Kafka
1.[Kafka] 카프카의 기본구조
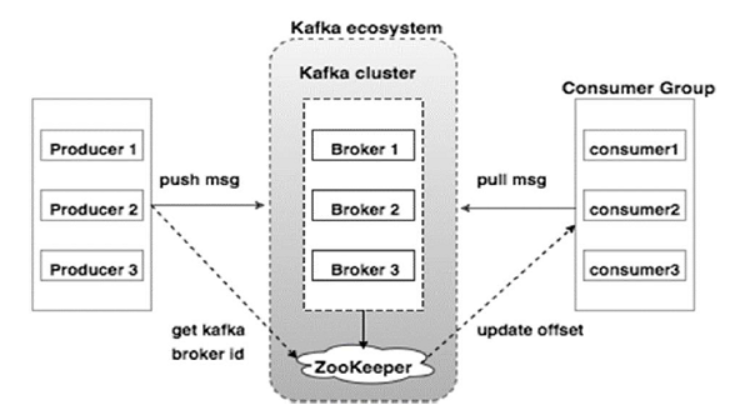
카프카는 발행-구독(publish-subscribe)모델을 기반으로 동작하며, 클러스터는 여러 브로커로 구성되어 있습니다. 각 브로커는 서로 연결되어 있고 한 브로커가 실패해도 다른 브로커가 그 역할을 대신해 고가용성을 보장합니다.카프카는 크게 브로커, 컨슈머, 프로듀
2024년 7월 16일
2.[Kafka] 카프카 로그와 세그먼트

로그와 세그먼트 카프카를 실행할 때 config/server.properties의 log.dir 옵션에 정의한 디렉토리에 데이터가 저장되고 토픽 이름과 파티션 번호의 조합으로 하위 디텍토리를 생성하여 데이터를 저장한다. 예를들어 hello.kafaka 라는 토픽이
2024년 7월 17일
3.[Kafka] 카프카 토픽,파티션,레코드의 특징
토픽이란? 토픽은 카프카에서 데이터를 구분하기위해 사용하는 단위입니다. 토픽은 1개 이상의 파티션을 소유합니다. 파티션의 특징 파티션에는 프로듀서가 보낸 데이터들이 저장되어있고 이 데이터를'레코드(record)'라고 부릅니다. 파티션의 자료구조는 큐(queue)와 비
2024년 7월 25일