코딩문제연습
1.문자찾기
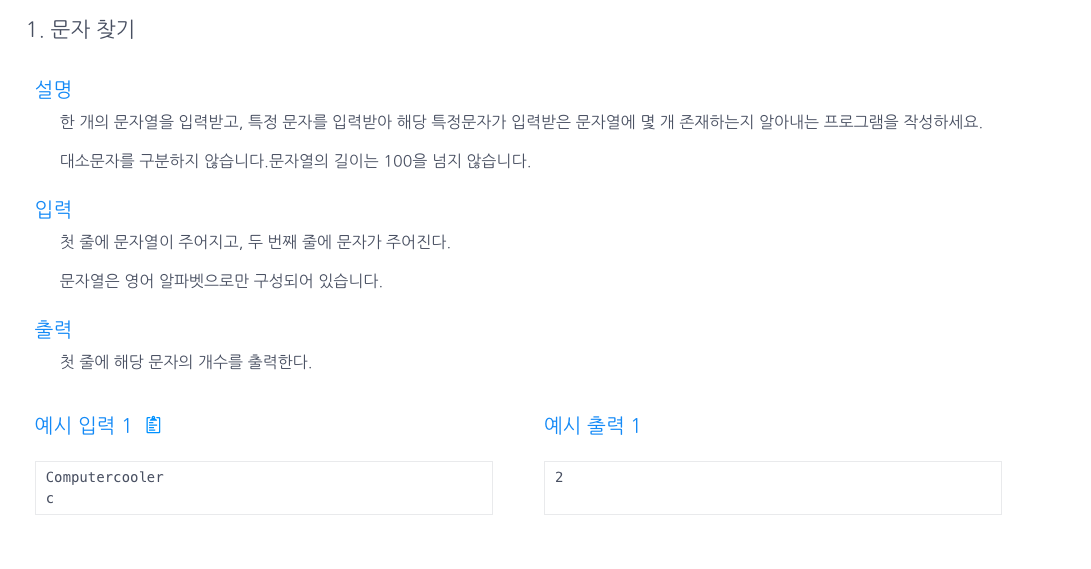
1.str의 길이만큼 for문을 돌려서 str.charAt(i)와 t가 일치하다면 answer는 ++;2.str을 .tocharArray()메소드를 이용하여 배열로 만든후, 배열 요소 x가 t와 일치하다면 answer는 ++;.tocharArray()를 사용하면 문자열
2.대소문자 변환
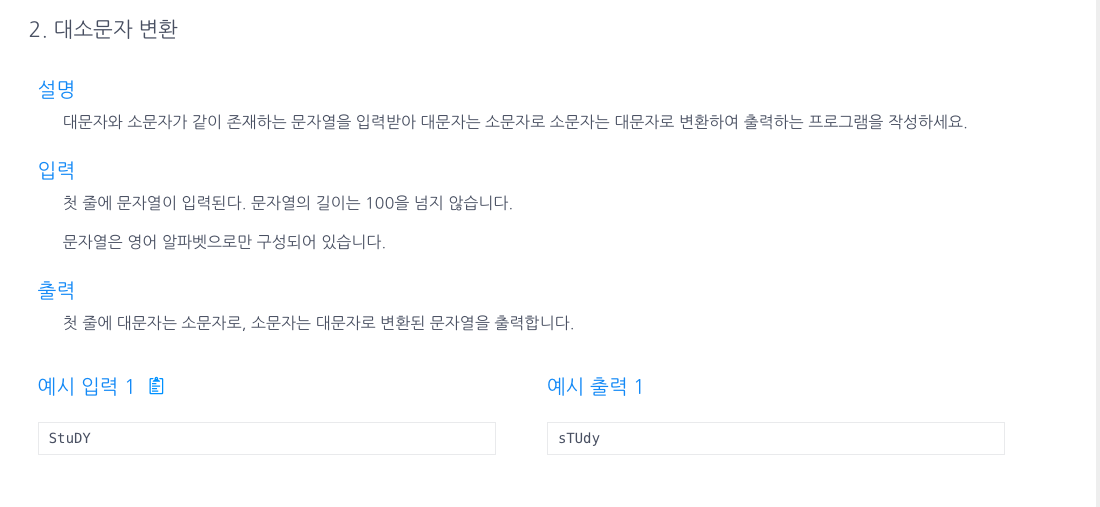
Character.isLowerCase() 또는 .isUpperCase() 메소드를 사용해 대,소문자 판별 후 for문을 통해 바꿔준값을 answer에 담는다.ASCII코드값을 이용해 대,소문자 판별 후 바꾼값을 answer에 담는다.ASCII코드 A~Z : 65~90
3.문장 속 단어
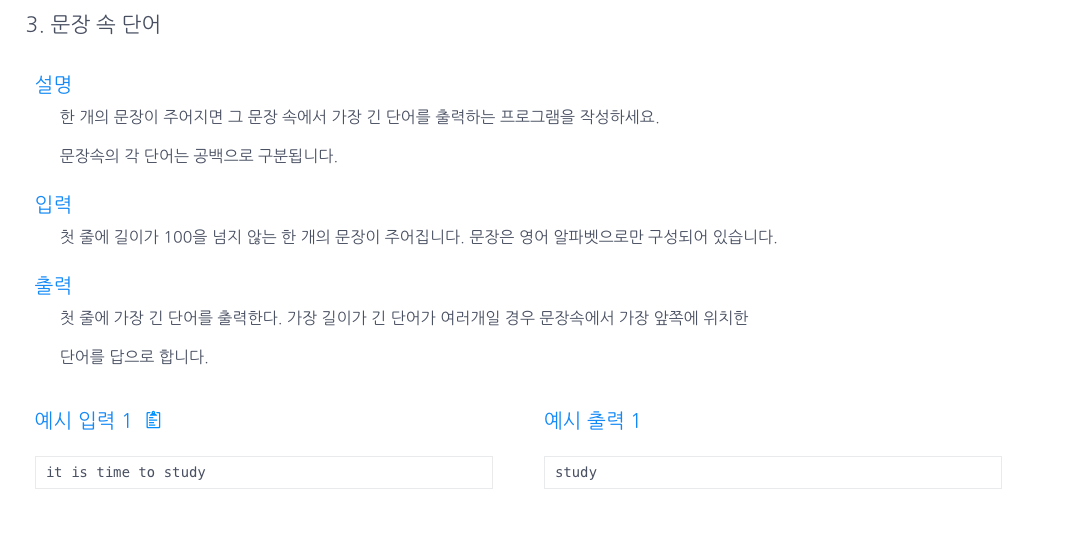
.()split 메소드를 사용해 a배열에 각각 값을 담고, for each 구문으로 최댓값을 비교.if(len>m)m = len;answer= x; \--> 즉, 현재 단어의 길이가 전 단어의 길이보다 길다면, m = 현재 단어의 길이가 되고 answer는 현재 단어를
4.단어 뒤집기 (StringBuilder)

StringBuilder 객체를 이용하여 뒤집기.new StringBuilder(x)의 reverse메소드를 통해 뒤집은 후,toString을 이용해 String으로 a 라는 값에 저장해준다.String a = new StringBuilder(x).reverse().
5.특정문자 뒤집기 (직접뒤집기 활용)
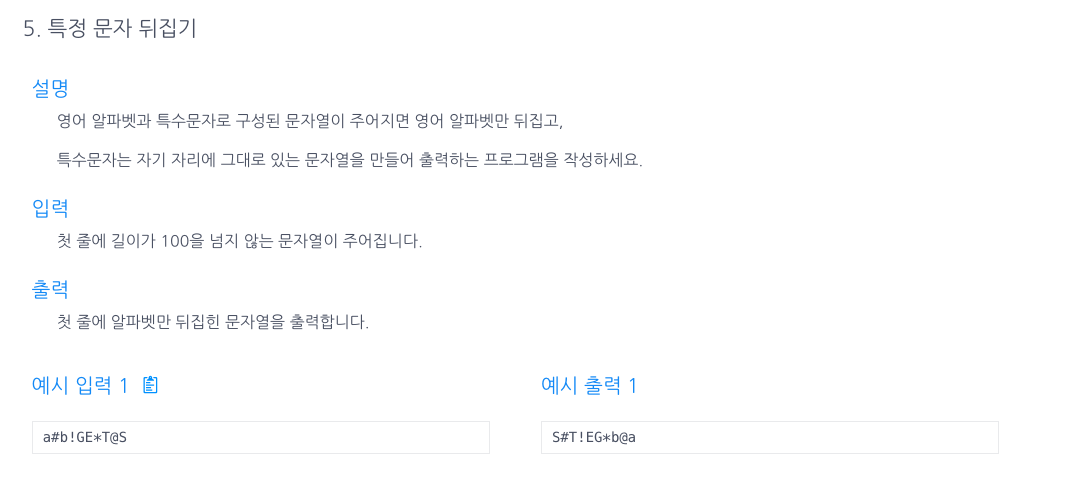
toCharArray 메소드를 통해 단어를 배열단위로 나누고, lt,rt를 통해 while문을 돌려준다.만약, lt가 알파벳이 아닌경우 = 특수문자를 만난경우. 바꾸지 않고 lt를 이동.만약, rt가 알파벳이 아닌경우 = 특수문자를 만난경우. 바꾸지 않고 rt를 이동.
6.중복문자제거
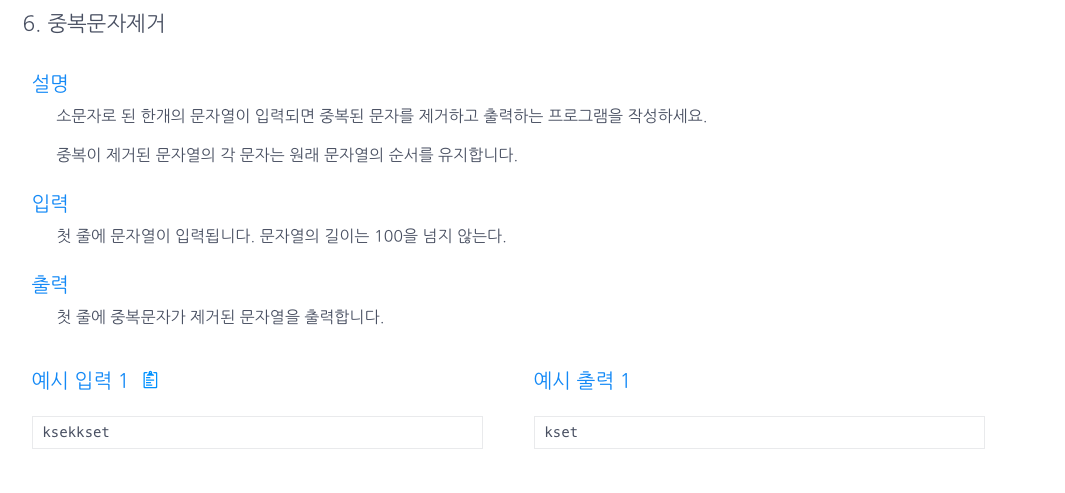
문제만 보고 내가 풀어본것인데, 객체생성하고 필요없이 for문을 두번이나 돌려서 구현한것같은 느낌이다...indexOf가 갖는 가장 큰 특징중 하나는 그 찾는문자의 가장 빠른 index만을 갖는다는 것이다.예를들어) String str = kakaooo에서 str.in
7.회문문자열 (.equalsIgnoreCase())
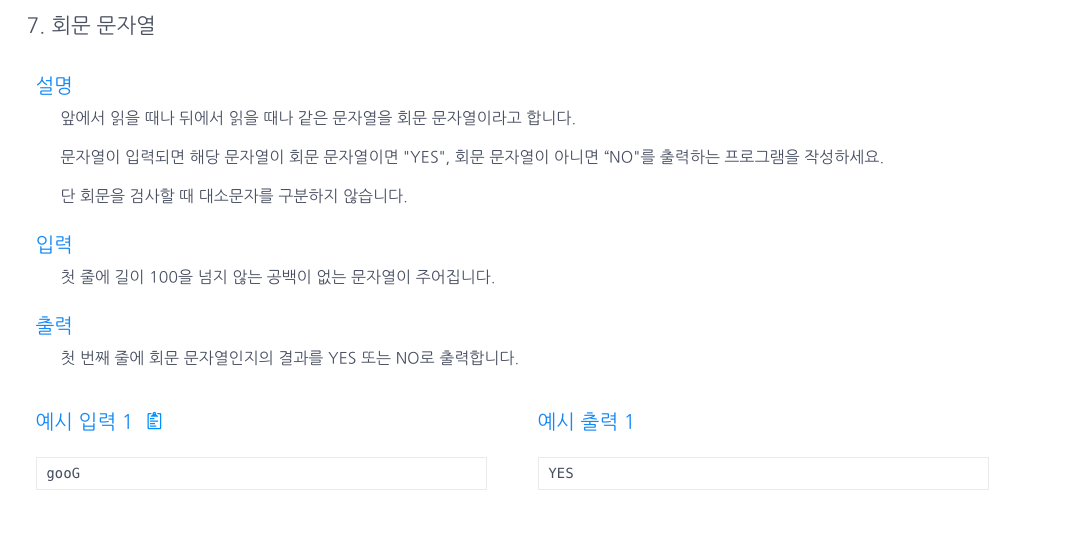
문제만 보고 직접 풀어본 것인데, 전부 케이스를 같게 해주고 뒤집은것과 원래 스트링을 비교했다..equalsIgnoreCase()메소드를 사용하면 대,소문자 관계없이 비교가 가능하다!직접비교 하는 방식인데 홀,짝 상관없이 해당 string의 길이의 절반만 for문을 돌
8.유효한 팰린드롬 (replaceAll 정규식 이용)
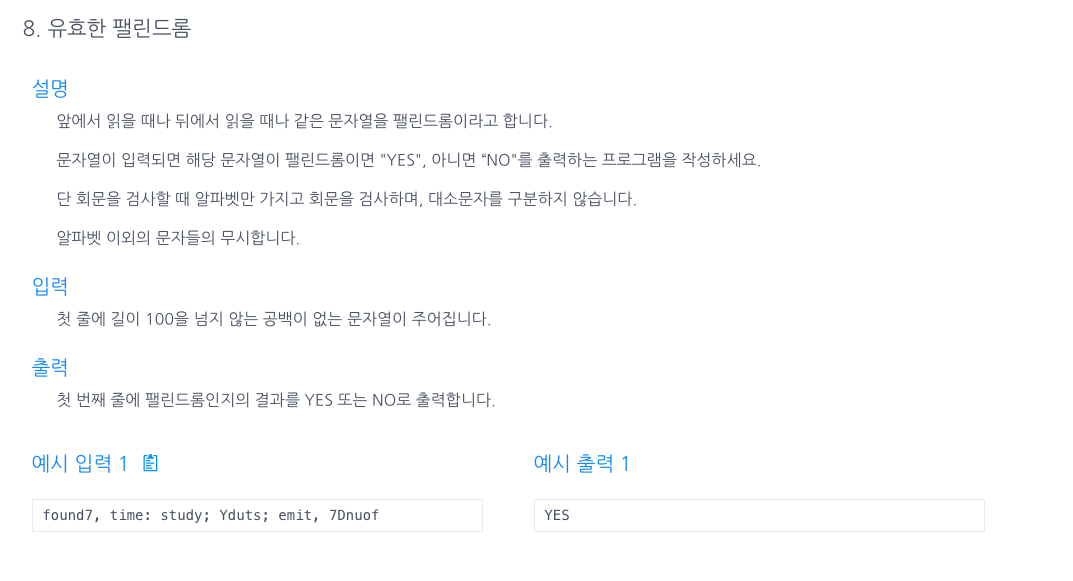
대,소문자 구분을 피하기 위해 toUpperCase로 전부 대문자로 바꿔준 후,replaceAll("^A-Z","")을 통해 A-Z까지의 문자가 아닌것을 전부 ""로 바꿔준다.StringBuilder로 뒤집힌 문자를 만들고 그 문자와 현재 문자를 비교하면 끝!repla
9.숫자만 추출
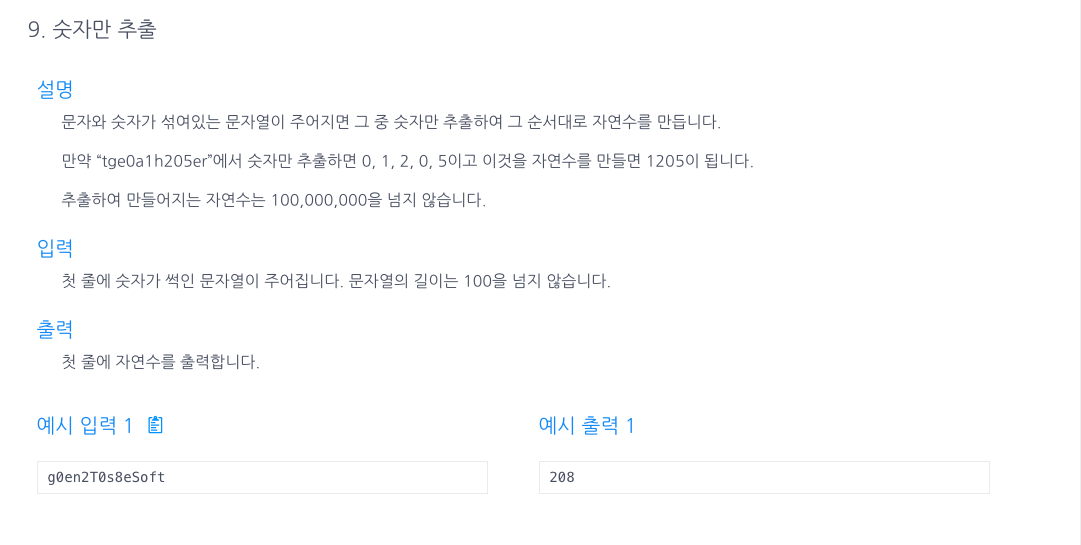
0~9의 아스키코드가 48~57인 점을 이용해서 만약 조건을 충족한다면res = res \* 10 +(x-48); 을 통해 값을 저장해준다.예시) 0 2 0 8 을 받으면, 1) res = 0 x 10 +(48-48) = 02) res = 0 x 10 +(50-48)
10.가장 짧은 문자 거리(앞,뒤에서탐색)
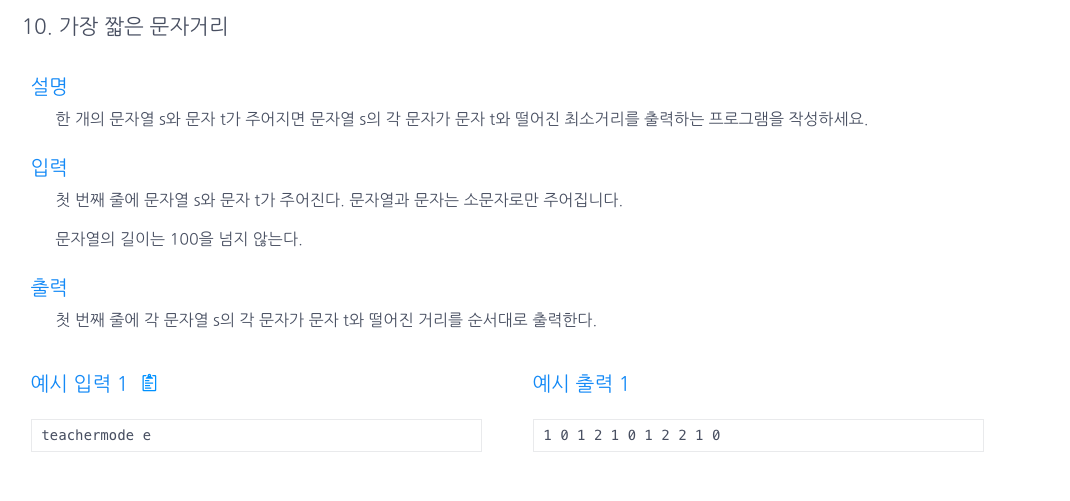
처음에 나는 원래 문자와 뒤집은것과 비교해서 둘다 배열로 거리를 저장하고 그 배열끼리 비교하면서 작은값을 리턴하려고했다.그럴 필요없이 0부터 탐색 vs length-1 부터 탐색을 통해 값을 비교하면서 작은값을 리턴해내면 된다.1\. for(int i=s.length(
11.문자열 압축
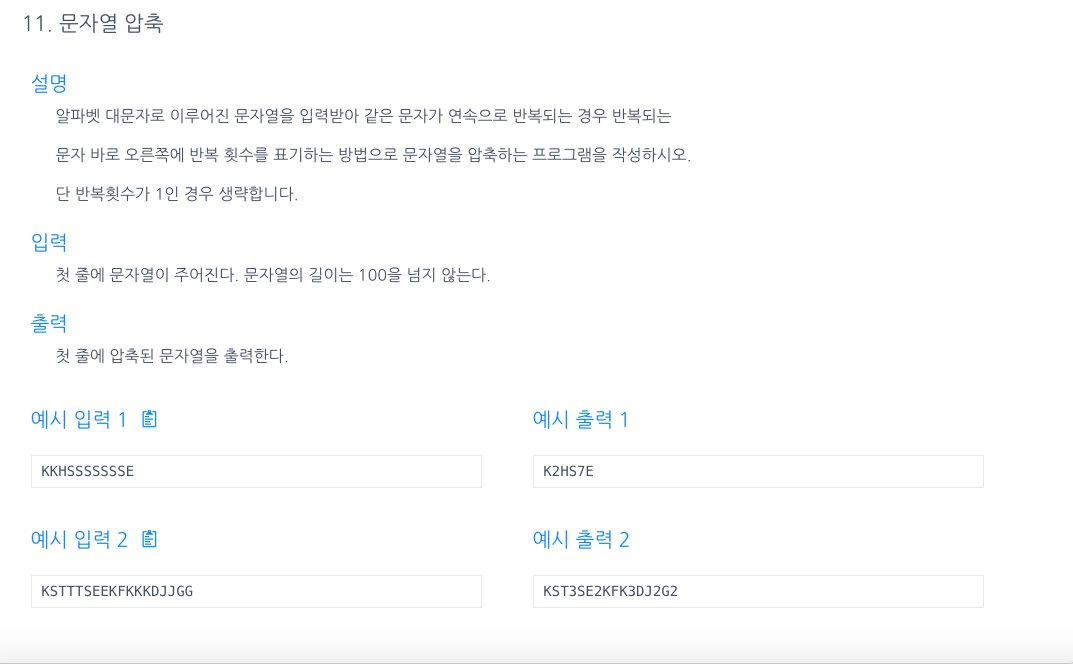
먼저, 문자열 s에 빈 문자 " "를 넣어준다. (s = s + " ";)그리고 count를 1에둬야 한다.그 이유는 처음 발견된 문자도 count할 때 포함되야 하기 때문.그 후, for문을 통해 현재 문자와 다음 문자를 비교해서,같다면 count만 1증가 / 다르다
12.암호 (문자열 활용)

효율적인풀이내 풀이방법이 틀린건 아니지만 코드 양이 많고, 조잡하다..효율적인 풀이법과 내 풀이의 차이점을 보자면,1\. for문을 n회만큼 돌린다. 그리고 전체 스트링을 놓고 보는게 아닌, substring후에는 필요없는 부분은 제외하고 처리한다. (배웠는데 ㅠㅠ)
13.2021 KAKAO BLIND RECRUITMENT 신규아이디추천
2021 KAKAO BLIND RECRUITMENT 신규아이디추천문자열 다루는것의 총집합인것 같다.. 다른분의 풀이를 보니 정규표현식을 이용해서 (temp 는 현재값)temp = temp.replaceAll(".{2,}",".");\--> ' . ' 이 두개 이상있을시
14.큰 수 출력하기
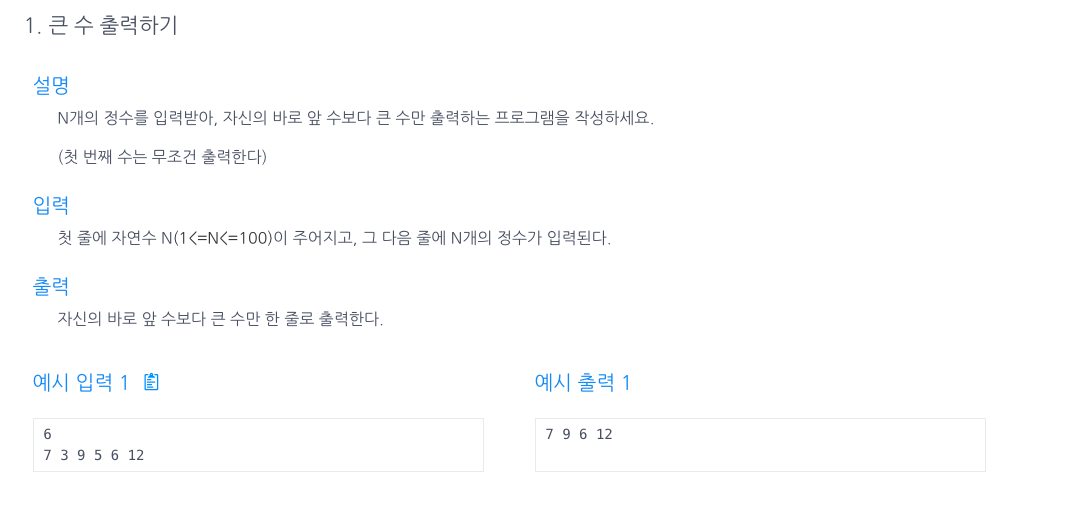
비교적 간단한 문제라서 쉽게 풀었다.배열을 1부터 시작하는것.
15.보이는 학생
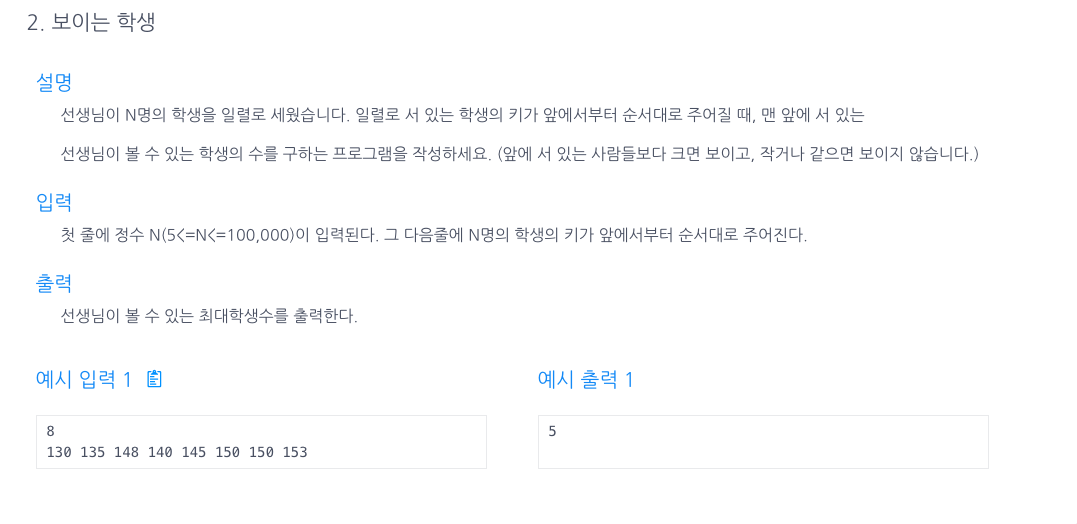
맨 앞 학생은 무조건 보이기때문에 카운팅을 1로 설정해두고,최댓값에 맨 앞 학생의 키를 설정해뒀다.for문을 돌면서 최댓값을 저장해서 만약 앞의 학생들보다 가장 크다면 카운트를 해주고 아니라면 그냥 지나치게 했더니 풀렸다!처음엔 배열을 하나더 만들어서 비교하려했다.조금
16.가위바위보

3가지 경우로 나눠서 생각했다.1\. 같은경우 = D2\. A가 이기는경우 = A3\. A가 지는경우 = B한 명의 경우만 생각해서 효율적으로 문제 푸는방법을 떠올리자!
17.피보나치 수열
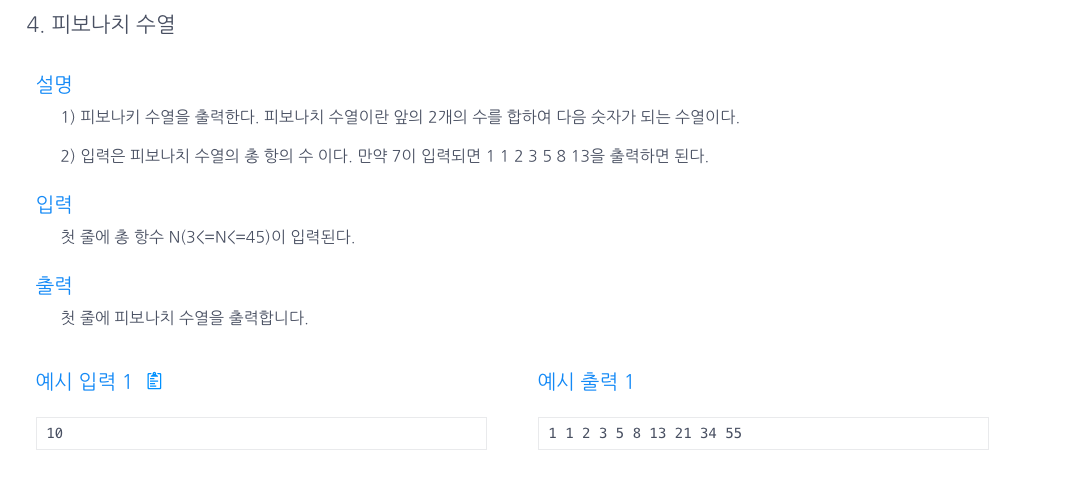
배열로 풀 때n크기의 배열에 1,2번째 값을 미리 넣은 후, 그다음 값부터 for문을 통해2칸 앞 + 1칸 앞 = 다음값으로 지정해서 배열에 추가해주었다.손코딩으로 풀 때배열과 비슷하게 1,2번째 값(a,b)은 미리 출력해주고, 다음 값부터 for문을 통해 a+b =
18.소수찾기 (에라토스테네스의 채)
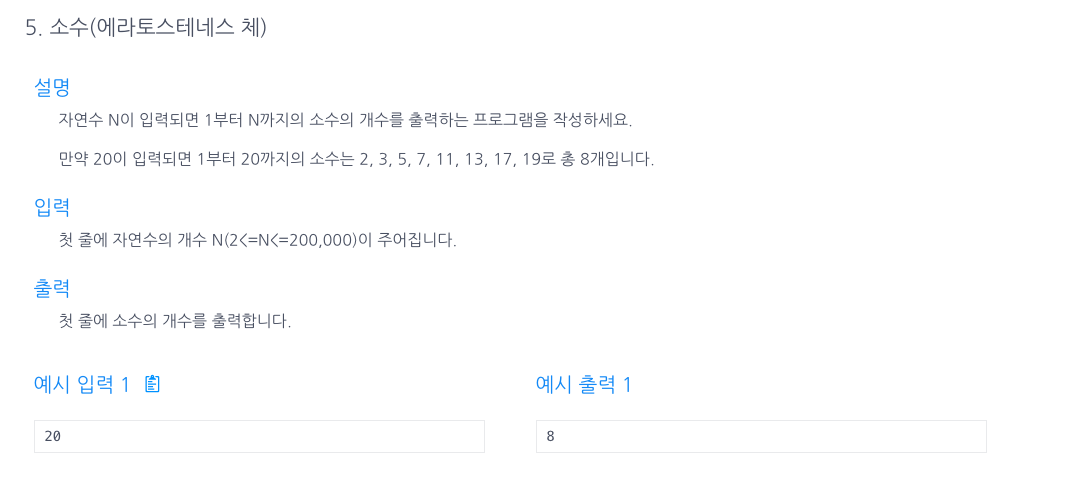
n+1까지의 동적 배열을 생성해주면 ch = 0,0,0,0,0,0,....이런 배열이 생성되는데, for문을 통해 2부터 탐색을 시작해서 chi가 0이라면 카운트가 1증가하고,i의 배수 즉, chj (j=j+i 를 하게되면 배수들만 선택할 수 있다.)를 1로 만들어주면
19.뒤집은 소수
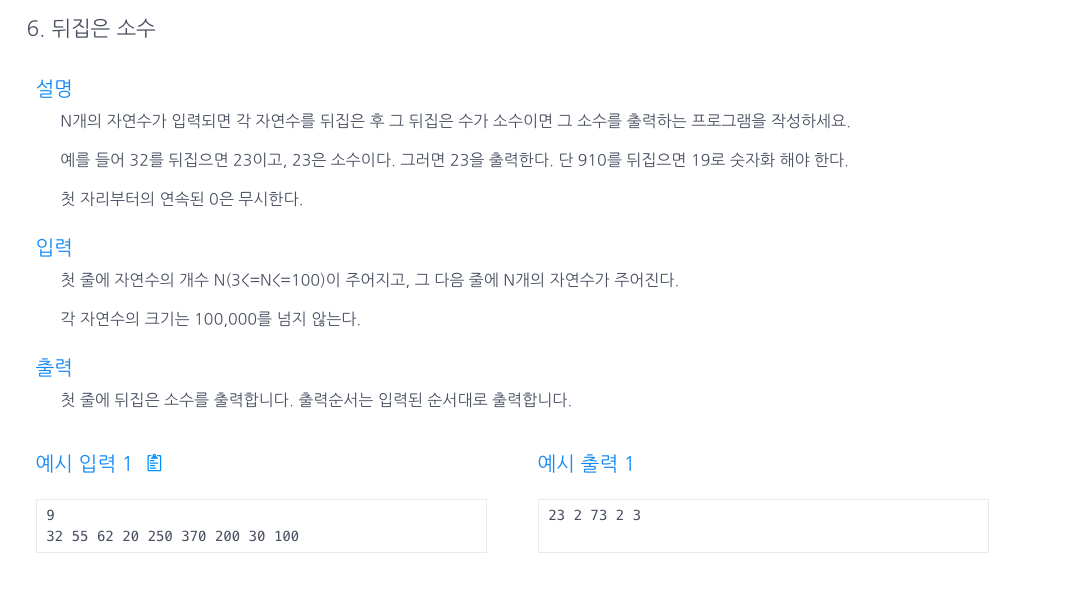
다른 isPrime을 따로 만든 풀이법처음엔 에라토스테네스의 체를 써서 해당 수의 제곱근까지의 배수만 전부 제외 시키는것을 따로 함수를 작성하지 않고 해결했는데,for문에서 rt까지 포함시켜야되는 사실을 모르고 애먹었다..2.isPrime을 따로 두고 숫자를 뒤집는것도
20.점수 계산

더 간단한 풀이내가 처음 푼것은 카운트가 0일때와 아닐때를 나눠서 생각했는데,틀린것은 아니지만 조금만 더 생각하면 더 짧게 나타낼수있다.answer에 1을더하고 count를 따로 더하는것이 아니라 count에 먼저 누적을시키고 count를 answer에 더하는것으로 해
21.등수 구하기
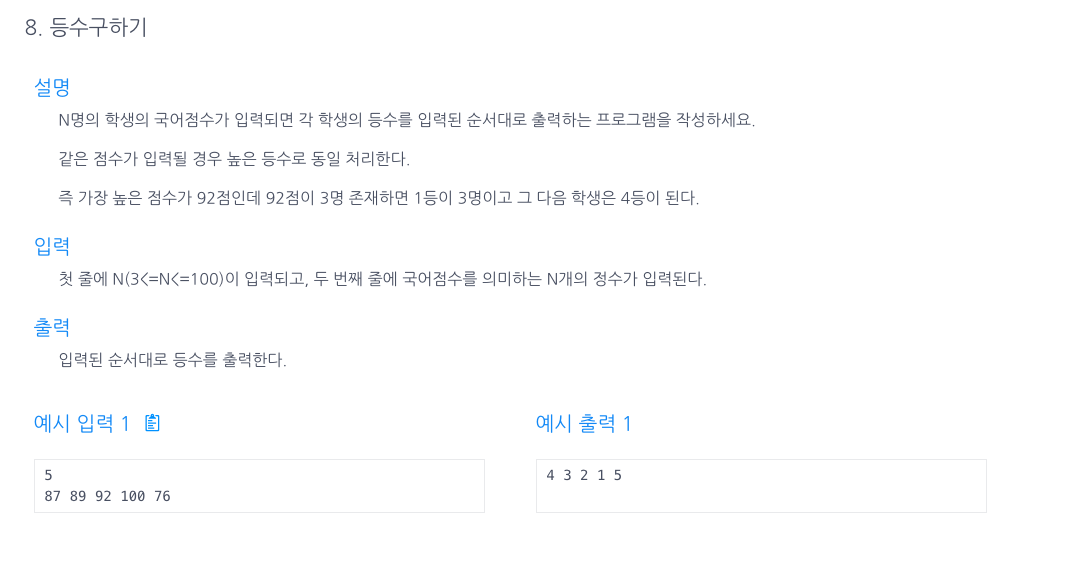
이중 for문을 통해 현재 숫자가 배열 안에서 더 큰 숫자를 만났을때만 count를 1증가시키면 그 count가 최종적으로 등수가 된다.이중for문이 나쁜것이 아니므로 활용해야할땐 잘 써먹자!
22.로또의 최고 순위와 최저 순위
로또의 최고 순위와 최저 순위당첨번호를 로또번호와 쉽게 비교하기위해 wn에 담았다.그리고 최고등수와 최저등수를 나눠서 비교했는데,최고등수일땐, 당첨번호 또는 0을 만났을때 count가 1 감소하게 했고,최저등수일땐, 당첨번호을 만났을때만 count가 1 감소하게 했다
23.격자판 최대합

int answer = MIN.VALUE 로 설정한 이유는,이 문제에서는 범위가 자연수로 정해져 있지만 만약 값 중에서 음수가 있으면 합이 0보다 적은 값이 나올수있기 때문에 integer의 가장 최솟값으로 설정했다.이중for문으로 각 행을 sum1에 저장하고 각 열을
24.봉우리
문제 나의풀이 ++ 위치값을 설정해서 푸는방법! 풀이방법 미리 0이 추가된 배열보다 더 큰 격자판에 핵심키워드
25.임시반장 정하기
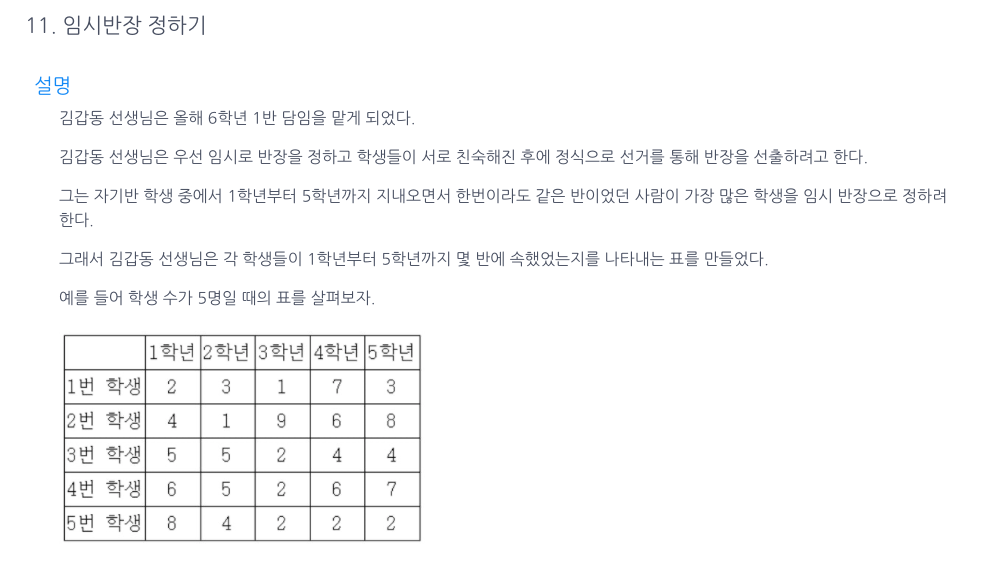
i는 고정된, 즉, 현재 선택된 학생이 j번호의 학생과 k학년일때 같은반이 된 적이 있는가 탐색했다.만약 같은반이 된 적이 한번이라도 발견되면 count가 증가되고 그 즉시 k문은 멈추고 다음 번호학생과 비교한다. (학생 수만 비교하기때문에)한 학생의 비교가 완전 끝나
26.멘토링 (4중 for문)

4중 for문... 이해하기도 너무 어려웠다.먼저, i,j로 1,2,3,4번 학생의 번호를 고정시킨다. ex) i = 1, j =3그 후, 테스트의 갯수(m)만큼 3번째 for문을 돌리고,등수(s)를 찾기위한 4번째 for문을 돌린다.만약, arrk == i와 일치하는
27.두 배열 합치기(Two Pointers)
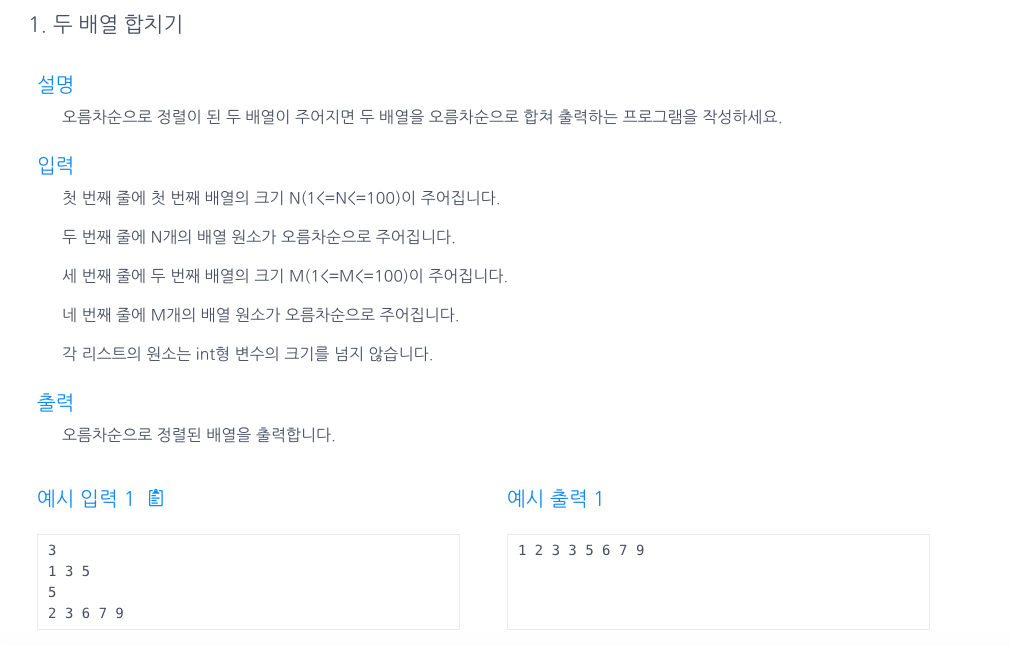
풀기 앞서,Two Pointer 란?문자 그대로, 두개의 포인터를 이용해서 알고리즘을 풀어나가는 방식이다.Two pointers 풀이방식은 O(N)의 시간만 가지고 풀어낼 수 있다.a배열의 포인터 p1 과 b배열의 포인터 p2를 각각 만들어주고while문으로 탐색을 시
28.공통 원소 구하기
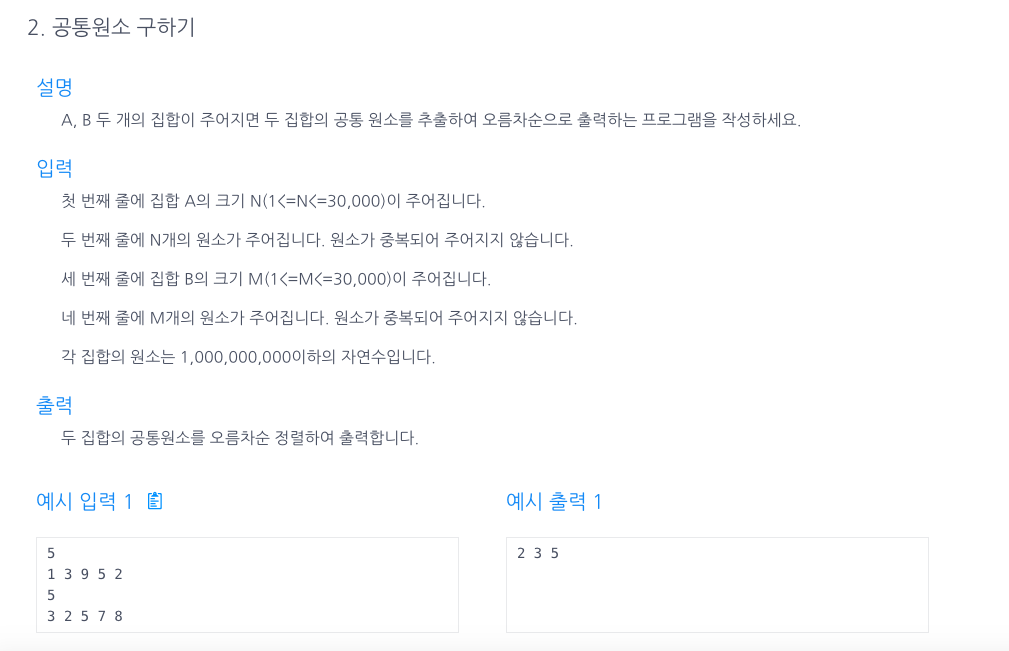
예제의 배열 a,b를 sorting 하면a = 1,2,3,5,9 b = 2,3,5,7,8 이다.p1,p2를 0으로 세팅해두고, 만약 두 배열중 작은값이 발견된 배열은 포인터가 1 증가해야한다.왜냐하면, 큰값이 발견된 배열에는 더이상 발견된 작은값보다 작은값이 없지만,
29.최대 매출 (Sliding window)
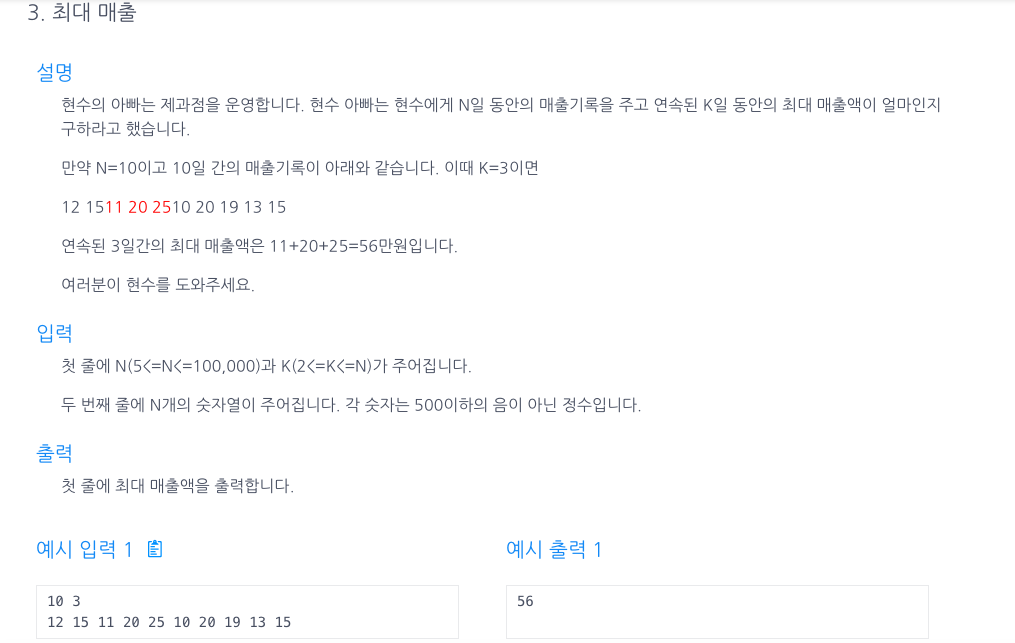
미끄러지는 창문? 연속된 k일 동안, 예를 들어 금토일, 토일월, 일월화 처럼 요일중 어떤 일정한 규칙의 연속된 자료의 최댓값이나 최솟값을 구할때 유용할 것같다.1 2 3 4 5 6 7 8 9...n | 월 화 수 목 금 토 일 월 화 ...n 에서 초기값이\[]라는
30.연속 부분수열
1 2 1 3 1 1 1 2 이 담긴 1차원 배열에서 m=6일때, 연속으로 더해 m값이 되면 카운팅을 한다.처음엔 while문 안에 for문을 넣어서 풀어보려했지만 잘 되지 않았다.풀이방법은 우선 start와 end를 정해줘서 start가 end를 쫓아가는 과정이다.f
31.연속된 자연수의 합
풀이는 바로 이전문제와 동일하다.for문의 길이를 n/2+1로 잡는 이유는,n=15라면 최대 7+8 즉, (15/2) + (15/2+1)를 넘어가는 순간 무조건 15초과의 값이 나와버리기 때문이다.만약 n이 10이어도 4+5를 넘어가는 순간 다음 연속된 수는 10이 절
32.연속된 자연수의 합 2 (수학적풀이)
그냥 와... 소리밖에 안나오는 풀이였다.코드라고 생각하지 않고 본다면, 15라는 숫자를 만들기위해연속된 n개 수를 구할려면, 1 + 2 + 3 + ... + n 값을 주고 15에서 (1+2+3...+n)를 뺀 후, 그 값이 n으로 딱 떨어져서 동등하게 분배를 해주면
33.학급 회장(해쉬)
먼저 foreach문을 통해 key값과 그 key값이 나온 횟수만큼 counting을 해서 결과적으로A : 2, B : 3, C : 5, D : 2, E : 3 값이 담긴 Hashmap을 만들었다.다시한번, foreach문을 통해만약, 현재 value값이max보다 크다
34.아나그램 (해쉬)
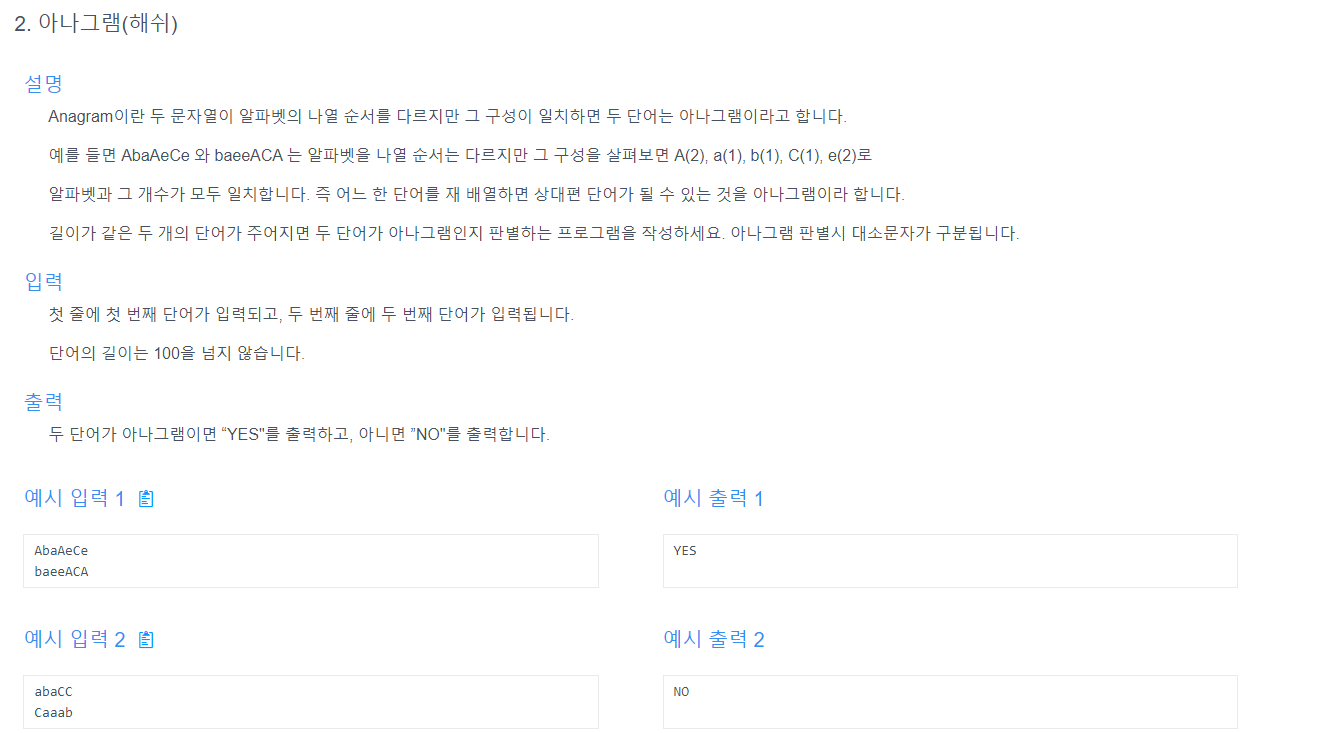
두 문자를 모두 hashmap에 따로 넣어서 두 map을 만들었다.그리고, 1번map과 2번map의 key값이 다르거나 key는 같아도 value값이 다를경우 NO를 리턴했다.두개중 한쪽만 hashmap에 넣었다.만약 abaCC를 넣었다면, map = {'a':2, '
35.최대 길이 연속부분수열
\++ 다른풀이나는 start를 고정시켜두고 while문(변경가능횟수k가 초과됐음에도 0을 만나면 종료)을 돌려서 1을 만나면 end,cnt(길이)를 증가시켰다.만약, k<0인데 0을 만난다면 break;되고 cnt까지가 최대길이이다.answer에는 최대길이를
36.매출액의 종류 (Hashmap + Sliding Window)
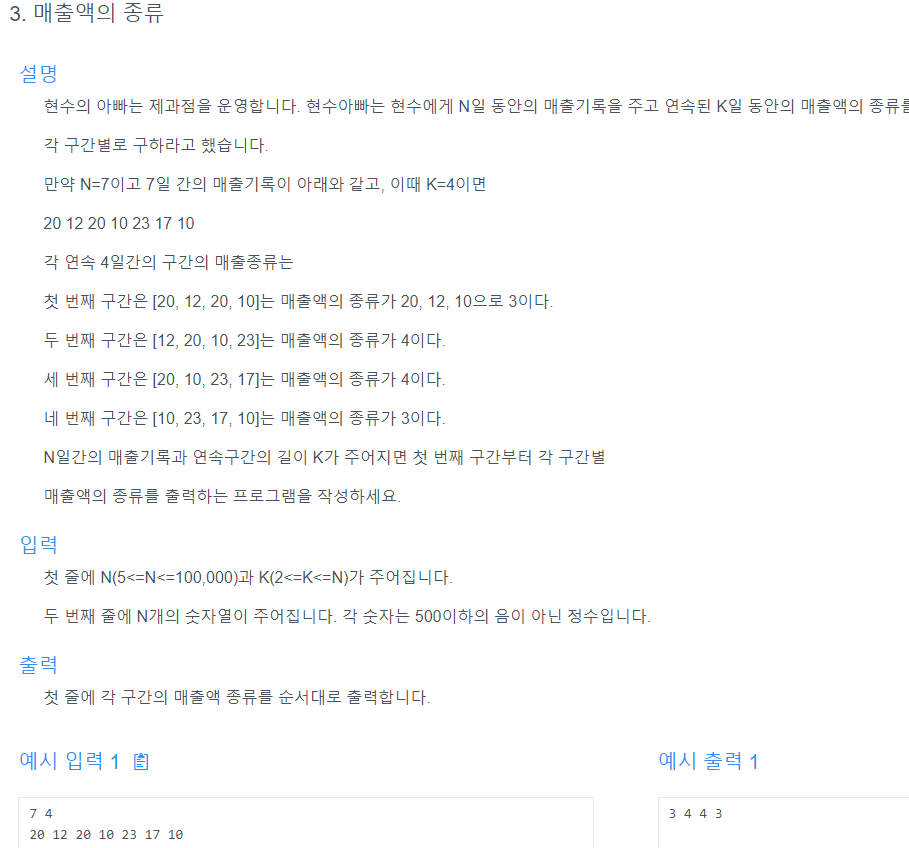
핵심
37.모든 아나그램 찾기(시간복잡도 O(n) Hash,sliding window)
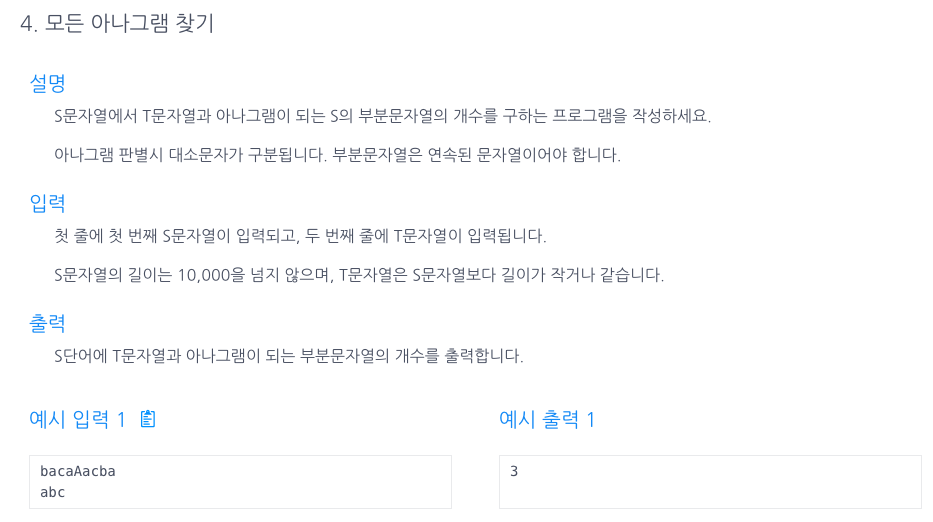
판별문자(t)를 해쉬맵에 넣고 비교할 문자(s)를 초기값으로 t의 len-1전까지 해쉬맵에 넣었다.lt가 rt를 쫓아가는 sliding window를 통해1) rt값을 넣는다2) smap과 tmap을 비교한다(.equals)\++2.1) if(smap.equals(tm
38.K번째 큰 수
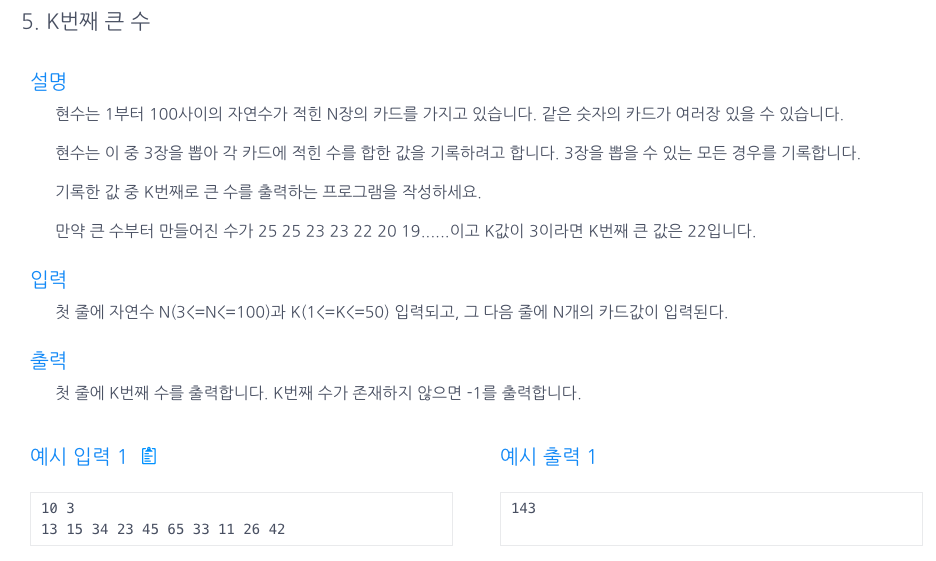
\++ for문의 바깥범위를 모두 n으로 해줘도 상관은없다!j값이나, l값이 거짓이되면 자동으로 멈추기 때문.. TreeSet은 기본적으로 오름차순(1,2,3,4...)으로 숫자를 저장한다.Set이기 때문에 당연히 중복값은 저장하지 않는다. Collections.rev
39.올바른 괄호(Stack)
정상적인 괄호가 되려면 짝이 맞아야하므로,'(' (여는괄호)는 전부 stack에 넣어두고 ')' 닫는괄호는 짝이 있는지 확인하고 있다면 pop()없다면 정상적인 괄호가 아니므로 NO가 된다.Stack은 LIFO(Last-In First-Out)형태로 카드 덱이라고 생각
40.괄호문자제거
\++ while문 수정나는 ')'를 만나면 여태 쌓아온 stack에서 '('를 만날때까지 pop시키기 위해 lastElement가 '('가 아니라면 pop을계속하고 '('를 만난순간 까지 pop시키고 다음으로 넘어갔다.하지만 while(stack.pop() != '
41.카카오 크레인 인형뽑기(stack)
카카오 크레인 인형뽑기현재 위치(pos)와 i로 2중 for문을 돌면서 만약 현재값이 0을 만나면 더 밑으로 내려가고, 0 이외의 수를 만나면, 현재 바구니의 맨 윗값과 비교해 같다면 맨 윗값을 pop, 다르다면 그냥 바구니에 넣었다.크레인에서 뽑히게 되면 현재값을 0
42.후위식 연산(postfix)
후위식연산을 어떻게 표현하는지 이해하는게 좀 어려웠다...숫자는 모두 stack에 넣고연산자를 만나면 숫자를 두 개 pop시켜서나중에나온값(b) | 연산자(+,-,\*,/) | 먼저 나온값(a)식을 만들어 계산을하면된다. 그 계산결과는 stack에 push돼야한다.이
43.쇠막대기
여는괄호'(' 를 만나면 무조건 stack에 넣고,닫는괄호')' 를 만나면 바로 전 문자와 비교해,바로 전 문자가 '('면 레이저이므로 stack에서 한개를 pop하고 남은 stack의 size만큼 answer에 더해주면된다.바로 전 문자가 ')'면 쇠막대기의 끝부분이
44.공주 구하기(Queue)
FIFO(First-In, First-Out) 자료구조Queue< DataType > q = new LinkedList<>();로 선언할 수 있다.주요 method:1) .offer(x) : Queue안에 x값을 삽입.2) .poll() : 가장 맨 앞의 값
45.교육과정 설계

\++ for문 다른 방법필수과목을 순서대로 Queue에 넣어두고,foreach문을 통해 x가 Queue에 있고, 가장 앞의 알파벳이 x와 같다면,필수과목 + 순서도 맞기 때문에, Queue에서 poll()시킨다.만약 Queue가 모두 비워지게되면 모든 필수과목을 순서
46.기능개발(Queue)
기능개발전부 Queue에 넣은후, 맨 앞의 작업의 진도가 100이 될때까지 모든 작업에 speed를 추가해줬다.맨앞의 진도가 100이 되는순간, q에서 poll시키고 cnt가 1증가한다.그 뒤에 작업부터는 peek이 100을넘는다면 poll시키고 cnt를 1증가시킨다.
47.선택 정렬
선택정렬방법!idx = 인덱스2중 for문을 통해 idx에는 최솟값의 인덱스를 저장하고 for문이 다 끝나고나면 i값과 idx의 값을 교체시켜준다.i=0부터 탐색을 시작해서 j문을 통해 i번째값보다 더 작은 값이 있는지 확인.idx에는 최솟값의 위치를 담아서 i값과 i
48.* 응급실 (class생성) *

Person에 id와 priority를 인스턴스 변수로 선언하고,Person을 데이터타입으로 갖는 Queue에 id값과 우선순위를 넣었다.만약, poll한 값보다 우선순위가 더 높은 값이 Queue에 존재하면,그 값은 다시 Queue에 넣는다.그리고 현재값은 null로
49.버블 정렬
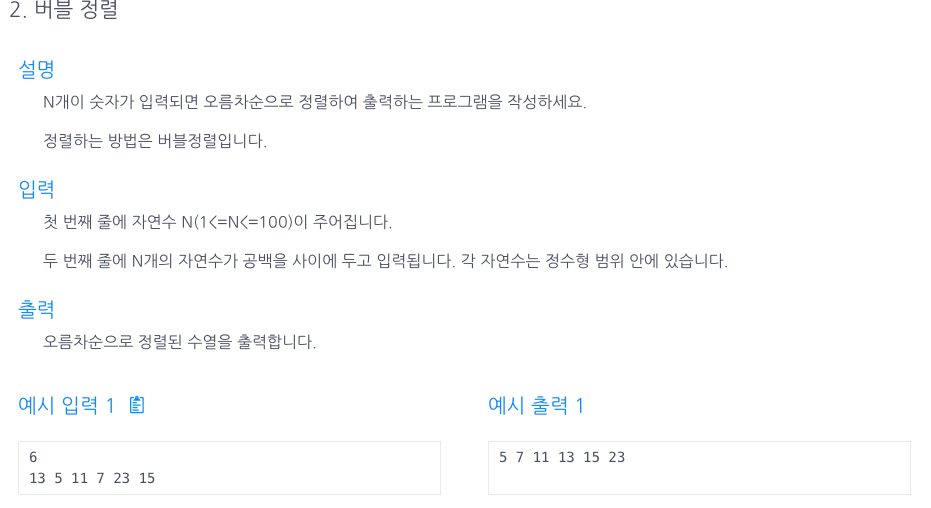
i문을 통해 젤 n번만큼 for문이 돌고,j문을 통해 0~n-1, 1~n-2, 2~n-3 ... 계속돈다.j문이 한바퀴 돌때마다 arr의 마지막값에는 arr에서 가장 큰 값이 담긴다.j문이 n번돌고나면 배열이 전부 탐색되고 오름차순으로 정렬이된다.뭔가 sliding w
50.삽입정렬
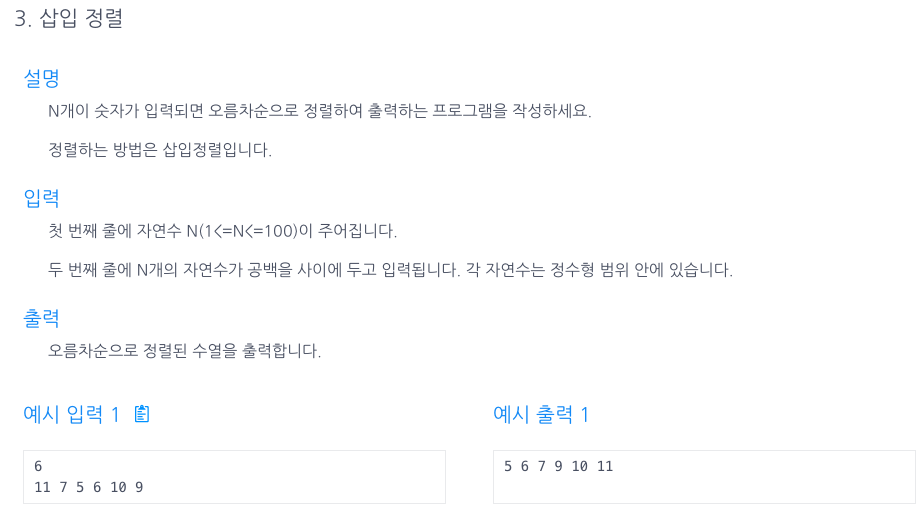
i번 바로 앞부터 탐색을 시작해서, 바로 전 값(j)이 tmp(i)보다 크다면 j가 j+1자리에 가고 tmp는 그 다음(j--)값과 비교하게된다.tmp가 자신보다 작은값을 만나면 그 즉시 break;되고 j+1번째가 tmp의 위치이므로 삽입한다.이때, j가 for문안에
51.Lease Recently Used(삽입정렬 활용)

arr에서 들어오는 값은 항상 cache의 맨 앞에 꽂힌다.만약 cache hit가 발생하면 해당값은 사라진다.hit가 발생하지 않는다면 모두 miss이므로 한 칸씩 다음칸으로 미뤄진다.스스로 풀지 못하고 강의를 듣고 풀었다...먼저, arr값을 순서대로 받을 fore
52.중복 확인 (정렬 사용)

\++ 정렬 사용1번 풀이:해쉬에 x값을 하나씩 추가해서 만약 이미 존재하는 key라면 "D"를 return 해줬다.2번 풀이:배열을 sort시켜 인접한 값중 같은값이 존재하면 "D"를 return 해줬다.중복을 확인할때, Hashmap을 활용하는 방법을 기억!!
53.장난꾸러기
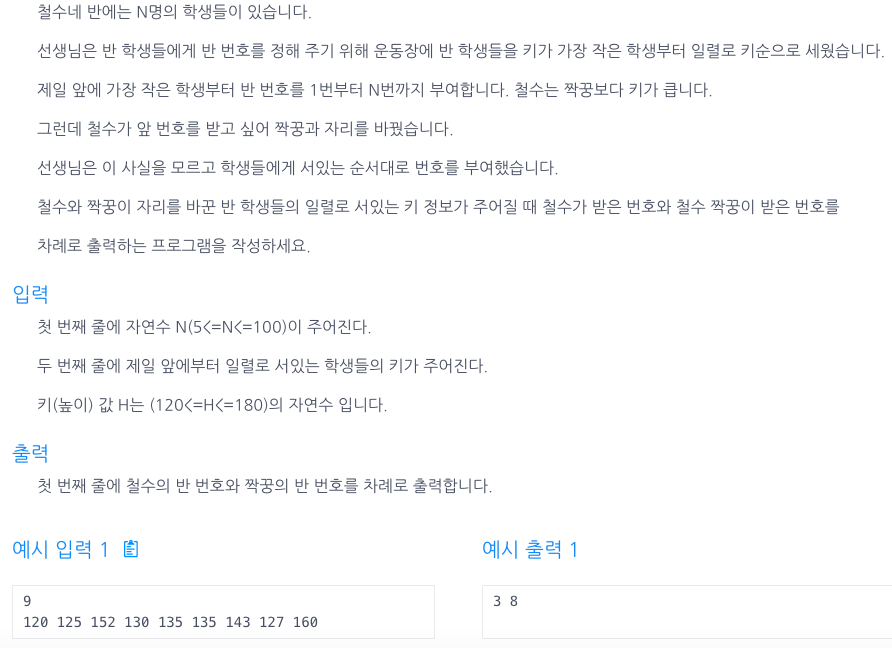
arr2에는 정렬된 배열을 담아서, arr과 arr2를 비교해서 값이 다른곳의 index 값을 answer에 +1시켜 담아주면 된다!arr이 변해도 값이 변하지 않는 배열을 복사하려면 clone을 이용하면된다!정렬을 이용하면 어려운 문제도 쉽게 풀리는경우가 있으니 문제
54.좌표 정렬(CompareTo)

CompareTo 메소드를 담고있는 Comparable을 implements해서 좌표정렬을 할 수있다!먼저 x,y값을 받을 class를 생성해준다.arr에 값을 모두 받고, compareTo 메소드를 통해this.x (비교값) == o.x(들어온값) 이라면 this.y
55.이분 검색
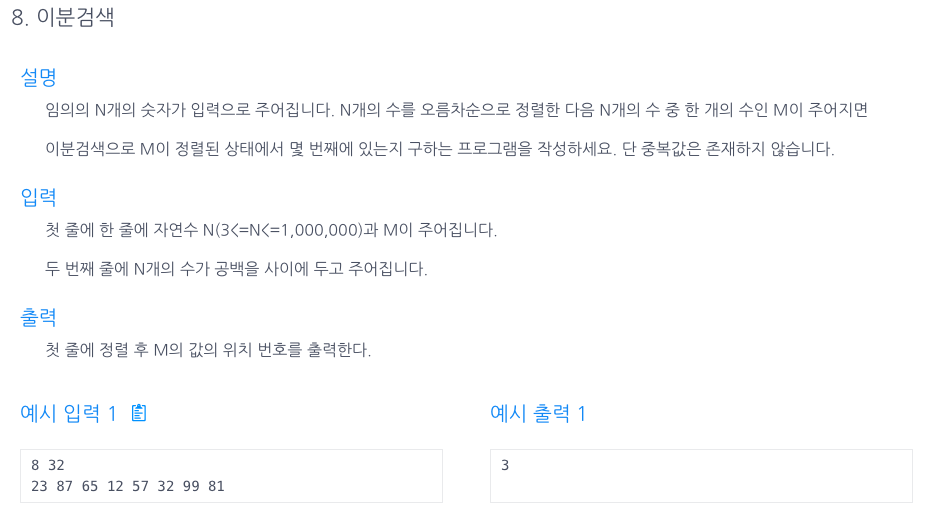
lt는 0 rt는 배열의 끝 index로 지정해두고 시작한다.mid는 배열의 중간지점 (lt+rt)/2.만약 mid가 m(타겟넘버)보다 크다면, mid~rt부분은 전부 제외시켜도 되므로rt= mid-1이 되고 다시 탐색을 시작한다.만약, mid가 m(타겟넘버)보다 작다
56.뮤직비디오(결정알고리즘)
더 좋은답을 향해서 계속 탐색Stream은 reduction을 도와주는 method이다.average,sum,max,min 등...Reduction : 큰 데이터를 가공해서 얻을수있는 정보를 일컫는말.Stream의 결과값이 int가 아니라면 getAsInt를 사용하여
57.뮤직비디오(결정알고리즘,이분탐색)

결정알고리즘은 가장 최선의 답을 찾기위해 계속 탐색을 하는 알고리즘을 뜻한다.lt(최솟값)를 9로 잡은 이유는, arr의 최댓값인 9분짜리의 곡을 cd에 담기위해선 최소 capacity가 9는 되어야하므로.rt(최댓값)를 45로 잡은 이유는, arr의 모든 원소를 더한
58.마구간 정하기(결정알고리즘)
문제 나의풀이 ++ Count함수 요약 풀이방법 전 문제와 비슷하듯 다른듯하다.. lt를 마구간 사이의 거리가 될 수 있는 최솟값인 1로두고, rt를 마구간 사이의 거리가 될 수 있는 arr의 젤 끝 원소로 지정해줬다. mid((lt+rt)/2) 값부터 탐색을 시
59.재귀함수 설명
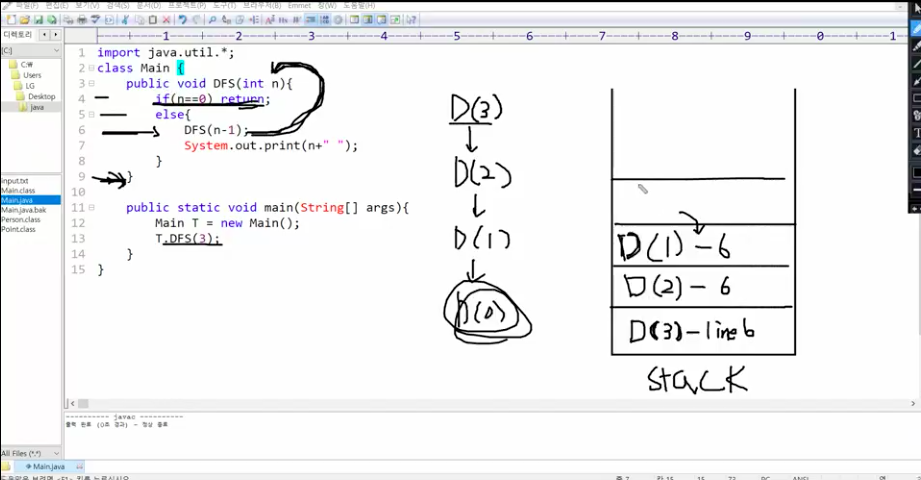
재귀함수는 Stack Frame을 사용한다.처음 DFS(3)이 돌면 line6에서 DFS(2)를 실행하는 함수를 만나서'DFS(3)은 line6까지 돌았다' 라는 값과 주소를 stack에 저장한다.DFS(2) 또한 line6에서 DFS(1)을 실행하는 함수를 만나서,D
60.이진수출력 (재귀)
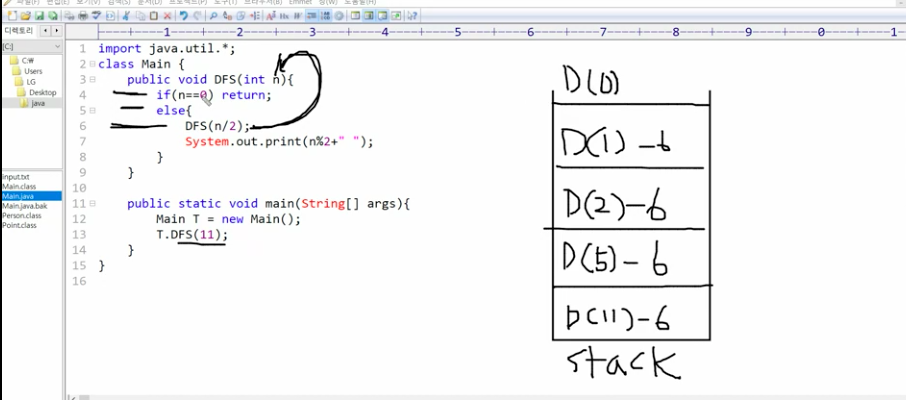
자연수 N의 이진수를 재귀 함수를 사용해 출력하기.자연수 N의 이진수는 N을 2로 나눠서 몫이 0이 되기까지의 나머지를 거꾸로 출력한 값이다.ex)11 나누기 2의 몫 = 5, 나머지 = 15 나누기 2의 몫 = 2, 나머지 = 12 나누기 2의 몫 = 1, 나머지 =
61.팩토리얼 (재귀)
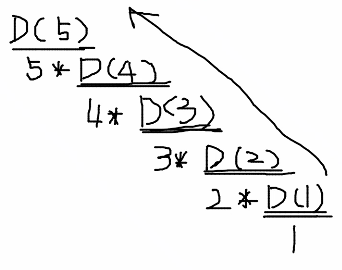
자연수 N의 팩토리얼값을 출력하기.ex) N=5 , answer = 120가장 마지막에 실행된 DFS(1)부터 차례대로 올라간다.DFS(1)은 1을 return하고 DFS(2)에 21이 담긴다.DFS(2)는 2를 return하고 DFS(3)에 23이 담긴다....DFS
62.피보나치수열(재귀,메모이제이션)
N항 까지의 피보나치 수열을 출력하기.\++ 메모이제이션 사용(시간단축)첫번째 풀이는 재귀를 통해 단순히 값을 출력하는 방법이다.하지만, 이렇게 단순히 재귀만을 하게되면 N값이 커졌을때, 모든 tree를 탐색해야하므로 시간이 오래걸린다.예를들어, DFS(45)는 DFS
63.이진트리순회(DFS-Depth First Search)
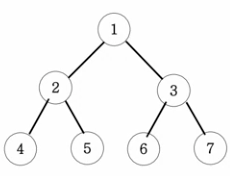
DFS-Depth First Search : 깊이 우선 탐색부모가 기준!전위순회 : 부모 - 왼쪽자식 - 오른쪽자식\--> 1 - 2 - 4 - 5 - 3 - 6 - 7중위순회 : 왼쪽자식 - 부모 - 오른쪽자식\--> 4 - 2 - 5 - 1 - 6 - 3 - 7후위