numpy, pandas
python에서 데이터 분석 시 자주 사용하게 되는 라이브러리인 numpy, pandas 라이브러리를 다뤄 보려한다. 먼저 numpy에서 사용되는 기본 함수를 알아보자
numpy 기본 함수
import numpy as np
datas = [1, 3, -2, 4]
print("합은 ", np.sum(datas))
print("평균은 ", np.mean(datas))
print("분산은 ", np.var(datas))
print("표준편차는 ", np.std(datas))
print("평균 두번째 ", np.average(datas))numpy 라이브러리를 사용하기 위해 먼저 numpy를 import로 불러와 주고 np라는 별명으로 사용할 수 있게 변경하였다.
datas 라는 list type의 변수를 하나 만들어 기본 함수들이 어떻게 적용되는지 확인해보자.
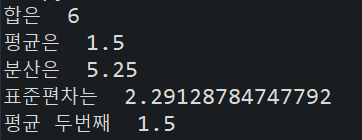
위의 사진과 같은 결과를 얻을 수 있다.
먼저 sum()함수는 받은 값들을 모두 더해준다.
var() 함수는 받은 값들의 분산을 구해준다.
std() 함수는 분산의 제곱근 값인 표준편차를 구해준다.
mean(), average() 함수는 받은 값들의 평균을 구해준다.
여기서 mean 함수와 average함수는 차이점이 존재하는데 mean 함수는 결측치를 무시를 하고 연산을 하고 average는 결측치를 포함하여 연산한다.
결측치가 존재할 수 있는 빅데이터에서 평균을 구할 때에 mean 함수를 사용하면 결측치를 피해 연산 할 수 있으므로 mean 함수를 많이 사용하게 될 것이다.
numpy에서 사용할 기본 함수들을 알아 보았으니 pandas로 넘어가자
pandas
pandas는 2차원 구조, 데이터 분석용 자료구조 및 함수를 제공하여 준다. 또한 numpy 기능을 계승, 스프레드시트, SQL 조작기능, 시각화, 시계열 처리, 축약연산, file i/o,...등 여러 기능이 존재한다.
데이터 분석 시 데이터 분석만큼 데이터 가공이 상당히 중요하다. pandas는 Data Wrangling(원자료(raw data)를 보다 쉽게 접근하고 분석할 수 있도록 데이터를 정리하고 통합하는 과정)에 주로 사용된다. 즉, 데이터 가공할 때에 pandas 라이브러리를 통해 원활하게 가공할 수 있으니 자주 만나게 될 것이다.
Series
먼저 알아볼건 Series이다. Series는 일련의 객체를 저장할 수 있는 1차원 배열 구조를 가진 객체로 하나의 열과 index로 구성 되어있는 모습을 볼 수 있다.
Series의 구조는 Series(data, name, index,...)로 되어 있으며 data에 인자값 타입은 tuple, list, dict 타입으로 넣을 수 있다. index의 인자값 타입은 tuple, list이다. 묶음형 자료 타입중 set은 사용할 수 없는데 set은 순서가 존재하지 않기 때문이다. dict타입은 순서가 없지만 key 이름이 존재하기 때문에 사용 가능한 것이다. dict타입으로 data에 값을 줄 경우 key 이름은 index명이 되고 value는 해당 index 데이터값으로 들어가게 된다.
import pandas as pd
obj = pd.Series([3, 7, -5, 4], index=['a', 'b', 'c', 'd'])
print(obj)pandas를 불러온 후 obj라는 변수에 Series를 저장한다.
obj를 출력한 결과는 아래의 사진과 같다.
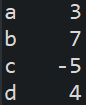
Series 함수 인자값 중 index에 값을 따로 주면 사용자가 원하는 index명으로 설정할 수 있다. 값을 주지 않을 경우 0번부터 시작하여 오름차순으로 번호가 붙는다.
name 인자값을 주면 Series 객체에 이름이 생기는데 다른 Series와 합치게 되면 Series의 name은 하나의 column명이 된다.
DataFrame
Series에 이어 DataFrame에 대해 알아보자. DataFrame은 2차원 자료구조를 가지고 있고 여러 개의 열로 구성되어 있다. DataFrame에서 하나의 column만 추출하게 되면 추출한 것의 타입은 Series 타입으로 된다. 즉, DataFrame은 여러 개의 Series가 붙어 있다고 생각하면 된다.
DataFrame의 구조는 DataFrame(data, columns, index,...)로 구성되어있다. Series와 다른점은 인자값 중 name대신 columns가 있다는 것이다. 위에서 한 설명처럼 Series의 name은 DataFrame에서 column명이라는 것을 인자값 구성을 통해 알 수 있다.
data = {
'irum':['홍길동','신기태', '유명한', '한가희'],
'juso':('역삼동', '신당동', '역삼동', '신사동'),
'nai':[23,33,32,25],
}
frame = pd.DataFrame(data)
print(frame)dict type의 data 객체를 만든 후 DataFrame의 data인자값으로 넣어주고 출력한 결과는 다음과 같다.

Series와는 다르게 key 이름이 column명이 되고 해당 column에 value들이 데이터값으로 들어가게 된다.
Series, DataFrame에 numpy에서 사용하는 기본 함수인 sum, mean, var, std 함수들 모두 사용가능하다. 이 함수들을 통해 원하는 결과값을 쉽게 구할 수 있음을 알아두자.
