
Redis sorted set과 비관적락을 활용한 핫딜 구매 대기열 구현 로직에서 트래픽이 몰렸을 때 구매가 잘 되는지 확인하는 데이터 정합성 테스트와 성능 테스트를 ngrinder로 진행 후 AWS Cloud Watch를 통해 모니터링
테스트 스크립트
이전의 테스트에서 로그인을 첫번째 테스트 구매를 두번째 테스트로 스크립트를 짜고 실행하였더니 동일한 유저가 여러번 구매 요청을 보내게 되어 구매 결과를 제대로 확인할 수 없었다. 그래서 로그인을 @BeforeProcess에서 미리 진행하고 토큰값을 배열에 저장해둔 뒤, 테스트에서는 해당 토큰값을 가져다가 사용하는 것으로 스크립트를 변경하였다.
@BeforeProcess
public static void beforeProcess() {
HTTPRequestControl.setConnectionTimeout(300000)
test = new GTest(1, "POST localhost:8080/api/hotdeals/purchase/sortedset")
request = new HTTPRequest()
headers.put("content-type", "application/json")
request.setHeaders(headers)
// 로그인을 수행하고 토큰을 배열에 저장
for (int i = 1; i <= 100; i++) {
HTTPResponse response = request.POST("http://localhost:8080/api/members/login",
[email: userEmail, password: userPassword])
// 토큰 앞에 붙는 String 제거
String token = response.getHeader("Authorization").toString().substring(15)
// 토큰 배열에 저장
tokens.add(token)
}
}
@Test
public void test() {
int threadIndex = grinder.getThreadNumber()
// 해당 스레드의 토큰을 가져와서 헤더에 설정
String token = tokens[threadIndex]
headers.put("Authorization", token)
request.setHeaders(headers)
// JSON 형식의 requestDto를 body로 추가하여 POST 요청 수행
HTTPResponse response = request.POST("http://localhost:8080/api/hotdeals/purchase/sortedset",
[hotdealId: 8, quantity: 1, address: address, phone: phone])
assertThat(response.statusCode, is(200))
}
그러나 이렇게 하여도 위처럼 유저들이 계속 중복되는 문제가 발생하였다 (심지어 중복이 랜덤하게 일어나 10개의 스레드가 모두 같은 유저일 때도, 10개 중 3개의 스레드만 같은 유저일 때도 존재했다.) 원인을 찾기 위해 테스트를 진행하면서 토큰 배열의 인덱스 값으로 사용하는 스레드넘버와 가져온 토큰값이 모두 다른지 로그로 확인해보았다.

확인 결과 스레드 넘버도 토큰값도 모두 달랐다...
다른 원인을 찾아보았는데 테스트 스크립트에서 전역 변수로 선언된 같은 헤더를 사용하고 있어서 테스트를 진행할 때마다 헤더를 지역 변수로 선언하는 것으로 변경해보았다.
Map<String, String> testheaders = [:]
testheaders.put("content-type", "application/json")
int threadIndex = grinder.getThreadNumber()
String token = tokens[threadIndex]
testheaders.put("Authorization", token)이렇게 하였더니 드디어 100개의 스레드를 생성하였을 때 100명의 유저중 중복 된 유저가 발생하는 문제가 해결되었다!
로컬 테스트
- 100개의 스레드를 생성하여 5분동안 약 5,000건의 구매 요청을 보냄 (초당 구매 가능 인원 : 100명)
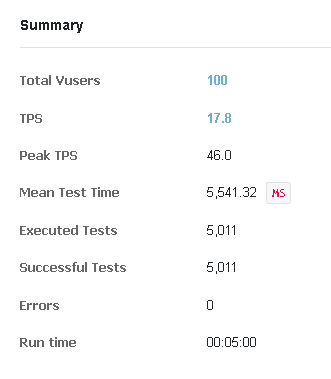
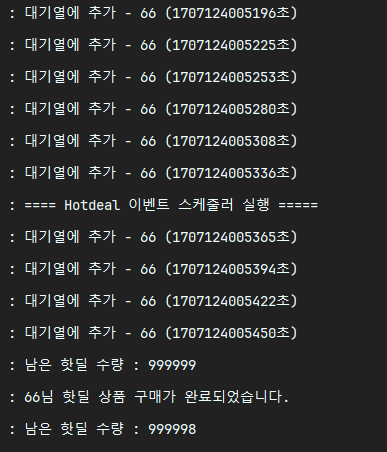
이전의 테스트와 다르게 약 5000건이 잘 구매된 것을 확인할 수 있었다.
다만 매초 100건씩 처리하지 못하고 90~100건 정도 처리가 되는 것을 확인할 수 있었다.
1초에 100건의 처리를 못하는 것인지 대기열에 같은 멤버가 등록되었기 때문인지 확인해보고자 했지만 스레드 수가 100을 초과할 경우 로그인 오류가 발생하여 확인해보지 못했다....
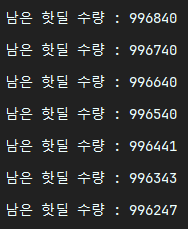
- 100개의 스레드를 생성하여 1분동안 약 700건의 구매 요청을 보냄 (초당 구매 가능 인원 : 50명)
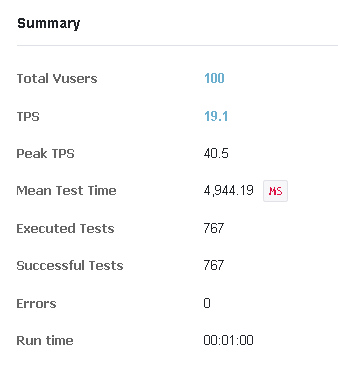
약 600건의 구매가 완료된 모습을 확인할 수 있었다.
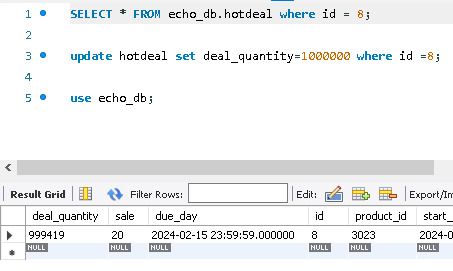
초당 구매 가능 인원 수를 50명으로 감소하였더니 정확히 50개씩 수량이 감소하는 것을 확인할 수 있었다.
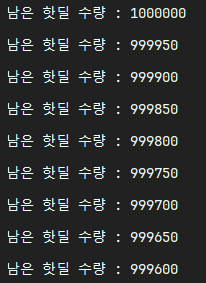
또한 멤버 id를 로그로 찍어보았더니 한 번 요청을 보낼 때는 각기 다른 유저들이 요청을 잘 보내고 있었다. 다만 스레드가 100개뿐이다 보니 당연히 유저도 100명뿐이고 해당 유저들이 요청을 반복적으로 보내어 결국 유저 중복 문제를 완전히 피해갈 수는 없었다.
서버 테스트
이 테스트 스크립트가 100명의 로그인된 유저에 대해 구매가 잘 이루어 지는 것을 확인하였으니 실제 서버에서 테스트를 실행해보자. 비관적락만 적용됐을 때와 sorted set이 함께 적용됐을 때를 비교해보고자 한다.
프로젝트 환경
EC2 : t2.xlarge
JDK 17
Spring Boot 3.2.1
Gradle 8.5
Redis 7.2.3
비관적락 적용
- 100개의 스레드를 생성하여 10분동안 약 44,000건의 구매 요청을 보냄

TPS 75.7, 약 44,000건의 구매가 잘 이루어짐을 확인
AWS Cloud Watch를 사용하여 CPU와 RAM 사용량 확인
- CPU 18%, RAM 18% 정도 사용하는 것을 확인하였다.
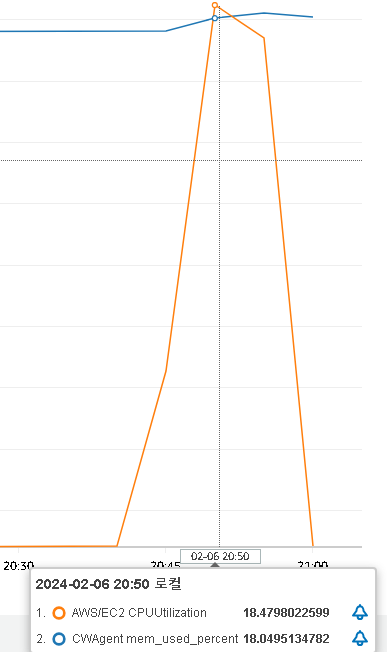
- 100개의 스레드를 생성하여 30분동안 약 135,000건의 구매 요청을 보냄
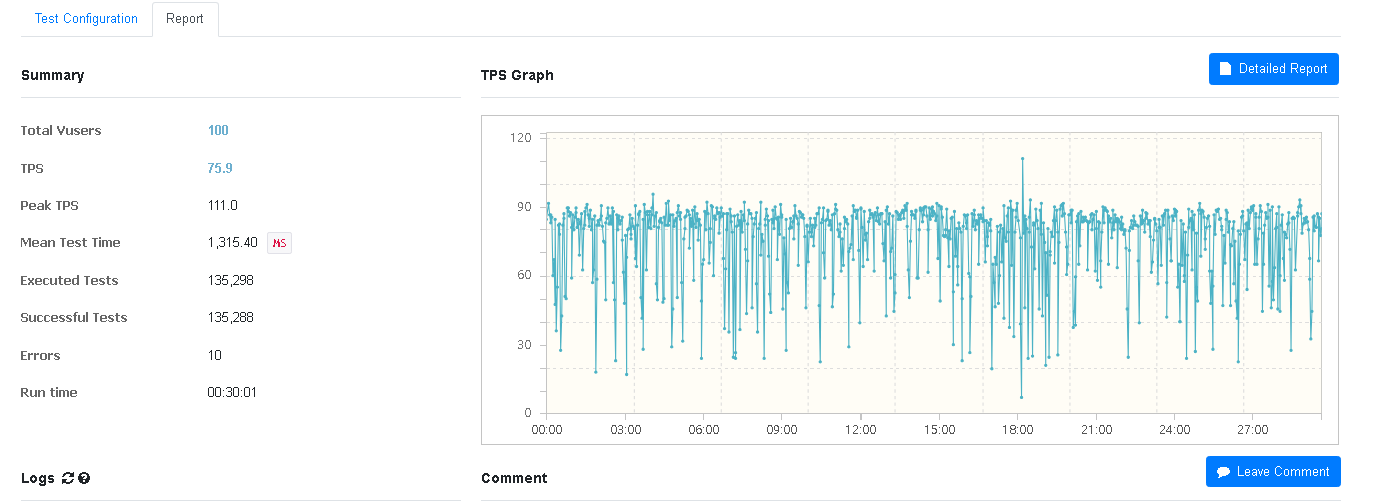
TPS 75.9, 약 135,000건의 구매가 잘 이루어짐
AWS Cloud Watch를 사용하여 CPU와 RAM 사용량 확인
- CPU 18%, RAM 18% 정도 사용하는 것을 확인하였다.
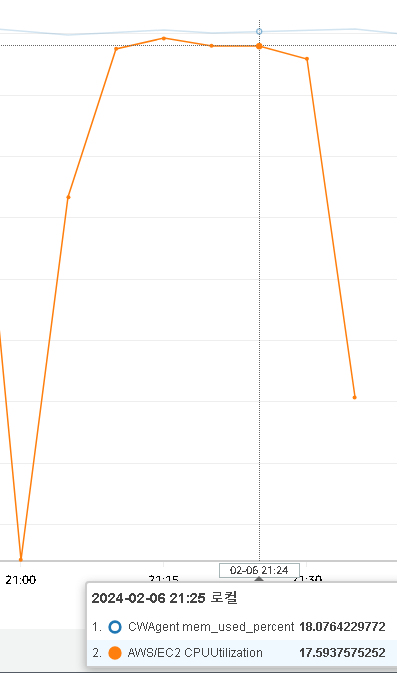
첫 번째 테스트와 거의 동일한 결과를 나타냈다.
비관적락 + sorted set 적용
⚠ sorted set 테스트의 경우 대기열 진입 시 구매 API 요청 종료되므로 이후 이벤트로 발생시키는 구매 로직에 대한 TPS를 ngrinder로 측정할 수 없다.
⚠ 또한 sorted set은 중복을 허용하지 않으므로 일정 시간 동안 같은 유저들이 중복 요청을 보내는 테스트에서는 정합성 테스트를 진행하지 않았다.
- 100개의 스레드를 생성하여 10분동안 약 64,000건의 구매 요청을 보냄 (초당 구매 가능 인원 100명)
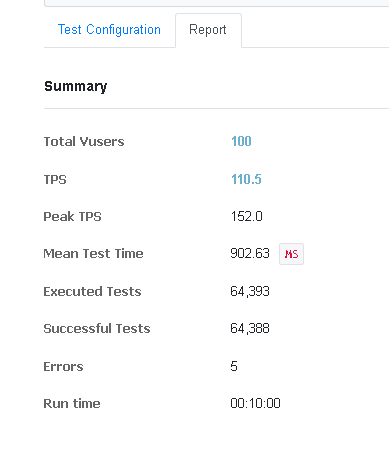
비관적 락만 적용했을 때보다 1.5배 많은 요청이 이루어졌다. TPS가 약 1.5배 증가했음을 알 수 있다. 위에 말했듯 이전 로직은 purchaseHotdeal API 요청시 구매까지 이어지지만 이 로직은 대기열에 입장하면 요청이 끝나게 되고 이 시점에서 트랜잭션 측정이 끝난다. 이후 실제 구매로직은 스케줄러가 발생시킨 이벤트 리스너에서 진행하므로 측정이 되지 않는 것이 당연한 결과일 것이다.
AWS Cloud Watch를 사용하여 CPU와 RAM 사용량 확인
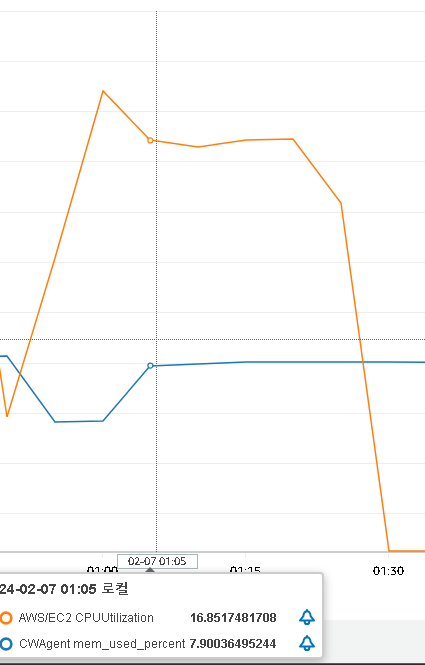
- CPU 18%, RAM은 6% 사용하는 것을 확인하였다.
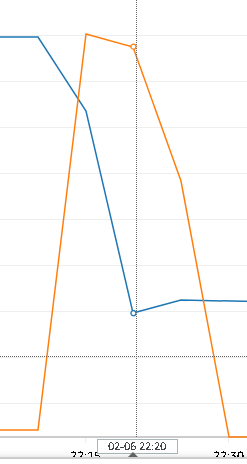
CPU 사용량은 비슷했으나 메모리 사용량은 오히려 줄어들었는데 이는 sorted set 코드를 push 했을 때부터 줄어들었다. 테스트가 끝난 이후에도 6%의 메모리 사용량이 유지되는 것을 확인하고 (기존 17% 유지) 다시 한 번 테스트를 진행하였는데도 비슷한 결과를 보였다.
사실 이유가 정확히 무엇 때문인지는 알아내지 못했다. sorted set을 제외하고 변경 사항이 거의 없었는데 요청을 보내기 전, 코드 변경만으로 메모리 사용량이 10%가량 감소하여 의문을 가진 상태.. 심지어 변경된 코드는 테스트를 위해 요청을 보내지 않아도 1초에 한 번씩 스케줄러가 도는 상태인데도 말이다..
이전과 동일하게 30분 테스트도 이어서 진행해보았다.
- 100개의 스레드를 생성하여 30분동안 약 200,000건의 구매 요청을 보냄 (초당 구매 가능 인원 100명)
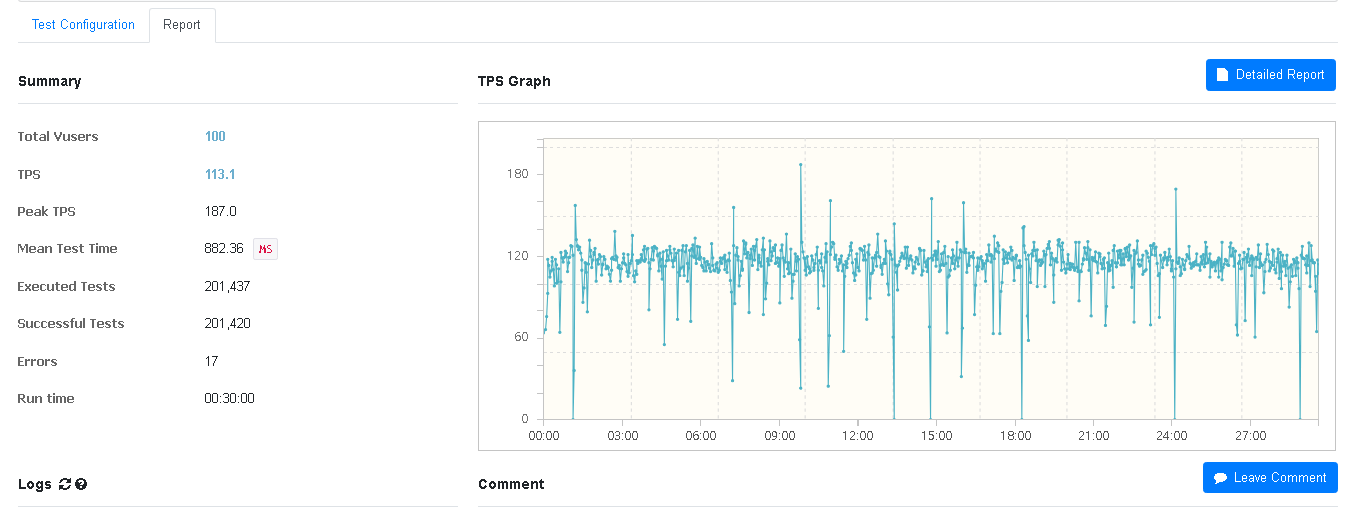
AWS Cloud Watch를 사용하여 CPU와 RAM 사용량 확인
- CPU 16~18%, RAM은 8% 사용하는 것을 확인하였다.
테스트 개선 방향
비관적락만 적용된 테스트의 경우 대기열이 존재하지 않으므로 중복 요청시에도 구매가 가능하지만 sorted set 대기열에 중복적으로 요청을 하면 실제 구매는 한 번만 이루어지기 때문에 정합성 테스트를 하기 어렵다.
그렇다고 100개의 스레드로 요청을 한 번만 보내는 테스트를 하게 되면 1분이내에 테스트가 끝나버리기 때문에 성능 측정을 하기가 어렵다. 원하는 테스트 결과를 보기 힘들었다..
다만 이렇게 진행된 테스트에서 우선은 비관적락만 적용하였을 때와 sorted set과 함께 적용하였을 때, CPU 사용률에 큰 차이가 없는 것을 발견하였다. RAM 사용률은 테스트 진행 도중에 거의 변하지 않지만 어떤 이유에선지 중간에 코드가 변경되자 사용률이 대폭 감소하였다. 이 두가지에 대한 분석은 조금 더 필요할 것 같다.
또한 우리는 로그인에 트래픽이 몰리는 상황은 고려하지 않았기 때문에 스레드를 100개 이상 생성하면 로그인에서 오류가 발생하여 구매 테스트가 제대로 진행이 되지 않았다. 그래서 스레드를 100개만 생성하고 일정 시간동안 계속해서 구매 요청을 보내도록 하여 테스트를 진행하였다.
100명의 유저가 계속해서 요청을 보낸다고 해도 더 많은 유저들이 요청을 보내는 상황을 체크해 볼 수가 없다. ngrinder는 최대 3000개의 스레드를 지원하므로 3000개의 스레드를 모두 사용하여 테스트를 진행할 수 있도록 추후 로그인을 아예 제외하고 유저를 직접 넣어주는 방식으로 코드를 변경하여 부하 테스트를 진행해보도록 해야겠다.
