
1. re.split
text3 = "사과+딸기+수박+메론+바나나"
re.split("\+", text3) # + 로 쓰면 에러남 \+ 로 써야됨2. nltk : natural language toolkit
# tokenization
from nltk.tokenize import RegexpTokenizer
text = """Don't be fooled by the dark sounding name, Mr.Jone's
Orphanage is as cheery as cheery goes for a pastry shop"""
token1 = RegexpTokenizer("[\w]+")
token2 = RegexpTokenizer("[\s]+", gaps=True)
print(token1.tokenize(text))
3. \w 는 숫자도 포함된다. 특수문자는 포함하지 않는다.

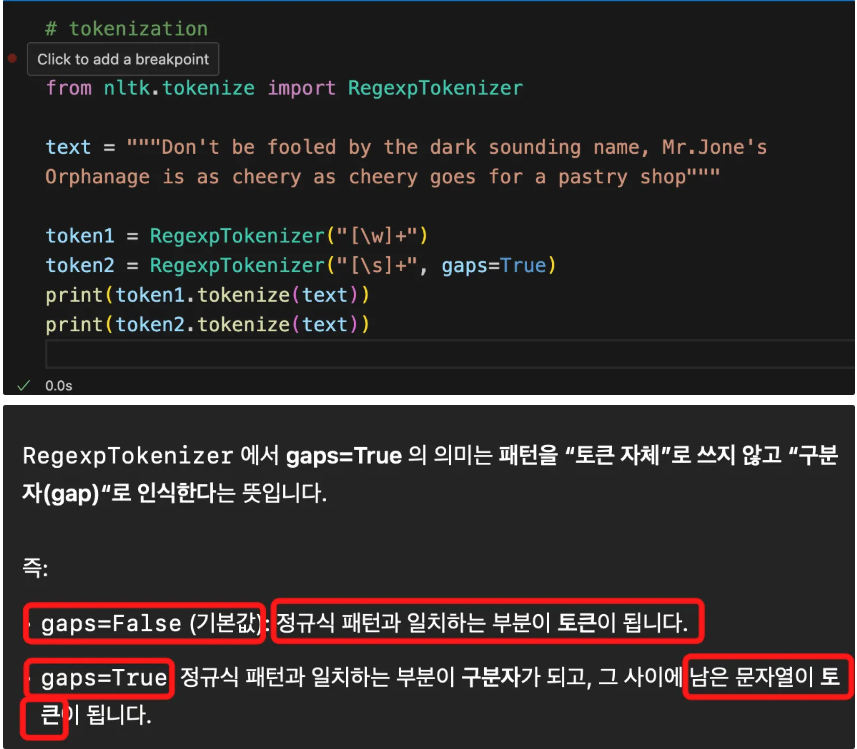
4. gaps options의 의미

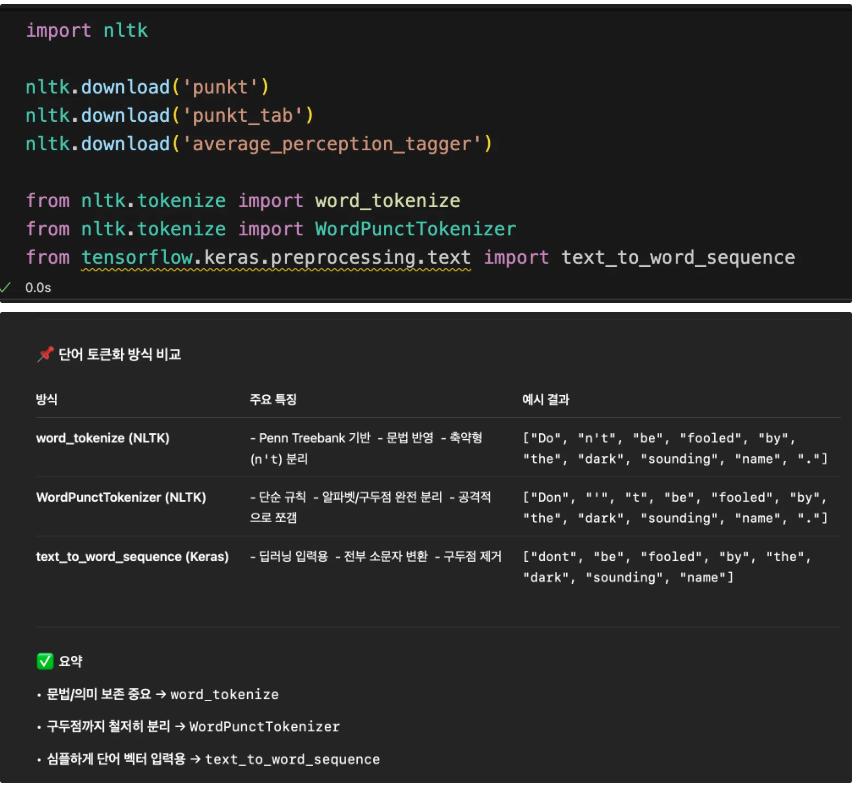
5. 토큰화 방식
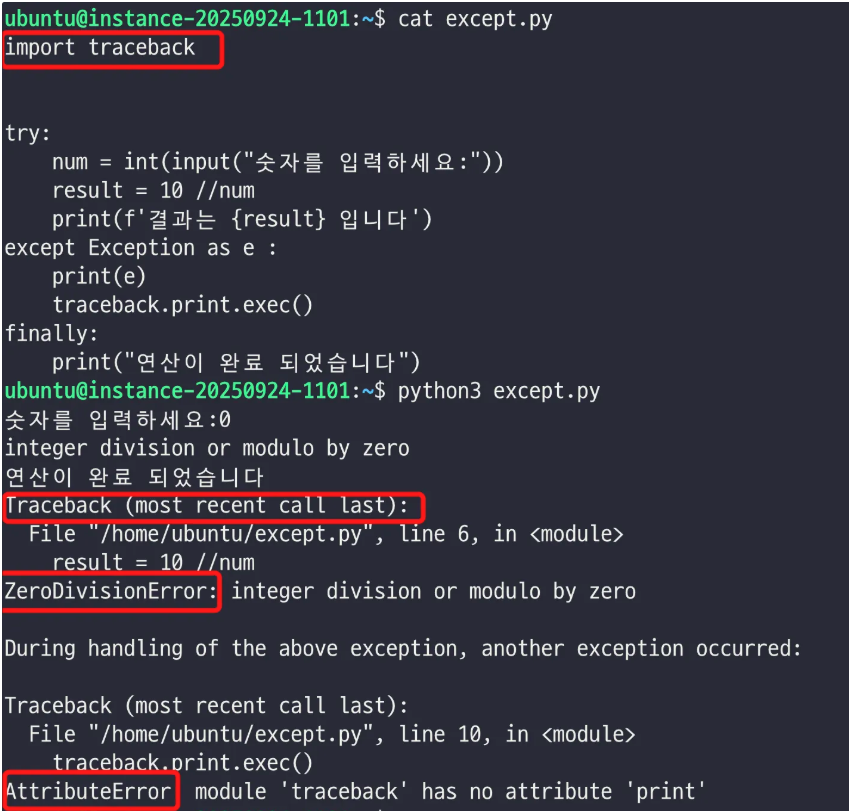
6. except tracback 라이브러리
- except 처리할때 실제 터지는 에러보고 추가하는 식으로 작성하면 된다.
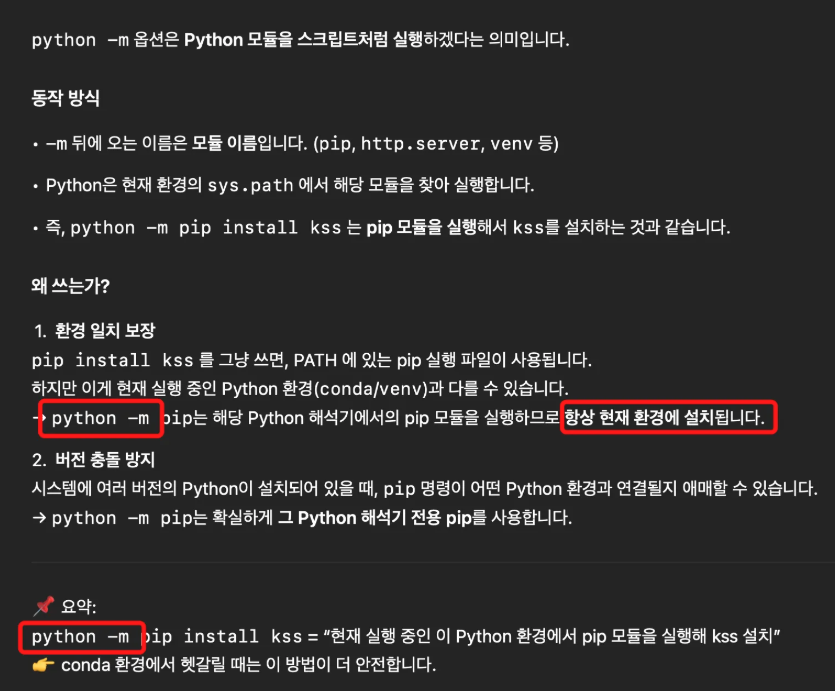
7. python -m 이용한 pip install
8. postgres 명령어
- select tablename from pg_tables; 테이블 이름 확인
- 관리자계정 아이디 : postgres
- CREATE EXTENSION IF NOT EXISTS vector; 백터DB 사용가능해짐
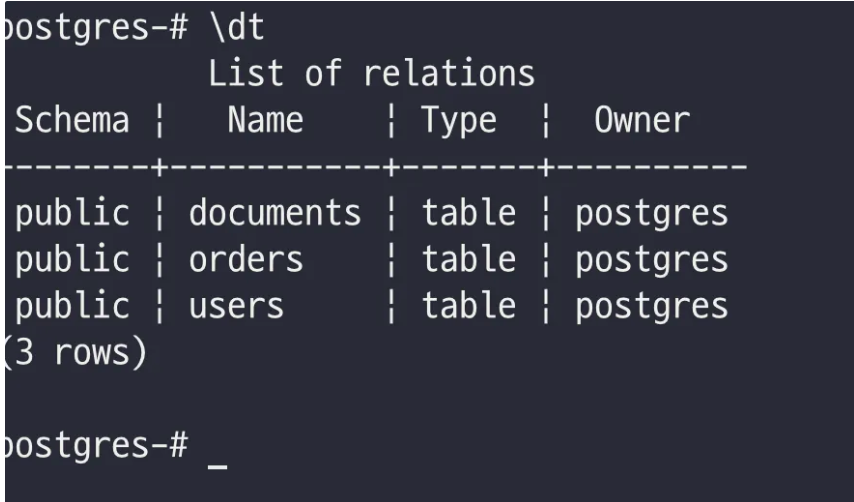
- \dt : 테이블 목록 보기
- \d 테이블명 : 테이블구조보기 / \d+ 자세한 정보보기
자주 쓰는 메타 커맨드
데이터베이스/스키마 관련
- \l : 데이터베이스 목록 보기
- \c [DB명] : 다른 데이터베이스로 접속
- \dn : 스키마 목록 보기
- \dt : 현재 스키마의 테이블 목록 보기
- \dt . : 모든 스키마의 테이블 목록 보기
테이블/뷰 관련
- \d 테이블명 : 테이블 구조 보기
- \d+ 테이블명 : 테이블 구조 + 추가 정보 (스토리지, 권한 등)
- \dv : 뷰(View) 목록 보기
- \ds : 시퀀스(Sequence) 목록 보기
- \di : 인덱스(Index) 목록 보기
- \dO : 외래키(Foreign Key) 관계 보기
함수/타입 관련
- \df : 함수(Function) 목록
- \df+ : 함수 상세 정보
- \do : 연산자(Operators) 목록
- \dT : 사용자 정의 타입(Type) 목록
- \du : 사용자(User) / 롤(Role) 목록
쿼리 및 출력 관련
- \x : 확장 모드 on/off (출력을 세로 포맷으로 보기)
- \timing : 쿼리 실행 시간 표시 on/off
- \i 파일.sql : SQL 파일 실행
- \g : 직전 쿼리 실행
- \o 파일명 : 쿼리 결과를 파일로 저장
도움말
- \? : psql 메타 커맨드 도움말
- \h [SQL명령] : SQL 문법 도움말 (예: \h SELECT)
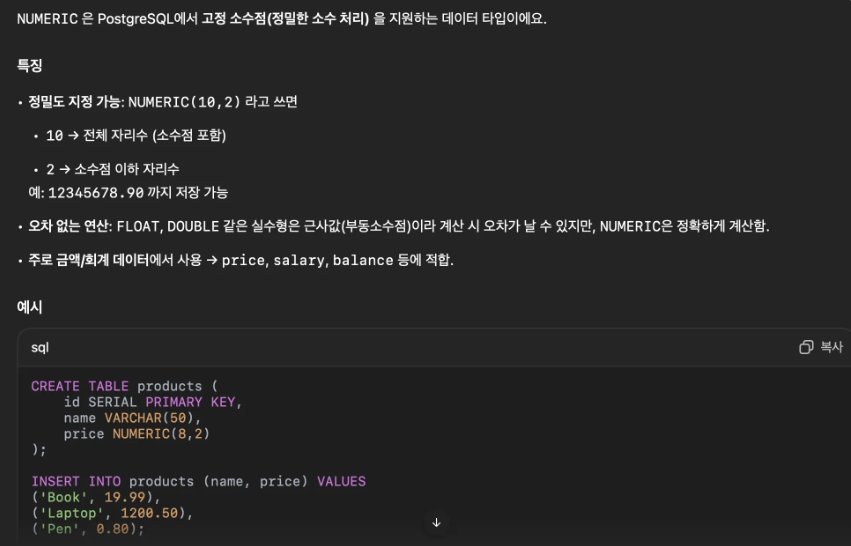
9. postgres numeric
10. 벡터DB 생성
CREATE TABLE documents (
id SERIAL PRIMARY KEY,
content TEXT,
embedding vector(3) -- 3차원 벡터
);INSERT INTO documents (content, embedding) VALUES
('Postgres is a powerful database', '[0.1, 0.2, 0.3]'),
('Vector databases are great for similarity search', '[0.4, 0.5, 0.6]'),
('I love working with embeddings', '[0.7, 0.8, 0.9]');-- 쿼리 벡터와 가장 가까운 문서 찾기
SELECT id, content, embedding
FROM documents
ORDER BY embedding <-> '[0.1, 0.2, 0.25]'
LIMIT 2;
####
<-> 연산자인데, 이건 pgvector 확장에서 제공하는 벡터 간 거리 연산자예요.
• <-> : Euclidean 거리(L2 distance) 계산
• <#> : 내적 (dot product)
• <=> : 코사인 거리 (cosine distance)테이블 목록 보기 \dt
11. 환경변수 가져오기
from dotenv import load_dotenv
import os
load_dotenv()
# 환경 변수 가져오기
print(os.getenv("GEMINI_API_KEY"))- dotenv는 .env 에 있는 값 가져오는 용도임 ( env에 있는 값 가져오는게 아님)
- os.getenv("키값") (환경변수 가져오기)
12. Vector DB
- https://milvus.io/ko (강사님 회사 사용 모델)
create table prod_embeddings (id serial primary key, name text,
embedding vector(3)); # 3차원 벡터 추가한것
- postgres는 최대 16000 차원까지 저장가능
- 코사인유사도 기반으로 유사도를 계산한다.
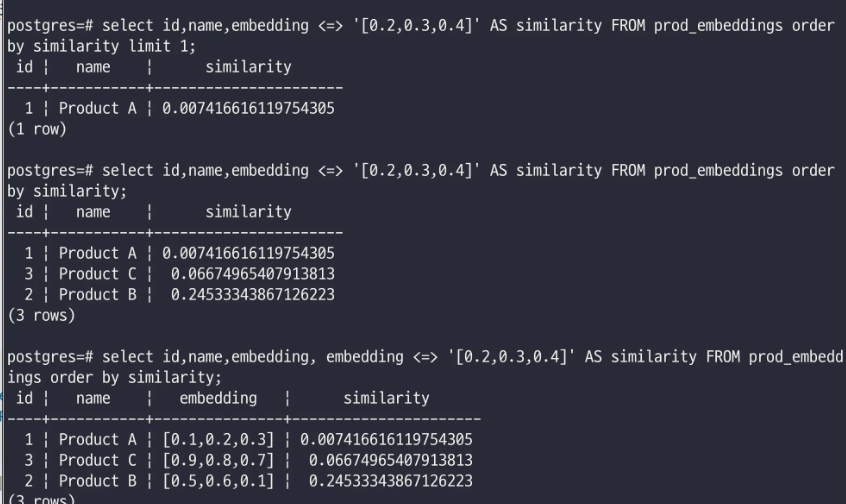
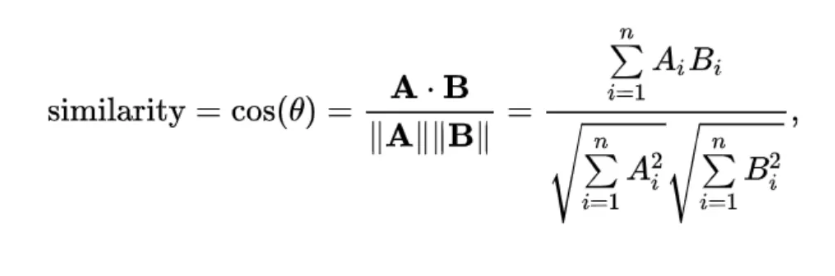
select id,name,embedding, embedding <=> '[0.2,0.3,0.4]' AS similarity
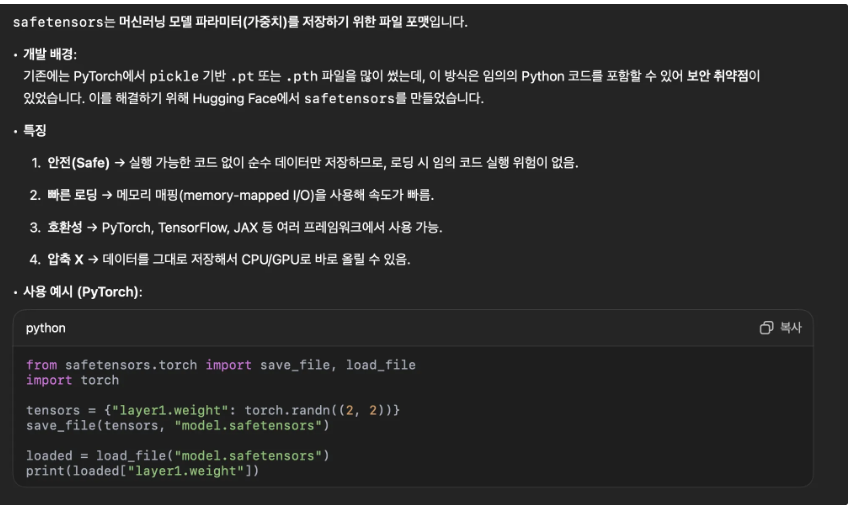
FROM prod_embeddings order by similarity;13. safetensor

즐겁게 공부하고 사람들에게 도움을 주는 개발자가 되고 싶습니다.