
검색 API
FastAPI와 MongoDB를 활용한 영어 문자열 검색 API를 구현하기 위해 정규표현식을 사용하였다. 문자열 검색의 경우 완전히 일치하는 결과뿐만이 아니라 해당 문자열이 포함되는 결과도 같이 출력해야 하기 때문이다.
regex_pattern = fr"\b{re.escape(input_mark)}\b"
query = {"wordmark":{"$regex": regex_pattern, "$options": "i"}}사용자가 입력한 문자열(input_mark)를 포함한 결과를 대소문자 구별 없이 찾아올 수 있도록 쿼리를 작성했다. 그런데 여기서 검색 속도가 굉장히 느려지는 문제가 발생했다. 이전의 검색 API는 시리얼넘버, 등록넘버 등이 완전히 일치하는 검색 결과만을 리턴했기 때문에 페이지네이션과 DB 인덱싱만으로도 충분히 빠른 속도를 보였다. 그러나 문자열의 일부분이 일치하는 검색 결과에 대해서는 10초 이상이 소요되는 것이다.

예를 들어 약 1200만건이 저장된 MongoDB의 컬렉션에서 이름에 "mandel"이 들어가는 데이터를 검색했을 때, 37건을 조회해오는데 26초가 걸렸다.
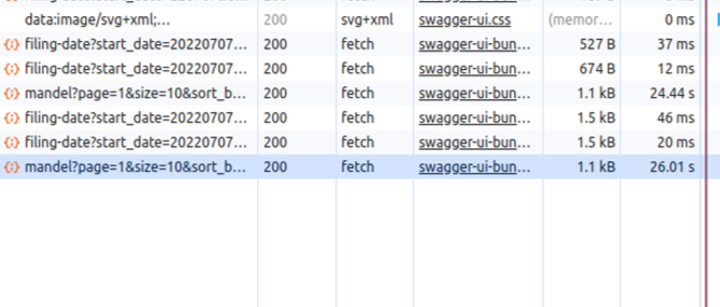
참고로 해당 필드에 대해 인덱스가 없을 땐 2분이 넘게 걸렸다.
⚠️ 일반 (B-Tree) 인덱스가 아닌 텍스트 인덱스를 사용하는 방법도 존재한다. 텍스트 인덱스는 텍스트 검색에 대해 최적화된 속도와 결과를 제공하지만 완전히 일치하는 결과만 출력한다. 즉 "나이키"를 검색하면 "나이키 가방", "나이키 신발"과 같은 결과는 나오지 않는다는 뜻이다. 텍스트 인덱스는 API의 요구사항에 맞지 않으므로 적용시키지 않았다.
Elastic Search
정규식과 인덱스의 적용 이후 MongoDB에서 검색 속도를 더 줄이기에는 한계가 있다. 그래서 이 시점에 검색 성능 개선을 위한 검색 엔진으로 Elastic Search를 적용하였다.
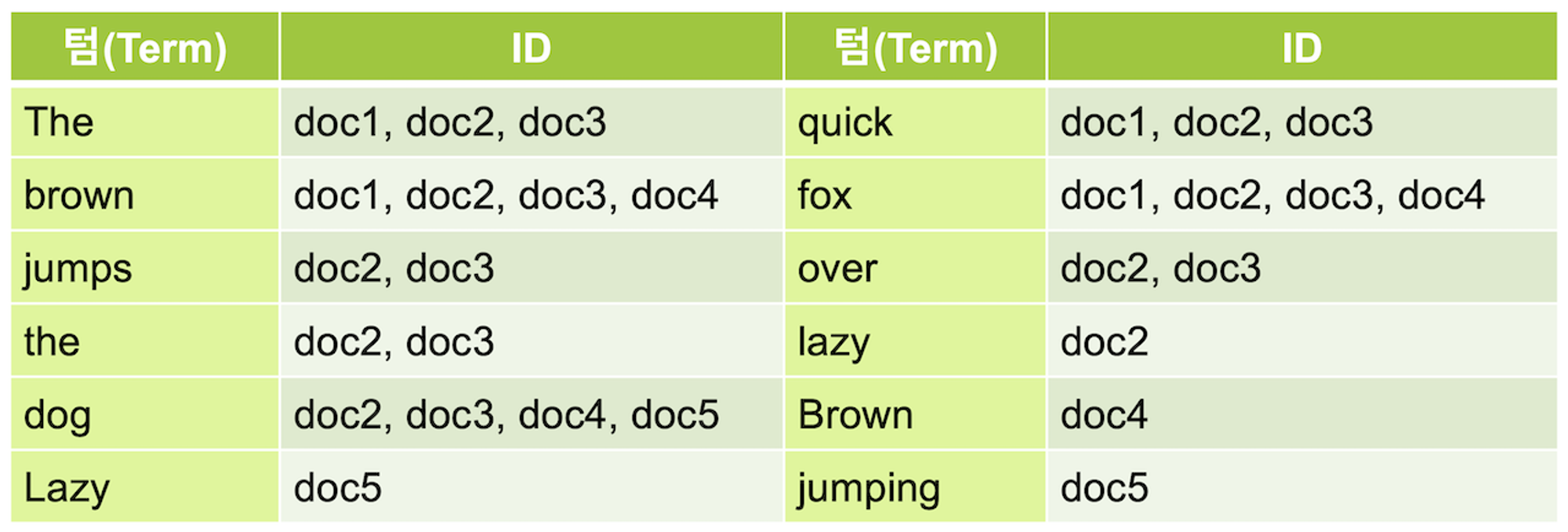
Elastic Search는 가장 인기 있는 오픈 소스 검색 엔진으로 뛰어난 검색 능력과 대규모 분산 시스템을 구축할 수 있는 다양한 기능들을 제공한다. 문서에서 추출된 각각의 키워드(텀 term)와 그 키워드를 가지고 있는 문서 id를 저장해둔 구조인 역 인덱스 구조를 통해 특정 키워드를 가지고 있는 데이터를 빠르게 조회할 수 있다.
검색엔진으로 Elastic Search를 사용하기 위해 일단 현재 MongoDB에 있는 데이터 중 특정 필드만 복사해서 넣어주었다. 이 때 필요한 필드만을 복사할지 문서 전체를 복사할지는 시스템에 따라 개발자가 선택하면 되겠지만 ES를 메인 DB로 사용하는 것은 권장되지 않는다고 한다. 아무튼 도커를 통한 ES, MongoDB와의 연결 설정 등 Setting에 대한 내용은 다른 글에서 다루도록 하자.
검색
FastAPI에서 검색 API 로직을 수정하였다.
- 문서 전체를 복사해서 쿼리를 ES로만 날리는 경우
es = Elasticsearch(["http://elasticsearch:9200"])
def search_by_mark(mark:str, page:int, size:int, sort_by:str, sort_order:str):
query = {
"query": {
"match": {
"field_name": {
"query": input
}
}
},
"sort": {sort_by: sort_order},
"from": (page - 1) * size,
"size": size,
"_source" : [ "serial-number", (...)]
}
return es.search(index="index_name", body=query)Elastic Search에 연결 설정을 해주고 쿼리를 ES로 날려서 결과를 바로 리턴한다.
- 특정 필드만 복사해서 DB로 쿼리를 한 번 더 날리는 경우
def search_by_mark(mark:str, page:int, size:int, sort_by:str, sort_order:str):
query = {
"query": {
"match": {
"field_name": {
"query": input
}
}
},
"sort": {sort_by: sort_order},
"from": (page - 1) * size,
"size": size,
"_source" : ["serial_number"]
}
response = es.search(index="index_name", body=query)
total_count = response['hits']['total']['value']
serial_numbers = [hit["_source"]["serial_number"] for hit in response["hits"]["hits"]]
docs = get_data_from_db(serial_numbers)
return {
"page": page,
"size": size,
"total_results": total_count,
"total_pages": (total_count + size - 1) // size,
"data": docs
}
def get_data_from_db(serial_numbers):
projection = {
"serial-number": 1,
(....)
"_id": 0
}
return list(collection.find({"serial-number": {"$in": serial_numbers}}, projection))
나는 ES에 serial-number와 wordmark 필드만 복사해두었다. ES에서 이름으로 검색된 결과들의 serial-number를 리스트로 반환하도록 하는 메서드와, 추가로 필요한 필드를 MongoDB에서 가져올 수 있도록 하는 메서드를 선언해준다.
성능 개선 결과

위의 약 1200만건이 저장된 MongoDB의 컬렉션에서 이름에 "mandel"가 들어가는 데이터를 검색했을 때, 35건을 조회해오는 예시를 똑같이 실행하였을 때 26초에서 6ms(0.006초)로 확실하게 개선되었다.

그렇지만 쿼리를 ES로 한 번만 날리되 데이터를 전부 복사해두어야 한다는 번거로움이 있는 1번 방법과 쿼리를 두 번 날리지만 ES에는 최소한의 데이터만 담아둘 수 있는 2번 방법 중에 어느 것이 더 나은 방법인지 서비스의 규모를 고려하지 않고 단정할 수는 없을 듯 하다. 일단 우리 서비스에서는 두가지 방법이 속도의 차이를 크게 보이지는 않았다.
정렬
Elastic Search에서 데이터를 검색하여 리턴해올 때 특정 필드로 정렬을 하고 싶은데 해당 필드가 text 타입일 경우 오류가 발생한다. 정렬 필드는 keyword 또는 numeric 타입이어야 한다. 만약 정렬 기준이 없다면 검색어와 일치하는 정도를 score로 매겨서 자동으로 정확도순으로 정렬해준다.
특정한 text 타입 필드를 정렬 기준으로 사용하기 위해서는 keyword 타입으로 서브 필드를 추가해주면 된다. text 타입은 fields 속성을 통해 여러 서브 필드를 정의할 수 있으며 보통 text 타입은 검색에 사용, keyword 타입은 정렬과 집계에 사용된다.
PUT /index_name {
"properties": {
"field_name": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword"
}
}
}
}이후 정렬 기준 파라미터에 서브 타입 필드를 명시적으로 지정해주면 field.keyword 해당 기준으로 정렬이 가능하다.
Total Result
Elastic Search는 기본적으로 한 번에 가져오는 데이터의 개수가 10,000개로 제한되어 있다. 그렇지만 이 제한은 정확한 결과값을 얻기 힘들게 한다. 뿐만 아니라 전체 검색 결과 값이 얼마인지도 알기 어렵다. 페이지네이션이 적용되어 있다면 이미 데이터 개수에 대한 처리를 한 것이므로 제한을 해제하여 정확한 결과를 얻을 수 있도록 하자.
 EX) “personal computer”라고 검색했을 때 total result가 10,000개로 딱 떨어져서 나온다.
EX) “personal computer”라고 검색했을 때 total result가 10,000개로 딱 떨어져서 나온다.
해제하는 방법은 간단하다. ES에 보내는 쿼리의 "track_total_hits" 옵션을 true로 설정하면 된다. 이 옵션은 전체 결과 수를 추적하도록 한다.
query = {
(...)
"track_total_hits": True
} EX) “personal computer”라고 똑같이 검색했는데 total result가 17,164개로 나온다.
EX) “personal computer”라고 똑같이 검색했는데 total result가 17,164개로 나온다.
