
다변수 함수(Multivariate Functions)와 그래디언드(Gradients)
아래 그림에서 f(x1, x2)는 x1과 x2라는 두 개의 변수를 입력으로 받아
y라는 하나의 값을 출력하는 함수이다.
이 함수의 그래디언트 벡터 ∇f(x1, x2)는 다음과 같다
∇f(x1, x2) = ( ∂f/∂x1 , ∂f/∂x2 )
즉, x와 y에 대한 편미분값을 각각 벡터의 요소로 하는 벡터이며
이 그래디언트 벡터는 함수의 최대값이나 최소값을 찾는 데 유용하게 사용된다.
그래디언트 벡터의 크기는 함수의 변화율을 나타내며,
이 크기가 가장 큰 방향으로 이동하면 함수 값이 가장 크게 증가한다.
따라서 최대값을 찾으려면 그래디언트 벡터의 크기가 최대인 지점을 찾으면 된다.
반대로, 그래디언트 벡터의 크기가 가장 작은 방향으로 이동하면 함수 값이 가장 작게 감소하므로 최소값을 찾으려면 이 방향으로 이동하면 된다.

아래 그림은
▽x f(x) = ∂f / ∂x는 다변수 함수 f(x)의 그래디언트 벡터를 x에 대한 편미분으로 나타낸 것입니다.
여기서 ∇x f(x)는 f(x)의 그래디언트 벡터를 나타내는데, 이 벡터는 각 입력 변수에 대한 편미분값으로 이루어진 벡터이다.
∇x f(x) = ( ∂f / ∂x1 , ∂f / ∂x2 , ..., ∂f / ∂xn )
따라서 이 벡터의 x에 대한 편미분은 그래디언트 벡터의 x1, x2, ..., xn 중에서 x에 해당하는 변수의 편미분값이 된다. 따라서 이를 간단히 ∂f / ∂x로 표기할 수 있다.
즉, 주어진 식은 그래디언트 벡터의 x에 대한 편미분값이 x에 대한 편미분값과 같다는 것을 나타낸다.
이는 다변수 함수의 편미분을 이용하여 그래디언트 벡터를 구할 수 있다는 것을 의미한다.
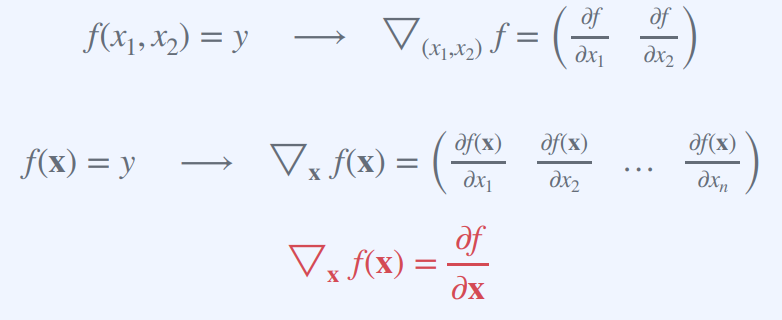
참고)
그래디언트 벡터는 다변수 함수의 모든 입력 변수에 대한 편미분값들을 모아서 만든 벡터이다.
각 입력 변수에 대한 편미분값들을 벡터로 모아놓은 것이기 때문에 벡터로 표현된다.
그래디언트 벡터는 함수의 입력값을 어느 방향으로 조금씩 바꿔가면서 함수값이 가장 크게 증가하는 방향을 가리키는 벡터이다.
이 벡터를 따라 함수의 입력값을 변화시키면 함수값이 가장 빨리 증가하게 된다.
따라서 그래디언트 벡터는 함수의 최댓값을 찾는 데에 유용하게 사용된다.
예를 들어, 함수 f(x,y) = x^2 + y^2의 그래디언트 벡터는 (2x, 2y)이다.
이 벡터는 함수 f(x,y)의 입력값 (x,y)를 어느 방향으로 바꿔야 함수값이 가장 크게 증가하는지를 나타낸다.
예를 들어, 입력값이 (1,2)인 경우 그래디언트 벡터는 (2,4)가 되며, 입력값을 이 벡터 방향으로 조금씩 바꾸면 함수값이 가장 빨리 증가하게 된다.
그래디언트 벡터는 머신러닝에서 많이 사용되는데, 이는 함수의 최댓값을 찾는 최적화 문제에서 매개변수를 업데이트할 때 사용되기 때문이다.
예를 들어, 손실 함수의 그래디언트 벡터를 구하여 매개변수를 업데이트하면, 손실 함수의 최솟값에 가까워지게 된다.
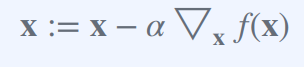
위의 식 x := x − α ▽x f(x)은 경사 하강법(Gradient Descent)의 간단한 형태이다.
-> 주어진 함수 f(x)의 최소값을 찾기 위해 사용
여기서 x는 최소화하려는 함수 f(x)의 인자이며, ▽x f(x)는 x에서의 f(x)의 그래디언트(기울기)를 나타낸다.
1) 현재 위치 x에서의 그래디언트 벡터를 구한다. (▽x f(x))
2) 그래디언트 벡터의 반대 방향으로 이동한다. (x - α ▽x f(x))
3) 이동 거리와 방향을 조절하는 하이퍼파라미터인 학습률(learning rate) α를 곱해준다. (x - α ▽x f(x))
이 알고리즘은 현재 위치 x에서 그래디언트의 반대 방향으로 이동하는 것을 반복하면서 함수 f(x)의 최소값을 찾는다. 이때 이동하는 크기는 학습률(learning rate) α를 곱한 값이다.
따라서 위 식은 현재 위치 x에서, 그래디언트의 반대 방향으로 학습률과 함께 이동한 새로운 위치를 x에 할당하는 것을 나타낸다.
이 과정을 반복하면서 x의 값이 최적의 값으로 수렴하게 된다.
경사 하강법은 함수의 최솟값을 찾기 위해 사용되며, 학습률을 조절함으로써 최솟값을 더 빠르게 혹은 더 정확하게 찾을 수 있다.
학습률이 너무 작으면 수렴하는데 시간이 오래 걸리고, 학습률이 너무 크면 발산할 수 있다.
따라서 적절한 학습률을 찾는 것이 중요하다.
경사 하강법은 머신러닝에서 많이 사용되며, 신경망 학습에서도 주로 사용된다.
경사 하강법을 이용하여 신경망의 가중치를 업데이트하면, 손실 함수를 최소화하는 가중치를 찾을 수 있다.
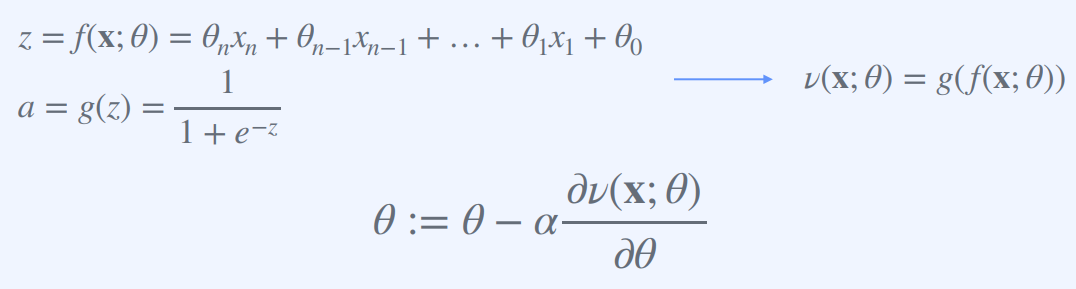
위 식은 딥러닝에서 많이 사용되는 경사 하강법(Gradient Descent) 알고리즘 중 하나인 역전파(Backpropagation)에서 사용되는 식이다.
여기서 x는 인공신경망에서의 입력값이며, θ는 인공신경망의 파라미터(weights)를 나타낸다.
ν(x; θ)는 인공신경망의 출력값이며, ∂ν(x; θ)/∂θ는 ν(x; θ)를 θ로 미분한 값으로, 인공신경망에서의 각 파라미터에 대한 그래디언트(기울기)를 나타낸다.
이 식은 현재 파라미터 θ에서 학습률(learning rate) α와 ∂ν(x; θ)/∂θ를 곱한 값을 빼서 새로운 파라미터 θ를 업데이트하는 것을 나타낸다.
이 과정을 반복하면서 인공신경망의 출력값이 실제값과 가까워지도록 파라미터 θ를 조정한다.
즉, 이 식은 인공신경망에서의 오차를 최소화하기 위해 역전파 알고리즘을 사용하여 파라미터를 업데이트하는 과정을 나타낸다.
여기서 핵심은 현재 파라미터 θ에서 학습률(learning rate) α와 그래디언트(기울기)를 곱한 값을 빼서 새로운 파라미터 값을 계산한다는 것!
이 새로운 파라미터 값은 기존 파라미터 값에서 오차를 줄이기 위한 방향으로 조정된다.
그래디언트는 인공신경망에서 출력값과 실제값 사이의 오차를 계산하는데 사용된다
이 오차를 각각의 파라미터로 편미분하여 그래디언트를 구하고, 이를 이용해 파라미터를 업데이트한다.
즉, 이 식은 인공신경망에서의 오차를 최소화하기 위해 현재 파라미터 값을 업데이트하는 공식
