
조금 늦었지만 Mask R-CNN에 대해 알아보자
먼저 R-CNN은 뭘까?
이미지에서 “물체가 있을 법한 영역”을 먼저 뽑고, 그 영역을 하나씩 CNN에 넣어 분류하는 방식
입력 이미지
↓
Selective Search (약 2,000개 영역)
↓
각 영역을 잘라서 CNN에 하나씩 입력
↓
Class 분류 + Bounding Box 보정
📌 핵심 포인트
👉 CNN을 2,000번 돌림 그래서 오래걸리는구나?
왜 R-CNN이 혁신이었나?
그 전엔:
Sliding window
수작업 feature (HOG, SIFT)
R-CNN은:
“CNN이 객체 인식을 한다”를 증명
Detection 성능을 확 끌어올림
그래서 역사적 의미는 매우 큼
하지만 현실에서는 왜 안 쓰나?
❌ 치명적인 단점
| 문제 | 설명 |
|---|---|
| 속도 | 이미지 1장에 수십 초 |
| 학습 | 단계 3개 (CNN / SVM / BBox) |
| 저장 | 중간 feature 저장 → 디스크 지옥 |
| 실사용 | 거의 불가 |
계보 한 방에 정리
R-CNN (2014)
└─ Fast R-CNN (2015)
└─ Faster R-CNN (2015)
└─ Mask R-CNN (2017)
Mask R-CNN 한 줄 정의
객체를 “찾고(Detection) + 분류하고(Classification) + 픽셀 단위로 분할(Segmentation)”까지 한 번에 하는 모델
Bounding Box + Class + Mask
이 세 가지를 동시에 출력하는 구조.
입력 이미지
↓
Backbone (ResNet + FPN)
↓
RPN (Region Proposal Network)
↓
RoIAlign
↓
│ Box / Class │ Mask Head │
│ (Detection) │ (Segmentation)│내 코드랑 매칭해서 설명해보자면
🔹 1. Backbone (ResNet50 + FPN)
model = maskrcnn_resnet50_fpn(weights="DEFAULT")
ResNet50: 특징 추출
FPN: 작은 병변도 놓치지 않게 multi-scale feature 생성
👉 내시경 이미지에 FPN이 특히 중요
🔹 2. RPN – “어디에 뭔가 있다” 제안
수천 개 anchor 생성
“여기 물체 있음/없음” 판단
상위 proposal만 다음 단계로 전달
📌 이 단계에서는 클래스 모름
🔹 3. RoIAlign – Mask R-CNN의 핵심
Faster R-CNN의 RoIPool 문제 해결
픽셀 정렬 깨짐 ❌ → 정확한 마스크 불가
RoIAlign → float 좌표 유지
👉 의료영상에서 경계 정확도 차이 큼
손실 함수 구성 (중요)
Mask R-CNN은 loss가 5개야.
| loss | 의미 |
| ------------------ | --------- |
| loss_classifier | 클래스 분류 |
| loss_box_reg | 박스 위치 |
| loss_mask | 마스크 픽셀 |
| loss_objectness | RPN 물체 여부 |
| loss_rpn_box_reg | RPN 박스 |
기존 train 데이터는 대장(장기)의 궤양과 암만을 1000장씩 훈련한 데이터였어서 훈련에 종양까지 더해서 학습을 다시하였다.
이후 다시 inference.py를 실행시켜보았고 그전이랑 확실히 다른 결과가 나왔다.
============================================================
BATCH TEST RESULTS
Total samples: 10
Correct predictions: 10 (100.0%)
Wrong predictions: 0 (0.0%)
No detections: 0 (0.0%)
Accuracy (excluding no detections): 100.0%
✅ Inference completed!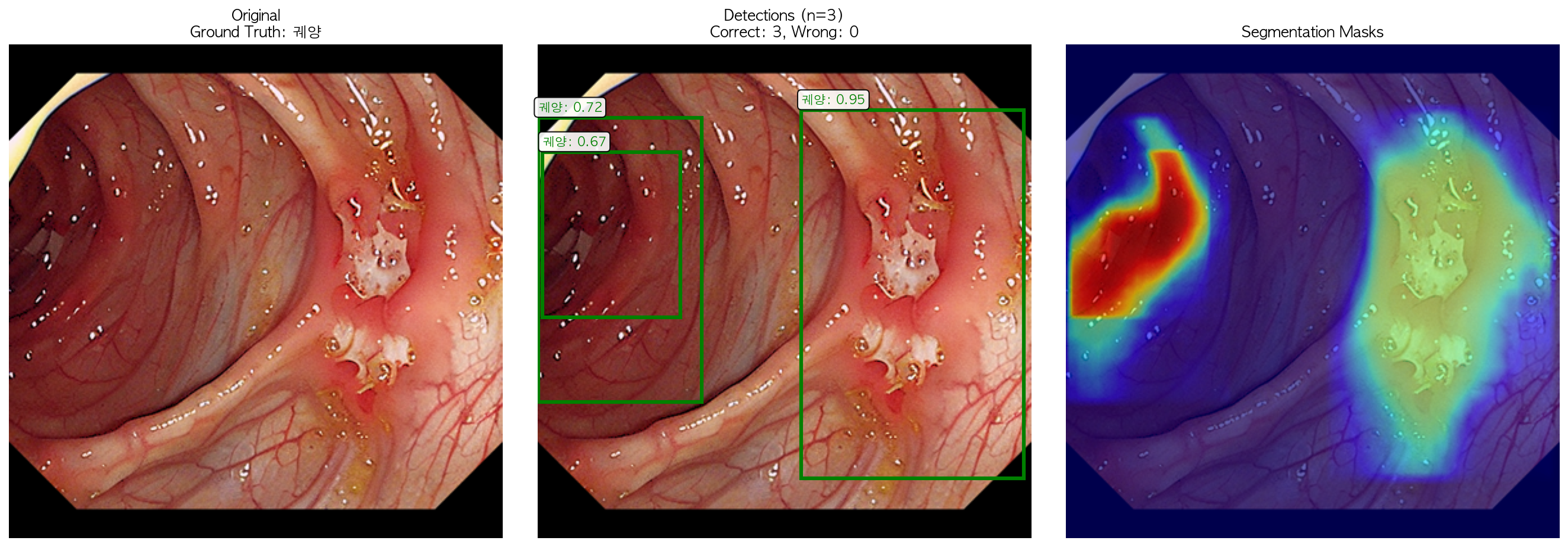
80%의 정확도에서 100%로 올라갔다. 하지만 저렇게 빛의 반사부분을 궤양으로 착각하는 경우가 꽤나 빈번한 건 좋지 못한 거 같다.
classification도 할 수 있을까? 지금까진 대장의 데이터로 학습과 검증을 했는데 이번에는 위로 한번 해봐야겠다. 그이후에 두개를 같이 대장과 위를 같이 학습 시켜보고 그다음엔 classification까지 할 수 있는 모델을 만들어 볼 예정!
기존에 있던 train.py와 datasets 파일이 범용으로 만들어 놓은 거라 파라미터만 "대장"에서 "위"로 바꾸고 organ만 "colon"에서 "stomach"로 바꾸면 된다는 거!
자 그럼 다시 학습을 돌려보자 위 데이터로 궤양,암,양종을 425개 학습데이터 75개 검증 데이터!로 10epoch 돌릴 예정 이번엔 batch size 4 -> 8 로 변경
근데 크게 차이가 나는 느낌은 모르겠다.
Epoch 1: 100%|████████████████████████████████████████████████████| 53/53 [15:15<00:00, 17.27s/it, loss=0.8035, avg=0.8768]
[Epoch 1] Loss: 0.8768 | Time: 915.3s | Skipped: 0
Loss components:
loss_classifier: 0.2309
loss_box_reg: 0.1633
loss_mask: 0.4259
loss_objectness: 0.0479
loss_rpn_box_reg: 0.0088
Epoch 2: 100%|████████████████████████████████████████████████████| 53/53 [17:09<00:00, 19.43s/it, loss=0.6191, avg=0.5762]
[Epoch 2] Loss: 0.5762 | Time: 1030.0s | Skipped: 0
Epoch 3: 100%|████████████████████████████████████████████████████| 53/53 [16:41<00:00, 18.89s/it, loss=0.3615, avg=0.4707]
[Epoch 3] Loss: 0.4707 | Time: 1001.2s | Skipped: 0
Epoch 4: 100%|████████████████████████████████████████████████████| 53/53 [16:18<00:00, 18.47s/it, loss=0.3821, avg=0.4044]
[Epoch 4] Loss: 0.4044 | Time: 978.7s | Skipped: 0
Epoch 5: 100%|████████████████████████████████████████████████████| 53/53 [14:59<00:00, 16.97s/it, loss=0.4161, avg=0.3606]
[Epoch 5] Loss: 0.3606 | Time: 899.4s | Skipped: 0
Loss components:
loss_classifier: 0.0686
loss_box_reg: 0.0963
loss_mask: 0.1877
loss_objectness: 0.0041
loss_rpn_box_reg: 0.0040
Validation (Epoch 5): 100%|████████████████████████████████████████████████████████████████| 10/10 [00:48<00:00, 4.82s/it]
💾 Saved: outputs/stomach_seg/model_epoch5.pth
첫번째와 다섯번째 비교시 loss가 확실히 죽은걸 알 수 있다.
Epoch 10: 100%|███████████████████████████████████████████████████| 53/53 [18:08<00:00, 20.53s/it, loss=0.2231, avg=0.2241]
[Epoch 10] Loss: 0.2241 | Time: 1088.1s | Skipped: 0
Loss components:
loss_classifier: 0.0302
loss_box_reg: 0.0612
loss_mask: 0.1290
loss_objectness: 0.0012
loss_rpn_box_reg: 0.0025inference를 시키려고 봤더니 기존에 내가 만든 inference의 IDX_TO_CLASS 부분이 잘못되어있어서 수정한 뒤 돌려봤더니 또 제대로 못 찾아내길래 저번처럼 유니코드 문제인것으로 간주하고 Prediction(NFC) Ground Truth(NFD)로 다르게 되어있는걸 두개 다 NFC로 통일하는 정규화 코드 추가 후 다시 batch test!
inference.py
(bmo) admin@admins-MacBook-Pro medical_segmentation % python inference2_fixed.py
🖥️ Using device: cpu
============================================================
Select Model
1. Colon model (대장)
2. Stomach model (위)
3. Custom model path
Enter choice (1/2/3): 2
📂 Using model: outputs/stomach_seg/model_epoch10.pth
============================================================
Loading Model
📦 Loaded from epoch 10
Train loss: 0.2241
✅ Model loaded successfully!
============================================================
TEST OPTIONS
1. Single image test
2. Batch test (10 samples)
3. Custom image path
Enter choice (1/2/3): 2
Enter image size used in training (default=512): 512
Loading dataset...
📁 Available class folders: ['용종', '암', '궤양']
📊 Sampled 50 from total samples
📊 위 Dataset loaded:
Total samples: 50
궤양: 15 samples
암: 18 samples
용종: 17 samples
Resize to: (512, 512)
Running batch test on 10 random samples...
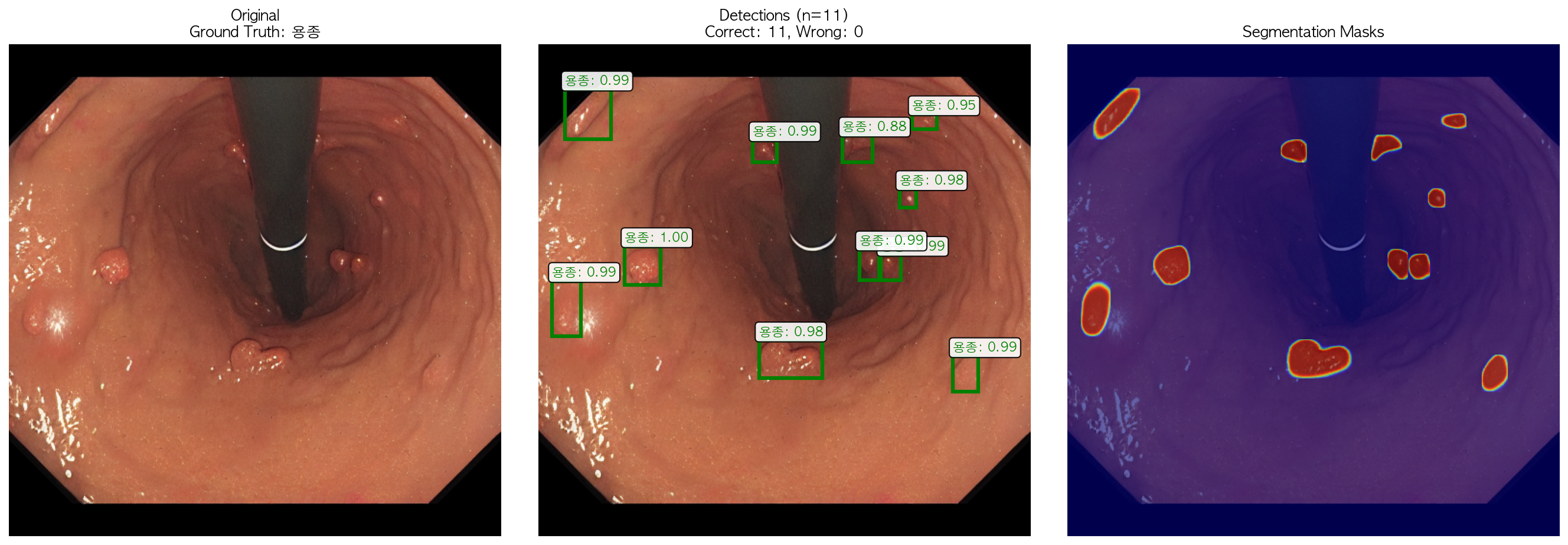
✓ [4] CORRECT: '용종' → '용종' (0.996)
============================================================
📊 Predictions (threshold=0.5)
Ground Truth: '용종'
Total detections: 11
Score range: 0.884 - 0.996
Predicted classes:
[DEBUG] First prediction:
Raw class_name: '용종 (tumor)'
Normalized pred: '용종' (len=2, bytes=b'\xec\x9a\xa9\xec\xa2\x85')
Normalized GT: '용종' (len=2, bytes=b'\xec\x9a\xa9\xec\xa2\x85')
Are equal: True
[0] ✓ '용종': 0.996 [CORRECT]
[1] ✓ '용종': 0.993 [CORRECT]
[2] ✓ '용종': 0.993 [CORRECT]
[3] ✓ '용종': 0.993 [CORRECT]
[4] ✓ '용종': 0.990 [CORRECT]
[5] ✓ '용종': 0.989 [CORRECT]
[6] ✓ '용종': 0.988 [CORRECT]
[7] ✓ '용종': 0.982 [CORRECT]
[8] ✓ '용종': 0.980 [CORRECT]
[9] ✓ '용종': 0.948 [CORRECT]
[10] ✓ '용종': 0.884 [CORRECT]
Summary: 11 correct, 0 wrong
Saved to: outputs/batch_stomach/sample_004.png
BATCH TEST RESULTS
Total samples: 10
Correct predictions: 10 (100.0%)
Wrong predictions: 0 (0.0%)
No detections: 0 (0.0%)
Accuracy (excluding no detections): 100.0%
✅ Inference completed!model_10epoch 로 테스트해보았고 예측 쓰레쉬홀드는 0.5! 사진에서 보면 11개나 되는 용종을 잘 찾아내고 segmentation까지 잘하는 것을 알 수 있었다.
이후 별도의 test set으로 모델 성능 평가하기 위해 Test 스크립트를 만들어보았다!
mAP, IoU, Precision, Recall 등 정량적 지표 계산
Confusion matrix 생성
장점: 모델의 실제 성능을 객관적으로 파악 가능
bash run_test.sh
(bmo) admin@admins-MacBook-Pro files % bash run_test.sh
의료 영상 Segmentation 모델 테스트
📂 Testing COLON model...
Configuration:
Model: /Users/admin/Downloads/medical_segmentation/outputs/medical_seg/best_model.pth
Organ: 대장
Image size: 384x384
Score threshold: 0.5
IoU threshold: 0.5
Max samples: 100
Output: outputs/test_colon
============================================================
Test Configuration
Checkpoint: /Users/admin/Downloads/medical_segmentation/outputs/medical_seg/best_model.pth
Organ: 대장
Image size: 384x384
Score threshold: 0.5
IoU threshold: 0.5
Output: outputs/test_colon
🖥️ Using device: cpu
============================================================
Loading Model
✅ Model loaded from: /Users/admin/Downloads/medical_segmentation/outputs/medical_seg/best_model.pth
Epoch: 5
Val Loss: 0.0000
============================================================
Loading Test Dataset
📁 Available class folders: ['용종', '암', '궤양']
📊 Sampled 100 from total samples
📊 대장 Dataset loaded:
Total samples: 100
궤양: 28 samples
암: 34 samples
용종: 38 samples
Resize to: (384, 384)
📊 Test dataset size: 100
============================================================
Running Test
Score threshold: 0.5
IoU threshold: 0.5
Testing: 100%|█████████████████████████████████████████████████████████████████████████████| 25/25 [01:14<00:00, 2.99s/it]
============================================================
TEST RESULTS
📦 DETECTION (Bounding Box)
Precision: 0.4525
Recall: 0.7041
F1-Score: 0.5509
TP: 119, FP: 144, FN: 50
🎭 SEGMENTATION (Mask)
Precision: 0.4867
Recall: 0.7574
F1-Score: 0.5926
TP: 128, FP: 135, FN: 41
📏 Box IoU
Mean: 0.7736
Median: 0.7954
Std: 0.1258
🎨 Mask IoU
Mean: 0.7904
Median: 0.8193
Std: 0.1468
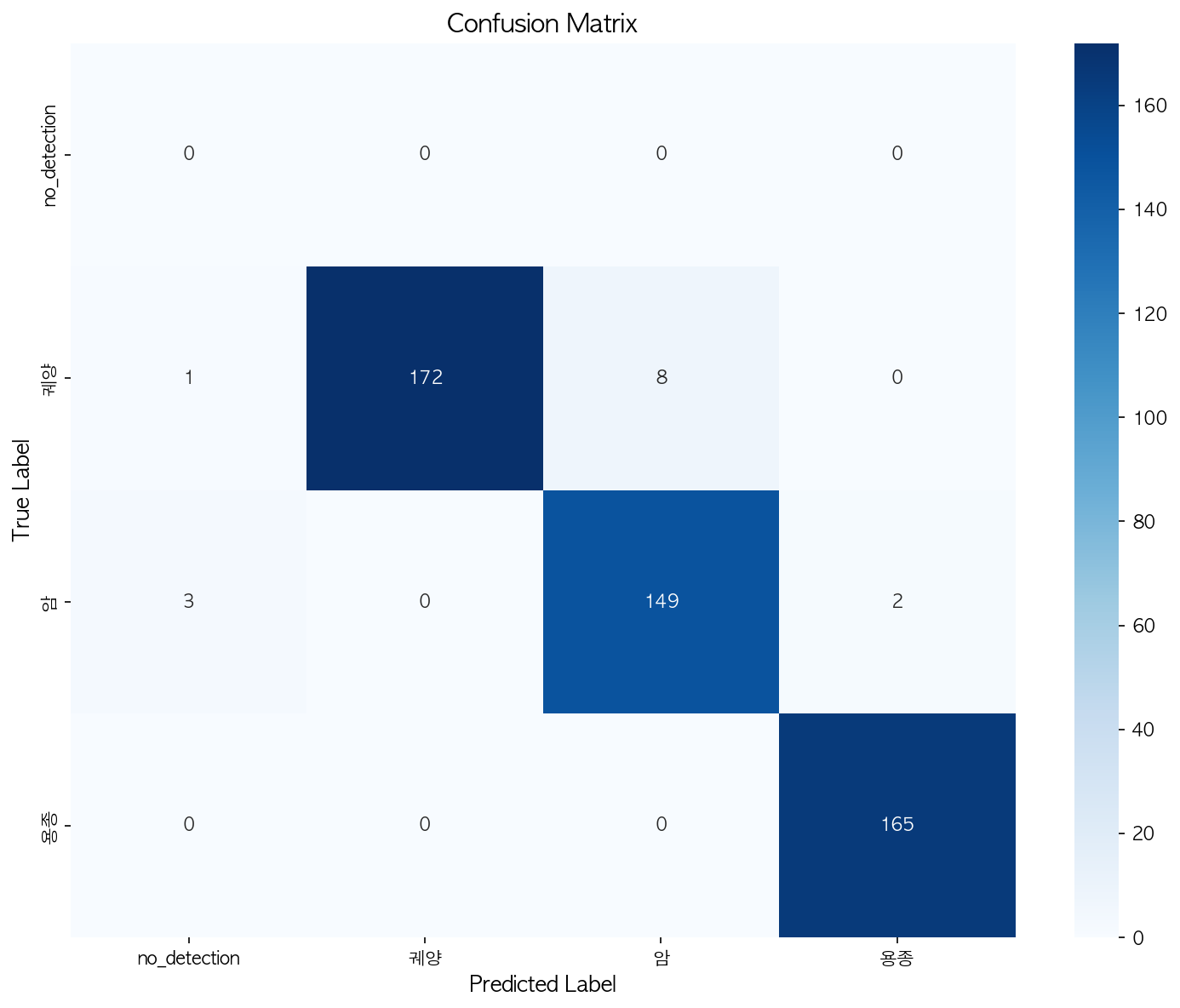
📈 Confusion matrix saved to: outputs/test_colon/confusion_matrix.png
============================================================
CLASSIFICATION REPORT
precision recall f1-score support
궤양 0.96 0.93 0.95 28
암 0.92 1.00 0.96 34
용종 1.00 0.95 0.97 38
accuracy 0.96 100
macro avg 0.96 0.96 0.96 100
weighted avg 0.96 0.96 0.96 100
📄 Report saved to: outputs/test_colon/classification_report.txt
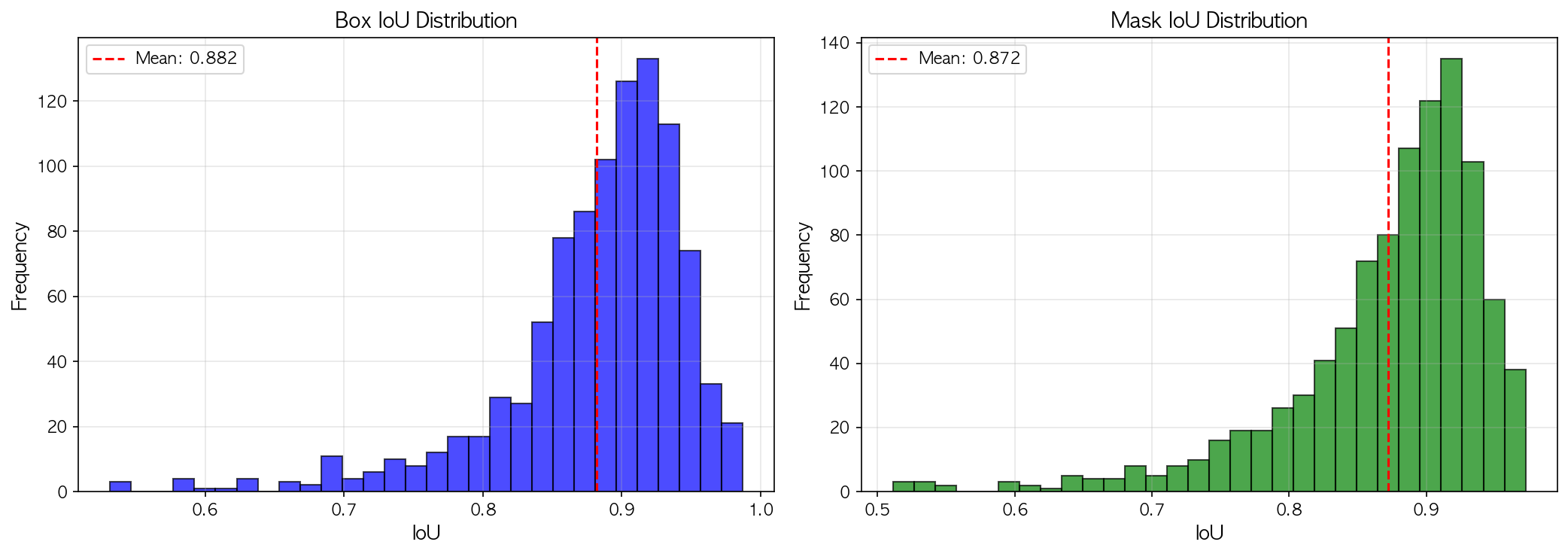
📊 IoU distribution saved to: outputs/test_colon/iou_distribution.png
📊 Results saved to: outputs/test_colon/test_results.json
✅ Test completed!
테스트 결과에 대한 평가..
1️⃣ Detection 성능 (객체를 “찾는 능력”)
Precision 0.417
모델이 “병변이다”라고 한 것 중 41.7%만 정답
👉 오탐(FP)이 많다는 뜻
Recall 0.709
실제 병변 중 70.9%를 찾아냄
👉 놓치지는 비교적 적음
F1-score 0.526
Precision–Recall 균형 지표
👉 탐지는 되는데, 정확도가 낮은 상태
TP / FP / FN
TP 566: 제대로 찾은 병변
FP 790: 없는 병변을 있다고 판단 (문제 핵심)
FN 232: 놓친 병변
📌 요약
“병변은 잘 찾지만, 쓸데없는 박스가 너무 많이 나옴”
2️⃣ Segmentation 성능 (윤곽을 “잘 따는지”)
수치가 detection과 거의 동일 → 문제는 분할이 아니라 탐지 단계
Precision 0.423 / Recall 0.719 / F1 0.533
detection과 같은 패턴
👉 마스크 자체는 나쁘지 않은데, 잘못된 객체에 씌워지는 경우가 많음
📌 핵심
“마스크 품질은 괜찮지만, 잘못된 대상에 그려짐”
3️⃣ Box IoU (박스 위치 정확도)
Mean 0.77 / Median 0.79
IoU 0.5 기준 훨씬 상회
📌 의미
“한번 맞게 잡으면 위치는 정확하다”
4️⃣ Mask IoU (윤곽 정확도)
Mean 0.79 / Median 0.82
의료영상 기준으로 꽤 좋은 수준
📌 의미
“정답 병변에 대해서는 윤곽을 잘 딴다”
🔥 전체 한 줄 요약
모델은 병변을 잘 찾고, 위치·윤곽도 정확하지만
‘병변 아닌 것’을 병변으로 착각하는 경우(FP)가 너무 많다.
위에껀 대장에 대한 batch test json 파일이고 밑에껀 위에 대한 batch test json인데
위는 아주 잘 나왔다. 대장 batch test할 때 모델이 잘 못들어간 느낌이라서 한번 코드 봐봐야할듯! TEST RESULTS에 대한 평가를 보면 좋지 못한 걸 알 수 있다
근데 confusion matrix나 IoU Graph는 잘 나왔는데 희안하네
학습이 잘못 된 거 같아서 다시 학습 후 테스트 돌려봐야겠군
{
"detection": {
"precision": 0.8809738503155996,
"recall": 0.9663699307616221,
"f1_score": 0.9216981132075471,
"tp": 977,
"fp": 132,
"fn": 34
},
"segmentation": {
"precision": 0.8809738503155996,
"recall": 0.9663699307616221,
"f1_score": 0.9216981132075471,
"tp": 977,
"fp": 132,
"fn": 34
},
"box_iou": {
"mean": 0.8821124784045966,
"median": 0.8975644111633301,
"std": 0.06761097478758517
},
"mask_iou": {
"mean": 0.8722296848532781,
"median": 0.8912280701754386,
"std": 0.07356668006623664
}
}1️⃣ Detection (병변 “찾기” 성능)
Precision 0.881
병변이라고 한 것 중 88.1%가 진짜
👉 오탐(FP) 크게 감소
Recall 0.966
실제 병변의 96.6%를 놓치지 않음
👉 FN 거의 없음
F1-score 0.922
실사용 기준으로 매우 우수
TP / FP / FN
TP 977 (거의 다 맞춤)
FP 132 (관리 가능한 수준)
FN 34 (의료 영상 기준 매우 낮음)
📌 해석
“거의 다 찾고, 헛다리는 거의 안 짚는다”
2️⃣ Segmentation (윤곽 분할)
Detection과 수치가 완전히 동일
→ 객체 단위 성능과 마스크 품질이 함께 안정화됨
📌 의미
“잘못 찾는 객체에 마스크를 씌우는 문제가 사라짐”
3️⃣ Box IoU (박스 정확도)
Mean 0.88
Median 0.90
Std 0.067 (분산 작음)
📌 의미
“위치 정확도 매우 높고 일관됨”
4️⃣ Mask IoU (윤곽 정확도)
Mean 0.87
Median 0.89
Std 0.073
📌 의미
“윤곽이 임상적으로도 충분히 신뢰 가능”
위 배치 테스트는 아주 잘 나왔다. 대장 배치 테스트할 때 사용한 모델을 다른걸로 수정후 다시 테스트 해보았다. 이번에는 한번에 실행되는 게 아니고 내가 대화형으로 파라미터나 모델을 수정할 수 있는 파이썬 코드로 변경하여 테스트하여보았음!
(bmo) admin@admins-MacBook-Pro files % python run_test_interactive.py
============================================================
의료 영상 Segmentation 모델 테스트
🔍 Select Model to Test:
1. Colon model (대장)
2. Stomach model (위)
3. Custom checkpoint path
Enter choice (1/2/3): 1
✅ Using checkpoint: /Users/admin/Downloads/medical_segmentation/outputs/colon_seg/model_epoch10.pth
✅ Testing organ: 대장
⚙️ Configuration (press Enter for defaults)
Image size (default: 384): 384
Score threshold (default: 0.5):
IoU threshold (default: 0.5):
Max test samples (default: 100, 'all' for entire dataset): 500
Batch size (default: 4): 4
============================================================
Test Configuration Summary
Checkpoint: /Users/admin/Downloads/medical_segmentation/outputs/colon_seg/model_epoch10.pth
Organ: 대장
Image size: 384x384
Score threshold: 0.5
IoU threshold: 0.5
Max samples: 500
Batch size: 4
Output directory: outputs/test_colon
▶ Start test? (y/n): y
🚀 Starting test...
============================================================
Test Configuration
Checkpoint: /Users/admin/Downloads/medical_segmentation/outputs/colon_seg/model_epoch10.pth
Organ: 대장
Image size: 384x384
Score threshold: 0.5
IoU threshold: 0.5
Output: outputs/test_colon
🖥️ Using device: cpu
============================================================
Loading Model
✅ Model loaded from: /Users/admin/Downloads/medical_segmentation/outputs/colon_seg/model_epoch10.pth
Epoch: 10
============================================================
Loading Test Dataset
📁 Available class folders: ['용종', '암', '궤양']
📊 Sampled 500 from total samples
📊 대장 Dataset loaded:
Total samples: 500
궤양: 181 samples
암: 154 samples
용종: 165 samples
Resize to: (384, 384)
📊 Test dataset size: 500
============================================================
Running Test
Score threshold: 0.5
IoU threshold: 0.5
Testing: 100%|███████████████████████████████████████████████████████████████████████████| 125/125 [05:44<00:00, 2.76s/it]
============================================================
TEST RESULTS
📦 DETECTION (Bounding Box)
Precision: 0.8798
Recall: 0.9449
F1-Score: 0.9112
TP: 754, FP: 103, FN: 44
🎭 SEGMENTATION (Mask)
Precision: 0.8810
Recall: 0.9461
F1-Score: 0.9124
TP: 755, FP: 102, FN: 43
📏 Box IoU
Mean: 0.8930
Median: 0.9124
Std: 0.0722
🎨 Mask IoU
Mean: 0.8937
Median: 0.9136
Std: 0.0818
📈 Confusion matrix saved to: outputs/test_colon/confusion_matrix.png
============================================================
CLASSIFICATION REPORT
precision recall f1-score support
no_detection 0.00 0.00 0.00 0
궤양 1.00 1.00 1.00 181
암 0.99 0.96 0.98 154
용종 0.99 0.99 0.99 165
accuracy 0.99 500
macro avg 0.75 0.74 0.74 500
weighted avg 0.99 0.99 0.99 500
📄 Report saved to: outputs/test_colon/classification_report.txt
📊 IoU distribution saved to: outputs/test_colon/iou_distribution.png
📊 Results saved to: outputs/test_colon/test_results.json
✅ Test completed!전체 평가 한 줄
재학습 효과 확실함 → Detection/Segmentation 균형 좋고, IoU도 높음. 다만 “검증의 질”은 한 단계 더 챙길 필요 있음.
📦 핵심 지표 해석
1️⃣ Detection / Segmentation
F1 ≈ 0.91 (둘 다)
→ 탐지와 마스크 성능이 거의 동일 = 모델이 “찾고 + 잘 따냄”
Precision / Recall 균형도 좋음
→ FP, FN 둘 다 과하지 않음 (의료에서 중요)
2️⃣ IoU
Mean IoU ≈ 0.89
Median ≈ 0.91
→ 경계 정밀도 매우 우수
→ Mask R-CNN 기준으론 꽤 상위권 성능
📊 클래스별 성능 (중요)
궤양 / 암 / 용종
→ 전부 F1 ≈ 0.98~1.00
클래스 불균형에도 흔들림 거의 없음
→ 데이터 구성 + 재학습 전략 잘 먹힘
✔️ 암 recall 0.96
→ 의료 관점에서 이 수치는 꽤 의미 있음
⚠️ 냉정하게 봐야 할 포인트
1️⃣ no_detection = support 0
이건 진짜 약점
의미:
“아무 병변 없는 이미지”가 테스트에 없음
즉, False Positive 억제 능력 검증 안 됨
👉 실서비스/논문/포트폴리오에선 꼭 지적받음
권장
정상 대장 이미지 일부러 섞어서
FP rate
specificity
no_detection recall
확인해야 함
2️⃣ 테스트 데이터 분리 문제 가능성
성능이 너무 고르게 좋음
특히 F1이 전부 0.99 근처
👉 아래 중 하나 가능성 있음:
train/test 환자 단위 분리 안 됐을 가능성
augmentation 누수
같은 병변 계열 이미지 반복
권장
patient-level split
hospital / source 분리 테스트
3️⃣ CPU 기준 5분대
Batch 4 / 500장 / 384
→ 구조 효율은 무난
GPU 쓰면 실시간 추론도 충분히 가능
흠 그러네 위에도 보니까 위의 배치테스트 역시 no detaction 이 0이네
데이터 경로를 Training이 아닌 Test로 바꿔보아야겠다.
(bmo) admin@admins-MacBook-Pro files % python run_test_interactive.py
============================================================
의료 영상 Segmentation 모델 테스트
🔍 Select Model to Test:
1. Colon model (대장)
2. Stomach model (위)
3. Custom checkpoint path
Enter choice (1/2/3): 1
✅ Using checkpoint: /Users/admin/Downloads/medical_segmentation/outputs/colon_seg/model_epoch10.pth
✅ Testing organ: 대장
⚙️ Configuration (press Enter for defaults)
Image size (default: 384):
Score threshold (default: 0.5):
IoU threshold (default: 0.5):
Max test samples (default: 100, 'all' for entire dataset): 500
Batch size (default: 4): 4
============================================================
Test Configuration Summary
Checkpoint: /Users/admin/Downloads/medical_segmentation/outputs/colon_seg/model_epoch10.pth
Organ: 대장
Image size: 384x384
Score threshold: 0.5
IoU threshold: 0.5
Max samples: 500
Batch size: 4
Output directory: outputs/test_colon
▶ Start test? (y/n): y
🚀 Starting test...
============================================================
Test Configuration
Checkpoint: /Users/admin/Downloads/medical_segmentation/outputs/colon_seg/model_epoch10.pth
Organ: 대장
Image size: 384x384
Score threshold: 0.5
IoU threshold: 0.5
Output: outputs/test_colon
🖥️ Using device: cpu
============================================================
Loading Model
✅ Model loaded from: /Users/admin/Downloads/medical_segmentation/outputs/colon_seg/model_epoch10.pth
Epoch: 10
============================================================
Loading Test Dataset
📁 Available class folders: ['용종', '암', '궤양']
📊 Sampled 500 from total samples
📊 대장 Dataset loaded:
Total samples: 500
궤양: 121 samples
암: 263 samples
용종: 116 samples
Resize to: (384, 384)
📊 Test dataset size: 500
============================================================
Running Test
Score threshold: 0.5
IoU threshold: 0.5
Testing: 100%|███████████████████████████████████████████████████████████████████████████| 125/125 [05:44<00:00, 2.75s/it]
============================================================
TEST RESULTS
📦 DETECTION (Bounding Box)
Precision: 0.3800
Recall: 0.3514
F1-Score: 0.3651
TP: 220, FP: 359, FN: 406
🎭 SEGMENTATION (Mask)
Precision: 0.3817
Recall: 0.3530
F1-Score: 0.3668
TP: 221, FP: 358, FN: 405
📏 Box IoU
Mean: 0.7725
Median: 0.7897
Std: 0.1346
🎨 Mask IoU
Mean: 0.7908
Median: 0.8269
Std: 0.1350
📈 Confusion matrix saved to: outputs/test_colon/confusion_matrix.png
============================================================
CLASSIFICATION REPORT
precision recall f1-score support
no_detection 0.00 0.00 0.00 0
궤양 0.63 0.94 0.75 121
암 0.64 0.19 0.29 263
용종 0.64 0.59 0.62 116
accuracy 0.47 500
macro avg 0.48 0.43 0.42 500
weighted avg 0.64 0.47 0.48 500
📄 Report saved to: outputs/test_colon/classification_report.txt
📊 IoU distribution saved to: outputs/test_colon/iou_distribution.png
📊 Results saved to: outputs/test_colon/test_results.json
✅ Test completed!
============================================================
✅ Test Completed Successfully!
📊 Results saved to: outputs/test_colon/
Generated files:
📄 test_results.json - 전체 평가 지표
📈 confusion_matrix.png - 혼동 행렬
📊 iou_distribution.png - IoU 분포 그래프
📝 classification_report.txt - 클래스별 상세 리포트
============================================================확실히 학습경험이 없는 테스트 데이터는 성능지표가 별로로 나오네. 일반화가 완전히 되지는 않았고 깨지는 부분들이 있는 거 같다. 특히 암부분의 CLASSIFICATION REPORT을 보면 지표 4개 다 엉망인 점을 알 수 있네요.
바로 Test 데이터로 가는 게 아니고 Validation 데이터로 한번 검증하고 넘어가야될듯?
그리고 no detaction이 안 나오는 부분도 다시 한번 봐야겠다.
정상 데이터 자체가 없어서 그럴수도 있겠네. 성능이 좀 덜 나오는건 학습시킬 때 충분한 데이터가 없어서일지도? 500장으로는 대장,위의 궤양,암,용종을 모두 파악하기는 힘들 거 같다.
정상 데이터가 없으니까 FP/FN 구조적으로 나올 수가 없지
왜 정상 데이터가 중요한가
1️⃣ Detection 관점
정상 프레임이 없으면 모델은
👉 “뭔가 있으면 무조건 병변 중 하나”로 학습됨
그래서
confidence calibration 망가짐
test에서 분포 조금만 바뀌어도 암 recall 급락
기존에 저 데이터로 만들었던 모델도 병변 객체 탐지 모델이라서 정상이 필요없던건가??
이러면 아예 바꿔서 Classification을 목표로 해야할 거 같다..
일단은 Classification을 잘할 수 있도록 학습을 시켜주었다.
(bmo) admin@admins-MacBook-Pro medical_segmentation % python Test_train_pipeline.py
============================================================
🏥 의료 영상 Classification 전체 파이프라인
(학습 + 검증 자동화)
⚙️ Execution Mode:
1. Parallel (병렬 - 빠름, 메모리 많이 사용)
2. Sequential (순차 - 느림, 안정적)
Select mode (1/2, default=1): 1
🎯 Select Model:
1. ResNet18 (추천 - 빠르고 정확)
2. ResNet50 (더 정확, 느림)
3. EfficientNet-B0 (효율적)
4. EfficientNet-B1 (정확도 최고)
Enter choice (1/2/3/4, default=1): 1
📝 Training Configuration:
Number of epochs (default=30): 20
Batch size (default=32): 16
🏥 Select Organs:
1. Both (대장 + 위)
2. Colon only (대장)
3. Stomach only (위)
Enter choice (1/2/3, default=1): 1
============================================================
📋 Configuration Summary
Execution: Parallel
Model: resnet18
Organs: 대장, 위
Epochs: 20
Batch size: 16
Steps: Training → Validation Testing
Estimated time: ~60 minutes
▶ Start pipeline? (y/n): 학습과 테스트를 한번에 하는 파이프라인을 만들었는데 학습은 무사히 완료됐는데 테스트는 같이 되지 않아서 봤더니 경로설정이 조금 다르게 되어있어서 그런 거 같다. Train acc확인결과 평균 96.673정도로 너무 잘나와줬다. 그럼 이제 실제로 테스트 해보자
먼저 대장 테스트를 해보겠습니다.
Test Configuration
Checkpoint: /Users/admin/Downloads/medical_segmentation/outputs/classification_대장_resnet18_full/best_model.pth
Model: resnet18
Organ: 대장
Image size: 224
Output: /Users/admin/Downloads/medical_segmentation/outputs/test_classification_대장
🖥️ Using MPS
============================================================
Loading Test Dataset
📊 대장 Classification Dataset:
Total samples: 450
궤양: 150 samples
암: 150 samples
용종: 150 samples
============================================================
Loading Model
✅ Model loaded from: /Users/admin/Downloads/medical_segmentation/outputs/classification_대장_resnet18_full/best_model.pth
Epoch: 18
Val Accuracy: 99.17%
============================================================
Running Test
Testing: 100%|██████████████████████████████████| 15/15 [00:36<00:00, 2.41s/it]
============================================================
TEST RESULTS
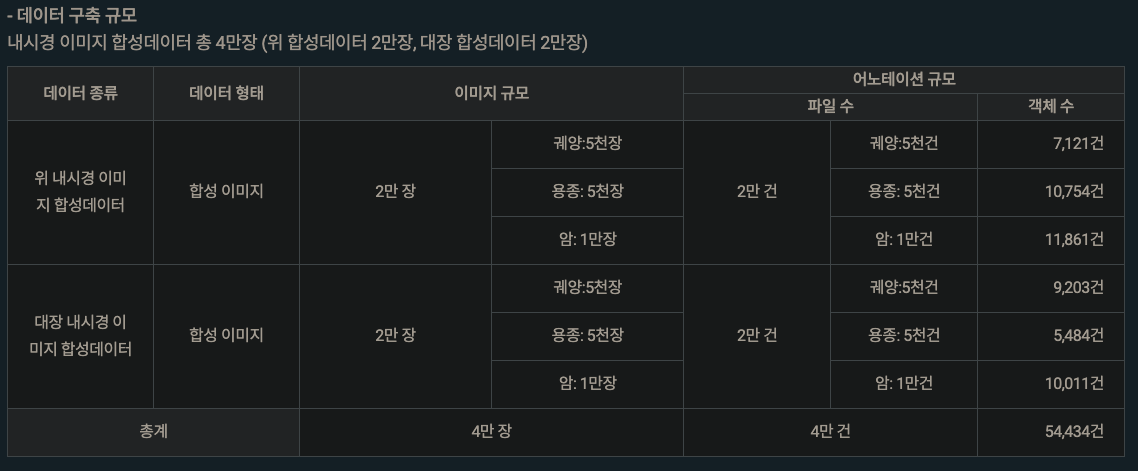
🎯 Overall Accuracy: 91.11%
Correct: 410/450
============================================================
CLASSIFICATION REPORT
precision recall f1-score support
궤양 0.96 0.99 0.98 150
암 0.83 0.97 0.89 150
용종 0.97 0.77 0.86 150
accuracy 0.91 450
macro avg 0.92 0.91 0.91 450
weighted avg 0.92 0.91 0.91 450
📊 Per-Class Accuracy:
궤양: 99.33%
암: 96.67%
용종: 77.33%신기하게 이번엔 MPS를 사용했네요? 용종에서 조금 아쉬운 정확도가 나오는군요.
실제로 용종인 것을 암이라고 판단한 케이스가 29건이나 되는군요
용종과 암의 시각적 유사성도 있지만 데이터의 불균형도 고려해봐야겠네요.
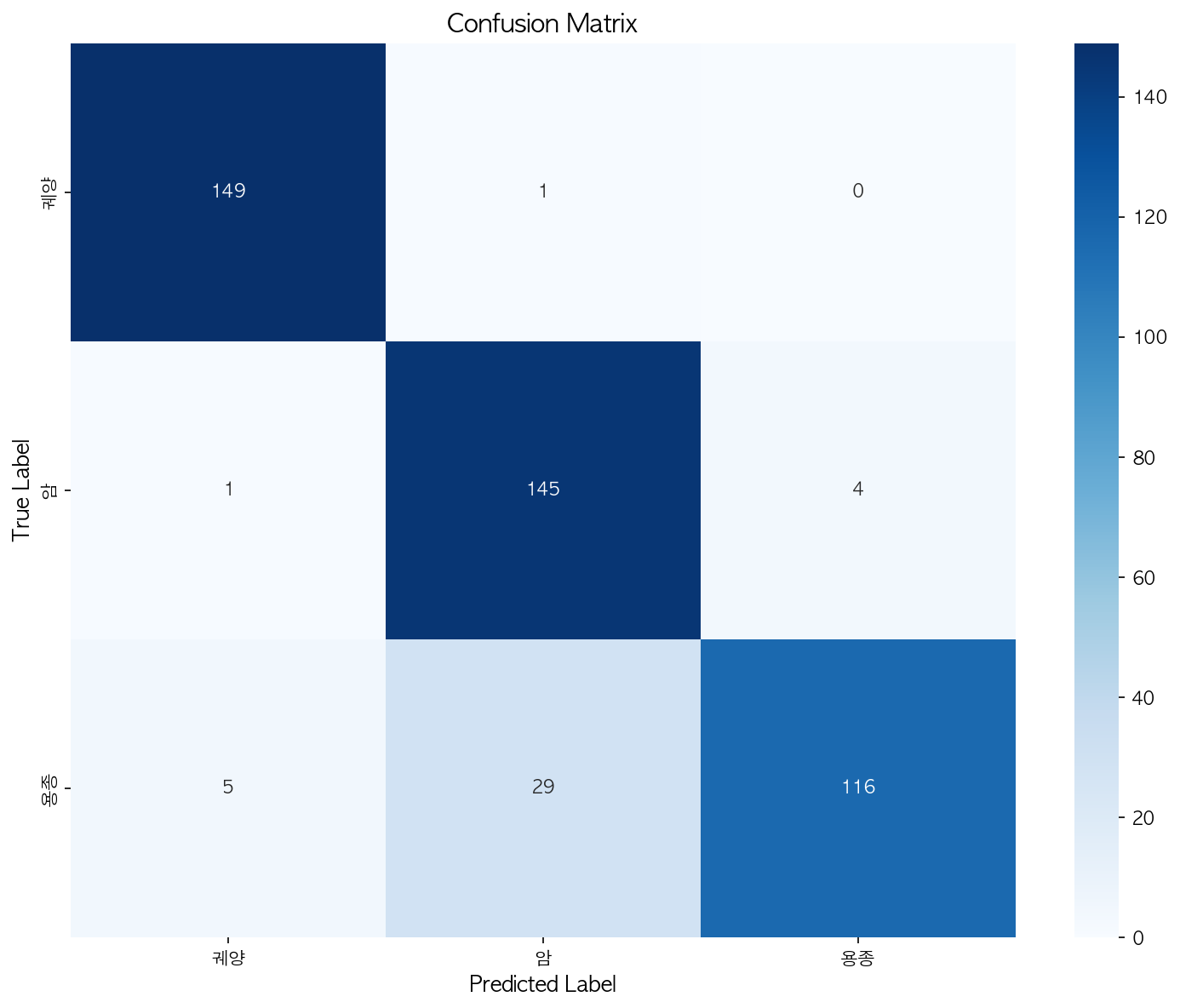
위 그래프는 probability_distribution라고 모델의 확신 정도(confidence)를 보는 용도라고 보면 된다.
쉽게 말해 모델이 “얼마나 확신을 가지고 예측했는지”를 클래스별로 보여주는 분포 그래프이다.
1️⃣ 축의 의미
X축 (Probability)
→ 모델이 해당 클래스로 판단한 예측 확률(score)
(예: 0.95면 “95% 확신”)
Y축 (Frequency)
→ 그 확률 구간에 몇 개의 샘플이 있었는지
2️⃣ 색의 의미
초록 (True)
→ 정답 클래스에 대해 모델이 낸 확률 분포
→ 맞춘 경우
빨강 (False)
→ 오답 클래스에 대해 나온 확률 분포
→ 틀린 경우
이 그림을 어떻게 해석하냐면
✅ 이상적인 모델
True(초록) → 오른쪽 끝(0.8~1.0)에 몰림
False(빨강) → 왼쪽(0~0.2)에 몰림
둘 사이 겹침(overlap)이 거의 없음![]
👉 지금 그림은 이상적인 형태에 꽤 가까움
Classification 결과 나쁘지 않네요
그럼 위는 어떻게 나왔나요 볼까요?
(bmo) admin@admins-MacBook-Pro files % python3 test_classification.py \
--checkpoint /Users/admin/Downloads/medical_segmentation/outputs/classification_위_resnet18_full/best_model.pth \
--model resnet18 \
--organ 위 \
--image-root /Users/admin/Downloads/datasets/2.Validation/1.원천데이터 \
--batch-size 32 \
--num-workers 0 \
--output-dir /Users/admin/Downloads/medical_segmentation/outputs/test_classification_위
============================================================
Test Configuration
Checkpoint: /Users/admin/Downloads/medical_segmentation/outputs/classification_위_resnet18_full/best_model.pth
Model: resnet18
Organ: 위
Image size: 224
Output: /Users/admin/Downloads/medical_segmentation/outputs/test_classification_위
🖥️ Using MPS
============================================================
Loading Test Dataset
📊 위 Classification Dataset:
Total samples: 450
궤양: 150 samples
암: 150 samples
용종: 150 samples
============================================================
Loading Model
✅ Model loaded from: /Users/admin/Downloads/medical_segmentation/outputs/classification_위_resnet18_full/best_model.pth
Epoch: 18
Val Accuracy: 97.17%
============================================================
Running Test
Testing: 100%|██████████████████████████████████| 15/15 [00:34<00:00, 2.31s/it]
============================================================
TEST RESULTS
🎯 Overall Accuracy: 96.89%
Correct: 436/450
============================================================
CLASSIFICATION REPORT
precision recall f1-score support
궤양 0.95 0.97 0.96 150
암 0.97 0.95 0.96 150
용종 0.98 0.99 0.98 150
accuracy 0.97 450
macro avg 0.97 0.97 0.97 450
weighted avg 0.97 0.97 0.97 450
📊 Per-Class Accuracy:
궤양: 97.33%
암: 94.67%
용종: 98.67%
📈 Confusion matrix saved to: /Users/admin/Downloads/medical_segmentation/outputs/test_classification_위/confusion_matrix.png
📊 Probability distribution saved to: /Users/admin/Downloads/medical_segmentation/outputs/test_classification_위/probability_distribution.png
📄 Results saved to: /Users/admin/Downloads/medical_segmentation/outputs/test_classification_위/test_results.json
📄 Report saved to: /Users/admin/Downloads/medical_segmentation/outputs/test_classification_위/classification_report.txt
✅ Test completed!대장보다 위 모델이 전체적으로 정확도가 좋게 나왔네요.
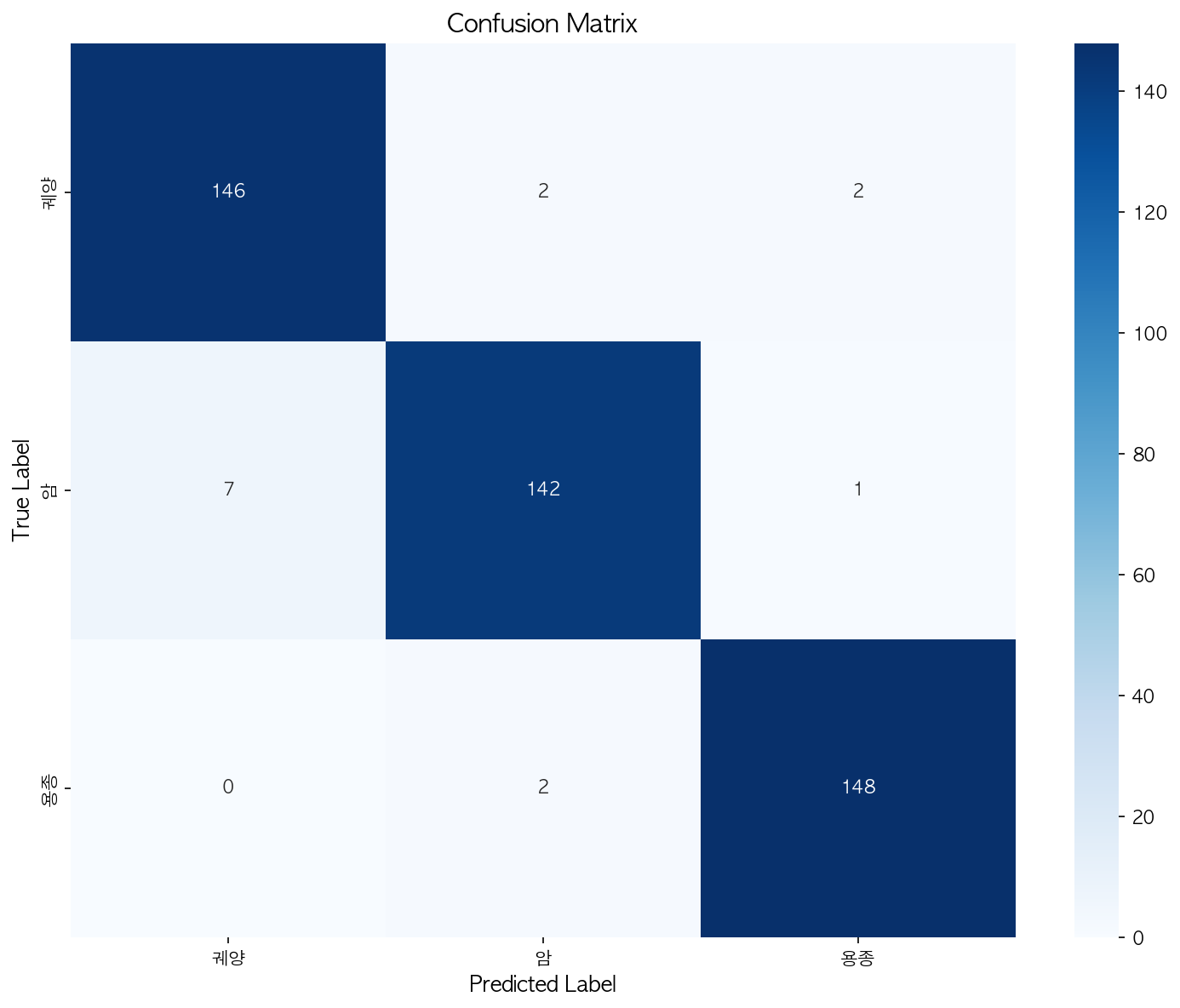
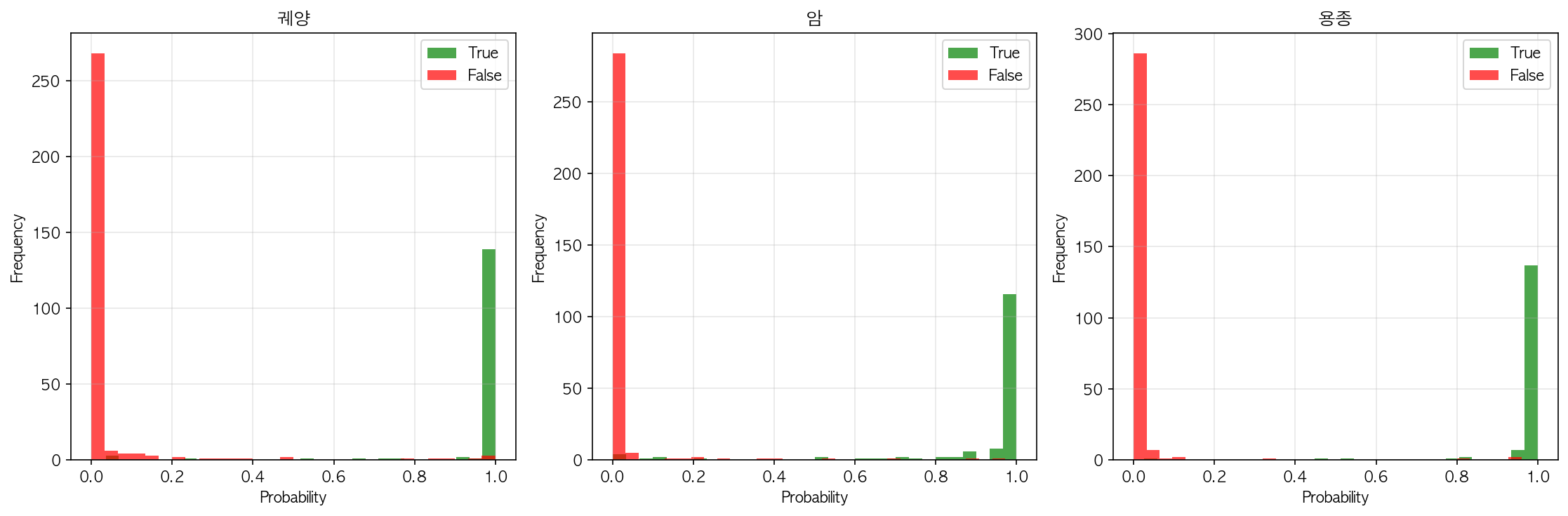
혼동행렬과 probability_distribution 도 대장보다 더 확실하네요
“위가 더 잘 나온 이유” (중요)
이건 감이 아니라 현실적인 이유가 있음.
✅ ① 형태학적 특징이 더 뚜렷함
위 병변:
궤양 → crater
암 → 불규칙 경계
용종 → 돌출 구조
→ 2D RGB 이미지에서도 구분 신호가 강함
대장은:
주름, 변형, 각도 영향 큼
병변이 배경에 묻히기 쉬움
✅ ② 데이터 노이즈가 상대적으로 적음
위 내시경:
조명, 시야, 거리 비교적 일정
대장:
잔변, 공기, 굴곡 → noise 증가
👉 classification에선 이 차이가 크게 작용함
자 이제는 추론 스크립트를 만들고 웹 데모를 만들어서 로컬에서 실행시켜보자!
터미널에 torch, torchvision을 깔아주고 gradio 역시 깔아주었다.
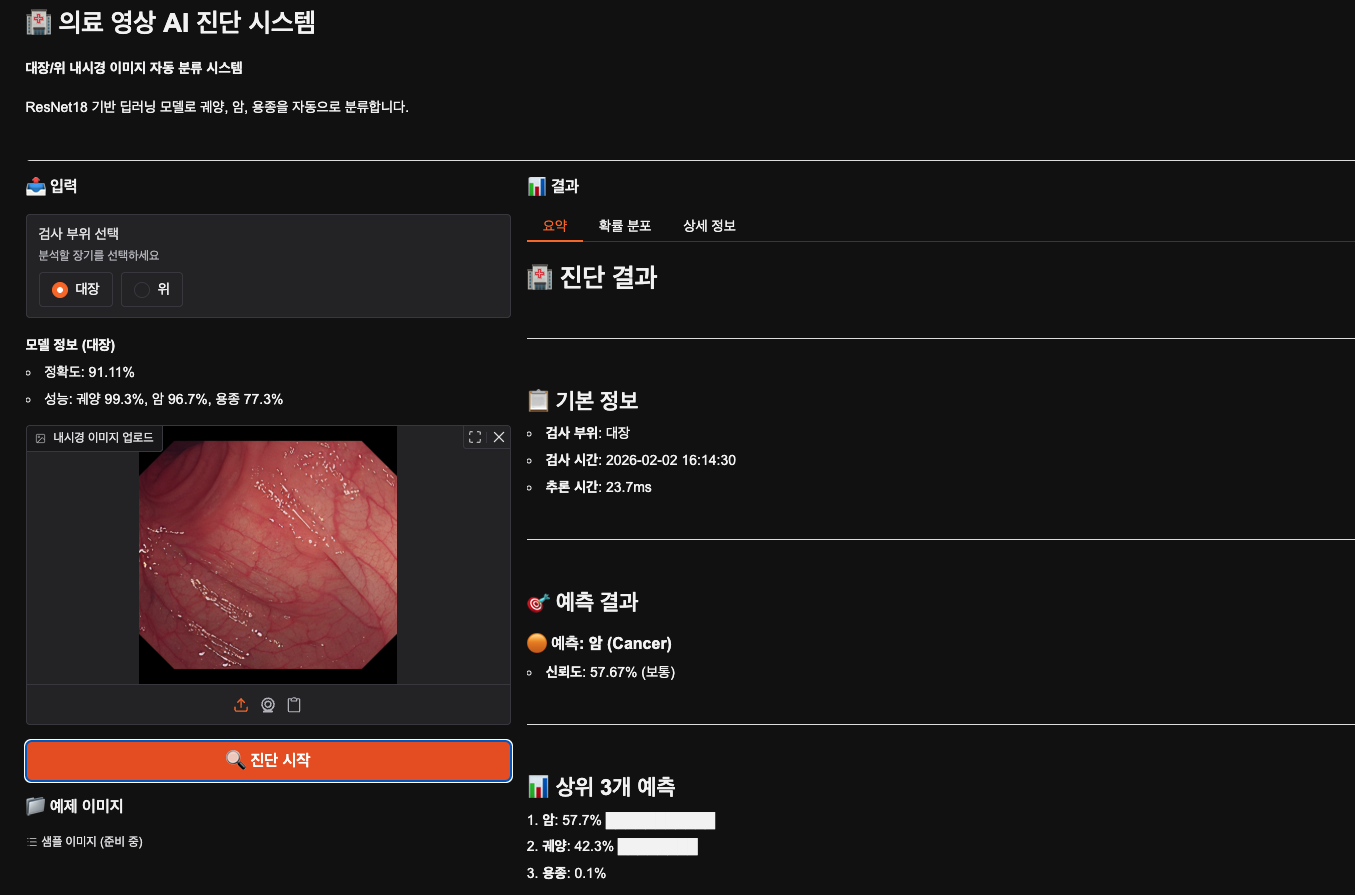
코드 오류난 곳 몇곳 수정 후 웹 app.py를 시켜봤더니 잘 분류해주었다. 대장에서 암 데이터를 입력했는데 아슬아슬하지만 암이라고 판단한 확률이 더 높았고 분류만 하는 거라서 그런지 되게 빨리 나왔다.
근데 아쉬운 점이 어디가 병변 구역인지 detaction이나 segmentation을 해주지 않는 게 아쉬워서 classification, segmentation이 한번에 되는 통합 웹 intergrated_app.py를 만들어 다시 이미지를 진단 시켜보았음!
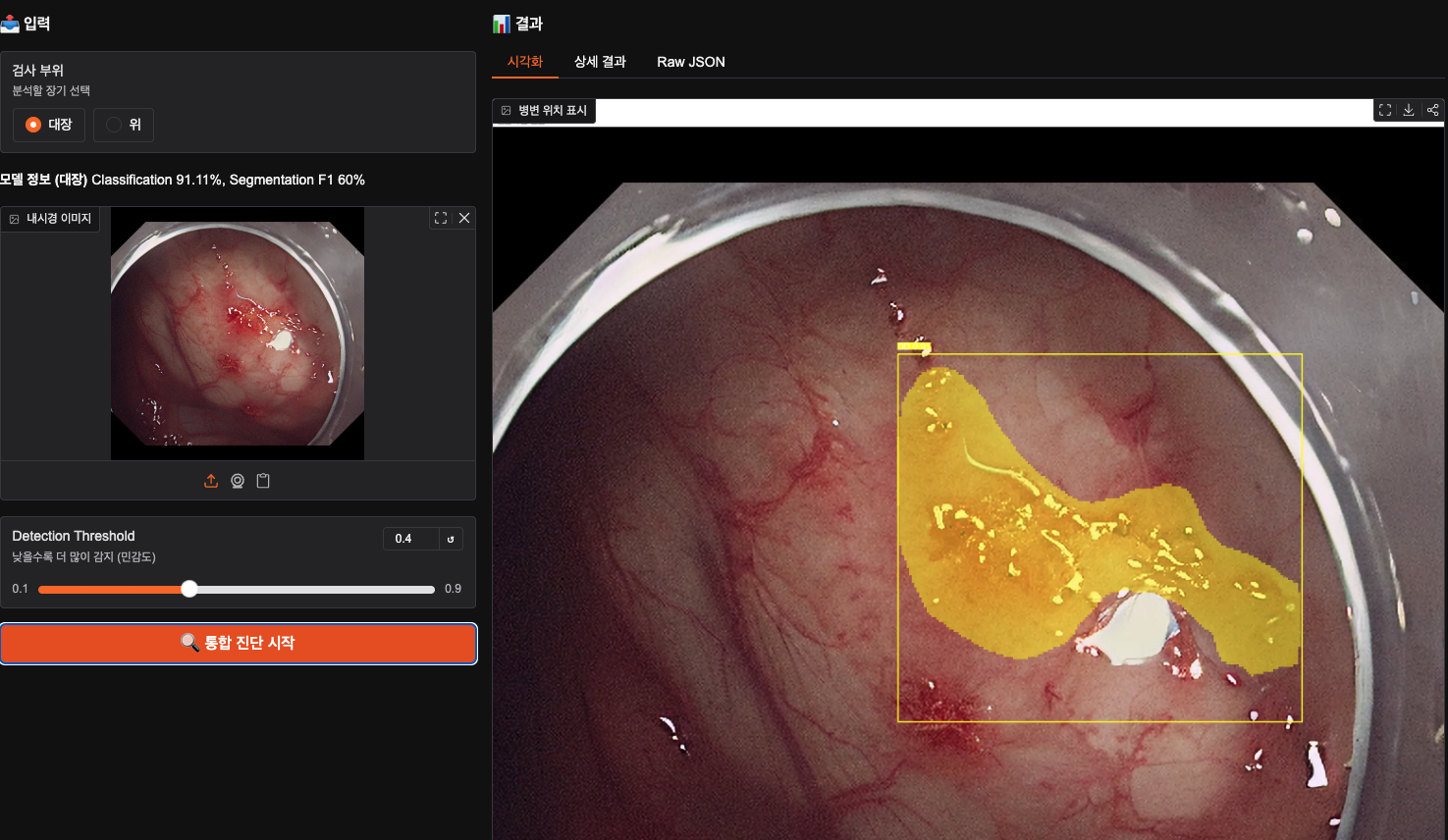
대장의 궤양인 부분을 포착하기는 했지만 완벽하게 포착했다고 보기는 어렵네요.
detaction 색에 따라 노랑은 궤양, 빨강은 암, 초록은 용종으로 구분해두었다.
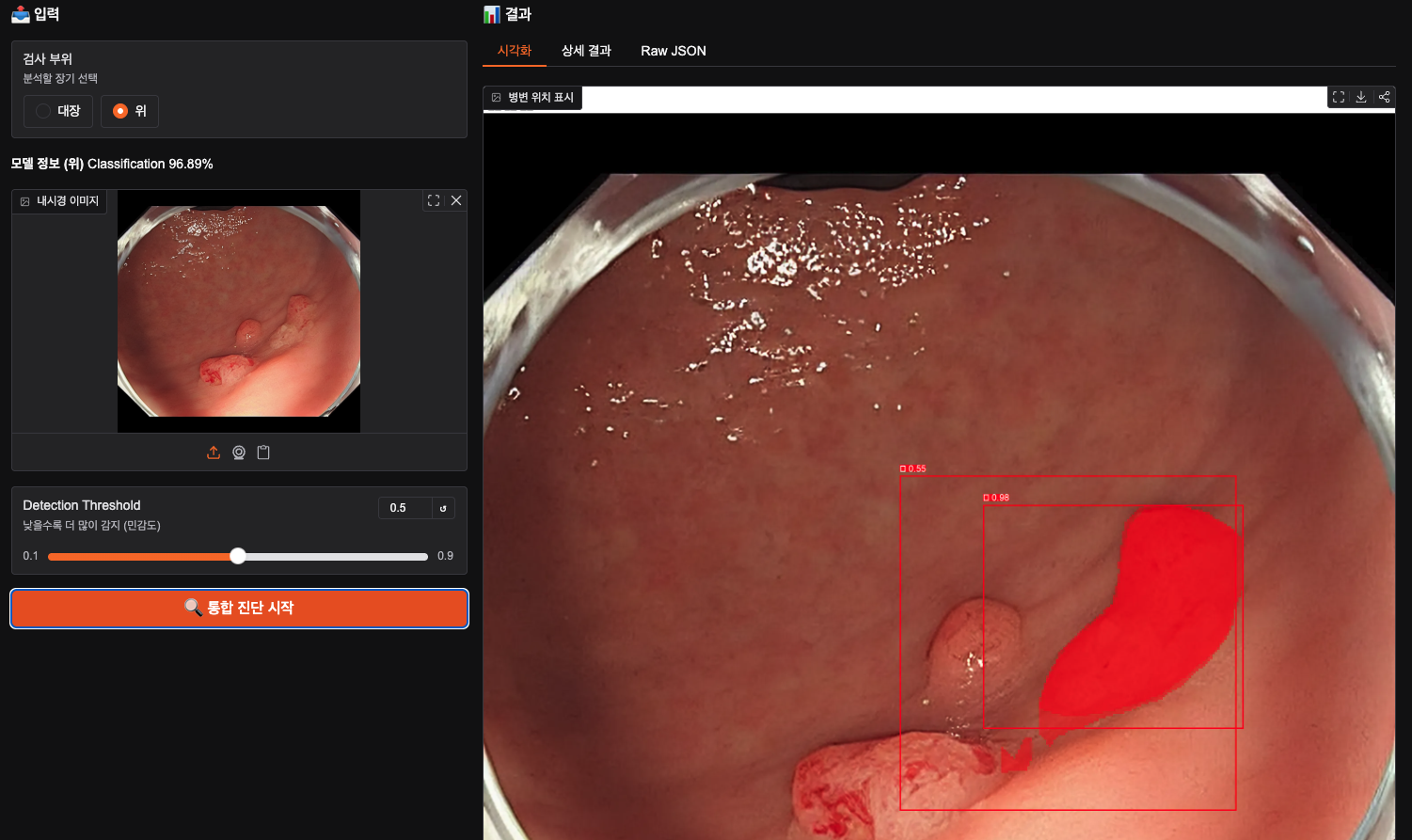
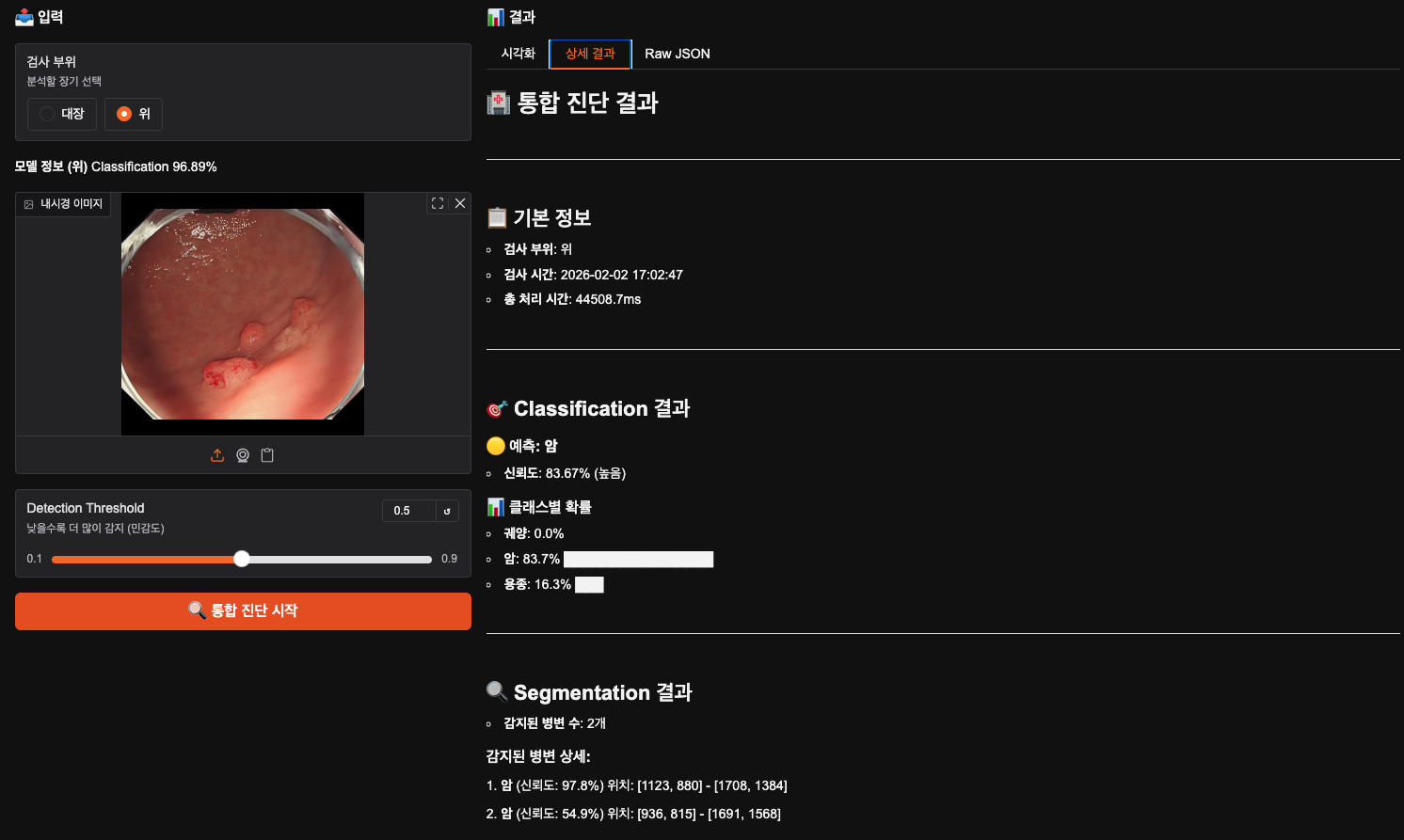
위의 암은 detaction했지만 segmentation을 보면 두개 정도는 빠뜨린 거 같아서 아쉽기도 하다. 아직 완전하지는 못하나보다. 모델이 학습을 더 한다면 괜찮아질려나? 그래도 암은 암이라고 분류할 줄 아는 게 신기하네.
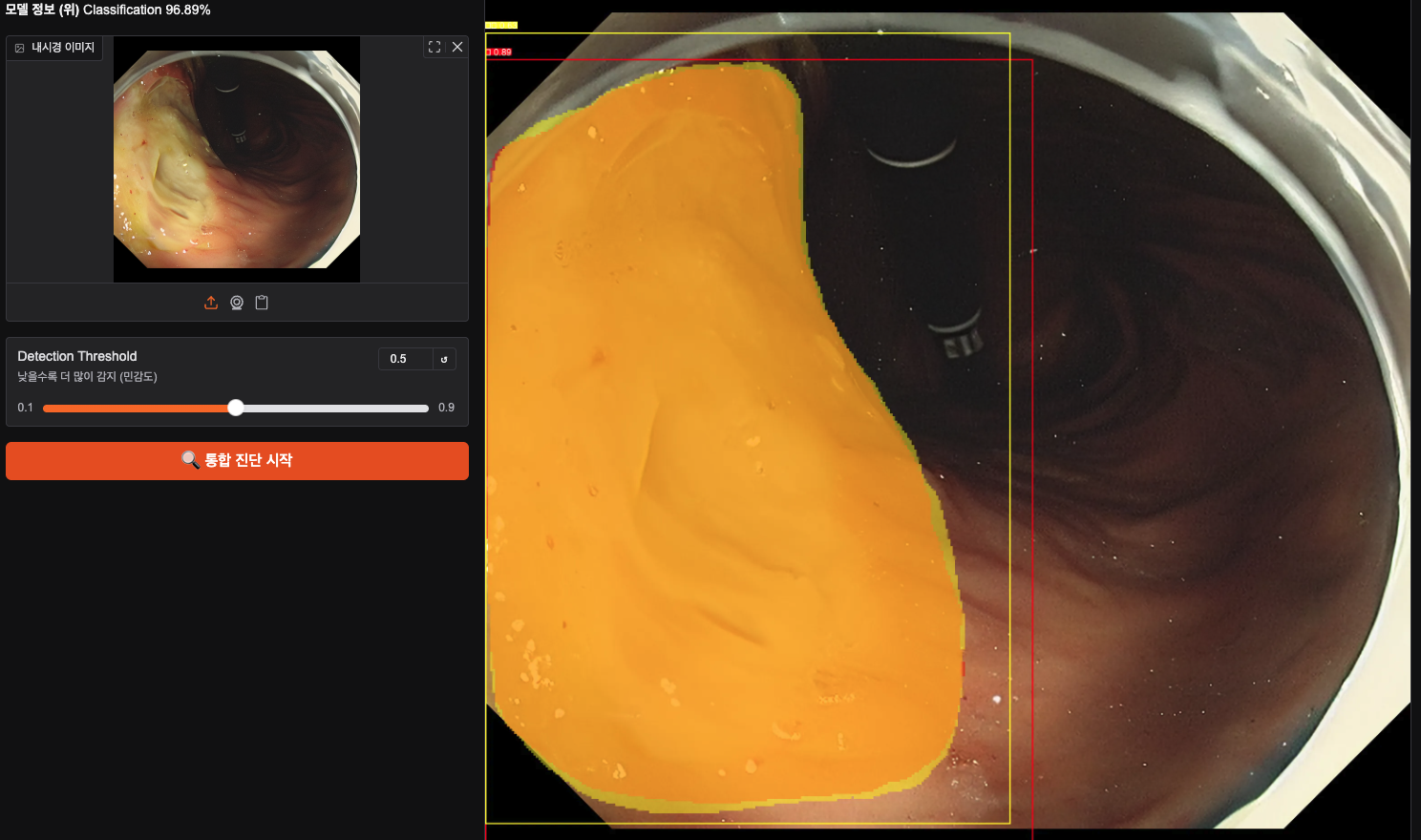
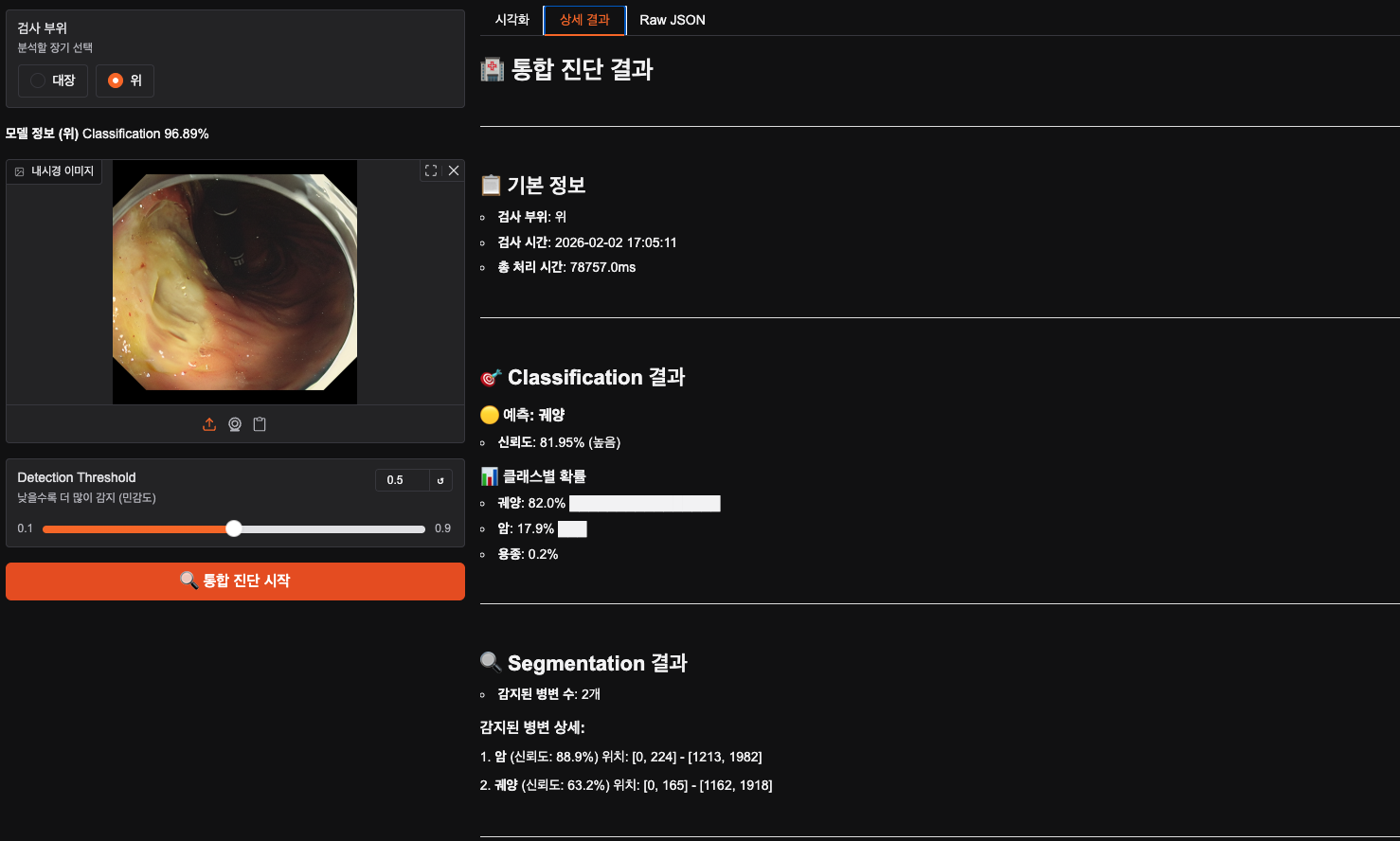
그다음은 위의 궤양인데 꽤나 segmentation을 병변 부위에 맞게 잘 한 거 같다.
분류 역시 궤양으로 잘 맞혔고 좋네요.
segmentation, detaction을 잘 못하는 경우를 방지하기 위해 쓰레쉬홀드를 0.1로 했더니 너무 과하게 찾아내서 0.3으로 다시 진단해보았다.
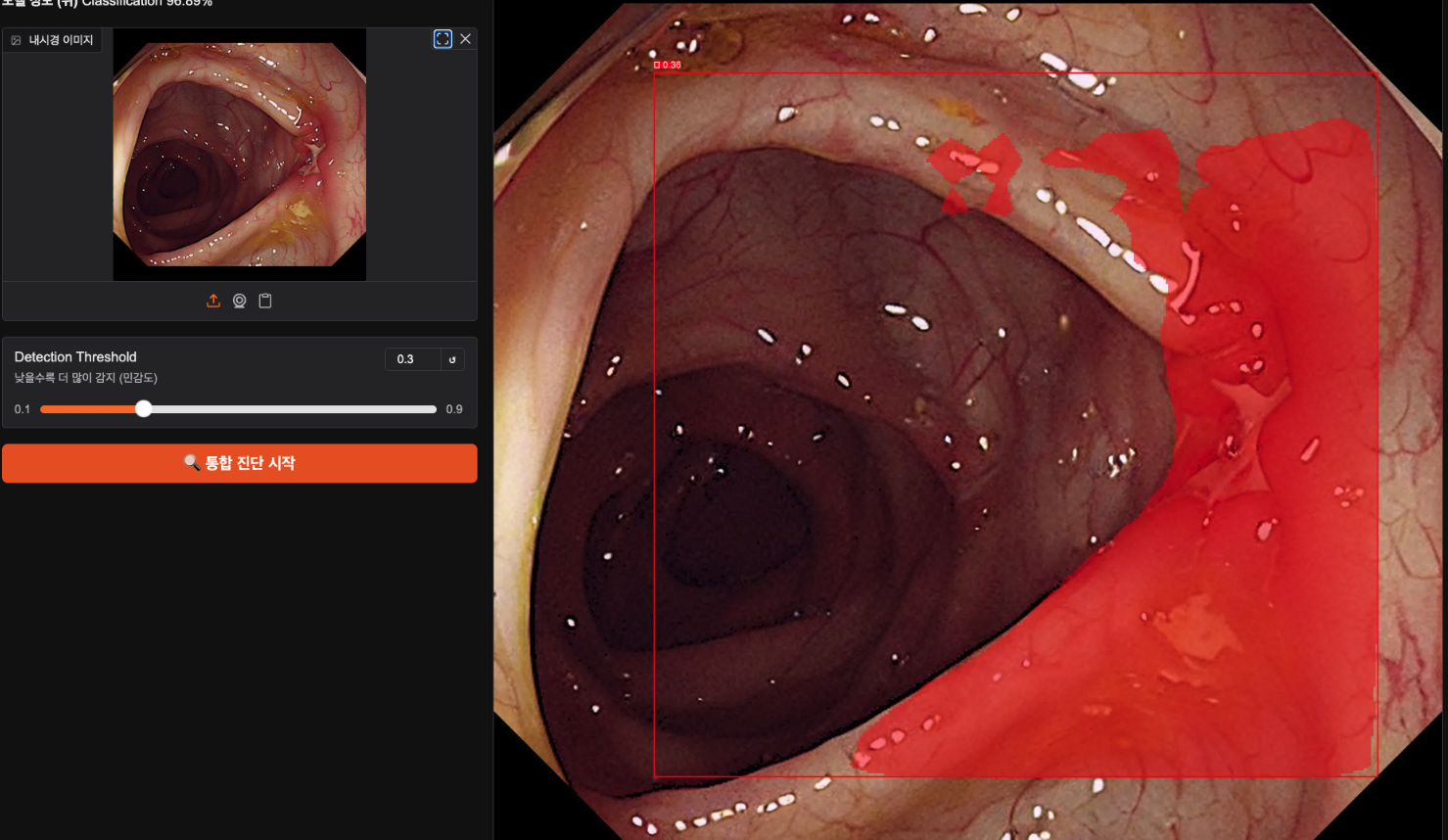
이렇게 1차적으로 병변이 있는지 찾고 분류 후 2차적으로 정확한 병변이나 정상적인 데이터가 껴있거나 하는 경우를 찾아내는 방법도 좋을 거 같다.
후~ 일단 이정도로 스터디 프로젝트는 마무리 할 거 같다.
꽤나 글이 길어졌는데 읽어주셨다면 감사합니다. 두서없이 쓴 글이라서 읽기 힘들었을테지만요. 재밌는 프로젝트였다. 전혀 모르는 대장, 위 내시경 이미지를 가지고 detaction부터 시작해서 segmentation, classification을 학습하고 검증하고 그 모델로 다시 시험해보는 일련의 과정을 전부 다 해보고나니 어떤 식으로 흘러가는지에 대한 큰 흐름을 느낄 수 있었다. 특히 실제로 웹으로 그것들을 통합하였을 때 되게 보람찬 느낌을 느꼈다.
인생에 영감을 줄 수 있는 일을 찾고싶다. 아침에 눈을 떴을 때 얼른 하고싶어지는 일!
감사합니다.
