Login Process
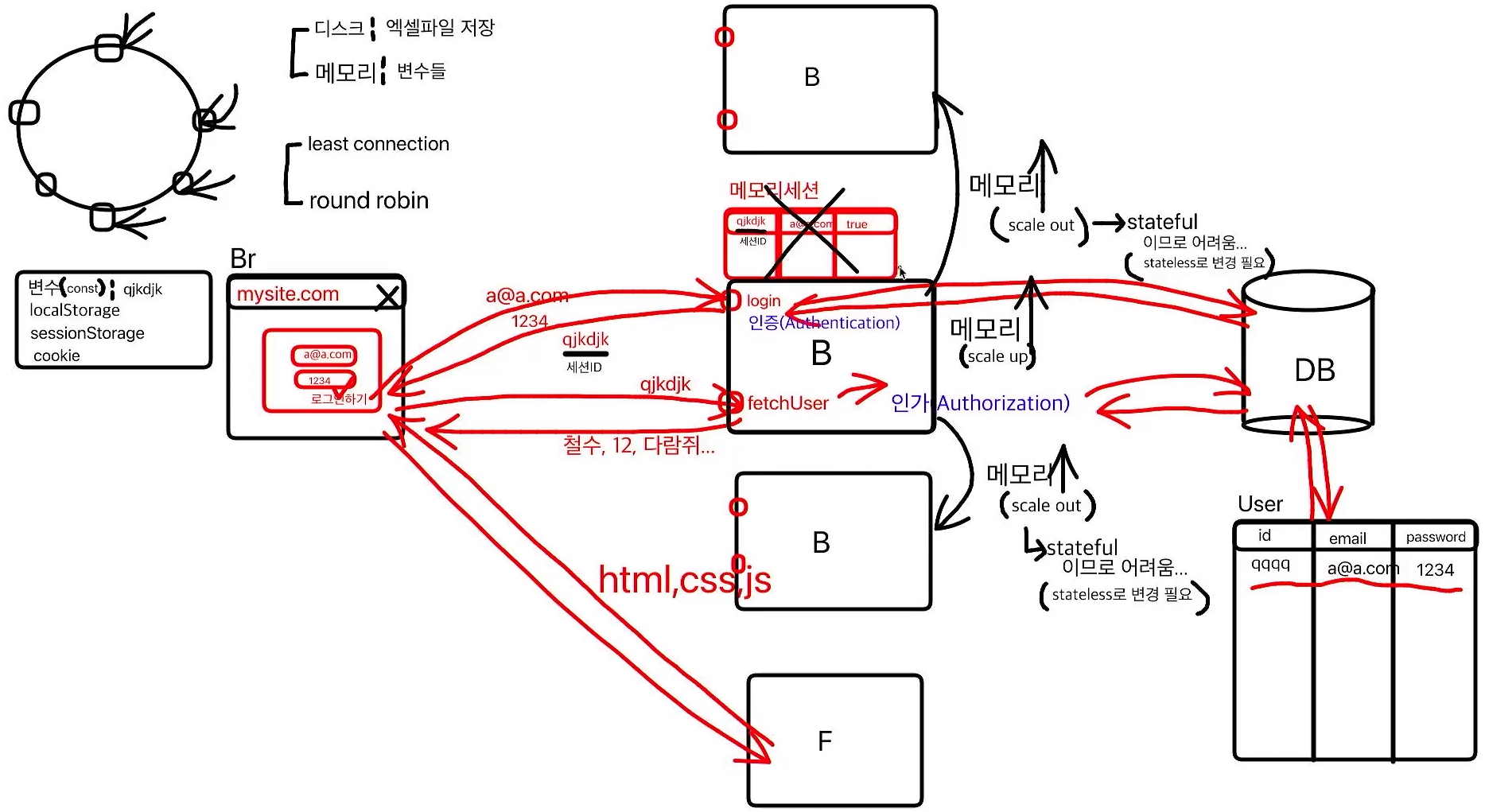
브라우저에서 로그인을 하면 백엔드로 API 요청이 가고, 백엔드에서는 DB에 해당 유저가 있는지 확인한 후 memory session에 저장하고 session id를 부여한다.
하지만 유저가 많아지게 되면 그 많은 유저 정보를 일일이 메모리세션에 저장할 수 없다.
그래서 메모리를 늘리게 되는데 이 과정을 Scale-up이라고 한다.
이 방법도 한계가 있기 때문에 컴퓨터를 복사해 여러 대로 늘리게 된다.
하지만 여러 곳으로 분산시키는 방법도 세션까지 scale-out이 되지 않아서 기존에 로그인 정보를 가지고 있던 컴퓨터가 아니면 로그인이 되지 않아 로그인을 유지시킬 수 없다.
그래서 로그인 정보를 DB에 저장하게 되었다. 하지만 이 방법도 DB에도 부하가 몰리게 되어 병목현상이 일어난다.
그렇다면 백엔드 컴퓨터를 복사해 여러 대로 늘린 것처럼 DB도 똑같이 늘리면 되지 않을까?
백엔드 컴퓨터의 경우는 소스코드를 복사해 똑같이 실행시켜주면 되는 것이였지만, DB는 데이터를 다 가지고 복사해주어야 하기 때문에 비효율적이고 쉽지 않다.
하지만 DB를 분리하는 방법은 있다.
DB를 수직으로 쪼개는 수직파티셔닝, 수평으로 쪼개는 수평파티셔닝(샤딩)이 있다.
하지만 이 방법에도 단점이 있다. DB에 저장된 정보는 영구적으로 저장된다는 장점이 있지만 디스크에 저장되는 것이기 때문에 느리다.
이 점을 해결하기 위해 메모리에 저장하는 DB가 있다. (redis) 대신 껐다 켜면 데이터는 사라진다.
현재 2가지 방법을 많이 사용하는데,
- redis에 session 정보 저장
- redis에도 저장하지 않고 사용하는 방법 -> 암호화
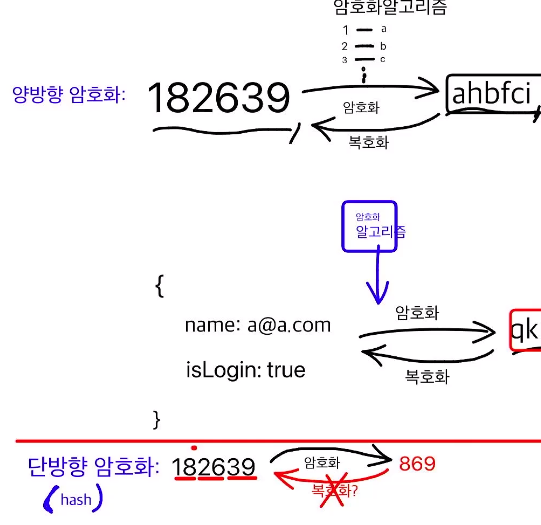
암호화 방식에는 양방향 암호화, 단방향 암호화가 있다.
양방향 암호화는 복호화가 가능하고 단방향 암호화는 복호화가 불가능하다.
복호화가 불가능한 단방향 암호화를 hash라고 한다.
JWT
session id는 Token이다. JWT(JSON Web Token) - 유저 정보를 자바스크립트 객체 형태로 만들어 암호화한 토큰.
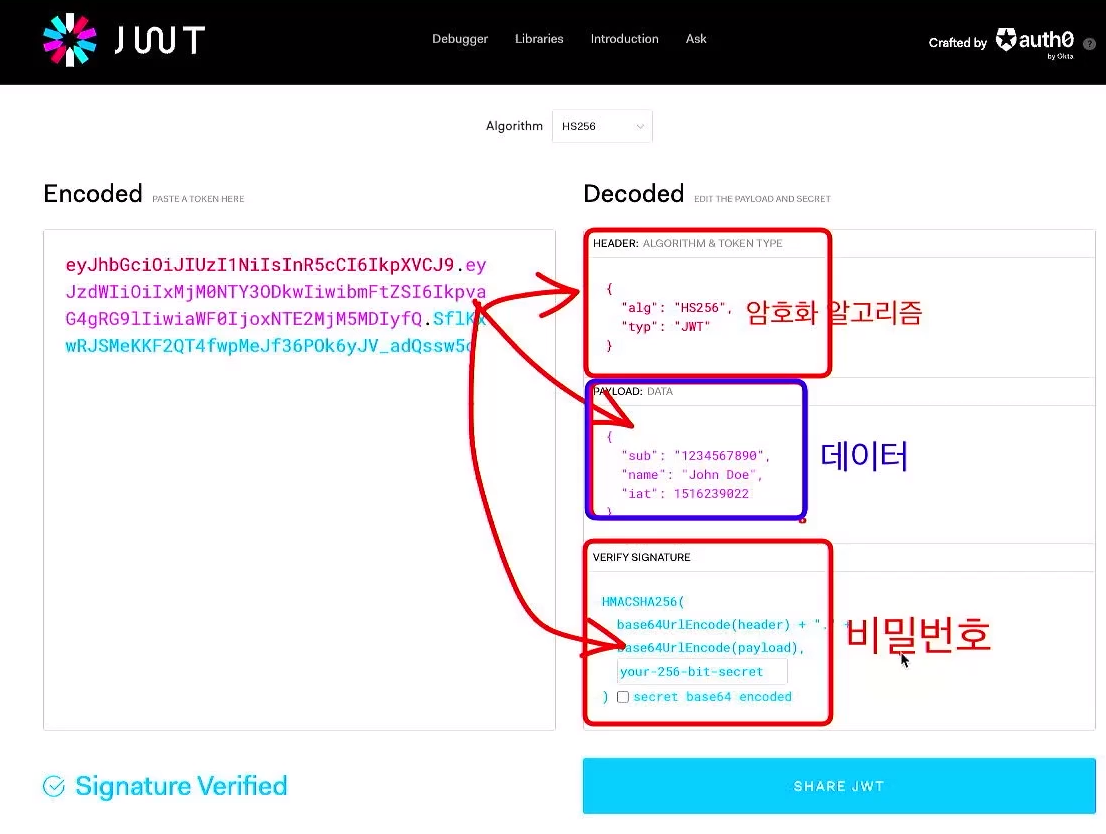
JWT의 암호화 방식에는 우리가 알고 있는 암호화 방식과는 차이가 있다.
어떤 방식으로 암호화가 되었는지, 어떤 정보를 저장했는지 안에 있는 내용들을 누구나 볼 수 있다. 이것이 JWT의 특징이다. 그래서 이 곳에는 절대 중요한 내용은 저장하면 안된다.
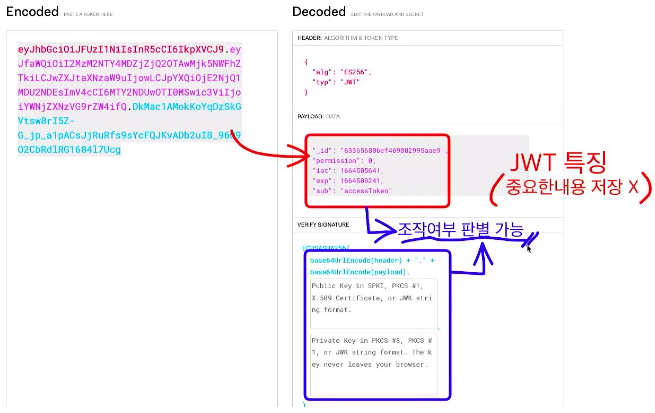
그러면 쓸 이유가 없는 것 아닐까 생각할 수 있지만 JWT의 시그니처 비밀번호로 조작여부를 판별할 수 있다. 만료 시간을 늘린다거나, id를 바꾼다거나 하는 조작이 불가능하다는 장점이 있다.
