Github Pages
- Github에서 제공하는 온라인 호스팅 서비스
- 정적 웹 페이지 : 실시간으로 변경되는 내용없이 HTML, CSS, JavaScript 등으로 이루어진 단순한 웹 페이지
- Repository 생성
- 코드 파일 업로드
- main Branch로 설정
- 주소 생성
➡️ https://zomeong.github.io/Spartaflix/
URL
- 프로토콜(protocol) : 웹 브라우저와 웹 서버 간의 통신 방식 지정, http://가 가장 일반적
- 도메인(domain) : 인터넷 상에서 고유한 식별자로 사용되는 웹 사이트 주소, 일반적으로 사이트의 이름과 최상위 도메인(ex .com, .org)으로 구성
- 경로(path) : 웹 사이트 내에서 특정 페이지나 파일의 위치 지정
파이썬 스크래핑 (맛보기)
다음 영화 페이지에서 특정한 정보 가져오기
스크래핑 기본 세팅
import requests
from bs4 import BeautifulSoup
URL = "URL";
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get(URL, headers=headers)
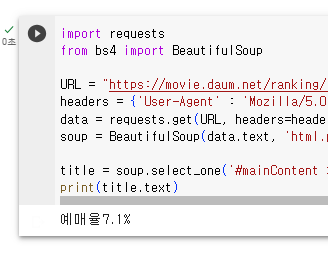
soup = BeautifulSoup(data.text, 'html.parser')특정 영화의 예매율 가져오기
1. 개발자 도구에서 예매율에 해당하는 데이터 뼈대 Copy Selector로 복사
2. soup.select_one()안에 셀렉터 값 입력

selector 사용 방법
# 선택자를 사용하는 방법 (copy selector)
soup.select('태그명')
soup.select('.클래스명')
soup.select('#아이디명')
soup.select('상위태그명 > 하위태그명 > 하위태그명')
soup.select('상위태그명.클래스명 > 하위태그명.클래스명')
# 태그와 속성값으로 찾는 방법
soup.select('태그명[속성="값"]')
# 한 개만 가져오고 싶은 경우
soup.select_one('위와 동일')
Server Developer