[Elasticsearch] 검색 API 성능 개선 #3 - snowball, phonetic, synonym filter

이전까지 Elasticsearch를 활용해 검색 API의 속도를 개선했다. 이제 속도는 충분히 빠르므로 검색어에 따른 검색 결과 성능을 개선해보자. (참고로 부분 문자열 검색이 가능한 API이며 모두 영어이다.)
분석
그전에 우선 Elasticsearch에서 인덱싱이 이루어지는 과정을 간단하게 살펴보자. 문서를 검색 가능한 형태로 저장하는 것을 인덱싱이라고 하며 이 과정에서 각 필드를 토큰화하여 인덱스를 생성한다. 토큰화란 입력된 텍스트를 분석하여 특정 기준에 따라 텍스트를 쪼개고 토큰으로 변환하는 것을 말하며, 토크나이저가 이 작업을 수행한다.
Elasticsearch에서는 기본적으로 표준 토크나이저 (Standard Tokenizer)를 제공하는데 이는 일반적인 텍스트를 공백, 구두점을 기준으로 나눈다. 예를 들면, "Elasticsearch is powerful"이라는 문장이 있다고 할 때, 공백을 기준으로 토큰화하여 'Elasticsearch', 'is', 'powerful'라는 세 개의 토큰이 생성되는 것이다.
이후 Elasticsearch는 토큰화된 단어와 그 위치를 포함하는 역색인(Inverted Index)를 생성한다. 이제 문서가 검색 가능한 형태로 저장되어 토큰화된 단어가 포함된 문서를 빠르게 찾을 수 있다. 위의 예시에서 'Elasticsearch'를 검색하면 "Elasticsearch is powerful"라는 문장을 가진 문서를 빠르게 찾을 수 있는 것이다.
이러한 분석 과정에 사용되는 프로그램을 분석기(Anaylzer)라고 한다. 분석기는 하나의 토크나이저(Tokenizer)와 0개 이상의 토큰필터(Token Filter)로 구성되어 있다. 토크나이저는 설정된 기준에 따라 입력 데이터를 토큰으로 분리하는 작업을 하고, 토큰필터는 분리된 토큰에 필터를 적용해 검색어로 최종 변환한다.
예를 들면, "Elasticsearch is powerful"을 공백 기준으로 나누어 'Elasticsearch', 'is', 'powerful' 세 개의 토큰을 생성하는 것은 토크나이저가 하고, 여기서 'is'와 같은 불용어 제거, 대소문자 변환 등의 추가적인 작업을 해서 실제로 식별 가능한 검색어로 변환하는 작업은 토큰 필터가 한다.
어간 추출
지금의 API는 검색어와 부분적으로 온전히 일치하는 결과만을 출력한다. 즉, 사용자가 오타를 치거나 단어의 형태를 다르게 입력하면 결과로 출력되지 않는다. 예를 들어, 'codes'라고 검색하면 원형인 'code'과 관련된 결과는 나오지 않는 것이다.
이를 해결하기 위해 어간 추출을 제공하는 분석기를 사용할 수 있다. 대표적으로 snowball 분석기가 있으며 이 분석기는 단어의 어미나 접미사를 제거하여 단어의 어간을 추출한다.
다음과 같은 방법으로 인덱스의 특정한 필드에 분석기를 세팅할 수 있다. snowball 분석기는 영어 외에도 다국어를 지원하므로 lagnuage를 설정하여 사용하면 된다.
curl -X PUT "http://localhost:9200/index_name" -H "Content-Type: application/json" -d'
{
"settings": {
"analysis": {
"analyzer": {
"snowball_analyzer": {
"type": "snowball",
"language": "English"
}
}
}
},
"mappings": {
"properties": {
"field_name": {
"type": "text",
"analyzer": "snowball_analyzer"
}
}
}
}'결과
snowball 적용 전
- "running"이라고 검색 했을 때 "running"이 온전히 포함된 결과만을 출력

snowball 적용 후
- "running"이라고 검색 했을 때 원형인 "run"뿐만 아니라 "runner", "ran"과 같은 변형 형태도 모두 출력

이렇게 snowball 분석기를 통해 텍스트에서 단어의 변경을 줄이고, 동일한 어근을 가진 단어들을 통합하여 검색 성능을 향상시킬 수 있다. 다만, 일부 단어가 비정상적으로 변형될 수 있으며 결과값이 예상 외로 너무 많아질 수 있다는 단점도 존재한다.
형태소 분석
상표 검색 API의 경우 필드가 영어라 snowball 분석기를 사용했지만, 한국어의 경우 영어보다 좀 더 복잡하다. 단어를 원형으로 돌리는 것 뿐만 아니라 언어의 문법적 구조를 이해하고 단어를 구성하는 모든 형태소를 식별해야 한다. 이를 형태소 분석이라고 한다.
예를 들어, "나는 책을 읽는다"는 문장이 있을 때 이를 공백 기준으로만 나누게 되면 '나는', '책을', '읽는다'로 토큰화된다. 이를 의미있는 표준형으로 변환하기 위해 조사를 분리하고 복합어를 나누며 변형된 동사의 원형을 찾는 등 단어를 의미 단위로 나누어 분석해야한다. 이를 위해 다국어 분석기가 필요하며 대표적인 한국어 분석기로는 '노리(nori)'가 있다.
오타 보정
Fuzzy Query
퍼지 쿼리는 사용자가 입력한 단어와 유사한 단어를 검색할 때 사용된다. query문에 fuzzy 옵션을 추가하여 사용할 수 있다. fuzzy 옵션은 사용자가 입력한 검색어와 유사한 텍스트를 찾기 위해 Levenshtein 거리(문자 삽입, 삭제, 교체의 수)를 활용한다. fuzzy 값을 AUTO로 설정하면 자동으로 적절한 fuzzy 값(문자 차이의 수)을 결정한다. 일반적으로 검색어의 길이에 따라 자동으로 조정된다.
다만 이를 실제로 검색에 활용하게 되면 검색의 정확도가 상당히 떨어지게 된다. 예를 들어 "runnin"이라고 오타를 내서 검색했는데 "dunkin"이 결과로 나온다. fuzziness는 텍스트의 유사성을 기준으로 단어를 찾기 때문에 실제 입력한 검색어와 스펠링은 비슷한데 뜻은 완전히 다른 단어들이 결과에 포함되는 것이다. 그래서 fuzzines를 1로 고정하여 한글자정도 오타가 났을 때만 fuzzy 쿼리로 보정할 수 있도록 하였다.
"query": {
"match": {
"field_name": {
"query": input,
"fuzziness": "AUTO" // 또는 특정 숫자
}
}
}phonetic
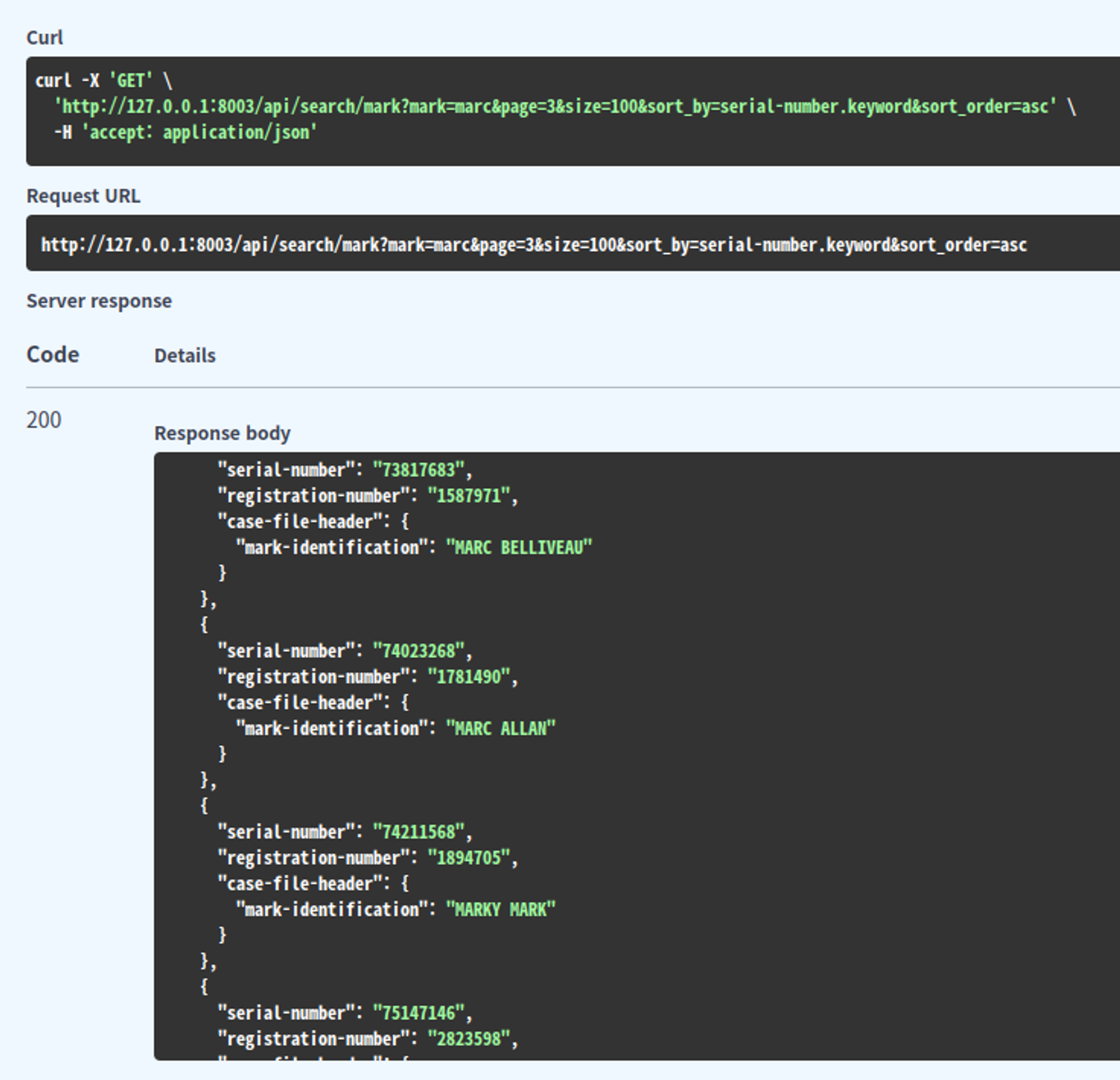
Phonetic 필터는 발음 기반으로 텍스트의 유사성을 분석한다. 영어의 경우 encoder로 Soundex나 Metaphone 같은 분석기를 사용할 수 있다. 이를 통해 "marc"라고 잘못 검색해도 발음이 유사한 "mark"가 결과로 출력되도록 할 수 있다.
"settings": {
"filter": {
"phonetic": {
"type": "phonetic",
"encoder": "metaphone",
"replace": false // phonetic 결과를 기존 결과에 추가
}}}phonetic 필터는 elasticsearch의 플러그인을 설치해야 사용 가능하다. 아래의 명령어로 설치 후 확인할 수 있다.
bin/elasticsearch-plugin install analysis-phonetic
bin/elasticsearch-plugin list # 목록 확인결과
phonetic 필터 적용후
- “marc”라고 검색할 경우 발음이 비슷한 “mark”에 대한 검색 결과가 함께 출력
Synonym
Synonym 필터는 줄임말 등 특정 용어와 그에 대응하는 용어를 직접 정의할 수 있다. 즉, 동의어를 설정할 수 있다.
이를 사용하기 위해서는 두 가지 방식이 있는데 첫 번째는 파라미터로 등록하는 방식이다. 이는 필터의 파라미터에 직접 동의어를 나열하는 방식인데 사실 잘 쓰이지는 않는다. 두 번째는 특정 파일을 별도로 생성해서 파일에 동의어를 등록하고 관리하는 방식이다. 이 방식이 주로 사용되며 이 파일을 동의어 사전이라고 부르곤 한다.
"filter": {
"synonym": {
"type": "synonym",
"synonyms_path": "analysis/synonym.txt", // 동의어 사전 파일 경로
"updatable": true // 파일 업데이트 반영
}}동의어 사전 파일은 elasticsearch에 생성하면 된다. 도커로 띄웠을 경우 볼륨 설정으로 로컬의 파일과 동기화해줄 수 있다.
/usr/share/elasticsearch/config/analysis/synonyms.txt또한 텍스트 파일의 같은줄에 단어들을 입력하면 동의어로 인식하며 쉼표로 단어, 엔터로 동의어를 구분하면 된다. 이때, 한글과 영어를 동의어로 등록해두면 별다른 설정없이 한영 검색도 가능하다.
결과
Synonym 필터 적용후
-
“PC”라고 검색했을 때, 동의어 사전에 등록된 “personal computer” 검색 결과도 같이 출력

-
"나이키"라고 검색했을 때, 동의어 사전에 등록된 “nike” 검색 결과 출력

N-grams
N-grams 토크나이저는 단어를 일정 길이의 서브 스트링으로 나누어 검색어와 비슷한 패턴을 찾는다. 오타 또는 비슷한 단어 검색이 가능하다
그러나 토큰의 갯수가 기하급수적으로 늘어나고 검색 결과 또한 예상치 못한 결과들이 굉장히 많이 나타날 수 있기 때문에 정확도가 떨어진다. N-grams는 대용량 데이터보단 소규모 데이터의 자동완성 같은 기능에 유용하다.
커스텀 분석기
처음에 설명했듯, 하나의 분석기는 하나의 토크나이저와 0개 이상의 토큰필터로 구성되어 있다. elasticsearch 내부에 정의된 분석기를 사용하면 해당 분석기가 가지고 있는 토크나이저와 토큰필터로 분석할 수 있다. snowball 분석기의 경우 standard 토크나이저와 standard, lowercase, stop, snowball 토큰 필터를 사용한다.
만약 임의의 토크나이저와 토큰필터를 직접 추가하고 싶다면 분석기를 커스텀하여 사용자 분석기를 정의하면된다. 예를 들어 필자는 standard 토크나이저와 snowball, phonetic, synonym 등의 특정 토큰필터를 적용한 커스텀 분석기를 생성하였다.
curl -X PUT "http://localhost:9200/index_name" -H "Content-Type: application/json" -d'
{
"settings": {
"analysis": {
"filter": {
"snowball_filter": {
"type": "snowball",
"language": "English"
},
"synonym_filter": {
"type": "synonym",
"synonyms_path": "analysis/synonym.txt",
"updatable": true
},
"phonetic_filter": {
"type": "phonetic",
"encoder": "metaphone",
"replace": false
},
},
"analyzer": {
"custom_analyzer": {
"type": "custom",
"tokenizer": "standard",
"filter": [
"stop",
"lowercase",
"snowball_filter",
"synonym_filter",
"phonetic_filter"
]
}
}
}
}이를 통해 변형된 단어로의 검색, 오타 보정, 동의어 검색 등이 가능하도록 하여 검색 성능을 향상시켰다. 또한 elasticsearch의 경우 검색어로 입력된 단어와의 유사도를 score로 매겨 내림차순 정렬로 보여주는 것이 기본 정렬값이므로 해당 필터들을 적용하여 검색 결과가 늘어났다고 하더라고 사용자가 직접 입력한 단어에 대한 검색 결과가 최대한 최상단에 나올 수 있도록 한다.
