🔎 JS의 숫자 정밀도에 따른 문제
📃 문제
https://school.programmers.co.kr/learn/courses/30/lessons/77885
오늘 2개 이하로 다른 비트 < 라는 문제를 풀고 있었을 때 생긴 문제다.
여러 정수를 배열로 받고 그 정수의 비트가 1 ~ 2개 다른 수들 중에서 가장 작은 수를 구하는 문제였다.
-
짝수일 경우
- 주어진 정수가
짝수일 경우에는 비트가 1개 다르다.
ex) 010 -> 2 / 011 -> 3-
이렇게 짝수일 경우는 마지막 비트가 0이기 때문에 단순히 비트를 1로 바꿔주면 다음 숫자가 된다.
-
그래서 짝수는 원래 숫자에 +1을 하게되면 비트가 1~2개 다른 수 중에 가장 작은 다음 수가 된다.
- 주어진 정수가
-
홀수일 경우
-
주어진 정수가
홀수일 경우에는 비트가 2개 다르다. -
가장 뒤에 있는 0을 찾아 1로 바꾸고 그 뒤에 있는 비트를 0으로 바꾸면 된다.
ex) 1001(9) -> 1011 -> 1010 -
위 방법을 이용해서 구한 풀이
function solution(numbers) {
const answer = [];
// 비트 마스크
for (let i = 0; i < numbers.length; i++) {
let num = numbers[i];
if (num % 2 === 0) {
answer.push(num+1)
} else {
let bit = 1;
// 가장 뒤에 있는 0을 찾을 때 까지 1을 왼쪽으로 이동
while((num & bit) !== 0) {
bit <<= 1;
}
// 1과 0의 위치를 뒤 바꿈
answer.push(num + bit - (bit >> 1));
}
}
return answer;
}하지만 테스트 케이스 10번, 11번이 틀렸다고 나온다.
이유인 즉슨 문제의 조건 사항에 있는
1 ≤ numbers의 길이 ≤ 100,000
0 ≤ numbers의 모든 수 ≤ 10^15
10^15인 경우에 숫자가 엄청커지기 때문에 js의 숫자 정밀도로 인해 생기는 문제였다.
엄청 큰 수를 넣어본 테스트 케이스
-
입력값 〉 [1000000000000000, 999999999999999]
-
기댓값 〉 [1000000000000001, 1000000000000001]
-
실행 결과 〉 실행한 결괏값 [1000000000000001,1000000000016383]이 기댓값 [1000000000000001,1000000000000001]과 다릅니다.
이처럼 엄청 큰 수일 경우 연산에서 오류가 발생해 값이 다르게 나타난다.
이유는 JS에서 숫자 데이터 타입에 따른 표현 방식 때문인데
-
Number 타입
-
JS의 Number 타입은 IEEE 754 표준인 64비트 부동 소수점 숫자를 사용하여 모든 숫자를 표현한다.
-
안전한 정수의 범위는 -2^53+1 ~ 2^53-1 까지 증 53비트 까지 정확히 저장할 수 있다.
-
정밀도 손실: 53비트 이상의 정수를 사용할 경우 정밀도 손실이 발생한다.
9007199254740992(2^53) 이후의 숫자는 정확하게 표현되지 않을 수 있다. -
부동 소수점 형식은 정밀도가 낮고, 10진수 소수를 이진수로 변환할 때 근사치로 표현될 수 있습니다. 이로 인해 0.1 + 0.2의 결과가 0.3이 아닌 0.30000000000000004가 되는 문제가 발생할 수 있다.
-
-
BigInt 타입
-
ES2020부터 도입된 BigInt는 임의의 정밀도를 가진 정수를 표현할 수 있다.
-
BigInt는 매우 큰 숫자를 저장할 수 있으며, 소수점이 없는 정수만을 다루며 이로 인해 큰 숫자의 연산에서 정밀도 손실이 발생하지 않는다.
-
표기법: BigInt는 숫자 뒤에 n을 붙여서 표기한다. 예를 들어, 123456789012345678901234567890n과 같이 사용한다.
-
Number와 BigInt는 서로 다른 타입이기 때문에, 이 둘 간의 연산은 직접적으로 수행할 수 없다. 연산을 수행하기 전에 둘 중 하나의 타입으로 변환해야 한다.
-
테스트 케이스의 숫자 1000000000000001는 53비트 범위 안에 있지만
JS에서 비트 연산을 수행할 때는 숫자를 32비트 정수로 변환하고 이 과정에서 부동 소수점에서 정수로 변환이 일어나 32비트 범위를 초과하게 되어 오류가 발생하게 되는 것이다.
💻 해결
해결법으로는 BigInt를 사용해서 연산하는 것이나 어째서인지 BigInt를 사용해도 프로그래머스 사이트에서는 정상적인 연산이 이루어지지 않았다.
하는 수 없이 숫자 연산을 포기하고 문자열 타입에서 숫자를 수정하는 방법으로 선회하여 해결하였다.
짝수일 경우엔 똑같고
홀수일 경우에는 마지막 0의 위치를 찾고 마지막 0 전까지의 문자열을 자르고
마지막 0 대신 1을 문자열에 더한 후 이후의 문자열에서 첫번째 1을 0으로 바꾸고
나머지 문자열을 더하면 이전 방식과 똑같은 방법이 된다.
이후 문자열을 십진수로 변환하면 홀수가 된다.
function solution(numbers) {
const answer = [];
for (const num of numbers) {
if (num % 2 === 0) {
answer.push(num+1)
} else {
let bit = "0" +num.toString(2);
let idx = bit.lastIndexOf("0");
const str = bit.slice(1,idx)+"1"+"0"+bit.slice(idx+2)
answer.push(parseInt(str,2));
}
}
return answer;
}🚗 객체 지향 프로그래밍(Object-Oriented Programming, OOP)

이미지 출처: https://www.linkedin.com/pulse/concepts-object-oriented-programming-oop-emran-khandaker-evan
❔ 객체 지향 프로그래밍이란?
프로그래밍 패러다임
프로그래밍 패러다임은 프로그래밍의 방식이나 관점을 바탕으로 효율적이고 명확한 코드를 작성하는 방법이다.
-
구조적 프로그래밍
- 기능 중심적인 개발 방법. 가장 처음 적용된 패러다임.
-
객체 지향 프로그래밍
- 프로그램 처리 단위가
객체인 방법. 현실 세계를 프로그램으로 모델링하는 가장 대표적인 프로그램 패러다임.
- 프로그램 처리 단위가
-
함수형 프로그래밍
- 함수 중심적인 개발 방법. 가장 초기에 만들어졌지만 최근에 주목받기 시작한 패러다임.
객체 지향 프로그래밍
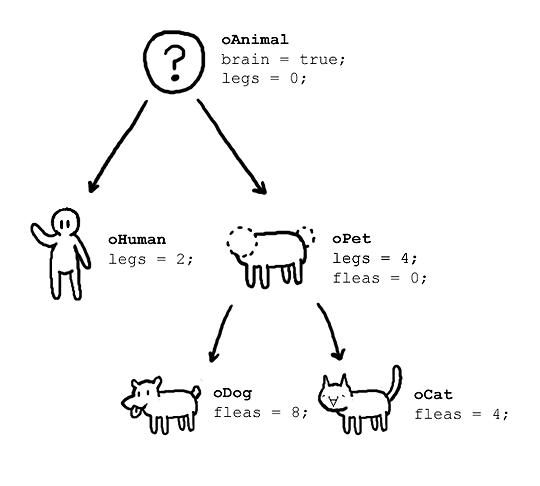
이미지 출처: https://www.reddit.com/r/ProgrammerHumor/comments/418x95/deleted_by_user/
객체 지향 프로그래밍이란
상태(데이터)와 그 데이터를 조작하는프로세스(메소드)가 같은 모듈 내부에 배치되는 프로그래밍 방식.
-
코드를 추상화하여 개발자가 더욱 직관적으로 사고할 수 있게 하는 프로그래밍 방법론.
-
자동차, 동물, 사람 등과 같은 현실 세계의 객체를 유연하게 표현 할 수 있다.
-
객체는 고유한 특성을 가지고 있고, 특정 기능을 수행할 수 있다.
객체 지향 프로그래밍 사용하는 이유
가독성이 좋아야하며, 재사용성이 높고, 유지보수가 쉬워야한다.
-
객체 지향 프로그래밍은 데이터와 기능이 밀접하게 연결되어 있기 때문에 코드의 구조와 동작을 직관적으로 파악할 수 있다.
-
하나의 객체에 정의된 기능이나 데이터 구조는 다른 객체에서도 쉽게 재사용할 수 있다. -> 코드의 재사용성과 확장성 향상 -> 개발 시간 효율적 관리
📑 객체 지향 프로그래밍의 핵심 원칙
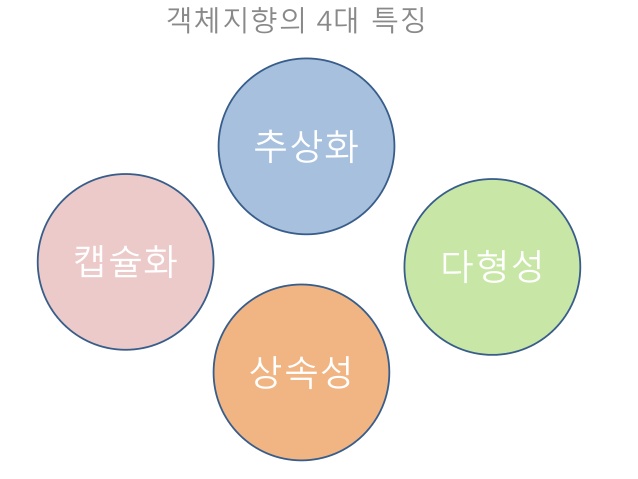
이미지 출처: https://shjz.tistory.com/94
캡슐화(Encapsulation)
객체 내부의 세부적인 사항을 감추는 것, 중요한 정보를 외부로 노출시키지 않도록 만드는 것을
캡슐화(Encapsulation)라고 한다.
-
JS에서는 완벽한 캡슐화를 지원하지 않음 -> 변수 앞에
언더바(_)를 붙여 내부의 변수를 숨긴 것 처럼 나타내는규칙을 따른다. -
typescript에서는
private접근 제한자를 사용하여, 인스턴스 내부에서만 해당 변수에 접근 가능하도록 제한하는 문법을 사용한다. -
getter, setter 메소드로 내부 변수에 값을 가져오거나 설정할 수 있다.
-
ES2019부터는 변수 앞에 #을 붙여서 private 필드로 정의할 수 있다.
-
클로저를 활용해 데이터를 보호할 수도 있다.
상속(Inheritance)
상속은 하나의 클래스가 가진 특징(힘수, 변수 및 데이터)를 다른 클래스가 물려받는 것.
-
상위 클래스의 특징을 하위 클래스가 그대로 물려받아 코드의 중복을 제거, 재사용성을 높이고, 일관성을 유지한다.
-
개별 클래스를 상속 관계로 묶어 클래스 간의 체계화된 구조를 쉽게 파악할 수 있다.
추상화(Abstraction)
객체에서 공통된 부분을 모아 상위 개념으로 새롭게 정의하는 것을
추상화(Abstraction)라고 한다.
-
불필요한 세부 사항을 생략하고, 중요한 특징만 강조함으로써 코드를 더욱 간결하고 관리하기 쉽게 만드는 원칙.
-
전체 시스템의 구조를 명확하게 이해하고, 테스트를 더욱 쉽게 작성할 수 있게 된다.
-
클래스 설계시 공통적으로 묶일 수 있는 기능을 추상화 -> 추상 클래스 -> 인터페이스 순으로 정리하면 여러 클래스 간의 일관성을 유지하면서 다양한 형태로 확장될 수 있는 코드, 즉
다형성(Polymorphism)이 가능해진다. -
인터페이스란 클래스를 정의할 때 메소드의 속성만 정의하여 인터페이스에 선언된 프로퍼티 또는 메소드의 구현을 강제하여 코드의 일관성을 유지하게 한다.
다형성(Polymorphism)
다형성(Polymorphism)은 하나의 객체(클래스)가 다양한 형태로 동작하는 것. 즉, 객체가 가진 특성에 따라 같은 기능이 다르게 재구성되는 것
-
다형성은 역할(인터페이스)과 구현을 분리하게 해준다. -> 오버라이딩을 통해 특정 서비스의 기능을 유연하게 변경하거나 확장할 수 있다. -
오버라이딩은 상속받은 부모의 메소드를 재정의하는 것을 의미한다. -
JS에서는 인터페이스와 추상 클래스 개념이 존재하지 않아서 흉내는 낼 수 있지만 하위 클래스에서 메소드 등의 구현을 강제할 수 없다. TS에선 존재하기 때문에 TS를 많이 사용한다.
🛠 객체 지향 설계 5 원칙 (SOLID)
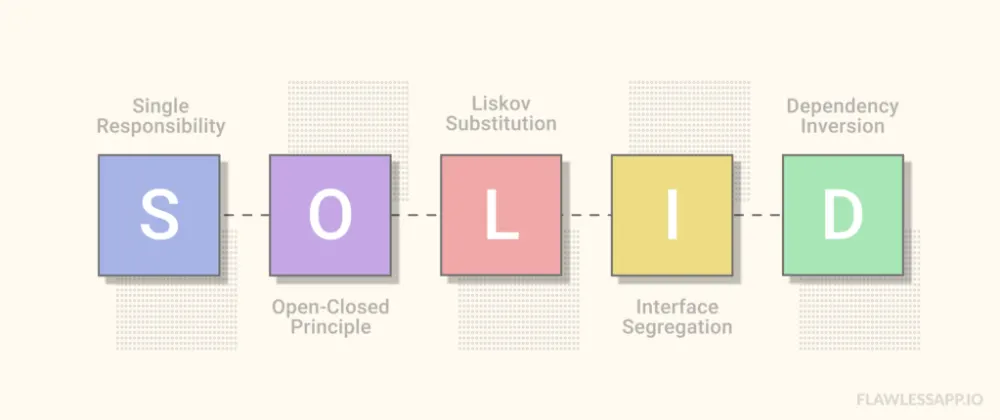
단일 책임 원칙 (Single Responsibility Principle, SRP)
하나의 객체는 단 하나의 책임만 가져야한다.
-
책임이라는 개념을 정의하며 적절한 클래스의 크기를 제시한다.
-
객체 지향 설계에서 중요한 개념이며, 다르기 쉬운 개념인 동시에 프로그래머가 가장 무시하는 규칙 중 하나이다.
-
일반적인 프로그래머는 동작하기만 하는 소프트웨어에 초점을 맞추기 때문.
개방-폐쇄 원칙 (Open-Closed Principle, OCP)
소프트웨어 엔티티 또는 개체(클래스, 모듈, 함수 등)는 확장에는 열려 있으나 변경에는 닫혀 있어야 한다.
- 기존 코드에 영향을 주지 않고 새로운 기능이나 구성 요소를 추가할 수 있어야 한다.
리스코프 치환 원칙 (Liskov substitution principle, LSP)
어플리케이션에서 객체는 프로그램의 동작에 영향을 주지 않으면서, 하위 타입의 객체로 바꿀 수 있어야 한다.
-
부모 클래스와 자식 클래스를 가지고 있다면, 이 두 클래스의 객체를 서로 바꾸더라도 해당 프로그램에 문제가 없어야 한다는 원칙.
-
메소드 체이닝은 사슬에 이어진 고리처럼 함수를 호출할때 객체를 반환하면, 객체안에 있는 메서드를 줄줄이 이어서 호출을 할수 있는 패턴을 말한다.const calc ={ originNum:0, setNum(num){ this.originNum = num; }, addNum(num){ this.originNum += num; }, substractNum(num){ this.originNum -= num; }, multiplyNum(num){ this.originNum *= num; }, divideNum(num){ this.originNum /= num; } } calc.setNum(10); calc.addNum(5); calc.substractNum(2); calc.multiplyNum(6); calc.divideNum(4); console.log(calc.originNum);메소드 체이닝 사용 후
const calc ={ originNum:0, setNum(num){ this.originNum = num; return this; }, addNum(num){ this.originNum += num; return this; }, substractNum(num){ this.originNum -= num; return this; }, multiplyNum(num){ this.originNum *= num; return this; }, divideNum(num){ this.originNum /= num; return this; } } calc.setNum(10).addNum(5).substractNum(2).multiplyNum(6).divideNum(4); console.log(calc.originNum);
인터페이스 분리 원칙 (Interface segregation principle, ISP)
특정 클라이언트를 위한 인터페이스 여러 개가 범용 인터페이스 하나보다 낫다.
- 사용자가 필요하지 않은 것들에 의존하지 않도록, 인터페이스는 작고 구체적으로 유지해야 한다.
의존성 역전 원칙 (Dependency Inversion Principle, DIP)
프로그래머는 추상화에 의존해야하며, 구체화에 의존하면 안된다.
-
고수준 계층의 모듈(도메인)은 저수준 계층의 모듈(하부 구조)에 의존해서는 안된다. 둘 다 추상화에 의존해야 한다.
-
고수준 계층의 모듈이 저수준 계층의 모듈을 의존하게 될 경우 사소한 변경 사항에도 고수준 계층의 코드를 변경해야할 것이고, 소모되는 개발 코스트또한 증가할 것이다.
-
의존성 주입(Dependency Injection)은 객체가 다른 객체에 대한 의존성을 외부에서 주입받도록 하는 설계 패턴이다.-
객체가 직접 의존성을 생성하지 않기 때문에 클래스 간의 결합도가 낮아 코드 수정 시 영향 범위가 줄어든다.
-
의존성 주입을 통한
모의 객체(mock)를 주입하여 단위 테스트를 쉽게 수행할 수 있다. -
주입된 의존성을 쉽게 교체할 수 있어, 요구 사항이 변경될 때 재사용성, 확장성이 높아진다.
-
생성자 주입, 메소드 주입, 프로퍼티 주입 등의 의존성 주입이 있다.
-
🧱 아키텍처 패턴 (Architecture Pattern)
아키텍처 패턴
아키텍처 패턴이란?
아키텍처 패턴은 소프트웨어의 구조를 구성하기위한 가장 기본적인 토대를 제시한다.
-
아키텍처 패턴은 각각의 시스템들과 그 역할이 정의되어 있고, 여러 시스템 사이의 관계와 규칙 등이 포함되어 있다.
-
검증된 구조로 개발을 진행하기 때문에 안정적인 개발이 가능하다.
-
복잡한 도메인 문제를 해결할 때, 아키텍처 패턴을 사용하면 모델이나 코드를 더 쉽게 변경할 수 있다는 측면에서 큰 이익을 얻을 수 있다.
대표적인 아키텍처 패턴
MVC 패턴(Model View Controller Pattern)
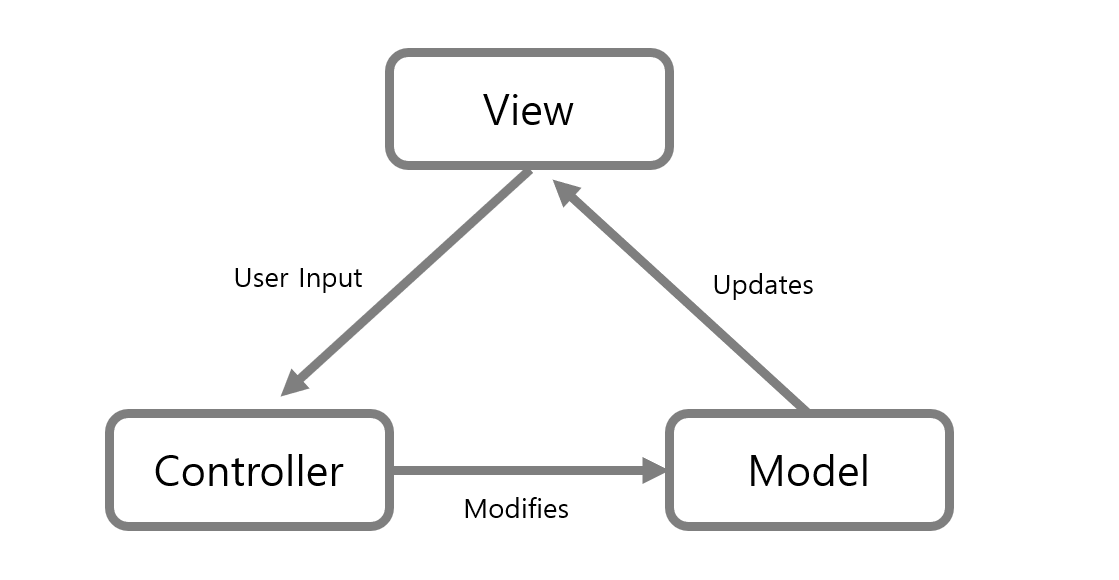
이미지 출처: https://cocoon1787.tistory.com/733
-
사용자 인터페이스(UI)가 필요한 어플리케이션에서 많이 사용되는 패턴이다.
-
모델(Model)은 데이터와 비즈니스 로직을 담당한다.
-
뷰(View)는 사용자 인터페이스(UI)를 담당한다.
-
컨트롤러(Controller)는 클라이언트의 요청을 모델과 뷰로 전달해주는 역할을 담당한다.
계층형 아키텍처 패턴(Layered Architecture Pattern)
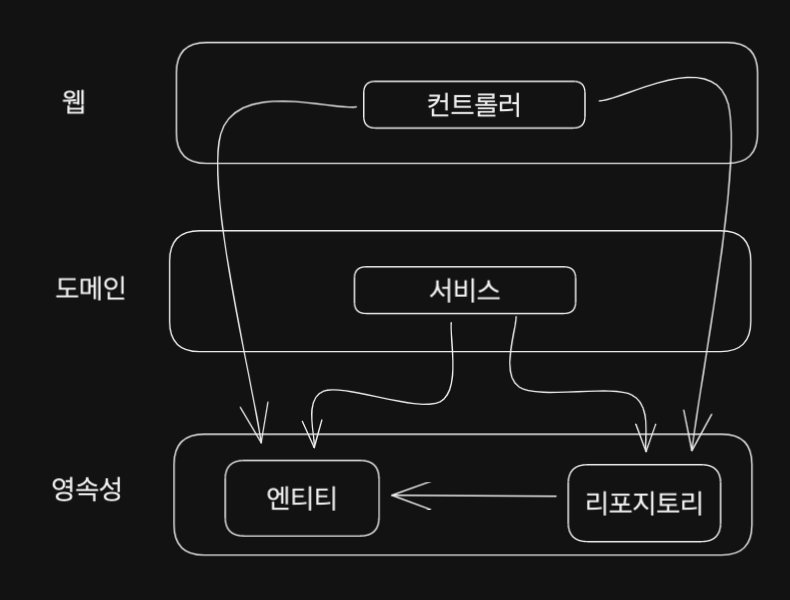
-
시스템의 서로 다른 기능을 여러 계층(Layer)으로 분할하는 패턴이다.
-
일반적으로 컨트롤러(Controller), 서비스(Service), 저장소(Repository) 계층으로 분리된다.
클린 아키텍처 패턴(Clean Architecture)
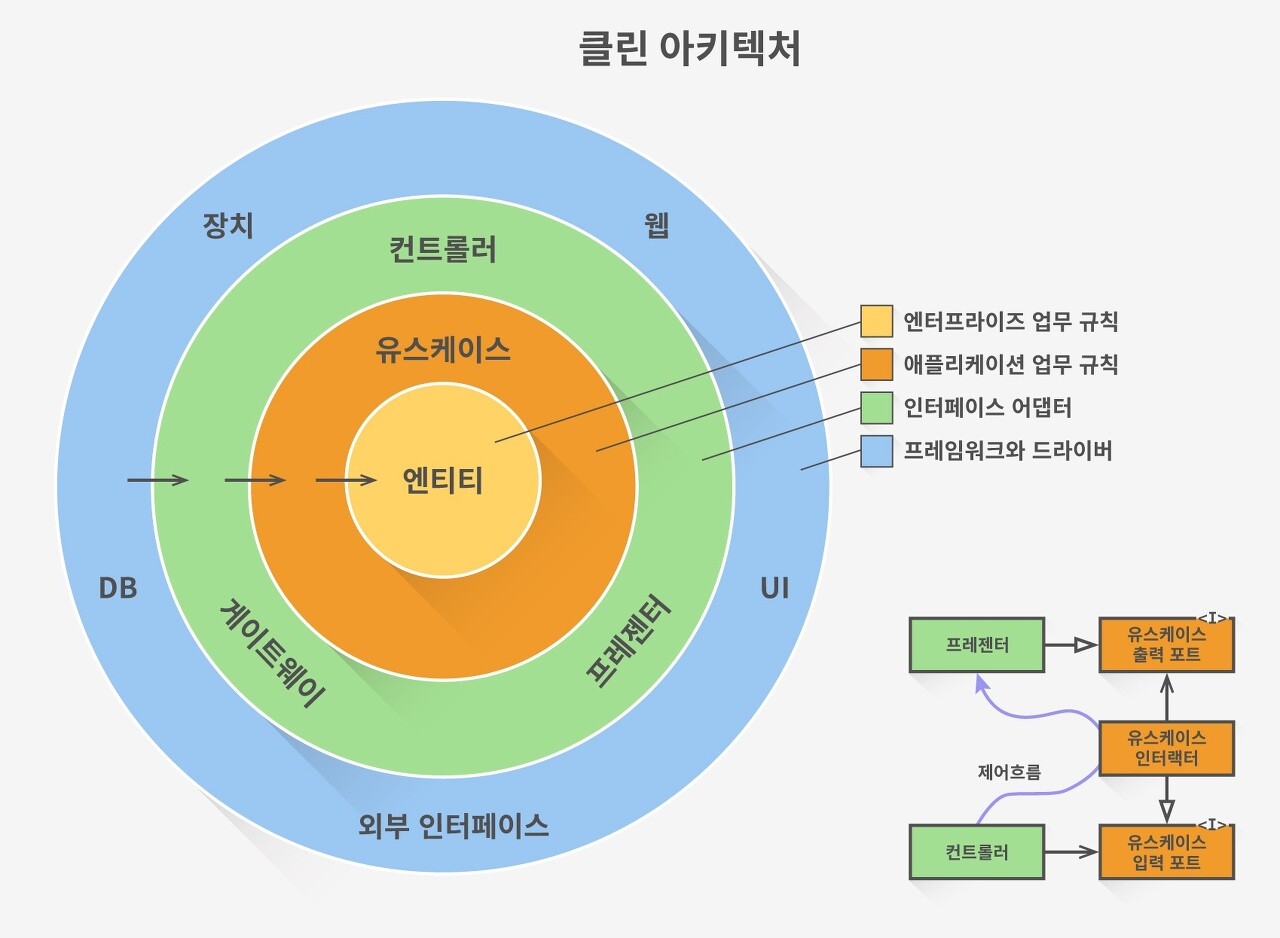
이미지 출처: https://6mini.github.io/software%20architecture%20pattern/2022/12/20/clean-architecture/
-
소프트웨어를 내부 도메인으로 향하는 의존성을 가지는 여러 계층으로 분리하는 패턴이다.
-
클라이언트의 요청 처리, 데이터베이스 조작, 외부 시스템과의 통신은 외부 계층에서 처리한다.
-
소프트웨어의 유지보수성과 확장성을 향상시키는 것이 주요 목표이다.
마이크로 서비스 아키텍처 패턴(Microservices Architecture Pattern)
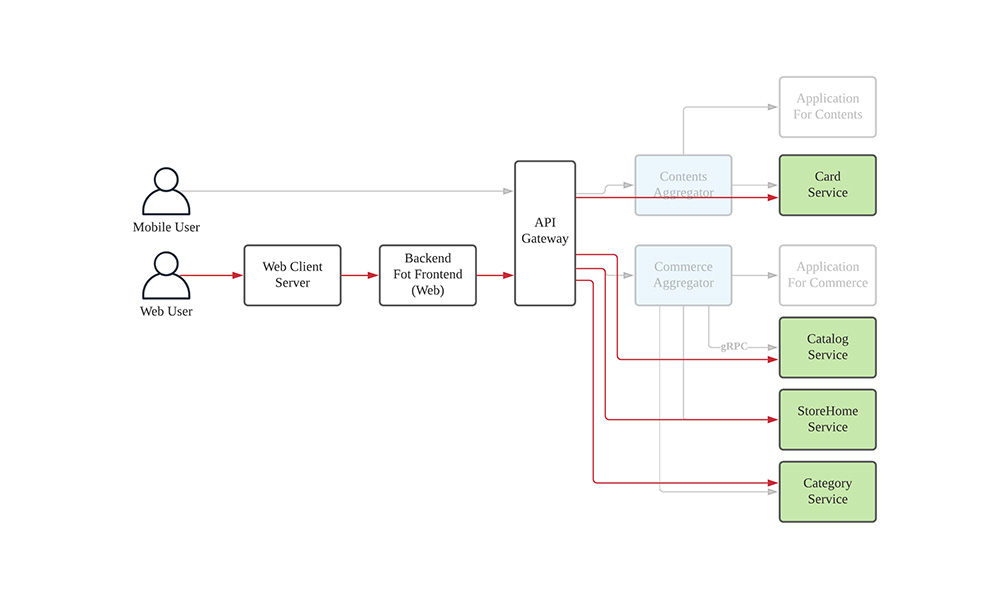
-
시스템을 작고, 독립적으로 배포 가능한 서비스로 분할하는 패턴이다.
-
하나의 시스템에서 다양한 언어와 프레임워크를 도입할 수 있는 패턴이다.
-
서비스 간의 통신은 API 또는 이벤트 기반 아키텍처(EDA, Event Driven Architecture)를 통해 통신한다.
🌫 계층형 아키텍처 패턴 (Layered Architecture Pattern)
계층형 아키텍처 패턴이란?
계층형 아키텍처 패턴(Layered Architecture Pattern)은 시스템을 여러 계층으로 분리하여 관리하는 아키텍처 패턴이다.
-
단순하고 대중적이고 비용도 적게 들어 사실상 표준 아키텍처이다.
-
각 계층을 명확하게 분리해서 유지하고, 각 계층이 자신의 바로 아래 계층에만 의존하게 만드는 것이 목표이다.
-
계층화의 핵심은 각 계층이 높은 응집도를 가지면서 다른 계층과는 결합도를 최소화 하는 것이다. -
상위 계층은 하위 계층을 사용할 수 있지만 하위 계층은 독립적으로 동작할 수 있어야 한다.
-
계층형 아키텍처 패턴의 경우 규모가 작은 어플리케이션의 경우 3개의 계층, 크고 복잡한 경우는 그 이상의 계층으로 구성된다.
-
3계층 아키텍처
-
프레젠테이션 계층 (Presentation Layer)
-
비즈니스 로직 계층 (Business Logic Layer)
-
데이터 엑세스 계층 (Data Access Layer) | 영속 계층(Persistence Layer)
-
계층형 아키텍처 패턴의 장점
-
관심사를 분리하여 현재 구현하려는 코드를 명확하게 인지할 수 있다.
-
각 계층은 서로 독립적이며, 의존성이 낮아 모듈을 교체하더라고 코드 수정이 용이하다.
-
각 계층 별로 단위 테스트를 작성할 수 있어 테스트 코드를 조금 더 용이하게 구성할 수 있다.
3계층 아키텍처
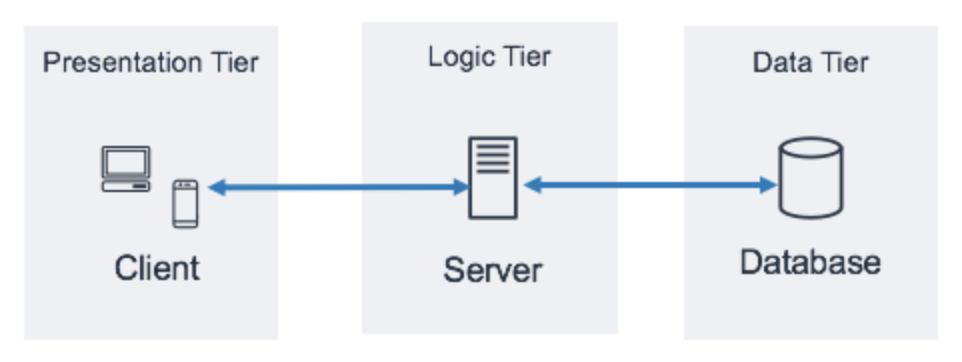
이미지 출처: Three-tier architecture overview - AWS Documentation
-
3계층 아키텍처의 수행 순서
1.
클라이언트(Client)가 어플리케이션에 요청(Request)을 보낸다.2.
요청(Request)을 URL에 알맞은 컨트롤러(Controller)가 수신 받는다.3.
컨트롤러(Controller)는 요청을 처리하기 위해 서비스(Service)를 호출한다.4.
서비스(Service)는 필요한 데이터를 가져오기 위해 저장소(Repository)에게 데이터를 요청한다.5.
서비스(Service)는 저장소(Repository)에서 가져온 데이터를 가공하여 컨트롤러(Controller)에게 데이터를 전달한다.6.
컨트롤러(Controller)는 서비스(Service)의 결과물(Response)을 클라이언트(Client)에게 전달해준다.
-
컨트롤러 - 어플리케이션의 가장 바깥 부분, 요청/응답을 처리
-
클라이언트의 요청(Request)을 받는다.
-
요청에 대한 처리는 서비스에게 위임한다.
-
클라이언트에게 응답(Response)을 반환한다.
-
-
서비스 - 어플리케이션의 중간 부분, API의 핵심적인 동작이 많이 일어나는 부분
- 사용자의 요구사항을 직접적으로 처리한다.
- 현업에서는 서비스 코드가 계속 확장되는 문제가 발생할 수 있다.
- DB 정보가 필요할 때는 Repository에게 요청한다.
- 사용자의 요구사항을 직접적으로 처리한다.
-
저장소 - 어플리케이션의 가장 안쪽 부분, 데이터베이스와 맞닿아 있다.
-
데이터베이스 관리 (연결, 해제, 자원 관리) 역할을 담당한다.
-
데이터베이스의 CRUD 작업을 처리한다.
-
