
Redis sorted set과 비관적락을 활용한 핫딜 구매 대기열 구현 로직에서 트래픽이 몰렸을 때 구매가 잘 되는지 확인하는 데이터 정합성 테스트와 성능 테스트를 ngrinder로 진행 후 AWS Cloud Watch를 통해 모니터링
이전의 테스트 스크립트에는 로그인을 포함하였더니 핫딜에 대한 부하 테스트를 정확히 진행할 수 없어서 로그인을 제외하고 오직 핫딜 구매에 트래픽이 몰리는 환경 구성을 위해 코드를 변경하였다.
기존의 로직은 로그인된 유저의 토큰값을 가져오는 방식이었는데 이를 스레드 넘버를 받는 것으로 변경하고 sorted set에 유저의 id 대신 스레드 넘버를 value 값으로 저장하도록 하였다. 또한 유저 레포지토리에 3000개 이상의 유저 더미 데이터를 넣어두고 스레드 넘버를 유저 id로 사용하여 유저 정보를 가져오도록 하였다.
이렇게 로그인 없이도 핫딜 구매가 가능하도록 변경하였다! 또한 스크립트를 다음과 같이 변경했다.
// 대기열 등록
@Test
public void test() {
String address = "address"
String phone = "01012345678"
int threadNumber = grinder.getThreadNumber() + 60
HTTPResponse response = request.POST("http://localhost:8080/api/hotdeals/purchase/sortedset",
[hotdealId: 8, quantity: 1, address: address, phone: phone, threadNumber: threadNumber])
assertThat(response.statusCode, is(200))
}프로젝트 환경
EC2 : t2.xlarge
JDK 17
Spring Boot 3.2.1
Gradle 8.5
Redis 7.2.3
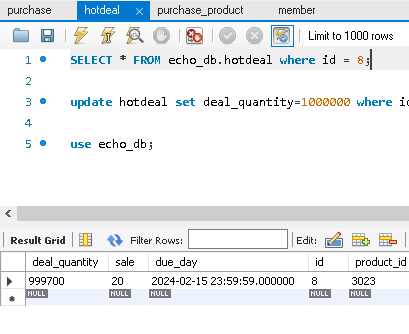
테스트 전 짚고 넘어가야 할 부분이 있었으니... hotdeal의 구매 로직이 변경되었다는 것이다... 이전에는 purchase hotdeal 요청시 hotdeal 객체가 필요하다고 생각해서 hotdeal 레포지토리에서 hotdeal을 찾아오면서 비관적락을 같이 적용하였다. 그러나 이것이 필요없다는 사실을 알게되어 비관적락만 적용했을 때와 sorted set만을 적용했을 때를 비교해보고자 한다.
부하 테스트가 처음이라 이런저런 다양한 시나리오로 테스트를 진행해보았다. 프로세스와 스레드수를 몇 개로 설정하고 어떻게 테스트를 진행해서 비교해야 하는지에 대한 고민도 더 필요할 것 같다.
서버 테스트
sorted set
⚠ sorted set은 중복을 허용하지 않으므로 일정 시간 동안 같은 유저들이 중복 요청을 보낼 수 있는 테스트에서는 정합성을 확인하기 어렵다. 또한 모든 테스트에서 초당 구매 가능 인원은 100명으로 설정하였다.
1. 500개의 스레드를 생성하여 1번씩 구매 요청을 보냄
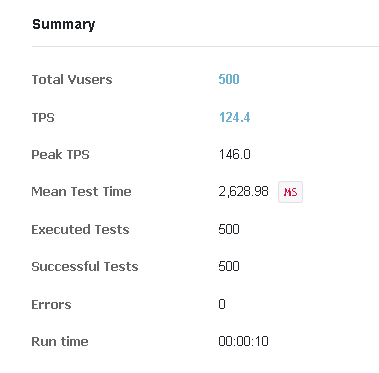
Duration이 아닌 Run Count를 1로 설정하여 같은 유저로 계속 요청을 보내지 않고 유저당 한 번씩만 요청을 보내도록 하였다. 이 테스트는 초당 100명의 인원 구매 처리가 가능한지 확인하기 위해서도 진행되었다.
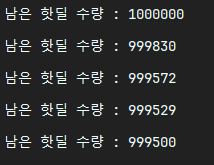
중간에 170건, 260건이 한번에 줄어든 것을 발견할 수 있었다. 핫딜 수량을 조회할 때 구매 진행중이던 트랜잭션이 종료되지 않은 탓인지 요청이 밀려서 진행된 것인지를 확인하는 것까지는 어려웠으나 정확히 5초만에 500건이 처리된 것을 보면 데이터 정합성이 지켜졌을 뿐 아니라 초당 100건씩 구매 이벤트를 잘 발생시켰으리라 생각된다. 이전의 테스트에서 100건을 처리하지 못한 것은 역시나 중복 요청 때문인듯하다.
2. 3개 프로세스, 100개 스레드를 생성하여 총 300명의 유저가 1번씩 구매 요청을 보냄
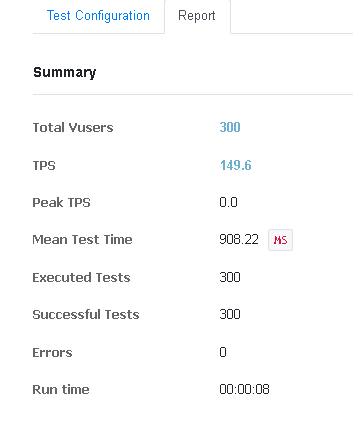
sorted set만을 적용해도 동시성 이슈가 잘 해결되었는지 확인하기 위해 프로세스 수를 늘려 요청을 보내보았다.
정확히 300개 구매된 것을 확인할 수 있었다
3. 1000개의 스레드를 생성하여 1번씩 구매 요청을 보냄
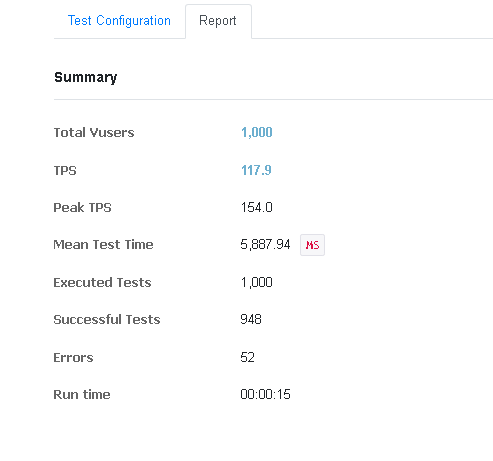
해당 테스트의 경우 실행 시간이 15초로 굉장히 짧아 cloud watch로 성능 측정은 하지 못하였다. 구매는 정확히 요청 성공 건수와 일치하는 948건 이루어짐을 확인하였다.
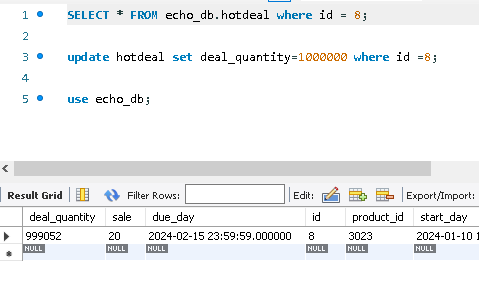
그런데 여기서 약 5% 정도의 오류가 발생한 것을 확인할 수 있는데 이것은 네번째 테스트에서 발생한 오류와 동일하니 후에 자세히 서술하겠다.
4. 3000개의 스레드를 생성하여 1번씩 구매 요청을 보냄
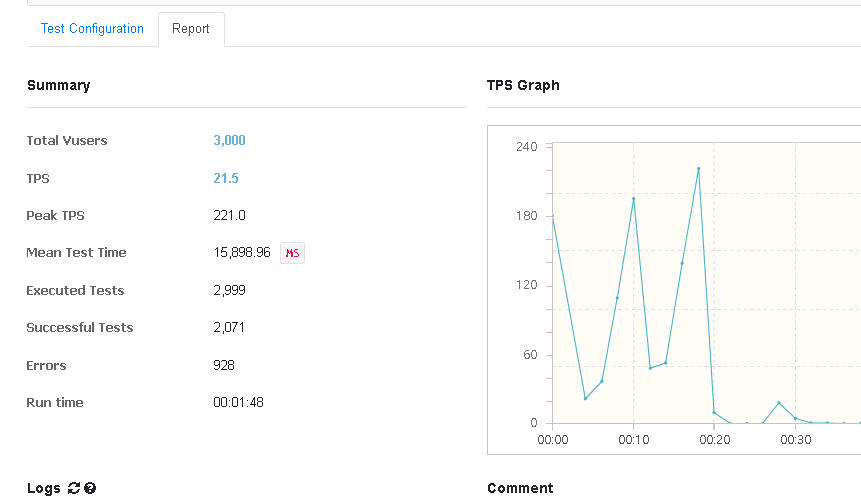
스레드의 개수를 ngrinder에서 가능한 최대로 늘려 요청을 전송했는데 3000건중 약 1000건에서 오류가 발생했다. 오류 메세지는 다음과 같다.
2024-02-07 20:54:54,000 ERROR java.util.concurrent.ExecutionException: java.io.IOException: 현재 연결은 원격 호스트에 의해 강제로 끊겼습니다
2024-02-07 20:54:54,090 ERROR java.util.concurrent.ExecutionException: java.net.ConnectException: Connection timed out: no further information
타임아웃의 원인은 정확히 알 수 없다. 다양한 이유로 발생할 수 있기 때문이다. 추측을 해보자..
첫번째는 서버가 3000개의 스레드를 감당하지 못한 것이다. 서버에서 사용하는 스레드 풀의 사이즈를 초과하는 요청이 들어오면 대기열 큐에서 기다리게 된다. 그런데 이러한 대량의 트래픽이 지속적으로 발생하면 서버의 지연 시간이 계속해서 증가하여 타임 아웃 오류가 발생할 수 있다고 하며 이러한 현상을 Thread Pool Hell 이라고 한다.
이를 해결하기 위해 스레드풀을 늘릴 수 있지만 너무 많이 늘릴 경우 시스템 리소스를 과도하게 사용하여 성능을 저하시킬 수 있다고 한다.
두번째는 네트워크 문제이다. 말그대로 네트워크 리소스를 과하게 사용하다가 연결이 끊어져 요청을 보내지 못한것이다.
세번째는 서버 리소스 부족 문제이다. 서버가 부하 테스트에 대응하기에 충분한 리소스를 가지고 있지 않을 수 있다. CPU, 메모리, 네트워크 대역폭 등의 리소스가 부족할 경우 타임아웃 오류가 발생할 수 있다.
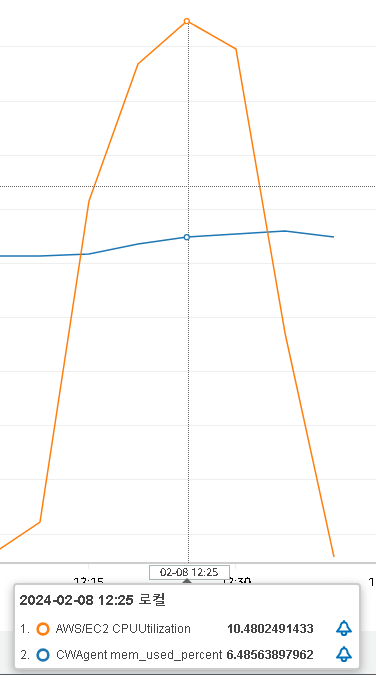
그러나 우리 프로젝트는 t2.xlagre를 사용하고 있고 요청을 보냈을 때의 cloud watch를 보면 2분 이내의 짧은 시간동안 CPU와 RAM 사용률에 그정도의 큰 변화는 없으므로 다른 문제일 가능성이 높다고 생각된다.
5. 1000개의 스레드를 생성하여 5분 동안 구매 요청을 보냄
그렇다면 1000개의 스레드로 5분 동안 지속적으로 보냈을 때는 서버가 어느 정도로 감당 가능할지 궁금하니 테스트를 진행해보자.
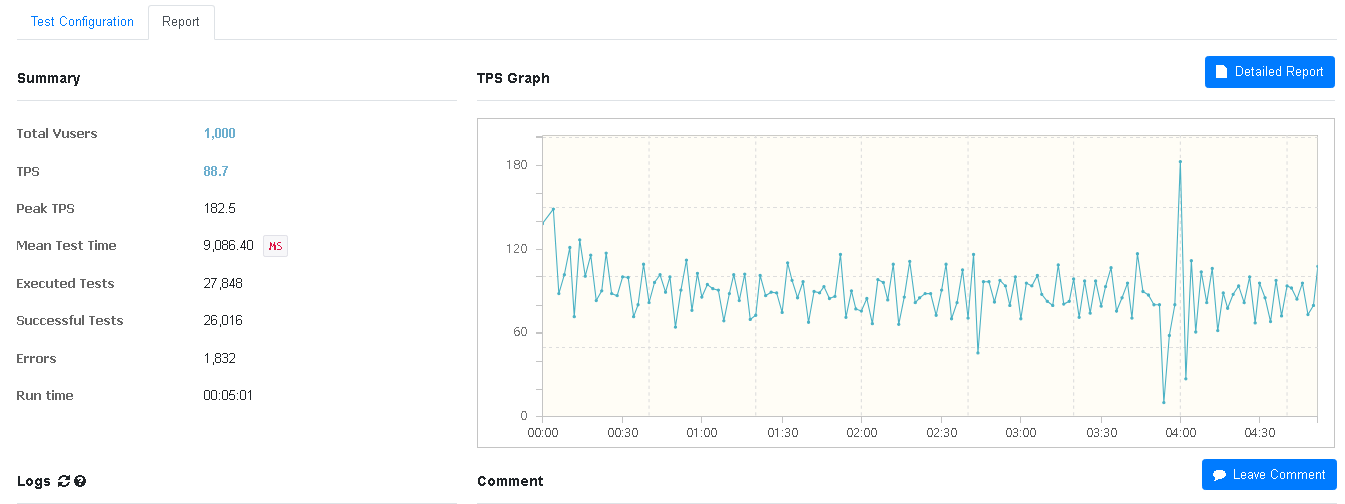
오류 발생률 6%, CPU와 RAM 사용량은 모두 7% 정도를 기록했다.
6. 500개의 스레드를 생성하여 5분 동안 구매 요청을 보냄
스레드를 줄여도 구매 실패 비율이 비슷한지 테스트해보고자 스레드 수를 500개로 줄이고 똑같이 5분동안 요청을 보내도록 하였다.
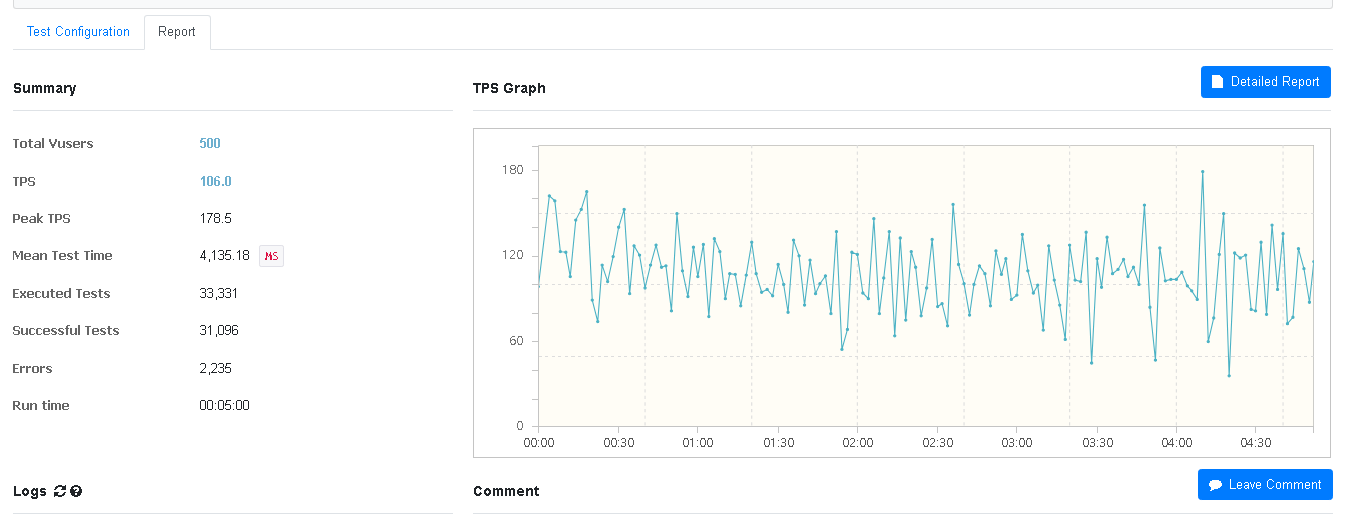
오류 발생률은 6% 정도로 1000개의 스레드보다 훨씬 낮은 수치를 보여주었다. 스레드 개수는 적지만 구매 요청 수는 오히려 더 많기 때문에 CPU 사용률도 4번 테스트보다 4%가량 더 높게 나온것으로 생각된다.
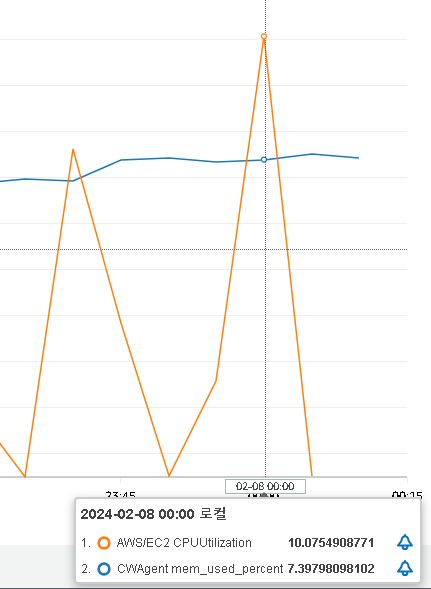
7. 3개 프로세스, 100개의 스레드를 생성하여 20분 동안 구매 요청을 보냄
비교적 오랜 시간 요청을 보냈을 때의 부하 테스트를 마지막으로 해보자.
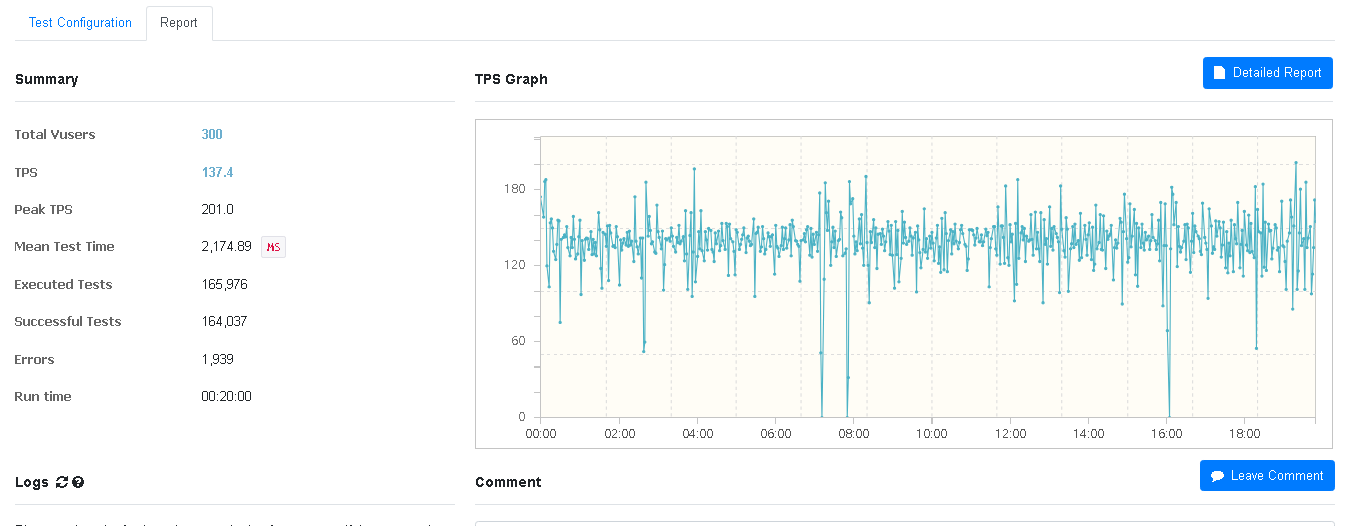
CPU 사용률 10%, RAM 사용률은 6% 정도를 기록했다.
비관적락
이제 비관적락만 적용된 테스트를 진행하여 sorted set을 적용했을 때와 성능을 비교해보자.
1. 3개 프로세스, 100 스레드를 생성하여 총 300명의 유저가 1번씩 구매 요청을 보냄
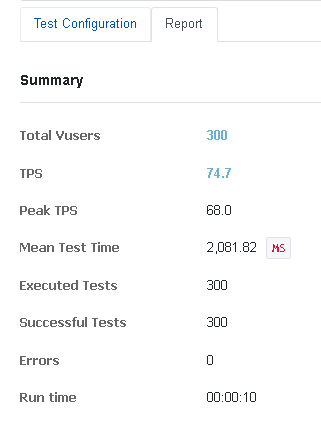
정확히 300개 감소하였다. 비관적락도 데이터 정합성이 잘 지켜짐을 확인할 수 있다.
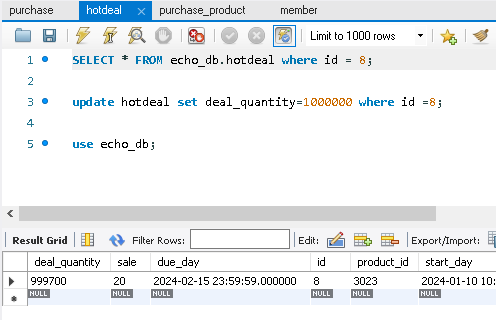
2. 3개 프로세스, 100개의 스레드를 생성하여 20분 동안 구매 요청을 보냄
sorted set 7번 테스트와 같은 시나리오이므로 성능 비교를 해보자.
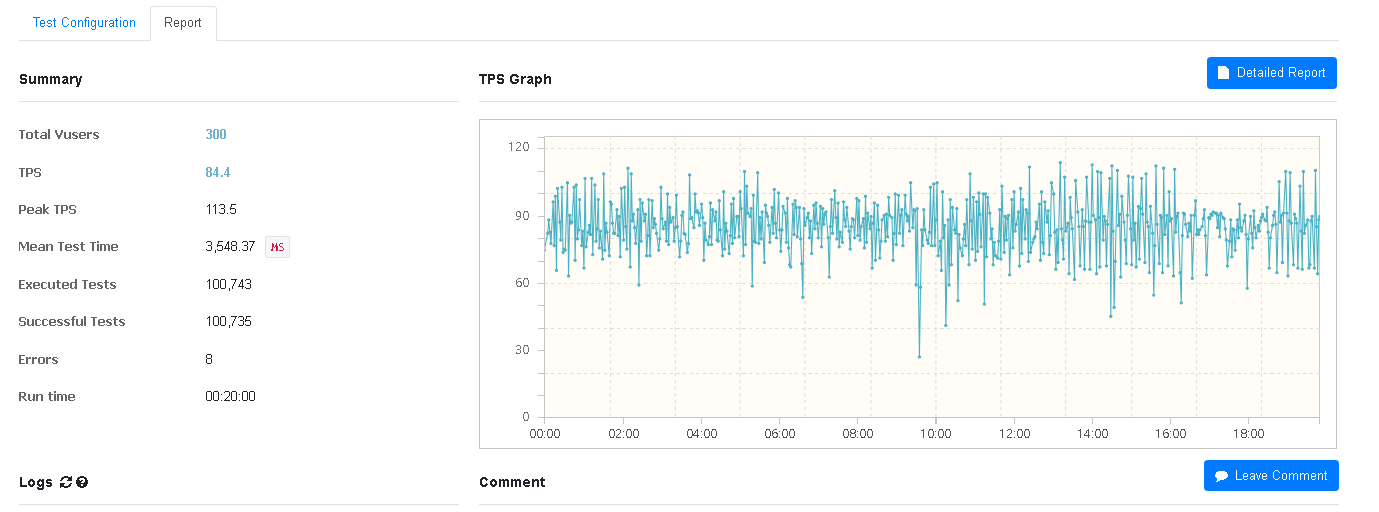
우선 sorted set이 1.5배 정도 더 높은 TPS를 보여주고 있어 훨씬 더 적은 수의 요청을 보낸 것을 알 수 있다. 그러나 이는 위에서도 말했듯 sorted set 로직의 정확한 TPS를 측정하기 어려우므로 넘어가도록 하겠다.
또한 MTT가 3.5초로 상당히 오래걸리는데 2초 걸리는 sorted set보다 1.5배 높다. (물론 2초도 오래 걸린다...) 다만 MTT도 TPS와 동일한 이유로 정확한 비교를 하기 어렵다.
sorted set과 CPU 사용률에서 2% 정도의 근소한 차이를 보이긴 했지만 오히려 더 적은 사용률을 보이며 예상 밖의 결과를 나타냈다.
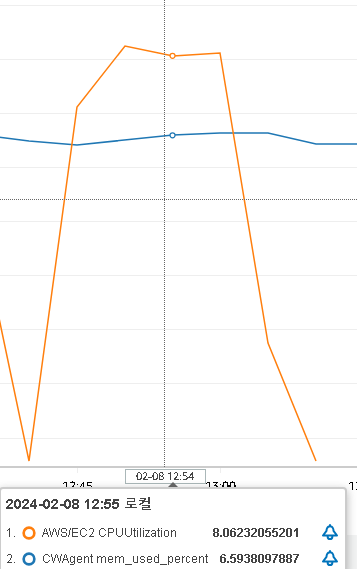
3. 1000개의 스레드를 생성하여 5분 동안 구매 요청을 보냄
sorted set 5번 테스트와 같은 시나리오이다. 오류 발생률이 다를지 궁금하여 테스트해보았다.
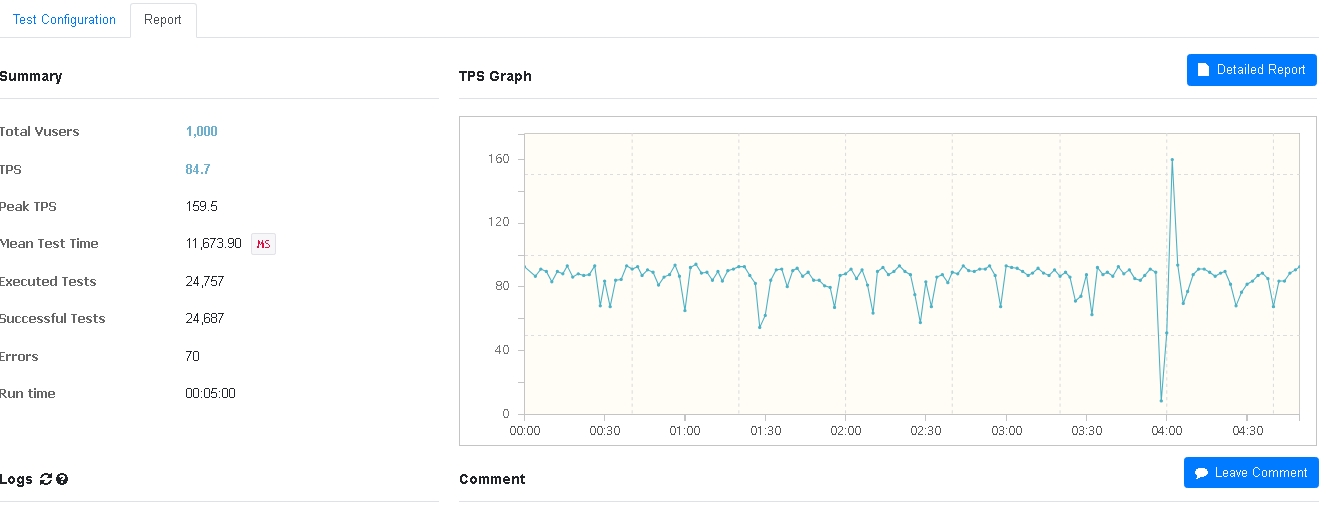
오류 발생률이 약 0.3% 정도로 거의 발생하지 않았다. 비관적락이 조금더 안정적인 로직인가?
CPU 사용률 7%, RAM 사용률 6.5% 정도로 sorted set과 거의 동일하였다.
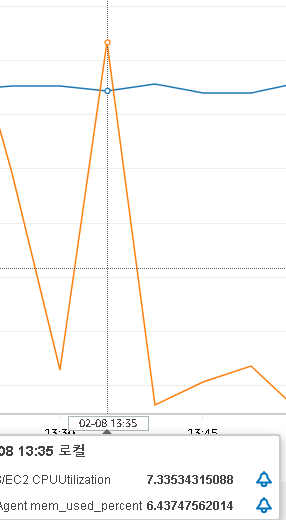
4. 3000개의 스레드를 생성하여 1번씩 구매 요청을 보냄
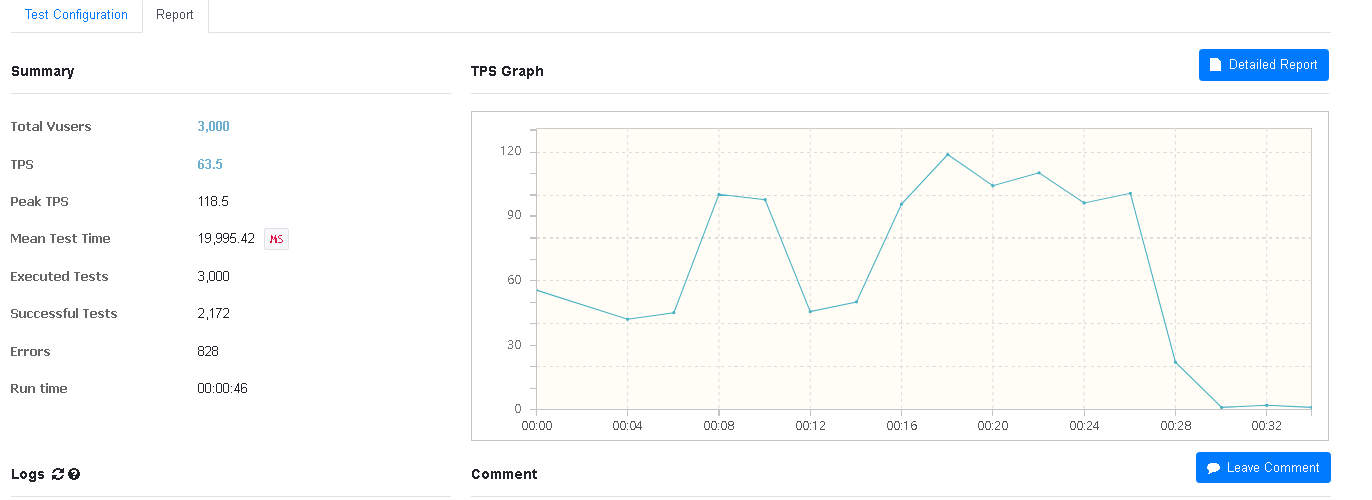
3000개 스레드의 경우에는 비관적락도 비슷한 에러 발생률을 보였다. 이는 서버 또는 네트워크에서 감당하지 못하는 스레드양인듯 하다.
결론
테스트 도중 메모리 사용률에 변화가 거의 없는 것을 보아 sorted set로직도 비관적락 로직도 해당 API가 메모리를 거의 사용하지 않는 것 같다.
sorted set 테스트의 경우 대기열 진입 시 구매 API 요청이 종료되므로 이후 이벤트로 발생시키는 실제 구매 로직에 대한 TPS와 MTT를 ngrinder로 측정하기 어렵다는 문제는 여전히 남아있었다.
비관적락만 적용했을 때와 sorted set을 적용했을 때 성능 차이를 비교하고 싶어서 시작한 테스트였는데 이론적으로 성능 개선이 있을 것이라 생각했지만 실제로 내가 한 테스트에서는 눈에 띄는 성능 차이를 볼 수 없었다. sorted set 로직의 구현 방식 문제인지 고민해봐야할 듯 하다.
우선 우리 프로젝트에서는 sorted set을 적용하여 유저들의 접근 순서를 보장하고 대기 번호를 부여해 줄 수 있는 기능을 구현한 것에 의의를 두어야겠다.
또한 이번의 테스트를 통해 테스트를 하는 것 자체도 굉장한 시간과 노력이 든다는 것을 깨달았다. 테스트 결과가 내가 의도한 대로 나오지 않은 순간이 정말 많아서 기능이 잘 동작한다고 해도 실제 서비스에서는 예상치 못한 오류들과 끊임없이 마주할 수 있겠구나 라는 생각이 들었다. 역시 이론만으론 안되나보다...ㅎㅎ
이러한 서비스에서 메세지큐를 사용하여 카프카나 래빗MQ 등을 적용하는 것이 성능적으로 더 좋겠으나 러닝커브를 우려해 적용해보지 못하였다. 향후 개선 방향으로 남겨두어야 겠다. 또한 대량의 스레드는 왜 감당하지 못하였는지 어떻게 해결할 수 있는지에 대한 고민과 공부도 추후에 해보아야겠다.
