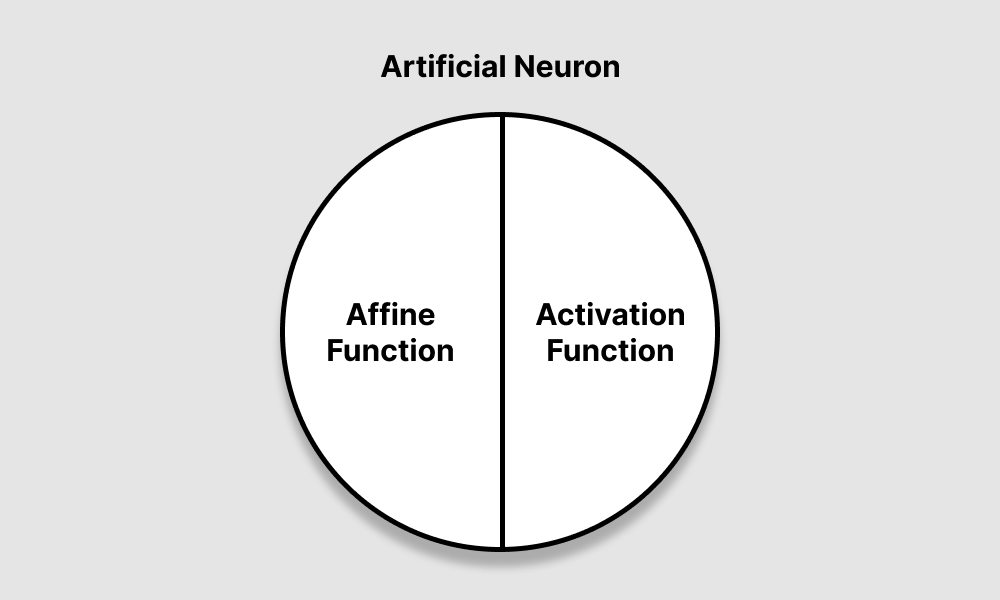
Artificial Neurons
mini-batch in Artificial Neurons
XT∈RN×l
neuron(x)=g(f((x)T;w,b);w,b)
A∈RN×1
XT∈RN×l
w=(w1…wl)∈Rl×1
b∈R
f(XT;w,b)
Z∈RN×1
Z∈RN×1
A∈RN×1
