Apache Kafka의 기본구조
카프카는 발행-구독(publish-subscribe)모델을 기반으로 동작하며,
클러스터는 여러 브로커로 구성되어 있습니다. 각 브로커는 서로 연결되어 있고 한 브로커가 실패해도 다른 브로커가 그 역할을 대신해 고가용성을 보장합니다.
카프카는 크게 브로커, 컨슈머, 프로듀서 세가지 컴포넌트로 구성되어 있습니다.
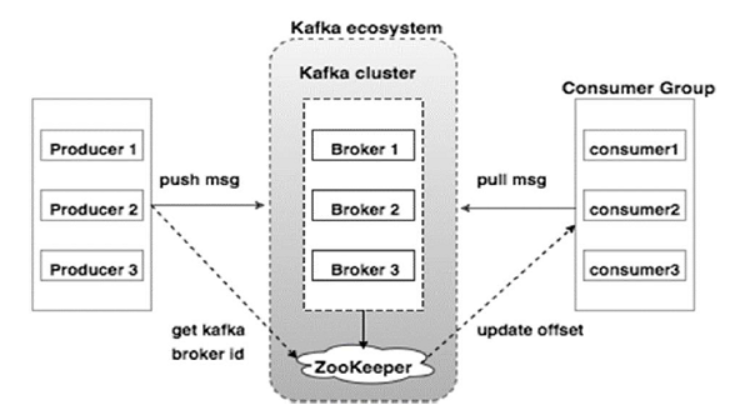
- 브로커: 카프카 클라이언트와 데이터를 주고 받기 위해 사용하는 주체입니다. 1대의 서버에는 하나의 브로커가 올라옴.
- 프로듀서: 카프카 브로커에 데이터(메세지)를 전송하는 어플리케이션
- 컨슈머: 브로커에 저장된 메세지를 읽어와 사용하는 어플리케이션
브로커의 특징과 역할
[특징]
- 각 브로커는 독립적으로 동작하고, 하나의 브로커가 실패해도 전체 클러스터에 큰 영향을 미치지 않는다.
- 한개의 클러스터는 여러개의 브로커로 이루어져 있다.
- 컨슈머가 데이터를 가져가도 토픽의 데이터는 삭제되지 않으며, 컨슈머나 프로듀서가 데이터삭제요청을 할 수 없다. 오직 브로커만이 데이터를 삭제 할 수 있다.
[역할]
- 복제 :브로커들은 토픽 내의 데이터(파티션 단위)를 서로 복제하며 리더 파티션은 읽기 및 쓰기를 담당하고, 팔로워 파티션은 리더의 데이터를 복제한다. 클러스터로 묶인 브로커 중 일부에 장애가 발생하더라도 데이터를 유실하지 않고 안전하게 사용하기 위해 복제한다.
- 컨슈머 오프셋 저장 : 컨슈머 그룹은 토픽이 특정 파티션으로부터 데이터를 가져가서 처리하고 이 파티션의 어느 레코드까지 가져갔는지 확인하기 위해 오프셋을 커밋한다. 커밋한 오프셋은 __consumer_ofsets 토픽에 저장하며 여기에 저장된 오프셋을 토대로 컨슈머 그룹은 다음 레코드를 가져가서 처리한다.
- 그룹 코디네이터: 코디네이터는 컨슈머 그룹의 상태를 체크하고 파티션을 컨슈머와 매칭되도록 분배한다. 컨슈머가 컨슈머 그룹에서 빠지면 매칭되지 않은 파티션을 정상 동작하는 컨슈머로 할당하여 끊임없이 데이터가 처리되도록 도와준다. 이렇게 파티션을 컨슈머로 재할당하는 과정을 리밸런스 라고한다.
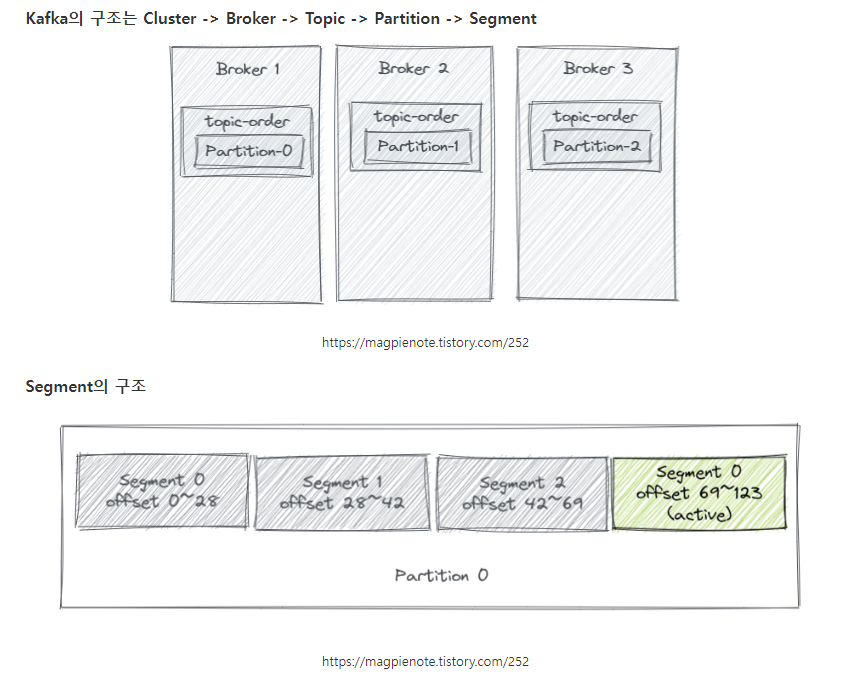
- 데이터의 저장: 카프카를 실행할 때 config/server.properties의 log.dir옵션에 정의한 디렉토리에 데이터를 저장한다. 토픽이름과 파티션번호의 조합으로 하위 디텍토리를 생성하여 데이터를 저장한다.(브로커에 데이터가 저장할때 메모리가 아닌 파일시스템에 저장됨)
- log에는 메시지와 메타데이터를 저장하며, index는 메시지의 오프셋을 인덱싱한 정보를 담은 파일이다. timeindex파일에는 메시지에 포함된 timestamp값을 기준으로 인덱싱한 정보가 담겨있다.

반갑습니다