1. RabbitMQ 컨테이너 띄우기
docker run -d --hostname my-rabbit --name some-rabbit -p 5672:5672 -p 15672:15672 rabbitmq:3-management-
여기서 포트를 두 개 열었는데
5672 포트는 RabbitMQ와 통신하기 위한 포트이고,
15672 포트는 모니터링 툴을 사용하기 위한 포트이다. -
로컬에 해당 이미지가 없어도 Docker hub에서 알아서 가져와 컨테이너를 만들어준다.
2. RabbitMQ 사용
2-1. 접속
-
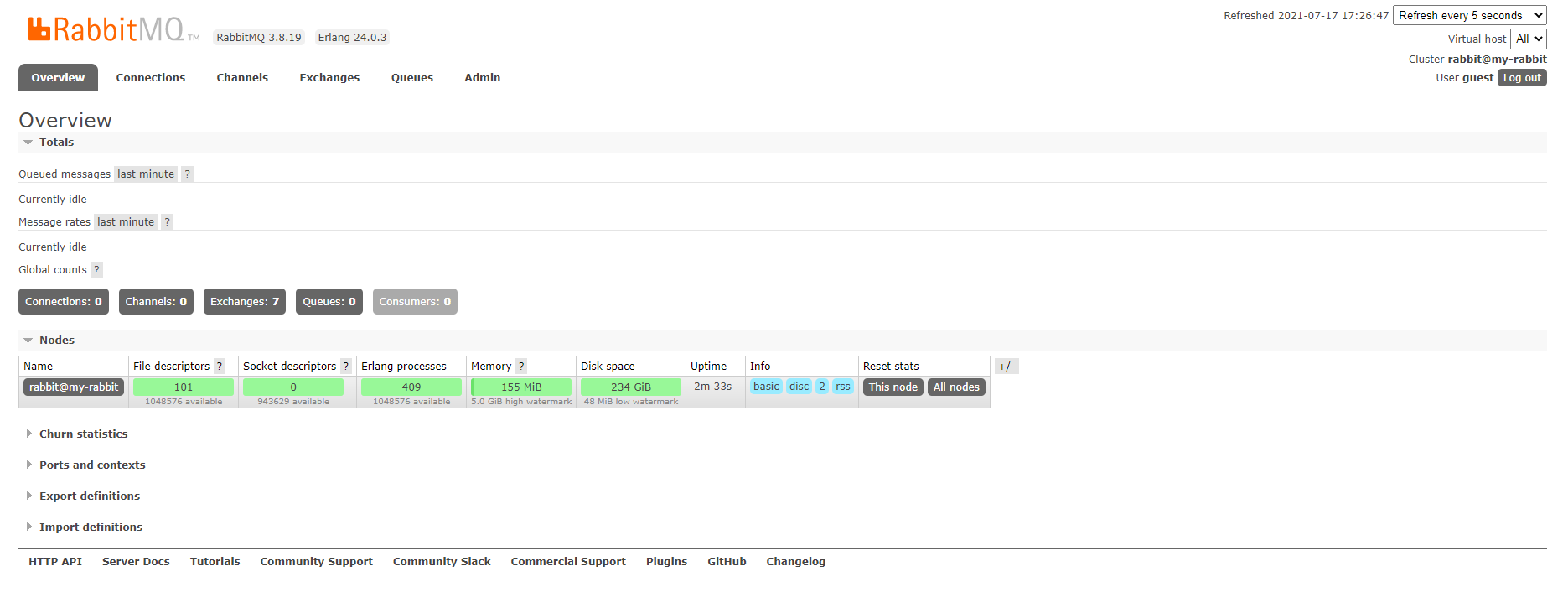
15672 포트로 접근하여 username : guest / pw : guest 로 로그인하면 위와 같은 모니터링 화면이 나온다.
-
원래는 Admin 계정을 생성해서 관리해야하지만, 현재는 실습을 위해 Guest 계정을 이용한다.
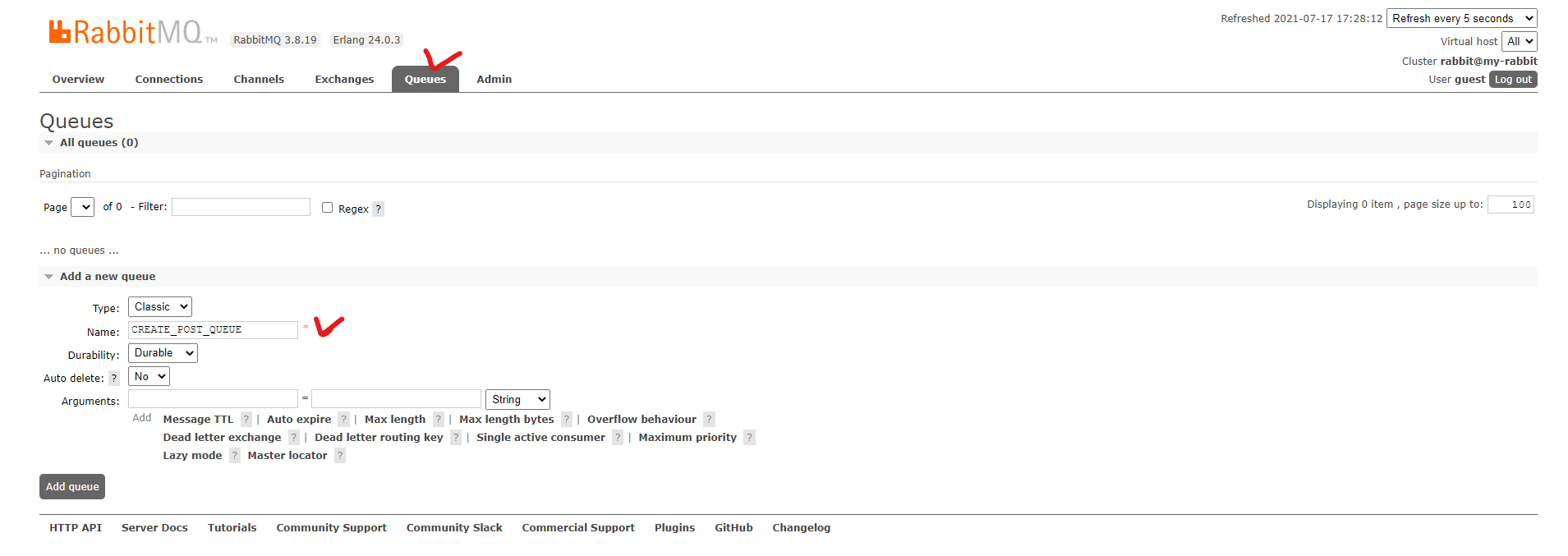
2-2. 새로운 큐 만들기
-
Queues 탭으로 이동해, 아래 Add a new queue 버튼을 클릭 하여 새로운 큐를 만들어준다.
-
나머지는 디폴트 설정을 그대로 가져가고 Name만 지정해준다.
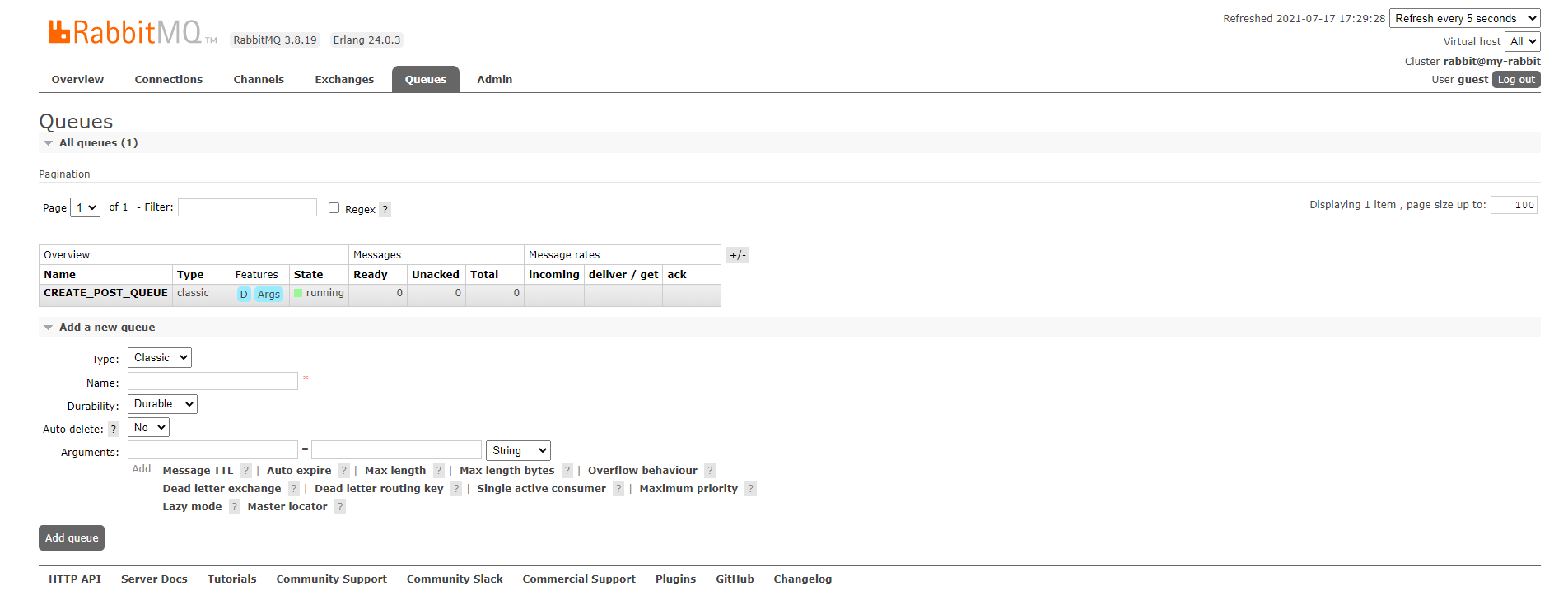
- 위와 같이 새로운 큐가 생긴걸 볼 수 있다.
2-3. 메시지 생성
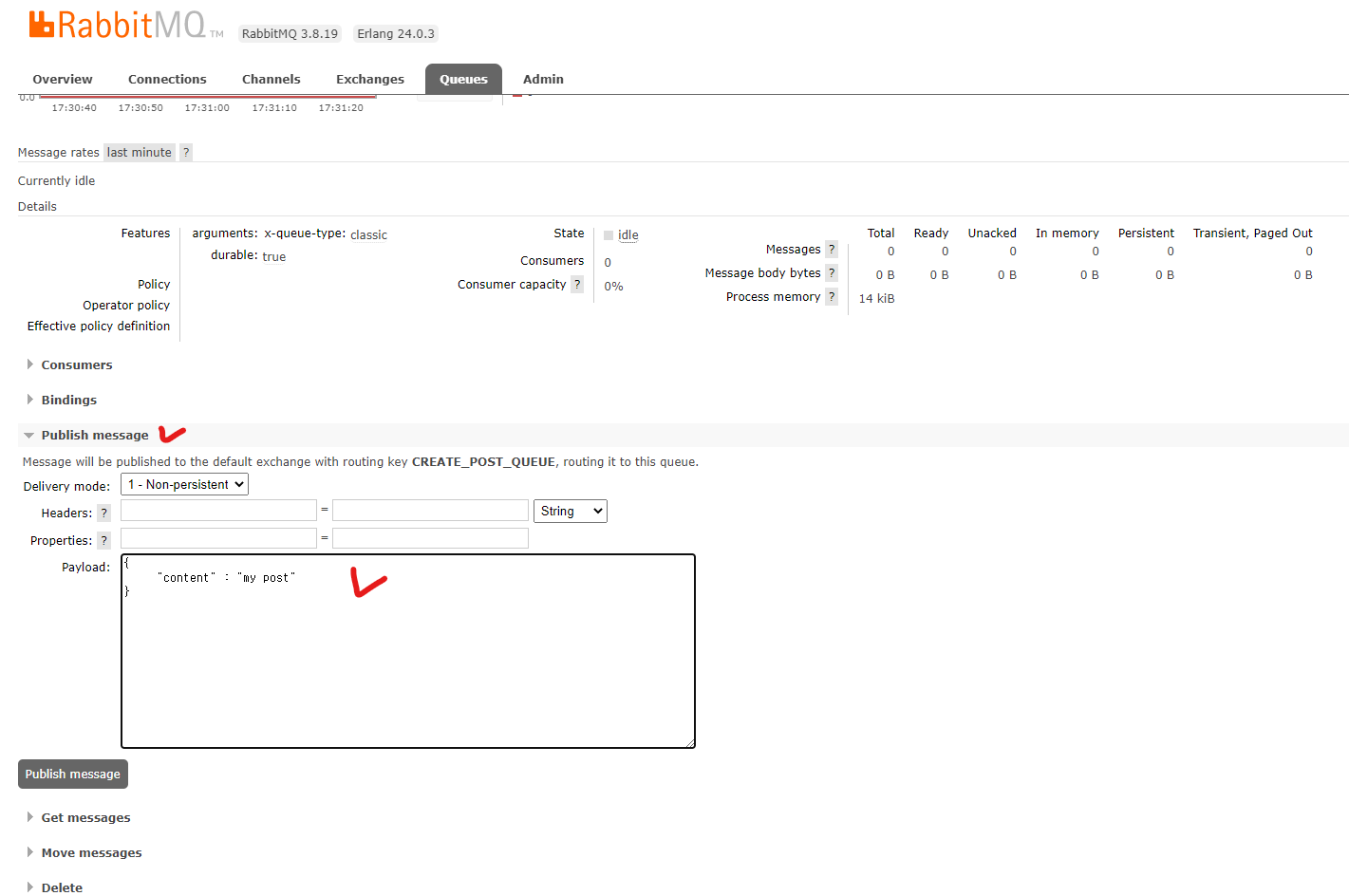
-
생성된 큐를 클릭해 들어오면 위와 같은 화면이 나오는데, 여기서 Publish message를 클릭해
메시지를 넣어보자. -
Payload에 값을 추가 후 Publish message 버튼을 누르자.
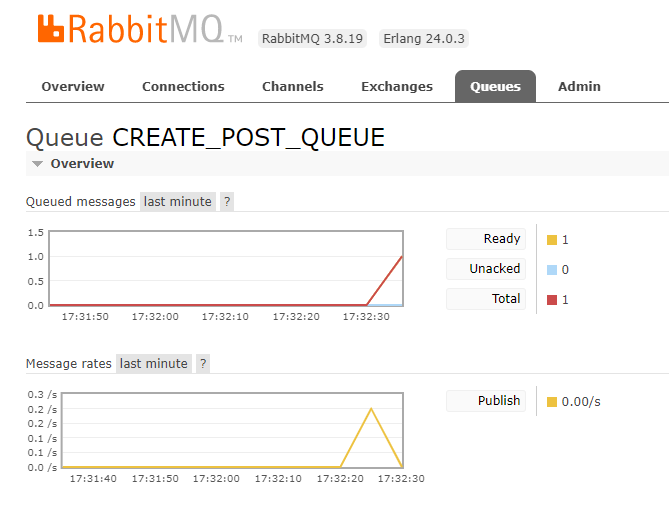
- 그러면 메시지가 생성된 걸 볼 수 있다.
2-4. 메시지 확인
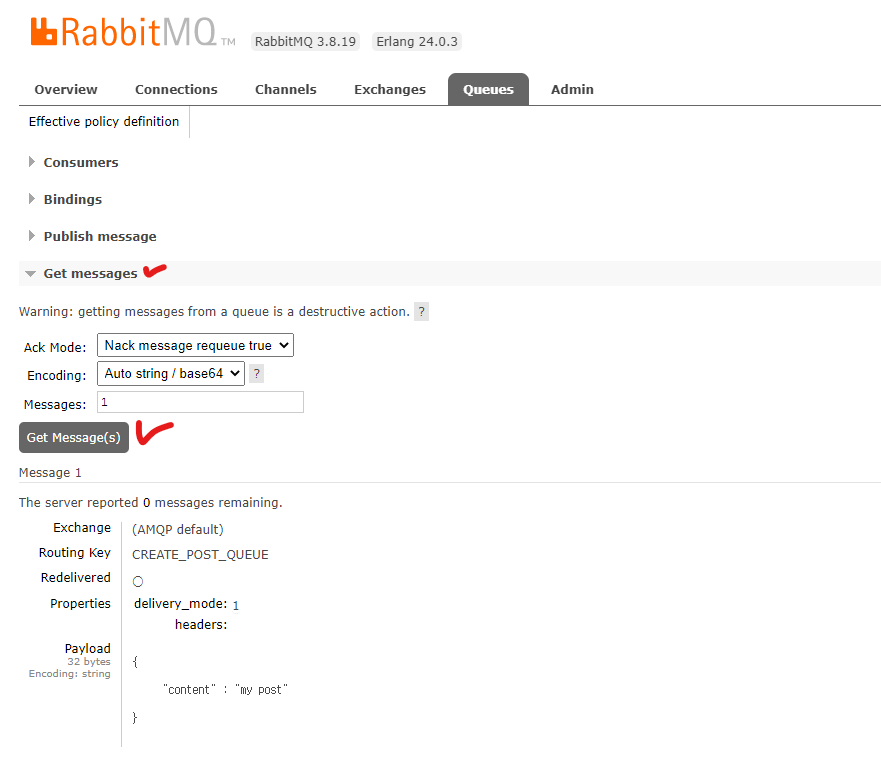
-
Get messages 항목에서 아까 넣은 메시지를 볼 수 있다.
-
Ack Mode를 Nack message requeue true로 하면 해당 메시지는 다시 큐로 들어간다.
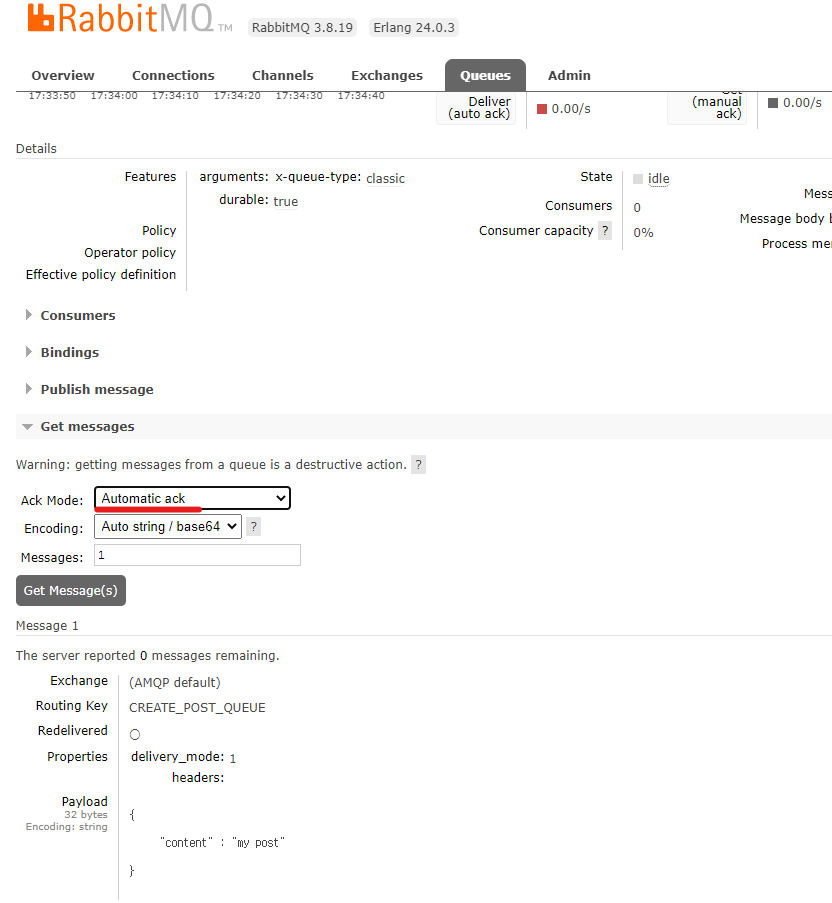
- Ack Mode를 Automatic ack로 변경하고 메시지를 꺼내면 다시 큐로 들어가지 않는다.
3. RabbitMQ 프로젝트에 적용
3-1. 의존성 추가
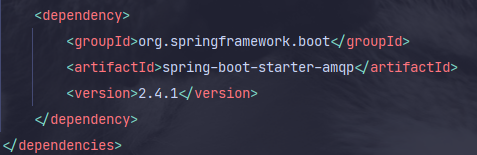
- Maven Repository에서 의존성을 코드를 가져온 후 maven 빌드 툴을 사용한다면
pom.xml에 추가해주면된다.
3-2. RabbitMQ 설정
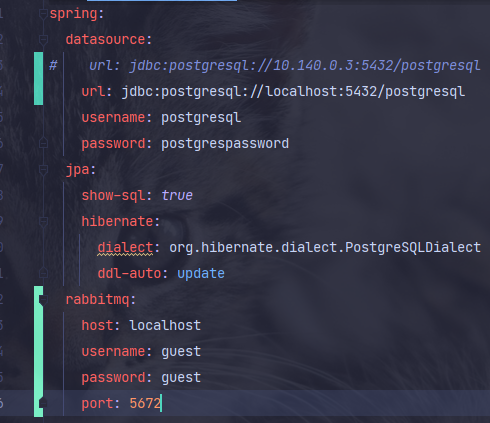
- 설정파일에 rabbitmq에 대한 정보들을 입력해 주자.
3-3. Producer 클래스 생성 후, 요청 메시지에 넣기
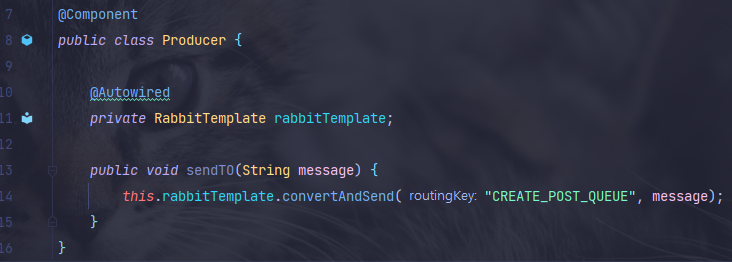
- Producer는 메시지를 큐에 집어넣는 역할을 수행한다.
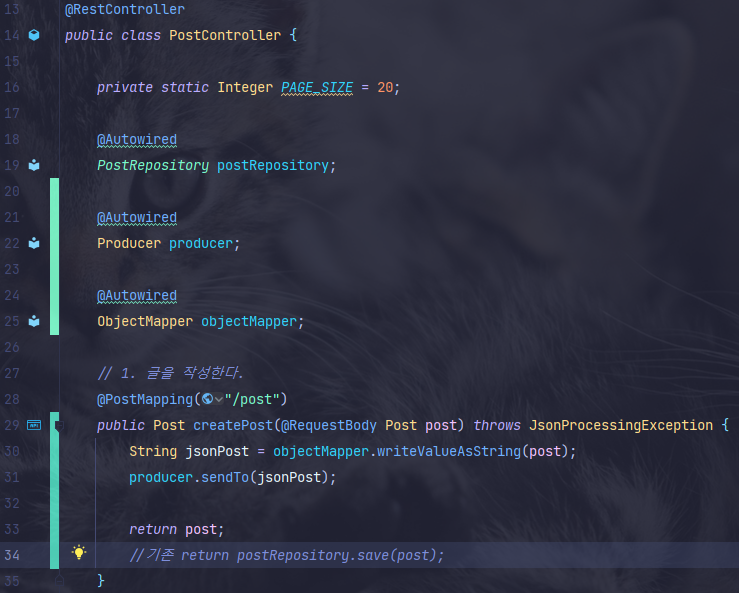
- Post 클래스로 요청을 받지만 메시지에 넣어줄 때는 String 형태로 넣어줘야 하기 때문에
ObjectMapper의 writeValueAsString() 메서드로 변환해서 넣어준다.
3-4. 테스트

- 애플리케이션을 실행시켜 테스트 하기 전에 PostgreSQL 컨테이너도 올라와 있어야 한다.
-
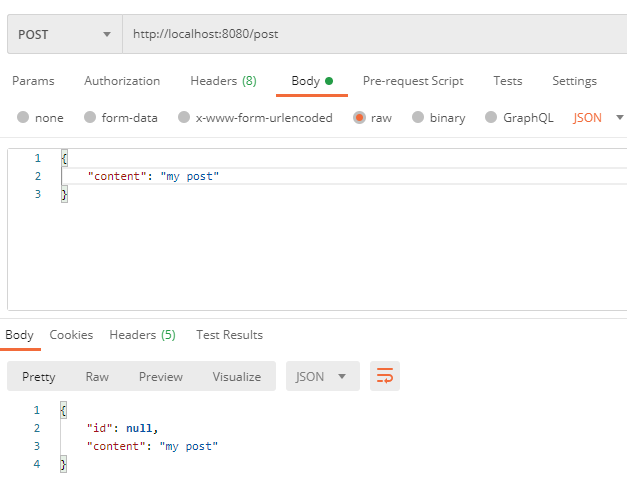
postman을 이용해 요청을 날려보면 정상적으로 응답이 오는걸 볼 수 있다.
-
id값은 따로 지정해주지 않았기 때문에 null이 나오는게 정상이다.
-
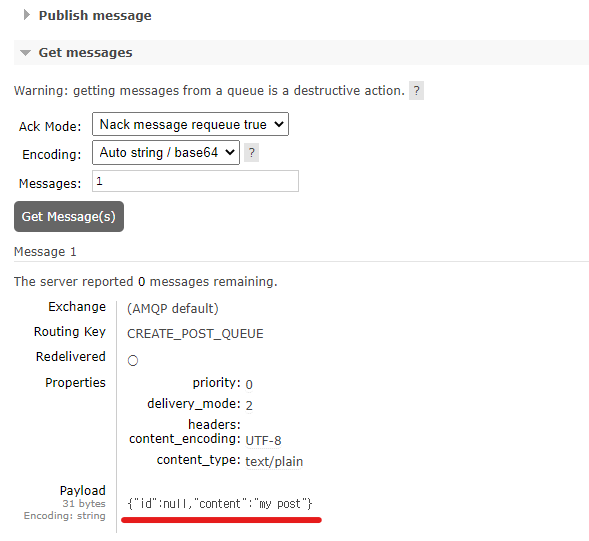
다시 RabbitMQ 모니터링 화면으로 돌아가서 메시지를 뽑아보면
방금 넣은 데이터를 볼 수 있다. -
이제 이 데이터를 Consume해서 DB에 넣어줘야 한다.
3-5. 메시지 뽑아서 DB에 값 넣기
-
이 과정을 Consume이라고 한다.
-
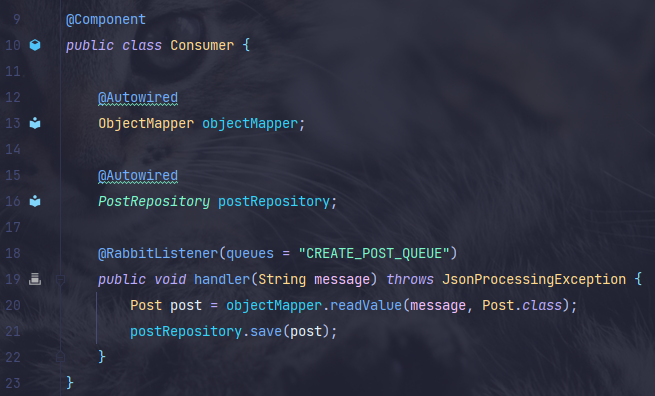
@RabbitListener 어노테이션을 이용한다.
queues 값으로 아까 생성한 큐의 이름을 매핑시켜주면 큐를 계속 컨슘하고 있는 상태가 된다.
즉 큐에 메시지가 들어오면 handler() 메서드가 호출된다. -
아까 큐에 메시지를 넣을 때 json 형태로 넣었기 때문에, 큐에서 메시지를 꺼내고 DB에 저장하기 위해서 다시 Post 클래스 형태로 변경해줘야 한다.
3-6. 테스트
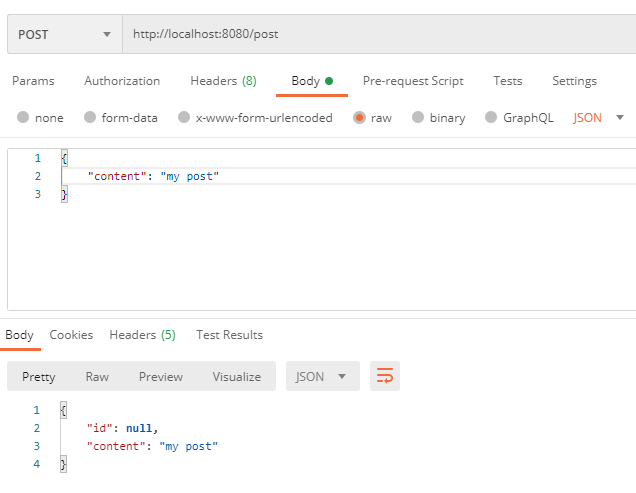
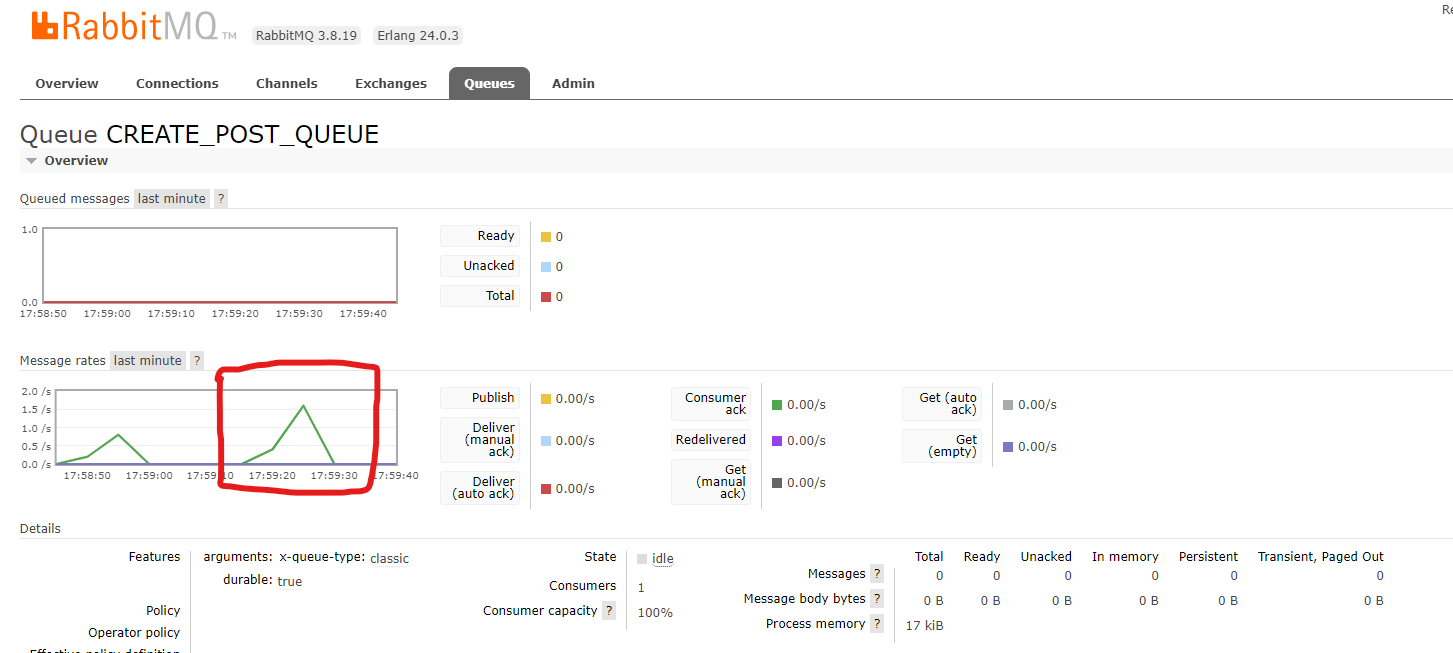
- 아까와 동일하게 postman으로 요청하고 모니터링 화면을 보면
메시지가 큐에 들어갔다가 빠져나오는 걸 볼 수 있다.
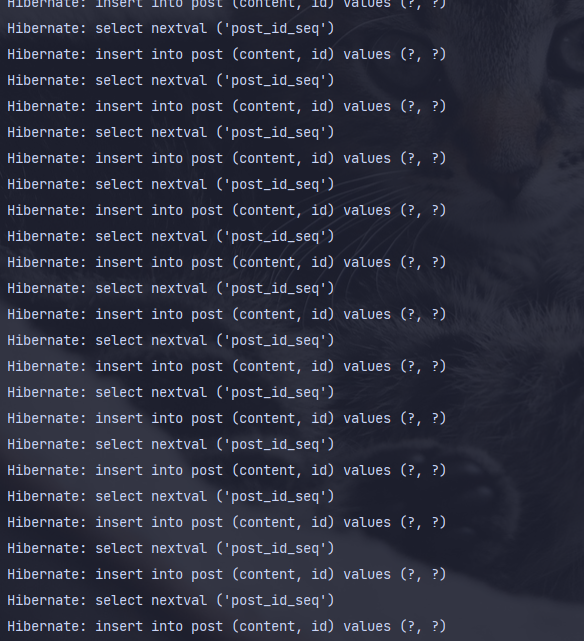
- 또한 하이버네이트가 찍어주는 로그에서도 볼 수 있다.
지금까지 로컬환경에서 RabbitMQ를 적용하고 테스트 해보았다.
다음은 배포 환경에서 동작시키기 위해 RabbitMQ 인스턴를 만들자.
4. RabbitMQ 인스턴스 만들기
- 현재 로컬에서는 RabbitMQ를 로컬에서 도커 컨테이너로 띄워서 사용했지만
GCP에 올라가있는 애플리케이션에 지금 만든 기능을 적용하려면 RabbitMQ 인스턴스가 필요함
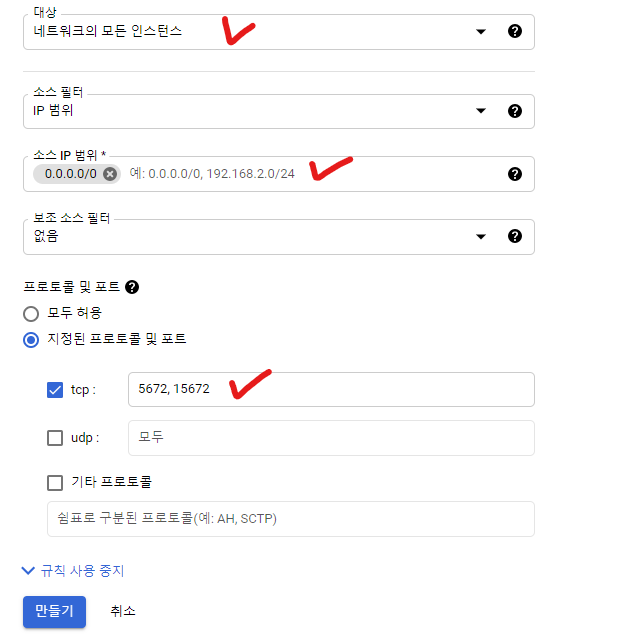
- 새 인스턴스를 생성해주고 5672, 15672 포트를 열어줘야 하기 때문에 방화벽에 규칙을 추가한다.
sudo yum -y install docker // docker 설치
sudo systemctl start docker // docker 실행
sudo chmod 666 /var/run/docker.sock // docker 실행 권한 부여
docker run -d --hostname my-rabbit --name some-rabbit -p 5672:5672 -p 15672:15672 rabbitmq:3-management // rabbitmq 컨테이너 생성 및 실행- 이후 인스턴스에 SSH로 접속하고
rabbitmq 인스턴스에 도커를 설치하고, rabbitmq 컨테이너를 띄운다.
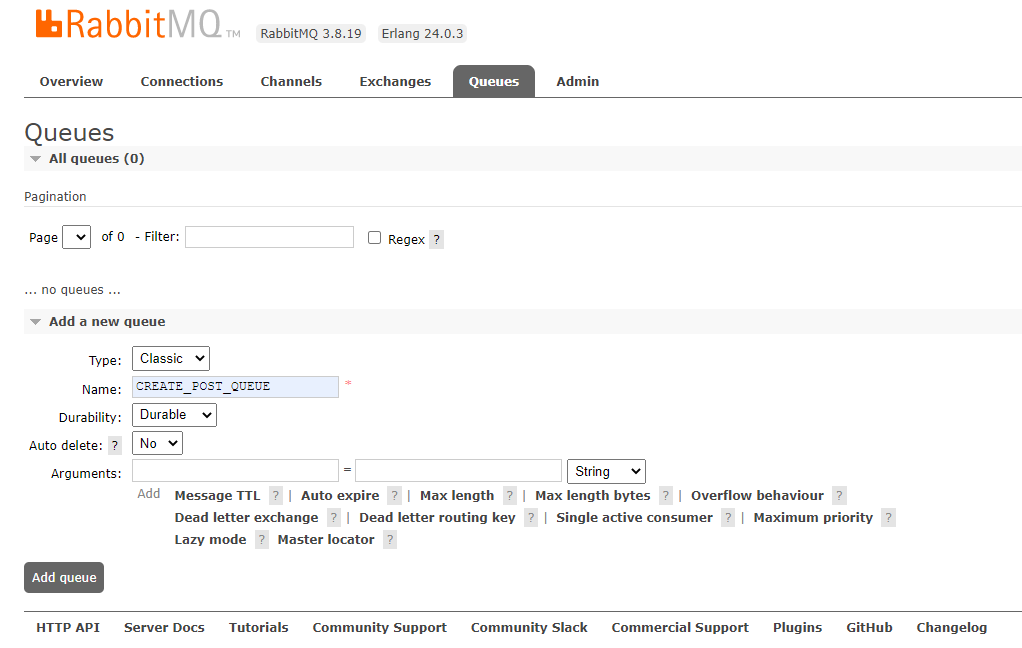
-
생성한 rabbitmq 인스턴스의 외부 ip로 접근해 로컬에서와 똑같이 Queue를 만들어준다.
-
이 때 Name은 이전과 동일하게 한다. 이미 애플리케이션 코드에 CREATE_POST_QUEUE 로 작성했기 때문이다. 물론 변경하고 싶으면 해도 된다.
인스턴스를 생성후, 해당 인스턴스에 RabbitMQ를 도커 컨테이너로 띄웠다.
이제 배포환경에서 동작시키기 위해 설정파일을 수정하고 원격지에 코드를 적용해보자.
5. 원격지에 코드 적용
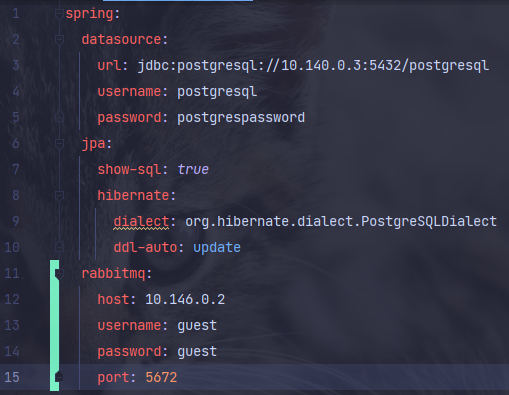
-
datasource의 url을 로컬에서, GCP postgresql 인스턴스의 ip로 변경한다.
-
rabbitmq의 설정을 적용한다. 각 워커 인스턴스들은 내부에서 붙기 때문에 host에 rabbitmq 인스턴스의 내부 ip를 적어주면 된다.
-
merge 하는 과정은 이전 글에 많이 했기 때문에 생략한다.
-
위와 같이 로컬과 origin에 있는 main, develop 모두 적용된 걸 볼수있다.
로컬에서 개발한 기능을 origin에도 적용했다.
이제는 글 목록을 캐싱하는 기능을 추가하고 배포해보자.
6. 캐싱 처리하기
-
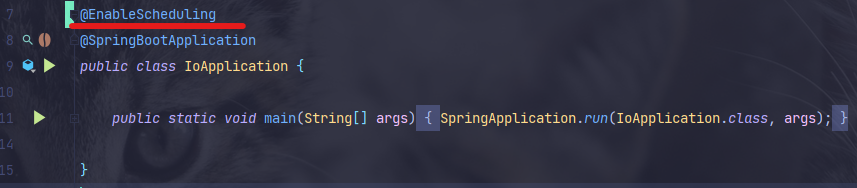
@EnableScheduling 어노테이션을 메인 클래스에 추가해야 한다.
-
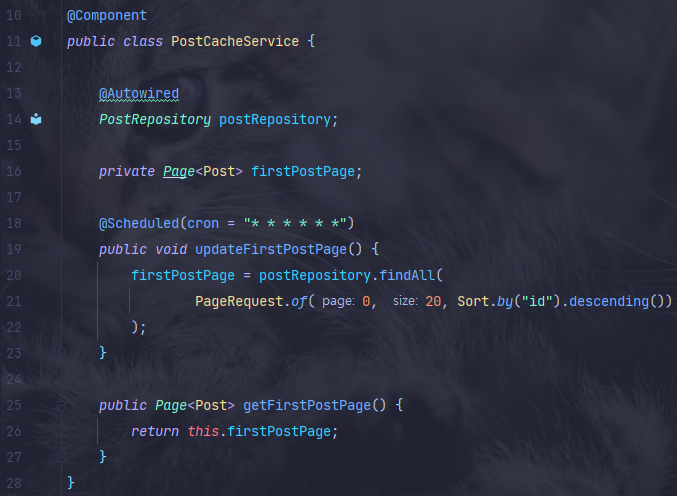
@Scheduled 어노테이션을 이용한다.
cron 표현식을 작성해주면 되는데 위에 작성한 cron표현식은 1초에 한번씩
updateFirstPostPage() 메서드가 실행된다. -
핵심만 간단히 보면 1초마다 첫 번째 페이지의 글 목록을 조회한 후 firstPostPage 필드에 저장하는 것이다.
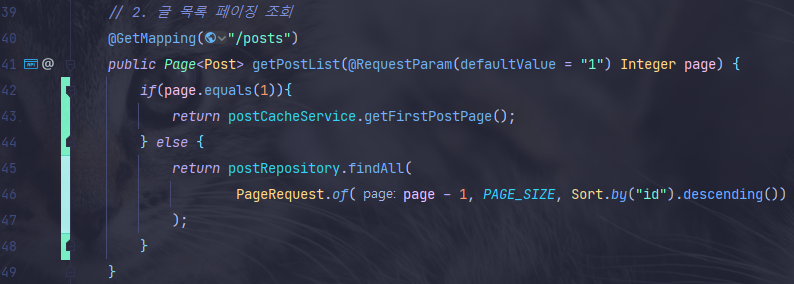
- 컨트롤러에서는 요청하는 페이지가 첫 페이지일때 캐시 서비스의 getFirstPostPage() 메서드를 호출하여 처리한다.
지금까지 첫 페이지를 조회하는 요청에대해 캐시처리를 했다.
이제 원격지에 코드 적용 후 jenkin로 배포하자.
7. 원격지에 코드 적용 후 배포하기
7-1. 원격지에 코드 적용
- 마찬가지로 과정은 설명한다.
7-2. Jenkins로 배포
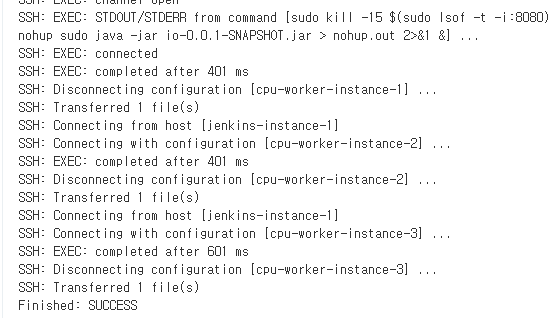
- 젠킨스에서 빌드하면 성공적으로 완료 된걸 볼 수 있다.
- postman으로 요청해서 테스트해보자.
7-3. 테스트
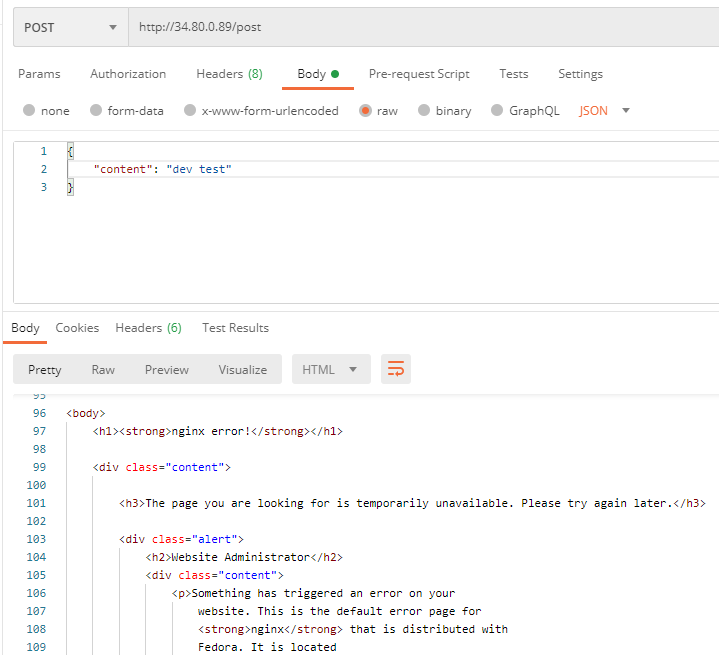
- 응답이 제대로 오지 않는다.
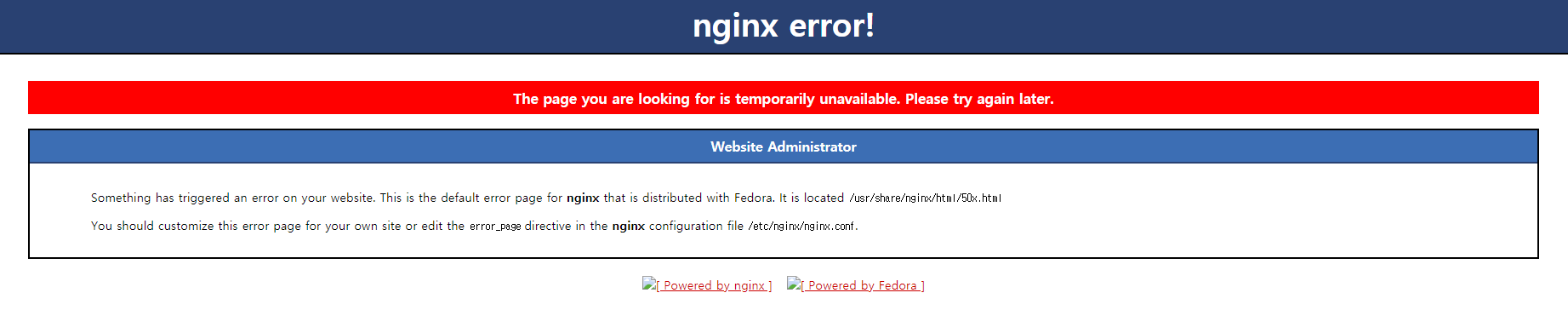
-
어제와 같은 현상이다. 배포를 다시 해보자..
-
배포해도 계속 같은 상황이다. 로컬에서 테스트해보면 정상적으로 동작한다.
—> 코드에 문제가 있는것은 아니다. -
그러던 도중 다시 Nginx로 요청 날려보니 갑자기 정상적으로 동작한다.
그냥 각 워커 인스턴스에 배포하고 애플리케이션이 실행되는데 시간이 좀 걸리나보다.
앞으로는 조금 기다려보자..
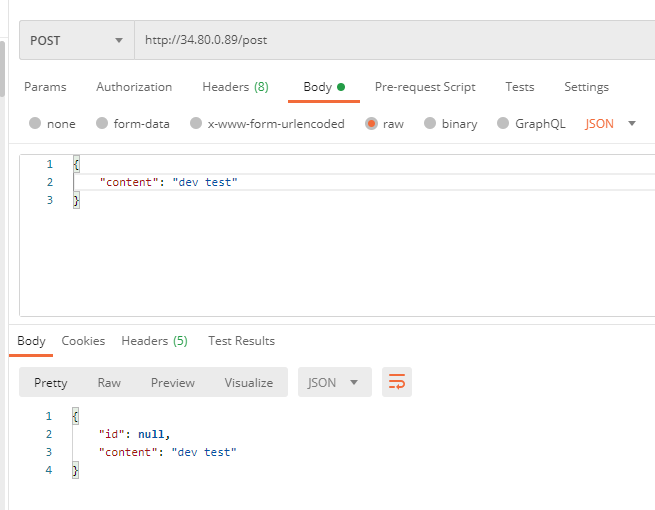
- Nginx 외부 ip 주소로 요청을 날려보면 정상적으로 응답이 오는걸 볼 수 있다.
- rabbitmq 인스턴스의 외부ip로 접근하고, 15672 포트로 접속해 모니터링 화면을 보면
메시지가 들어왔다가 빠져나가는 그래프를 볼 수 있다.
8. 마무리
-
지금까지 io bound 애플리케이션에 RabbitMQ를 적용해 보았다.
-
다음에는 스트레스 테스트를 진행해 적용 전과 후의 차이점을 비교해보자.
Etc)
1. Producer, Consumer 애플리케이션 분리
위에서 RabbitMQ를 적용했을 때는 Producer와 Consumer가 한 애플리케이션에 존재하게 된다.
하지만 실무에서는 Producer 애플리케이션과 Consumer 애플리케이션을 분리해서 사용하는게좋다.
아래 처럼 말이다.
사용자 ↔ Producer ↔ RabbitMQ ↔ Consumer
분리 되지 않았을 때와 분리 되었을 때의 가장 큰 차이점은 Consumer 애플리케이션을 배포할 때 얼마나 까다롭냐이다. 분리된 형태에서는 Consumer를 배포할 때 앞쪽에 RabbitMQ가 존재하기 때문에 모든 Consumer 가 종료되어도 문제 없다.
하지만 분리되지 않은 형태의 경우 Consumer 기능을 배포하기 위해 애플리케이션을 배포할 때 무중단 배포를 위한 요소들이 고려되어야 한다.
2. Redis
캐싱 처리는 위 처럼 애플리케이션 내부에서 구현하는 것 보다 주로 Redis를 이용하는게 더 효율적이다.
3. MQ 적용 시 요청 처리 시간 감소?
현재는, 애플리케이션 서버(Producer, Consumer) ↔ MQ 서버 ↔ DB 서버 와 같은 구조이다.
MQ서버를 적용하기 전에는, 애플리케이션 ↔ DB 서버 와 같은 구조이다.
그러면 중간에 MQ서버와 통신하기 위한 네트워크 I/O가 늘어나는데 성능에 문제가 없을까?
우리가 MQ를 도입한 이유에 대해서 다시한번 생각해보아야 한다. 이전 글에서 말했듯이 어떠한 이유가 됬든 사용자가 보낸 요청을 처리하지 못하여 요청이 유실되는 경우를 방지 할 수 있다.
즉 요청 하나를 처리하는 시간 자체가 빨라진다기 보다는 더 많은 요청이 들어 왔을 때 유실 없이 처리 가능하다.
4. 어떤 상황에 Message Queue를 도입해야 하는가?
주로 비동기적인 작업을 처리할 때 좋다. 즉 사용자가 요청했지만 응답을 받을 필요가 없거나
즉시 받을 필요가 없는 경우에 해당된다.
클라이언트가 응답을 받을 필요가 없는 경우 : 여러 서버에서 발생한 로그를 쌓는 작업 → 로그를 정상적으로 발송했고, MQ에 넣었다면 그게 어떤 곳에 저장되는지, 저장이 잘 되었는지 클라이언트는 알 필요가 없다.
5. MQ가 하나이고 Consumer가 여러개인 경우 경쟁상태가 발생하는가?
일단 하나의 메시지를 두 개의 Consumer가 동시에 Consume 하는 경우는 발생하지 않는다.
내부적으로 그렇게 구현되어 있다. 결과적으로 경쟁상태는 발생하지 않는다.
6. 메시지를 Consume 하는 주체는 애플리케이션이다.
-
애플리케이션은 MQ에서 일정 개수 만큼 Consume 한다.(디폴트 설정은 250개)
-
애플리케이션은 Consume한 메시지를 들고있고 DB에 insert 한다.
-
메시지 하나를 insert하면 다음 메시지를 Consume 한다.
위 과정이 반복된다.
결과적으로 애플리케이션이 메시지를 Consume 하고 싶을때 한다. DB에 insert하는 속도가 느리다면 애플리케이션은 Consume을 느리게 할 것이다.
MQ가 애플리케이션에게 강제로 메시지를 보내지 않는다.
오해하지 말자 애플리케이션이 주체이다.
